Реализация поискового движка с ранжированием на Python (Часть 1)
Просматривая ленту новостей я наткнулся на рекомендацию от Типичного Программиста на статью «Implementing a Search Engine with Ranking in Python», написанную Aakash Japi. Она меня заинтересовала, подобного материала в рунете не очень много, и я решил перевести её. Так как она довольно большая, я разделю её на 2-3 части. На этом я заканчиваю своё вступление и перехожу к переводу.
Каждый раз как я использую Quora, я в конечном итоге вижу по крайней мере вопрос вроде этого: кто-нибудь спрашивает, как работает Google и как они могли бы превзойти его по поиску информации. Большинство вопросов не настолько смелые и дезинформирующие, как этот, но все они выражают подобное чувство, и в этом они передают значительное непонимание того, как работают поисковые системы.
Но в то время как Google является невероятно сложным, основная концепция поисковой системы, которые ищут соответствия и оценивают (ранжируют) результаты относительно поискового запроса не представляет особой сложности, и это может понять любой с базовым опытом программирования. Я не думаю, что в данный момент возможно превзойти Google в поиске, но сделать поисковой движок — вполне достижимая цель, и на самом деле это довольно поучительное упражнение, которое я рекомендую попробовать.
Это то, что я буду описывать в этой статье: как сделать поисковую систему для локальных текстовых файлов, для которых можно обрабатывать стандартные запросы (по крайней мере, одно из слов в запросе есть в документе) и фразу целиком (появляется вся фраза в тексте) и может ранжировать с использованием базовой TF-IDF схемы.
Есть два основный этапа в разработке поискового движка: построение индекса, а затем, используя индекс, ответить на запрос. А затем мы можем добавить результат рейтинга (TF-IDF, PageRank и т.д.), классификацию запрос/документ, и, возможно, немного машинного обучения, чтобы отслеживать последние запросы пользователя и на основе этого выбрать результаты для повышения производительности поисковой системы.
Итак, без дальнейших церемоний, давайте начнем!
Построение индекса
Таким образом, первый шаг в построении текстового поискового движка — это сборка перевёрнутого индекса. Позвольте мне объяснить что это. Перевёрнутый индекс — это структура данных, которая сопоставляет маркеры с документами, в который они появляются. В данном контексте мы можем рассматривать маркер просто как слова, таким образом перевёрнутый индекс, в своей основе, это что-то, что берёт слово и возвращает нам список документов, где оно встречается.
Во-первых, мы, однако, должны проанализировать и отметить (маркировать, разделив на слова) наш свод документов. Мы сделаем это следующим образом: для каждого документа, который мы хотим добавить в наш индекс, мы удалим всю пунктуацию и разделить его на пробелы, создадим временную хеш-таблицу, которая соотносит имена документов к списку маркеров. Мы несколько раз преобразуем эту хеш-таблицу до тех пор, пока не достигнем окончательно перевёрнутого индекса, который я описал выше (правда, с небольшим усложнением, которое я объясню позже). Вот код, который сделает первоначальную фильтрацию текста:
Есть две вещи, которые я здесь не сделал, но рекомендую сделать. Удалите все стоп-слова («как», «и», «чтобы» и т.п., которые не добавляют релевантности документа) и преобразуйте все слова (таким образом «бег» и «бегун» превращаются в «бежать»), используя внешнюю библиотеку (хотя это будет замедлять индексирование).
Теперь я знаю, что упомянутый мною перевёрнутый индекс будет картой слова до имени документа, но мы так же хотим поддерживать запросы с фразами: запросы не только для слов, но и для слов в определённой последовательности. Для этого мы должны знать где в документе появляется каждое слово, таким образом мы сможем проверить порядок слов. Я индекс каждого слова в маркированном списке на документ в качестве позиции слова в этом документе, поэтому наш конечный перевернутый индекс будет выглядеть следующим образом:
Таким образом, наша первая задача состоит в том, чтобы создать сопоставление слов для своих позиций для каждого документа, а затем объединить их, чтобы создать наш полный перевёрнутый индекс. Это выглядит как:
Этот код довольно понятный: он принимает список терминов в документе, разделённые пробелом (в котором слова находятся в их первоначальном порядке), и добавляет каждое в хеш-таблицу, где значением является список позиций этого слова в документе. Мы строим этот список многократно, как мы идём по списку, до тех пор, пока не пройдём все слова, оставив нас с таблицей, снабжённую ключами по строкам и размеченными до списка позиций этих строк.
Теперь нам нужно объединить эти хеш-таблицы. Я начал это, с создания промежуточного формата индекса
которые мы затем преобразуем к нашему окончательному индексу. Это делается здесь:
Этот код очень прост: он просто принимает результаты функции file_to_terms, и создает новую хеш-таблицу помеченных ключом по имени файла и со значениями, которые являются результатом предыдущей функции, создавая вложенную хеш-таблицу.
Затем, мы можем на самом деле построить нашу перевернутый индекс. Вот код:
Итак, давайте разберём это. Во-первых, мы создаём простую хеш-таблицу (словарь Python), и мы используем два вложенных цикла для перебора каждого слова во входном (input) хеше. Затем, мы сначала проверяем, если это слово присутствует в качестве ключа в выходной (output) хеш-таблице. Если это не так, то мы добавим его, установив в качестве значения другую хеш-таблицу, которая сопоставляет документ (выявленные, в данном случае, по переменной filename) к списку позиций этого слова.
Если это ключ, то мы выполняем другую проверку: если текущий документ есть в каждой хеш-таблице слова (та, которая сопоставляет имена файлов с позицией слова). Если это ключ, то мы делаем другую чек: если текущий документ в хеш-таблицу каждого слова (тот, который сопоставляет имена файлов на должности слов). Если это так, мы расширяем список текущих позиций с этим списком позиций (обратите внимание, что этот случай оставили лишь для полноты: этого никогда не будет, потому что каждое слово будет иметь только один список позиций для каждого файла(filename)). Если это не так, то мы устанавливаем равные позиции в списке позиций для этого файла (filename).
И сейчас, у нас есть индекс. Мы можем ввести слово, и должны получить перечень документов, в которых оно встречается. В следующей статье я покажу как выполнить запрос по этому индексу.
Весь код, используемый во всех частях (вместе с реализацией) доступен на GitHub.
Быстрый живой поиск для сайта

Рабочий пример создаваемой поисковой системы.
Шаг 1: сканирование данных
Сначала нужно получить копию данных, которые должны быть доступны для поиска.
Для этого можно создать копию прямо из базы данных или извлечь ее с помощью API. Но я создам простой сканер, используя wget – инструмент командной строки с мощным «рекурсивным» режимом, который идеально подходит для загрузки содержимого сайтов.
Начнем со страницы https://24ways.org/archives/. На странице представлены публикации за каждый год работы сайта. Затем дадим команду для wget провести рекурсивное сканирование сайта, используя флаг —recursive.
Чтобы повторно не загружать в результатах поиска одинаковые страницы, используем параметр —no-clobber.
Код, отвечающий за запуск перечисленных выше команд:
Запустите его и через несколько минут вы получите подобную структуру:
Для проверки работоспособности примера подсчитаем количество найденных HTML-страниц:
Мы загрузили все публикации до 2017 года включительно. Но также нужно загрузить и статьи, которые опубликованы в 2018 г. Поэтому необходимо указать сканеру на публикации, размещенные на главной странице:
Теперь в компьютере есть папка, которая содержит HTML-файлы каждой статьи, опубликованной на сайте. Используем их, чтобы создать поисковой каталог.
Создание поискового каталога с помощью SQLite
SQLite – это наиболее широко используемая СУБД в мире. Она используется встроенными мобильными приложениями.
Для использования Jupyter на компьютере должен быть установлен Python 3. Можно использовать виртуальную среду Python, чтобы убедиться, что устанавливаемое программное обеспечение не конфликтует с другими установленными пакетами:
Особенность блокнотов Jupyter заключается в том, что при их публикации на GitHub они будут отображаться как обычный HTML. Это делает их очень мощным способом обмена кодом с аннотациями. Я опубликовал блокнот, который использовал для построения поискового каталога, в своей учетной записи GitHub.

Вот код Python, который я использовал для очистки релевантных данных из загруженных HTML- файлов. В блокноте приводится построчное объяснение того, что делает код.
Запустив этот код, я получил список словарей Python. Каждый из них содержит документы, которые необходимо добавить в каталог. Список выглядит примерно так:
Библиотека sqlite-utils может взять такой список и на его основе создать таблицу базы данных SQLite. Вот как это сделать, используя приведенный выше список словарей.
Библиотека создаст новую базу данных и добавит в нее таблицу «articles» с необходимыми столбцами. А затем вставит все документы в эту таблицу.
Можно проверить созданную таблицу с помощью утилиты командной строки sqlite3 (изначально встроена в OS X). Это можно сделать следующим образом:
Вызываем метод enable_fts(), чтобы получить возможность поиска по полям заголовка, автора и содержимого:
Представляем Datasette
Datasette – это открытое программное обеспечение, которое позволяет с легкостью публиковать базы данных SQLite в интернете. Мы анализировали нашу новую базу данных SQLite с помощью sqlite3 –инструмента командной строки. Возможно, стоит использовать интерфейс, который был бы удобнее для пользователей?
Если хотите установить Datasette локально, можно повторно использовать виртуальную среду, которую мы создали при разработке Jupyter:
Теперь можно запустить Datasette для файла 24ways.db, который мы создали ранее:
Эта команда запустит локальный сервер. Откройте в браузере адрес http://localhost:8001/, чтобы начать работу с веб-приложением Datasette.
Если вы хотите протестировать Datasette, не создавая собственный файл 24ways.db, можете загрузить мой.
Публикация базы данных в интернете
Если решите испробовать приведенный выше код, выберите другое значение —name, потому что имя «search-24ways» уже занято.
Фасетный поиск

Поиск SQLite поддерживает универсальные символы. Поэтому если вы хотите выполнять поиск с автозаполнением, нужно добавить * в конце запроса.
Используем собственный SQL для улучшения результатов поиска
Базовый SQL-запрос выглядит следующим образом:
Можно добиться лучшего результата, создав собственный SQL-запрос. Мы будем использовать следующий запрос:
Давайте разберем код SQL построчно:
Это другие поля, которые нам нужно вернуть. Большинство из них из таблицы articles. но мы извлекаем rank (демонстрирует релевантность поиска) из таблицы article_fts.
articles – это таблица, которая содержит наши данные. article_fts – это виртуальная таблица SQLite, которая реализует полнотекстовый поиск. Нужно подключиться к ней, чтобы появилась возможность отправлять ей запросы.
Затем мы сопоставляем это с таблицей article_fts с помощью оператора match. После этого применяем команду order by rank, чтобы самые релевантные результаты выводились наверх (ограничиваем их количество значением «10»).
JSON API вызывает поиск по статьям с ключевым словом SVG
Простой интерфейс поиска на JavaScript
Для создания интерфейса живого поиска мы будем использовать Vanilla JS. Нам нужно несколько служебных функций. Во-первых, классическая функция debounce:
Она будет отправлять запросы fetch() один раз в 100 мс во время ввода пользователем своего поискового запроса. Поскольку мы отображаем данные, которые могут включать в себя теги HTML, используем функцию htmlEscape. Я очень удивлен, что браузеры все еще не поддерживают одну из следующих команд по умолчанию:
Нам нужен HTML для формы поиска и div для отображения результатов:
А вот и реализация живого поиска на JavaScript:
Есть еще одна вспомогательная функция, используемая для построения HTML:
Как избежать многопоточности в живом поиске
Это ужасный пользовательский опыт: пользователь увидел нужные результаты на долю секунды, а потом они вдруг исчезли и появились результаты более раннего запроса.
К счастью, есть простой способ избежать этого. Я создал переменную с именем requestInFlight, которая изначально равна нулю.
Каждый раз, когда запускается новый запрос fetch(), создается новый объект currentRequest=<> и присваивается переменной requestInFlight.
Когда функция fetch() завершается, я использую requestInFlight!==currentRequest для проверки, что объект currentRequest идентичен объекту requestInFlight. Если пользователь вводит новый запрос в момент обработки текущего запроса, мы сможем это обнаружить и не допустить обновления результатов.
На самом деле, здесь не так уж много кода
Код выглядит весьма неаккуратно. Но вряд ли это важно, если вся реализация поисковой системы укладывается менее чем в 70 строк JavaScript. Использование SQLite– это надежный вариант. СУБД легко масштабируется до сотен МБ (или даже ГБ) данных. А тот факт, что он основан на SQL, обеспечивает простое взаимодействие.
Если использовать Datasette для API, то можно создавать относительно сложные приложения, с минимальными усилиями.
Дайте знать, что вы думаете по данной теме статьи в комментариях. За комментарии, дизлайки, подписки, лайки, отклики низкий вам поклон!
Дайте знать, что вы думаете по данной теме статьи в комментариях. Мы очень благодарим вас за ваши комментарии, дизлайки, подписки, лайки, отклики!
Краткое руководство. Вызов API Bing для поиска в Интернете с использованием Python
API Поиска Bing будут перенесены из Cognitive Services в службы Поиска Bing. С 30 октября 2020 г. подготовку всех новых экземпляров Поиска Bing необходимо будет выполнять в соответствии с процедурой, описанной здесь. API-интерфейсы Поиска Bing, подготовленные с помощью Cognitive Services, будут поддерживаться в течение следующих трех лет или до завершения срока действия вашего Соглашения Enterprise (в зависимости от того, какой период окончится раньше). Инструкции по миграции см. в статье о службах Поиска Bing.
Используйте это краткое руководство, чтобы вызвать API Поиска в Интернете Bing. Это приложение Python отправляет поисковый запрос к API и показывает ответ в формате JSON. Это приложение создано на языке Python. Но API представляет собой веб-службу на основе REST, совместимую с большинством языков программирования.
Этот пример запускается как записная книжка Jupyter в MyBinder. Чтобы запустить его, щелкните эмблему запуска Binder.
![]()
Предварительные требования
Создание ресурса Azure
Чтобы начать работу с API Поиска в Интернете Bing, создайте один из следующих ресурсов Azure.
Определение переменных
Замените значение subscription_key действительным ключом подписки из своей учетной записи Azure.
Объявите конечную точку API Bing для поиска в Интернете. Вы можете использовать глобальную конечную точку, указанную в коде ниже, или конечную точку личного поддомена, которая отображается на портале Azure для вашего ресурса.
Выполнение запроса
Полный список вариантов и параметров см. в разделе API Поиска в Интернете Bing версии 7.
Форматирование и отображение ответа
Пример кода в GitHub
Чтобы выполнить этот код локально, см. полный пример на сайте GitHub.
Как сделать полнотекстовую поисковую машину на 150 строках кода Python

Полнотекстовый поиск — неотъемлемая часть нашей жизни. Разыскать нужные материалы в сервисе облачного хранения документов, найти фильм в Netflix, купить туалетную бумагу на Ozon или отыскать с помощью сервисов Google интересующую информацию в Интернете — наверняка вы сегодня уже не раз отправляли похожие запросы на поиск нужной информации в невообразимых объёмах неструктурированных данных. И что удивительнее всего — несмотря на то что вы осуществляли поиск среди миллионов (или даже миллиардов) записей, вы получали ответ за считанные миллисекунды. Специально к старту нового потока курса Fullstack-разработчик на Python в данной статье мы рассмотрим основные компоненты полнотекстовой поисковой машины и попытаемся создать систему, которая сможет за миллисекунды находить информацию в миллионах документов и ранжировать результаты по релевантности, причём всю систему можно воплотить всего в 150 строках кода на Python!
Данные
Перед тем как начать создание поисковой машины, нужно подготовить полнотекстовые неструктурированные данные, в которых будет осуществляться поиск. Искать будем в аннотациях статей из английской Википедии. Это заархивированный с помощью gzip — утилиты сжатия и восстановления файлов — XML-файл размером около 785 Мбайт, содержащий приблизительно 6,27 миллионов аннотаций [1]. Для загрузки архивированного XML-файла я написал простую функцию, но вы можете поступить проще — загрузить его вручную.
Подготовка данных
Все аннотации хранятся в одном большом XML-файле. Аннотации в таком файле отделяются друг от друга элементом и выглядят примерно так (элементы, которые нас не интересуют, я опустил):
Интерес для нас представляют следующие разделы: title, url abstract (сам текст аннотации). Чтобы было удобнее обращаться к данным, представим документы как класс данных Python. Добавим свойство, конкатенирующее заголовок и содержание аннотации. Код можно взять здесь.
Затем нужно извлечь данные из XML-файла, осуществить их синтаксический разбор и создать экземпляры нашего объекта Abstract. Весь заархивированный XML-файл загружать в память не нужно, будем работать с потоком данных [2]. Каждому документу присвоим собственный идентификатор (ID) согласно порядку загрузки (то есть первому документу присваивается второму — и т. д.). Код можно взять здесь.
Индексирование
Полученные данные сохраняем в структуре данных, называемой «обращённый указатель», или «список документов». Полученная структура напоминает алфавитный указатель, который обычно приводится в конце книги, представляющий собой перечень встречающихся в книге соответствующих слов и понятий с указанием номеров страниц, на которых такие слова и понятия встречаются.
Так выглядит книжный алфавитный указатель
Фактически мы создаём словарь, в котором будет проведено сопоставление всех слов нашего набора документов с идентификаторами документов, в которых встречаются эти слова. Выглядеть это будет примерно так:
Обратите внимание, что в приведённом выше примере элементы словаря записаны строчными буквами. Перед созданием указателя мы должны разбить исходный текст на отдельные слова, или лексемы, то есть проанализировать текст. Сначала разобьём текст на отдельные слова (по-научному: выделим лексемы), а затем применим к лексемам ряд фильтров, например фильтр преобразования в нижний регистр или фильтр выделения основы слова (в принципе, фильтры можно и не применять), — это поможет получать более адекватные результаты поисковых запросов.
Выделение лексем
Анализ
Применим простейший способ выделения лексем: разобьём текст в местах, в которых встречаются пробелы. Затем к каждой лексеме применим пару фильтров: переведём текст лексемы в нижний регистр, удалим любые знаки препинания, исключим 25 наиболее распространённых английских слов (а также слово «википедия», так как оно встречается во всех заголовках всех аннотаций) и к каждому слову применим фильтр выделения основы слова (после этой операции разные формы слова, например, красный и краснота будут соответствовать одной и той же основе красн [3]).
Функции выделения лексем и перевода в нижний регистр довольно просты:
От знаков пунктуации избавиться также просто — к набору пунктуационных знаков применяется регулярное выражение:
Игнорируемые слова — это самые распространённые слова, которые, как мы полагаем, будут встречаться практически в каждом документе. Включение в указатель игнорируемых слов нежелательно, так как по поисковому запросу будет выдаваться практически каждый документ, и результат поиска станет малоинформативен (не говоря уже о том, что он займёт значительный объём памяти). Поэтому во время индексирования мы такие слова отфильтруем. В заголовках аннотаций статей Википедии содержится слово «Википедия», поэтому это слово мы также добавляем в список игнорируемых слов. В итоге мы внесли в список игнорируемых слов 25 самых распространённых слов английского языка, в том числе слово «Википедия».
Применяя все описанные выше фильтры, мы создаём функцию анализа (analyze), которая будет применяться к тексту каждой аннотации; данная функция разбивает текст на отдельные слова (или лексемы), а затем последовательно применяет каждый фильтр к списку лексем. Порядок применения фильтров важен, так как в списке игнорируемых слов не выделены основы слов, поэтому фильтр stopword_filter нужно применить до фильтра stem_filter.
Индексирование набора документов
Создадим класс Index, в котором будет храниться указатель (index) и документы (documents). В словаре documents будут храниться классы данных по идентификатору (ID), а ключи указателя index будут представлять собой лексемы со значениями идентификаторов документов, в которых встречаются лексемы:
Поиск
Теперь, когда все лексемы проиндексированы, задача выполнения поискового запроса превращается в задачу анализа текста запроса с помощью того же анализатора, который мы применили к документам; таким образом, мы получим лексемы, которые будут совпадать с лексемами, имеющимися в указателе. Для каждой лексемы осуществим поиск в словаре, выявим идентификаторы документов, в которых встречается такая лексема. Затем выявим идентификаторы документов во всех таких наборах (другими словами, чтобы документ соответствовал запросу, он должен содержать все лексемы, присутствующие в запросе). После этого возьмём итоговой список идентификаторов документов и выполним выборку данных из нашего хранилища документов [4].
Запросы получаются очень точными, особенно если строка запроса достаточно длинная (чем больше лексем содержит запрос, тем меньше вероятность выдачи документа, содержащего все такие лексемы). Функцию поиска можно оптимизировать, отдав предпочтение полноте, а не точности поиска, то есть пользователь может указать, что результатом поискового запроса может быть документ, в котором содержится лишь одна из указанных им лексем:
Релевантность
С помощью элементарных команд Python мы создали довольно быстро работающую поисковую систему, но остался один аспект, которого явно не хватает в нашей маленькой поисковой машине, а именно не учтён принцип релевантности. Сейчас программа поиска составлена таким образом, что пользователь получает неупорядоченный список документов и должен сам выбирать из полученного списка действительно нужные ему документы. Но, если результатов очень много, справиться с такой задачей не под силу никакому пользователю (в нашем примере OR программа выдала почти 50 000 результатов).
Вот тут-то и пригодится алгоритм ранжирования по релевантности, то есть алгоритм, который присваивал бы каждому документу собственный ранг — насколько точно документ соответствует запросу, и затем упорядочивал бы полученный список по таким рангам. Самый примитивный и простой способ присвоения ранга документу при выполнении запроса состоит в том, чтобы просто подсчитать, как часто в таком документе упоминается конкретное слово. Идея вроде бы логичная: чем чаще в документе упоминается термин, тем больше вероятность того, что это именно тот документ, который мы ищем!
Частота вхождения терминов
Расширим наш класс данных Abstract, чтобы можно было вычислять и сохранять частоту вхождения терминов в процессе индексирования. Соответственно, если нам потребуется ранжировать наш неупорядоченный список документов, у нас будет для этого вся нужная информация:
При индексировании должен осуществляется подсчёт частот вхождения терминов:
Внесём изменения в функцию поиска таким образом, чтобы к документам результирующего набора можно было применить ранжирование. Выборку документов будем осуществлять с помощью одного и того же логического запроса из указателя и базы данных документов, а затем для каждого документа такого результирующего множества подсчитаем, сколько раз встречается в этом документе каждый термин.
Обратная частота документов
Полученная функция работает уже намного лучше, но у нее всё равно имеются определённые недостатки. Мы подразумевали, что при оценке релевантности запроса все термины запроса имеют один и тот же вес. Но, как нетрудно догадаться, при определении релевантности некоторые термины имеют либо крайне малую, либо вообще нулевую различающую способность; например, в наборе из большого количества документов, относящихся к пиву, термин «пиво» будет встречаться практически в каждом документе (ранее мы уже пытались обойти эту проблему, исключив из указателя 25 самых распространённых английских слов). Поиск слова «пиво» приведёт к тому, что мы получим лишь маловразумительный набор хаотично упорядоченных документов.
Чтобы решить проблему, добавим в наш алгоритм определения релевантности ещё один компонент, занижающий в итоговом результате вес терминов, очень часто встречающихся в указателе. В принципе, можно было бы использовать значение частоты вхождения термина (то есть насколько часто такой термин встречается во всех документах), однако на практике вместо этого значения используется значение частоты документов (то есть какое количество документов в указателе содержат данный термин). Поскольку наша задача заключается в ранжировании именно документов, формировать статистику имеет смысл на уровне документов.
Обратная частота документов для термина определяется делением количества документов (N) в указателе на количество документов, содержащих термин, и взятием логарифма полученного частного.
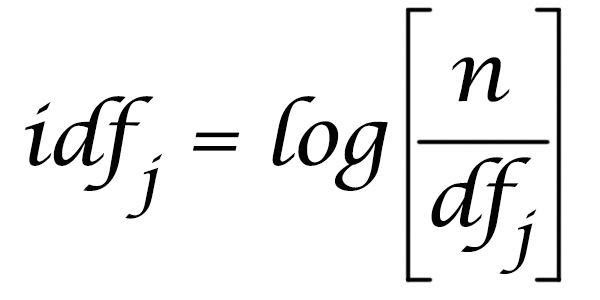 Обратная частота документов (IDF); формула взята из https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
Обратная частота документов (IDF); формула взята из https://moz.com/blog/inverse-document-frequency-and-the-importance-of-uniqueness
При ранжировании значение частоты термина умножается на значение обратной частоты документа, и, следовательно, документы, в которых присутствуют термины, редко встречающиеся в наборе документов, будут более релевантными [5]. Значение обратной частоты документов можно легко рассчитать по указателю:
Будущая работа™
Мы создали элементарную информационно-поисковую систему всего из нескольких десятков строчек кода Python! Код целиком приведён на Github. Также я написал вспомогательную функцию, загружающую аннотации статей Википедии и создающую указатель. Установите файл requirements, запустите его в выбранной вами консоли Python и получайте удовольствие от работы со структурами данных и операциями поиска.
Данная статья написана с единственной целью — привести пример реализации концепции поиска и продемонстрировать, что поисковые запросы (даже с ранжированием) могут выполняться очень быстро (например, на своём ноутбуке с «медленным» Python я могу осуществлять поиск и ранжирование среди 6,27 миллионов документов). Статью ни в коем случае не следует рассматривать как инструкцию по созданию программного обеспечения промышленного уровня. Моя поисковая машина запускается полностью в памяти ноутбука, но такие библиотеки, как Lucene, используют сверхпроизводительные структуры данных и даже оптимизируют дисковые операции, а такие программные комплексы, как Elasticsearch и Solr, распространяют библиотеку Lucene на сотни, а иногда и тысячи машин.
Но даже наш простенький алгоритм можно существенно улучшить. Например, мы молчаливо предполагали, что каждое поле документа вносит в релевантность одинаковый вклад, но, если поразмыслить, так быть не должно — ведь термин, присутствующий в заголовке, очевидно, должен иметь больший вес, чем термин, встречающийся в содержании аннотации. Другой перспективной идеей может стать более продвинутый синтаксический анализ запроса — должны ли совпадать все термины? только один термин? или несколько? Зная ответы на эти вопросы, можно повысить качество работы поисковых запросов. Также — почему бы не исключить из запроса определённые термины? почему бы не применить операции AND и OR к отдельным терминам? Можно ли сохранить указатель на диск и вывести его, таким образом, за пределы оперативной памяти ноутбука?
Благодаря своей универсальности и распространённости, Python уже который год находится в топе языков программирования и де-факто стал основным языком для работы с данными. Если вы хотите расширить свои компетенции и освоить этот язык под руководством крутых менторов — приходите на курс Fullstack-разработчик на Python.
Узнайте, как прокачаться в других инженерных специальностях или освоить их с нуля: