Руководство по веб-разработке серверной части с помощью Node.js
Дата публикации: 2019-02-04

От автора: большую часть своей веб-карьеры я работал исключительно на стороне клиента. Проектирование адаптивных макетов, создание визуализаций из больших объемов данных, создание панелей управления приложений и т. д. Но мне никогда не приходилось иметь дело с маршрутизацией или HTTP-запросами напрямую. До не давнего времени.
В этом посте приводится описание того, в чем заключается разработка серверной части веб с помощью Node.js, и краткое сравнение написания простого HTTP-сервера с использованием 3 различных фреймворков: Экспресс, Koa.js и Hapi.js.
Некоторые базовые принципы
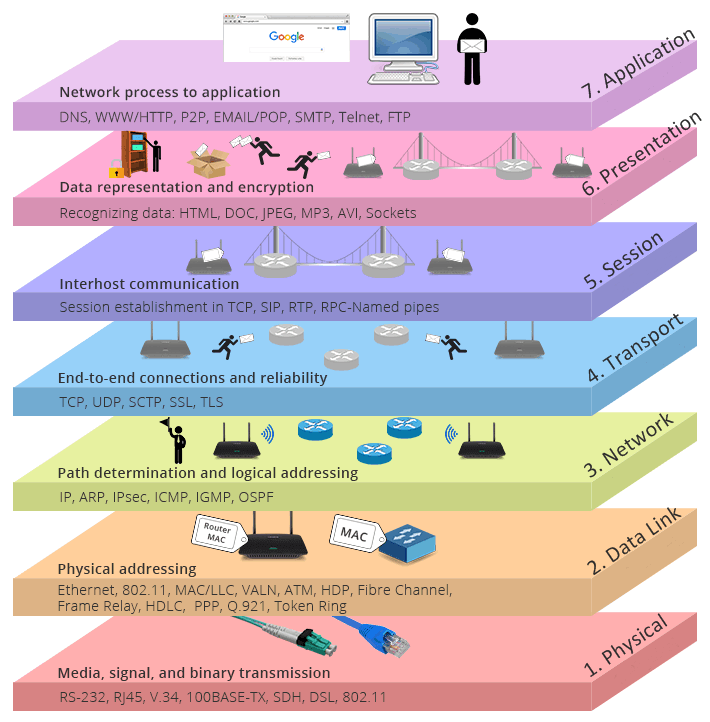
Здесь я только хочу привести краткий обзор вещей для контекста. HTTP (Hypertext Transfer Protocol) — это протокол связи, используемый в компьютерных сетях. В Интернете их много, такие как SMTP (Simple Mail Transfer Protocol), FTP (File Transfer Protocol), POP3 (Post Office Protocol 3) и так далее.
Эти протоколы позволяют устройствам с совершенно разным аппаратным / программным обеспечением связываться друг с другом, поскольку они предоставляют четко определенные форматы сообщений, правила, синтаксис и семантику и т. д. Это означает, что пока устройство поддерживает определенный протокол, оно может связываться с любым другим устройством. в сети.

Бесплатный курс «NodeJS. Быстрый старт»
Изучите курс и узнайте, как создать веб-приложение с нуля на JavaScript с NodeJS
Операционные системы обычно поставляются с поддержкой сетевых протоколов, таких как HTTP, из коробки, что объясняет, почему нам не нужно отдельно устанавливать какое-либо дополнительное программное обеспечение для доступа в Интернет. Большинство сетевых протоколов поддерживают открытое соединение между двумя устройствами, что позволяет им передавать данные туда и обратно.
HTTP, на котором работает сеть, отличается. Он известен как протокол без установления соединения, потому что он основан на режиме работы запрос / ответ. Веб-браузеры отправляют на сервер запросы на изображения, шрифты, контент и т. д., но после выполнения запроса соединение между браузером и сервером разрывается.

Серверы и клиенты
Термин «сервер» может немного сбивать с толку тех, кто плохо знаком с отраслью, поскольку он может относиться как к аппаратному обеспечению (физические компьютеры, на которых размещены все файлы и программное обеспечение, требуемое веб-сайтами), так и к программному обеспечению (программе, которая позволяет пользователям получать доступ к этим файлам в Интернете).
Сегодня мы поговорим о программной части. Но сначала несколько определений. URL обозначает Universal Resource Locator и состоит из 3 частей: протокола, сервера и запрашиваемого файла.

Протокол HTTP определяет несколько методов, которые браузер может использовать, чтобы попросить сервер выполнить кучу различных действий, наиболее распространенными из которых являются GET и POST. Когда пользователь кликает ссылку или вводит URL-адрес в адресную строку, браузер отправляет серверу GET-запрос на получение ресурса, определенного в URL-адресе.
Сервер должен знать, как обрабатывать этот HTTP-запрос, чтобы получить правильный файл, а затем отправить его обратно браузеру, который его запросил. Наиболее популярное программное обеспечение веб-сервера, которое обрабатывает это Apache и NGINX.

Оба представляют собой полный пакет программ с открытым исходным кодом, которые включают в себя такие функции, как схемы аутентификации, перезапись URL-адресов, ведение журнала и проксирование, и это лишь некоторые из них. Apache и NGINX написаны на C. Технически, вы можете написать веб-сервер на любом языке. Python, Go, Ruby, этот список можно продолжаться довольно долго. Просто некоторые языки лучше делают определенные вещи, чем другие.
Пишем масштабируемые и поддерживаемые сервера на Node.js и TypeScript

Последние три года я занимаюсь разработкой серверов на Node.js и в процессе работы у меня накопилась некоторая кодовая база, которую я решил оформить в виде фреймворка и выложил в open-source.
Основными особенностями фреймворка можно назвать:
В данной статье мы поговорим немного о Node.js и рассмотрим данный фреймворк
Всем кому интересно – прошу под кат
В чем же проблема и зачем писать очередной велосипед?
Основная проблема серверной разработки на Node.js заключается в двух вещах:
Что же с низким уровнем вхождения? Тут основная проблема в том, что с каждым оборотом колеса хайпа и приходом новых библиотек/фреймворков, все пытаются упростить. Казалось бы, проще — лучше, но т.к. пользуются этими решениями в итоге не всегда опытные разработчики — возникает культ поклонения библиотекам и фреймворкам. Наверное самый очевидный пример — это express.
Что не так с express? Да ничего! Нет, безусловно в нем можно найти недостатки, но express — это инструмент, инструмент которым нужно уметь пользоваться, проблемы начинаются когда express, или любой другой фреймворк, занимает главную роль в вашем проекте, когда вы слишком завязаны на нем.
Исходя из вышеперечисленного, начиная разрабатывать новый проект, я начал с написания некоторого «ядра» сервера, позже оно переносилось в другие проекты, дорабатывалось и в конечно итоге стало фреймврком Airship.
Основная концепция
Начиная продумывать архитектуру я задал себе вопрос: «Что делает сервер?». На самом высоком уровне абстракции сервер делает три вещи:
Все же просто, зачем усложнять себе жизнь? Я решил, что архитектура должна быть примерно следующей: у каждого запроса, поддерживаемого нашим севером, есть модель, модели запросов поступают в обработчики запросов, обработчики в свою очередь отдают модели ответов.
Важно заметить, что наш код ничего не знает про сеть, он работает только с инстансами обычных классов запросов и ответов. Этот факт позволяет нам не только доиться более гибкой архитектуры, но и даже сменить транспортный слой. Например мы можем пересесть с HTTP на TCP без изменения нашего кода. Безусловно это очень редкий случай, но такая возможность показывает нам гибкость архитектуры.
Модели
Начнем с моделей, что от них нужно? В первую очередь нам нужен простой способ сериализации и десериализации моделей, еще не помешает валидация типов при десериализации, т.к. пользовательские запросы — это тоже модели.
В дальнейшем описании я опущу некоторые детали, которые можно прочитать в документации, чтобы не раздувать статью.
Вот как это работает:
Если мы передадим данные неверного типа, то сериализатор выбросит исключение:
Модели запросов
Запросы — это те же модели, разница в том, что все запросы наследуются от ASRequest и используют декоратор @queryPath для указания пути запроса:
Модели ответов
Модели ответов тоже пишутся как обычно, но наследуются от ASResponse :
Обработчики запросов
Обработчики запросов наследуются от BaseRequestHandler и реализуют два метода:
Получение запросов
Соединяем все вместе
Генерация схемы API
В первую очередь нужно создать конфиг, который укажет все наши запросы и ответы:
После этого мы можем запустить утилиту, указав путь до конфига и до папки, в которую будет записана схема:
Генерация клиентского SDK
Зачем же нам нужна схема? Например мы можем сгенерировать полностью типизированное SDK для фронтенда на TypeScript. SDK состоит из четырех файлов:
Приведу кусок API.ts из рабочего проекта:
Весь этот код написан автоматически, это позволяет не отвлекаться на написание клиента и бесплатно получить подсказки названий полей и их типов, если ваша IDE это умеет.
Сгенерировать SDK тоже просто, нужно запустить утилиту asdkgen и передать ей путь до схем и путь, где будут лежать SDK:
Генерация документации
На генерации SDK я не остановился и написал генерацию документации. Документация достаточно простая, это обычный HTML с описанием запросов, моделей, ответов. Из интересного: для каждой модели есть сгенерированный код для JS, TS и Swift:
Заключение
Данное решение уже долгое время используется в production, помогает поддерживать старый код, писать новый и не писать код для клиента.
Многим и статья и сам фреймворк может показаться очень очевидным, я это понимаю, другие могут сказать, что такие решения уже есть и даже ткнуть меня носом в ссылку на такой проект. В свою защиту я могу сказать только две вещи:
Если кому-то все вышеперечисленное понравилось — добро пожаловать в GitHub.
Глава 5
Основы Серверного JavaScript
В этой главе даются основы серверной функциональности и различия между клиентским и серверным JavaScript. Здесь показано, как внедрять серверный JavaScript в HTML-файлы. Обсуждается, что происходит во время прогона программы на клиенте и на сервере, чтобы Вы могли разобраться во всём этом. В главе описано, как использовать JavaScript для изменения HTML-страницы, отправляемой клиенту, и, наконец, как распределить информацию между серверными и клиентскими процессами.
В главе имеются следующие разделы:
Серверный JavaScript имеет то же ядро языка, что и клиентский JavaScript, с которым Вы, возможно, уже знакомы. Задачи, выполняемые Вами при запуске JavaScript на сервере, несколько отличаются от задач, выполняемых при работе JavaScript на клиенте. Разные окружения и задачи обращаются к различным объектам.
Что Делать и Где
Клиентская среда (браузер) является передним краем работы приложения. В этой среде, к примеру, Вы отображаете HTML-страницы в окне и обслуживаете истории сессий HTML-страниц, отображаемых в браузере в течение сессии. Объекты этой среды, следовательно, обязаны иметь возможность манипулировать страницами, окнами и историей.
По контрасту, в серверной среде Вы работаете с ресурсами сервера. Например, Вы можете установить соединение с реляционной базой данных, распределить информацию между пользователями приложения или манипулировать файловой системой сервера. Объекты этой среды обязаны иметь возможность манипулировать реляционной БД и файловой системой сервера.
Кроме того, HTML-страница не отображается на сервере. Она запрашивается на сервере для отображения на клиенте. Запрошенная страница может содержать клиентский JavaScript. Если запрошенная страница является частью приложения JavaScript, сервер может генерировать эту страницу «на лету».
При разработке приложения JavaScript помните о разнице между клиентской и серверной платформами. Различия показаны в следующей таблице.
Таблица 5.1 Сравнение Клиента и Сервера
Серверы обычно (хотя и не всегда) являются высокопроизводительными рабочими станциями с быстрыми процессорами и возможностью хранения больших объемов информации.
Клиенты часто (хотя и не всегда) являются настольными системами с маломощными процессорами и относительно небольшим объемом хранимых данных.
Серверы могут быть перегружены при одновременном доступе тысяч клиентов.
Предварительная обработка данных на клиенте также может уменьшить требования к пропускной способности сети, если клиентское приложение может компоновать данные.
Обычно имеются разные пути распределения приложения между сервером и клиентом. Некоторые задачи могут выполняться только на клиенте или только на сервере; другие могут выполняться на любом из них. Хотя нет какого-то определённого способа определить, что и где делать, Вы может следовать следующим общим правилам:
Использовать серверный процессинг (тэг SERVER ) для следующих задач:
Служба JavaScript Session Management Service предоставляет объекты для сохранения информации, а клиентский JavaScript преходящ. Клиентские объекты существуют, пока пользователь имеет доступ к странице. Серверы могут объединять информацию от многих клиентов и многих приложений и могут сохранять большие объёмы данных в базе данных. Важно помнить обо всех этих характеристиках при распределении функциональности между клиентом и сервером.
Обзор Процессов Времени Прогона (Выполнения)
После того как Вы установили и стартовали приложение JavaScript, пользователь может получить к нему доступ.
Базовые процедуры таковы:
Рисунок 5.1 иллюстрирует это процесс.
Рисунок 5.1 Процессинг запроса JavaScript-страницы
Конечно, пользователь обязан иметь Netscape Navigator (или иной браузер с возможностью выполнения JavaScript), чтобы клиент мог интерпретировать операторы клиентского JavaScript. Аналогично, если Вы создаёте страницу, содержащую серверный JavaScript, он должен быть установлен на Netscape-сервере, чтобы нормально функционировать.
Например, предположим, клиент запрашивает страницу с таким исходным кодом:
Add a New Customer
Note: All fields are required for the new customer
Ваш первый сервер на Node.js
Node Hero: Глава 4


В этой главе я расскажу вам о том, как вы можете запустить простой HTTP-сервер на Node.js и начать обрабатывать запросы.
Модуль http для вашего Node.js-сервера
Затем запускаем этот скрипт:
Что нужно здесь отметить:
Модуль http крайне низкоуровневый: создание сложного веб-приложения с использованием вышеприведенного фрагмента кода очень трудоемко. Именно по этой причине мы обычно выбираем фреймворки для работы над нашими проектами. Есть множество фреймворков, вот самые популярные:
В этой и следующих главах мы будем использовать Express, так как именно для него вы можете найти множество модулей в NPM.
Express
Добавление Express в ваш проект — это просто установка через NPM:
После того, как вы установили Express, давайте посмотрим, как создать приложение аналогичное тому, что мы написали ранее:
Одна из самых мощных концепций, которую реализует Express — это паттерн Middleware.
Middleware — промежуточный обработчик
Вы можете думать о промежуточных обработчиках как о конвейерах Unix, но для HTTP-запросов.

На диаграмме вы можете увидеть, как запрос идёт через условное Express-приложение. Он проходит через три промежуточных обработчика. Каждый обработчик может изменить этот запрос, а затем, основываясь на вашей бизнес-логике, третий middleware отправит ответ, либо запрос попадёт в обработчик соответствующего роута.
На практике вы можете сделать это следующим образом:
Что следует здесь отметить:
Обработка ошибок
Как и во всех фреймворках, правильная обработка ошибок имеет решающее значение. В Express вы должны создать специальный промежуточный обработчик — middleware с четырьмя входными параметрами:
Что следует здесь отметить:
Рендеринг HTML
Ранее мы рассмотрели, как отправлять JSON-ответы. Пришло время узнать, как отрендерить HTML простым способом. Для этого мы собираемся использовать пакет handlebars с обёрткой express-handlebars.
Сначала создадим следующую структуру каталогов:
После этого заполните index.js следующим кодом:
Последнее, что мы должны сделать, чтобы заставить всё это работать, — добавить обработчик маршрута в наше приложение Express:
Метод render принимает два параметра:
Как только вы сделаете запрос по этому адресу, вы получите что-то вроде этого:
Это всего лишь верхушка айсберга. Чтобы узнать, как добавить больше шаблонов (и даже частичных), обратитесь к официальной документации express-handlebars.
Отладка Express
Руководство по Node.js, часть 1: общие сведения и начало работы
Мы начинаем публикацию серии материалов, которые представляют собой поэтапный перевод руководства по Node.js для начинающих. А именно, в данном случае «начинающий» — это тот, кто обладает некоторыми познаниями в области браузерного JavaScript. Он слышал о том, что существует серверная платформа, программы для которой тоже пишут на JS, и хотел бы эту платформу освоить. Возможно, вы найдёте здесь что-то полезное для себя и в том случае, если уже знакомы с Node.js.
Кстати, в прошлом году у нас был похожий по масштабам проект, посвящённый bash-скриптам. Тогда мы, после публикации всех запланированных материалов, собрали их в виде PDF-файла. Так же планируется поступить и в этот раз.
Сегодня мы обсудим особенности Node.js, начнём знакомство с экосистемой этой платформы и напишем серверный «Hello World».
Обзор Node.js
Node.js — это опенсорсная кроссплатформенная среда выполнения для JavaScript, которая работает на серверах. С момента выпуска этой платформы в 2009 году она стала чрезвычайно популярной и в наши дни играет весьма важную роль в области веб-разработки. Если считать показателем популярности число звёзд, которые собрал некий проект на GitHub, то Node.js, у которого более 50000 звёзд, это очень и очень популярный проект.
Платформа Node.js построена на базе JavaScript движка V8 от Google, который используется в браузере Google Chrome. Данная платформа, в основном, используется для создания веб-серверов, однако сфера её применения этим не ограничивается.
Рассмотрим основные особенности Node.js.
▍Скорость
Одной из основных привлекательных особенностей Node.js является скорость. JavaScript-код, выполняемый в среде Node.js, может быть в два раза быстрее, чем код, написанный на компилируемых языках, вроде C или Java, и на порядки быстрее интерпретируемых языков наподобие Python или Ruby. Причиной подобного является неблокирующая архитектура платформы, а конкретные результаты зависят от используемых тестов производительности, но, в целом, Node.js — это очень быстрая платформа.
▍Простота
Платформа Node.js проста в освоении и использовании. На самом деле, она прямо-таки очень проста, особенно это заметно в сравнении с некоторыми другими серверными платформами.
▍JavaScript
В среде Node.js выполняется код, написанный на JavaScript. Это означает, что миллионы фронтенд-разработчиков, которые уже пользуются JavaScript в браузере, могут писать и серверный, и клиентский код на одном и том же языке программирования без необходимости изучать совершенно новый инструмент для перехода к серверной разработке.
В браузере и на сервере используются одинаковые концепции языка. Кроме того, в Node.js можно оперативно переходить на использование новых стандартов ECMAScript по мере их реализации на платформе. Для этого не нужно ждать до тех пор, пока пользователи обновят браузеры, так как Node.js — это серверная среда, которую полностью контролирует разработчик. В результате новые возможности языка оказываются доступными при установке поддерживающей их версии Node.js.
▍Движок V8
В основе Node.js, помимо других решений, лежит опенсорсный JavaScript-движок V8 от Google, применяемый в браузере Google Chrome и в других браузерах. Это означает, что Node.js пользуется наработками тысяч инженеров, которые сделали среду выполнения JavaScript Chrome невероятно быстрой и продолжают работать в направлении совершенствования V8.
▍Асинхронность
В традиционных языках программирования (C, Java, Python, PHP) все инструкции, по умолчанию, являются блокирующими, если только разработчик явным образом не позаботится об асинхронном выполнении кода. В результате если, например, в такой среде, произвести сетевой запрос для загрузки некоего JSON-кода, выполнение потока, из которого сделан запрос, будет приостановлено до тех пор, пока не завершится получение и обработка ответа.
JavaScript значительно упрощает написание асинхронного и неблокирующего кода с использованием единственного потока, функций обратного вызова (коллбэков) и подхода к разработке, основанной на событиях. Каждый раз, когда нам нужно выполнить тяжёлую операцию, мы передаём соответствующему механизму коллбэк, который будет вызван сразу после завершения этой операции. В результате, для того чтобы программа продолжила работу, ждать результатов выполнения подобных операций не нужно.
Подобный механизм возник в браузерах. Мы не можем позволить себе ждать, скажем, окончания выполнения AJAX-запроса, не имея при этом возможности реагировать на действия пользователя, например, на щелчки по кнопкам. Для того чтобы пользователям было удобно работать с веб-страницами, всё, и загрузка данных из сети, и обработка нажатия на кнопки, должно происходить одновременно, в режиме реального времени.
Если вы создавали когда-нибудь обработчик события нажатия на кнопку, то вы уже пользовались методиками асинхронного программирования.
Асинхронные механизмы позволяют единственному Node.js-серверу одновременно обрабатывать тысячи подключений, не нагружая при этом программиста задачами по управлению потоками и по организации параллельного выполнения кода. Подобные вещи часто являются источниками ошибок.
Node.js предоставляет разработчику неблокирующие базовые механизмы ввода вывода, и, в целом, библиотеки, использующиеся в среде Node.js, написаны с использованием неблокирующих парадигм. Это делает блокирующее поведение кода скорее исключением, чем нормой.
Когда Node.js нужно выполнить операцию ввода-вывода, вроде загрузки данных из сети, доступа к базе данных или к файловой системе, вместо того, чтобы заблокировать ожиданием результатов такой операции главный поток, Node.js инициирует её выполнение и продолжает заниматься другими делами до тех пор, пока результаты выполнения этой операции не будут получены.
▍Библиотеки
Благодаря простоте и удобству работы с менеджером пакетов для Node.js, который называется npm, экосистема Node.js прямо-таки процветает. Сейчас в реестре npm имеется более полумиллиона опенсорсных пакетов, которые может свободно использовать любой Node.js-разработчик.
Рассмотрев некоторые основные особенности платформы Node.js, опробуем её в действии. Начнём с установки.
Установка Node.js
Node.js можно устанавливать различными способами, которые мы сейчас рассмотрим.
Так, официальные установочные пакеты для всех основных платформ можно найти здесь.
Существует ещё один весьма удобный способ установки Node.js, который заключается в использовании менеджера пакетов, имеющегося в операционной системе. Например, менеджер пакетов macOS, который является фактическим стандартом в этой области, называется Homebrew. Если он в вашей системе есть, вы можете установить Node.js, выполнив эту команду в командной строке:
Список менеджеров пакетов для других операционных систем, в том числе — для Linux и Windows, можно найти здесь.
Популярным менеджером версий Node.js является nvm. Это средство позволяет удобно переключаться между различными версиями Node.js, с его помощью можно, например, установить и попробовать новую версию Node.js, после чего, при необходимости, вернуться на старую. Nvm пригодится и в ситуации, когда нужно испытать какой-нибудь код на старой версии Node.js.
Я посоветовал бы начинающим пользоваться официальными установщиками Node.js. Пользователям macOS я порекомендовал бы устанавливать Node.js с помощью Homebrew. Теперь, после того, как вы установили Node.js, пришло время написать «Hello World».
Первое Node.js-приложение
Самым распространённым примером первого приложения для Node.js можно назвать простой веб-сервер. Вот его код:
Для того чтобы запустить этот код, сохраните его в файле server.js и выполните в терминале такую команду:
Разберём этот пример.
Для начала, обратите внимание на то, что код содержит команду подключения модуля http.
Платформа Node.js является обладателем замечательного стандартного набора модулей, в который входят отлично проработанные механизмы для работы с сетью.
Метод createServer() объекта http создаёт новый HTTP-сервер и возвращает его.
Сервер настроен на прослушивание определённого порта на заданном хосте. Когда сервер будет готов, вызывается соответствующий коллбэк, сообщающий нам о том, что сервер работает.
Первый предоставляет в наше распоряжение сведения о запросе. В нашем простом примере этими данными мы не пользуемся, но, при необходимости, с помощью объекта req можно получить доступ к заголовкам запроса и к переданным в нём данным.
Второй нужен для формирования и отправки ответа на запрос.
Далее, мы устанавливаем заголовок Content-Type :
После этого мы завершаем подготовку ответа, добавляя его содержимое в качестве аргумента метода end() :
Мы уже говорили о том, что вокруг платформы Node.js сформировалась мощная экосистема. Обсудим теперь некоторые популярные фреймворки и вспомогательные инструменты для Node.js.
Фреймворки и вспомогательные инструменты для Node.js
Node.js — это низкоуровневая платформа. Для того чтобы упростить разработку для неё и облегчить жизнь программистам, было создано огромное количество библиотек. Некоторые из них со временем стали весьма популярными. Вот небольшой список библиотек, которые я считаю отлично сделанными и достойными изучения:
Краткая история Node.js
В этом году Node.js исполнилось уже 9 лет. Это, конечно, не так уж и много, если сравнить этот возраст с возрастом JavaScript, которому уже 23 года, или с 25-летним возрастом веба, существующем в таком виде, в котором мы его знаем, если считать от появления браузера Mosaic.
9 лет — это маленький срок для технологии, но сейчас возникает такое ощущение, что платформа Node.js существовала всегда.
Я начал работу с Node.js с ранних версий платформы, когда ей было ещё только 2 года. Даже тогда, несмотря на то, что информации о Node.js было не так уж и много, уже можно было почувствовать, что Node.js — это очень серьёзно.
Теперь поговорим о технологиях, лежащих в основе Node.js и кратко рассмотрим основные события, связанные с этой платформой.
Итак, JavaScript — это язык программирования, который был создан в Netscape как скриптовый язык, предназначенный для управления веб-страницами в браузере Netscape Navigator.