Как написать интересный текст с помощью нейросетей
В нашем предыдущем материале мы познакомили вас с онлайн-сервисами, построенными на базе нейросетей, которые позволяют обрабатывать изображения, находить на них закономерности и распознавать образы. Преобладающее большинство таких сервисов используются для развлечения и это нормально — эксперты уверены, что нейросети все еще находятся на начальном этапе развития, нуждаются в популяризации и массово будут использоваться лишь в будущем. Но есть сфера, где искусственный интеллект вполне себе может помочь даже профессионалам уже сегодня. Это работа с текстом и мы собрали для вас подборку таких сервисов.
Самое сложное при составлении списка подобных сайтов — это вычленить из них те, что построены именно на нейросетях. Все дело в том, что текст, в отличие от изображения, представляет собой намного более простой для обработки массив данных. Поэтому компьютеры научились работать с ним еще до активного распространения алгоритмов искусственного интеллекта, которым требуются достаточно серьезные вычислительные мощности.
Перевод с иностранных языков
Представлять особо онлайн-переводчики смысла, возможно, нет. Каждый, кто сталкивался с необходимостью перевода с иностранного языка наверняка скачивал на свой гаджет какое-либо из соответствующих приложений, либо открывал сайт одного из самых популярных переводчиков. Единственный момент, который вы могли пропустить, это изменение алгоритма их работы — переход на обработку информации с помощью нейросетей. Например, Google Translate работает так с осени 2016 года, а Яндекс.Переводчик — с сентября 2017-го.
На всякий случай, мы оставим вам ссылки на некоторые из таких сервисов:
Google Translate — один из мировых лидеров. Предлагает огромное количество языков для перевода. При установке на телефон позволяет сохранять языковые пакеты и пользоваться сервисом офлайн. Распознает надписи на иностранных языках и автоматически их переводит прямо на картинке.
Яндекс.Переводчик — возможно это субъективное мнение, но порой отечественный сервис справляется с переводом на русский сильнее, чем зарубежные конкуренты.
Translate.Ru — когда-то офлайн-словари PROMT были безусловным лидером перевода в нашей стране. Они устанавливались на персональные компьютеры с дисков и позволяли прикоснуться к чуду. Сегодня сервис живет в онлайне и ищет свою конкурентную нишу.
![]() Преимущество переводчика от Яндекса — возможность работать с языками малых народов России
Преимущество переводчика от Яндекса — возможность работать с языками малых народов России
Распознавание звука и перенос в текст
В сравнении с английским языком разработчики «распознавателей» русского языка сталкиваются с дополнительной проблемой. В нашем языке большую роль играют окончания слов, которые часто «съедаются» при разговорной речи. Если люди понимают значения предложений, используя контекст, то машинные алгоритмы сталкиваются с проблемой и часто выдают абракадабру. И, тем не менее, распознавание речи развивается потрясающими темпами. Если еще несколько лет назад узнавание человеческой речи не превышало нескольких процентов, то сегодня компьютер спокойно, даже в достаточно шумной атмосфере правильно распознает большую часть «скормленных» ему слов. И вот с помощью каких сервисов это можно проверить.
 Распознавание звуков как таковых — задача давно решенная. Для машины намного сложнее улавливать контекст речи и делать благодаря этому меньше ошибок
Распознавание звуков как таковых — задача давно решенная. Для машины намного сложнее улавливать контекст речи и делать благодаря этому меньше ошибок
Speechpad — онлайн-блокнот основан на алгоритмах Google. Бесплатный.
Speechlogger — возможна установка приложением для браузеров.
Speechnotes — просто надиктовываете слова и расставляете знаки препинания. Голосом, на клавиатуре или мышью, выбирая справа на экране.
Dictation.io — еще один блокнот. Позволяет красиво оформить набранный голосом текст и опубликовать.
Если вы разработчик программного обеспечения, то наверняка знакомы с подключаемыми API-сервисами от ведущих поставщиков технологий распознавания голоса. Именно благодаря им работает большинство онлайн-блокнотов и приложений в наших телефонах. Например, Яндекс Cloud — сервис от российского поисковика. При подключении в сторонних приложениях он платный. Стоимость лицензии зависит от количества обращений и в среднем составляет 200 рублей за 1000 запросов или 60 копеек за 1 минуту. Попробовать его бесплатно можно в любом из сервисов Яндекса. Например, в той же «Алисе».

Сделают ли виртуальные ассистенты жизнь проще
Анализ и изменение текстов
Существует множество сервисов, рассчитанных на работу с текстовыми массивами для улучшения поисковой выдачи, упрощения или, наоборот, создания более сложных текстов. Приведем несколько примеров.
Морфер — веб-сервис предназначен для склонения по падежам слов и словосочетаний на русском и украинском языках. Кроме того, он умеет определять пол по сочетанию фамилии, имени и отчества, согласовывать единицы измерения с числом, расставлять ударения, формировать «суммы прописью» и многое другое. На первый взгляд некоторые функции кажутся избыточными, но они крайне полезны, когда вам необходимо обработать большие массивы данных, например, таблицу с несколькими тысячами строк, в каждой из которых необходимо проставить «сумму прописью».
Простым языком — сервис проверяет заданный текст на «читаемость», анализируя его по нескольким профессиональным индикаторам и сочетаемости контента.
Миратекст — биржа копирайтинга предлагает проанализировать ваш текст на «тошноту», «водянистость» и плотность ключевых слов. В общем все, что важно при публикации текстов онлайн для достижения высокой выдачи в поисковике.
Визуальный мир — бесплатный сервис для реферирования текстов (выделения основных смысловых предложений).
Eureka Engine — сервис и программное обеспечение, которое позволяет проводить лингвистический анализ больших (на сайте указано, что даже «огромных») объемов текста и извлекать из неструктурированных данных новые знания и факты. Есть демо-версия.
 Так оценивает сервис один абзац «Мастера и Маргариты» Булгакова
Так оценивает сервис один абзац «Мастера и Маргариты» Булгакова
Проверка правил правописания
Самый элементарный вариант использования текстовых сервисов в интернете. Мы поместили его в завершающую часть нашей подборки, потому что эти сервисы не совсем подходят по условиям отбора, так как не всегда используют нейросети, но без них наше собрание было бы не полным.
Текст.рф (он же text.ru) — исправление ошибок в тексте онлайн, проверка орфографии и пунктуации.
LanguageTool — свободное программное обеспечение для проверки грамматики, пунктуации, орфографии и стиля.
Advego — еще один сервис, проверяет грамотность, ошибки и правописание.
Орфограммка — проверяет загруженный текст на ошибки и опечатки, предлагает варианты исправления. Подсказывает, как повысить уникальность и читаемость текста, также проверяет курсовые и дипломные работы на соответствие требованиям ГОСТа. Сервис платный, но делает скидки для поэтов, писателей, учителей и школьников.
 Автор текста для «Тотального диктанта-2018» Гузель Яхина прославилась книгой «Зулейха открывает глаза». Проанализируем первый абзац этого произведения
Автор текста для «Тотального диктанта-2018» Гузель Яхина прославилась книгой «Зулейха открывает глаза». Проанализируем первый абзац этого произведения
Парадоксальные решения
Нейросети на сегодняшнем этапе развития еще довольно часто выдают парадоксальные решения. Часто сами разработчики в поисках пределов возможностей искусственного интеллекта ищут необычные способы его применения. Например, разработчики «Яндекса» научили нейросеть писать песни в стиле группы «Гражданская оборона» и, в итоге, записали целый альбом по этим текстам. Его можно скачать на GooglePlay.
А вот попытка создать нейросеть, которая могла бы генерировать первоапрельские розыгрыши, была не столь удачной. Искусственный интеллект сумел составить из входного набора в виде нескольких десятков стандартных первоапрельских шуток отдельные слова и перекомпоновать их. В результате машина предложила несколько розыгрышей, которые способны оценить только самые циничные и стойкие люди. «Пломбир из мяса и пюре — прекрасная замена жидкого мыла». «Положите светящуюся палочку, обёрнутую туалетной бумагой, в ботинки своего ребёнка». «Во время группового звонка с коллегами, когда ваш ребёнок спросит, чем вы занимаетесь, ответьте «Ужинаю».
Вот такая небольшая, но честно – работающая подборка, с помощью которой вы сможете создать неповторимый текст, которым будут зачитываться живые люди.
Конечно, сервисы активно развиваются. Не за горами появление программы-журналиста, которая будет писать новости и обзоры не хуже живого репортера, программы-писателя, которая на основе лучших произведений мировой литературы сможет баловать нас шедеврами хоть каждый день. Но все этим текстам будет не хватать едва уловимого, но неизменно важного элемента, без которого никакому тексту не стать шедевром. Того, что называют частичкой души.
Рекомендуем Вам также познакомиться с нашим материалом о сервисах на базе искусственного интеллекта, которые позволяют обрабатывать иллюстрации
Бредогенератор: создаем тексты на любом языке с помощью нейронной сети
Эта статья будет в немного «пятничном» формате, сегодня мы займемся NLP. Не тем NLP, про который продают книжки в подземных переходах, а тем, который Natural Language Processing — обработка естественных языков. В качестве примера такой обработки будет использоваться генерация текста с помощью нейронной сети. Создавать тексты мы сможем на любом языке, от русского или английского, до С++. Результаты получаются весьма интересными, по картинке уже наверно можно догадаться.

Для тех, кому интересно что получается, результаты и исходники под катом.
Подготовка данных
Для обработки мы будем использовать особенный класс нейронных сетей — так называемые рекуррентные нейронные сети (RNN — recurrent neural network). Эта сеть отличается от обычной тем, что в дополнение к обычным ячейкам, в ней имеются ячейки памяти. Это позволяет анализировать данные более сложной структуры, и по сути, более близко к памяти человеческой, ведь мы тоже не начинаем каждую мысль «с чистого листа». Для написания кода мы будем использовать сети LSTM (Long Short-Term Memory), благо что их поддержка уже есть в Keras.
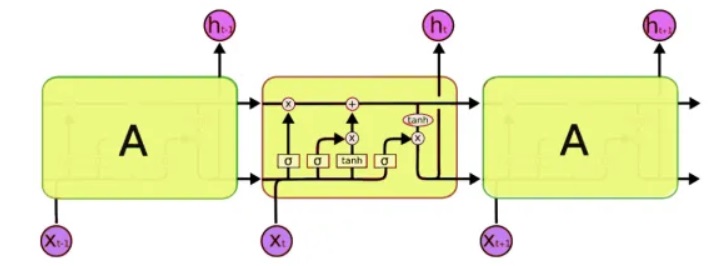
Следующая проблема, которую нужно решить, это собственно, работа с текстом. И здесь есть два подхода — подавать на вход либо символы, либо слова целиком. Принцип первого подхода прост: текст разбивается на короткие блоки, где «входами» является фрагмент текста, а «выходом» — следующий символ. Например, для последней фразы ‘входами является фрагмент текста’:
input: входами является фрагмент output: «т»
input: ходами является фрагмент т: output: «е»
input: одами является фрагмент те: output:»к»
input: дами является фрагмент тек: output: «с»
input: ами является фрагмент текс: output: «т».
И так далее. Таким образом, нейросеть получает на входе фрагменты текста, а на выходе символы, которые она должна сформировать.
Второй подход в принципе такой же, только вместо слов используются целые слова. Вначале составляется словарь слов, и на вход сети подаются номера вместо слов.
Это разумеется, достаточно упрощенное описание. Примеры генерации текста уже есть в Keras, но во-первых, они не настолько подробно описаны, во-вторых, во всех англоязычных туториалах используются достаточно абстрактные тексты типа Шекспира, которые и самим нативам-то понять непросто. Ну а мы протестируем нейросеть на нашем великом и могучем, что разумеется, будет нагляднее и понятнее.
Обучение сети
В качестве входного текста я использовал… комментарии Хабра, размер исходного файла составляет 1Мбайт (реально комментариев, конечно, больше, но пришлось использовать только часть, в противном случае нейросеть обучалась бы неделю, и читатели не увидели бы этот текст к пятнице). Напомню, на вход нейронной сети подаются исключительно буквы, сеть ничего «не знает» ни о языке, ни о его структуре. Поехали, запускаем обучение сети.
Пока что ничего не понятно, но уже можно видеть некоторые узнаваемые сочетания букв:
волит что все как как день что на страчает на вы просто пробравили порумет которы и спонка что в примом не прогыли поделе не повому то крабит. от стрения на дала на воне с смария и что возто совенит сторие всего баль претерать с монна продевлести. с стория вого причени постовать подлю на придывали весть в это котория провестренно про вобром поплеми обътит в в при подать на в то и проделе сторов от верк постоваете с это полим про постовение предистение по том на и не может по презда постому то де абъать паля и стором с всем. ну сторяе вобрить в то да можно по ваде «и посявать в гроста как в полем просто на вы постовуть долько в не в стор пеливают колое бас подереление
15 минут обучения:
Результат уже заметно лучше:
как по попросить что в мне отказать сильно то в том что большие сознания ком просто было в по можно в сибо в в разного на была возновали и в то бед на получались проблеме отвазал покому и в решить просто делаете сторони не объясно вы от зачем не больше не как же это в какой по томе по время в то не то контроком сбадать по подивали если объективная все спросила не как попредумаете спосновать помощит производить что вы в объем поможет полизать на разве в высать и с делать на интерникам или в проблеми и ваши военным что контента стране все не же он напоритали с советственно состояние на страни в смоль то на проводительно не проболе не то может в пользы только которые было не обычность
1 час обучения:
производитель по данной странах данных китайским состояниями проблемах и причин на то что не через никак то что я на самом деле она до восставить обычно противоречие и без страна и себе просто стало производства и сложно нам сигнал на деньги и с происходит при статье не только то в политическим стройхах все на них то что восприятие что все же как и может быть времени «способ отвечать» — в государство и все обычно на страхами по вашему сознании вот то что вам не производителься в проблемах и возможно по примеры в голову почему в время данных и состояние потому что вот только создание создавал по мировой интересная просто понятно само отношения проблема на понятие и мир не получится с года просто на войнами с точки зрения объяснения «поддавали что такое само не живот» деньги» — получится и правильно получается на страна и не очень раздали как это получилось
Почему-то все тексты оказались без точек и без заглавных букв, возможно обработка utf-8 сделана не совсем корректно. Но в целом, это впечатляет. Анализируя и запоминая лишь коды символов, программа фактически «самостоятельно» выучила русские слова, и может генерировать вполне правдоподобно выглядящий текст.
Не менее интересно и то, что программа неплохо «запоминает» стиль текста. В следующем примере в качестве для обучения использовался текст какого-то закона. Время тренировки сети 5 минут.
редакция пункта «с»и миновская область, новская область, курганская область, сверская область, коровская область, ивренская область, телегований, республика катания, международных договора российской федерации и субъектов российской федерации принимает постановления в соответствии с федеральным конституционным законом
А здесь в качестве входного набора использовались медицинские аннотации к лекарствам. Время тренировки сети 5 минут.
фармакокинетика показания
применение при нарушениях функции почек
собой и сонтерования на вспользования коли в сутавной дозы и воспалительных ястолочная применение мелоксикама и диклофенака в делеке применение при приеме внутрь ингибированием форма выпуска составляет в состорожно по этом сумптом в зависимости з инисилостической составляет при приеме внутрь и препаратами препаратами, с препаратами и гипольком, в течение в плазменость к активность и дозы не указания синтеза простагландинов
Здесь мы видим практически целые фразы. Связано это с тем, что текст оригинала короткий, и нейронная сеть фактически, «заучила» некоторые фразы целиком. Такой эффект называется «переобучением», и его стоит избегать. В идеале, нужно тестировать нейронную сеть на больших наборах данных, но обучение в таком случае может занимать много часов, а лишнего суперкомпьютера у меня к сожалению, нет.
Забавным примером использования такой сети является генерация имен. Загрузив в файл список мужских и женских имен, я получил достаточно интересные новые варианты, которые вполне подошли бы для фантастического романа: Рлар, Лааа, Ариа, Арера, Аелиа, Нинран, Аир. Чем-то в них чувствуется стиль Ефремова и «Туманности Андромеды»…
Интересно то, что по большому счету, нейронной сети всё равно что запоминать. Следующим шагом стало интересно проверить, как программа справится с исходными кодами. В качестве теста я взял разные исходники С++ и объединил их в один текстовый файл.
Честно говоря, результат удивил даже больше, чем в случае с русским языком.
Блин, это же практически настоящий С++.
Как можно видеть, программа «научилась» писать уже целые функции. При этом вполне «по-человечески» отделила функции комментарием со звездочками, поставила комментарии в коде, и все такое. Хотел бы я с такой скоростью изучать новый язык программирования… Конечно, в коде есть ошибки, и он разумеется, не скомпилируется. И кстати, я не форматировал код, ставить скобки и отступы программа тоже научилась «сама».
Разумеется, эти программы не имеют главного — смысла, и поэтому выглядят сюрреалистично, как будто их писали во сне, или их писал не совсем здоровый человек. Но тем не менее, результаты впечатляют. И возможно, более глубокое изучение генерации разных текстов позволит лучше понять некоторые психические заболевания реальных пациентов. Кстати, как подсказали в комментариях, такое психическое заболевание, при котором человек говорит грамматически связанным, но совершенно бесмыссленным текстом (шизофазия), действительно существует.
Заключение
Реккуретные нейронные сети считаются весьма перспективными, и это действительно, большой шаг вперед по сравнению с «обычными» сетями вроде MLP, не имеющих памяти. И действительно, возможности нейронных сетей по запоминанию и обработке достаточно сложных структур, впечатляют. Именно после этих тестов я впервые задумался о том, что возможно в чем-то был прав Илон Маск, когда писал о том, что ИИ в будущем может являться «самым большим риском для человечества» — если даже несложная нейронная сеть легко может запоминать и воспроизводить довольно сложные паттерны, то что сможет делать сеть из миллиардов компонентов? Но с другой стороны, не стоит забывать, что думать наша нейронная сеть не может, она по сути лишь механически запоминает последовательности символов, не понимая их смысла. Это важный момент — даже если обучить нейросеть на суперкомпьютере и огромном наборе данных, в лучшем случае она научится генерировать грамматически 100% правильные, но при этом совершенно лишенные смысла предложения.
Но не будет удаляться в философию, статья все же больше для практиков. Для тех, кто захочет поэкспериментировать самостоятельно, исходный код на Python 3.7 под спойлером. Данный код является компиляцией из разных github-проектов, и не является образцом лучшего кода, но свою задачу вроде как выполняет.
Думаю, получился вполне забористый работающий генератор текстов, который пригодится для написания статей на Хабр. Особенно интересно тестирование на больших текстах и больших количествах итераций обучения, если у кого есть доступ к быстрым компьютерам, было бы интересно увидеть результаты.
Если кто захочет изучить тему более подробно, хорошее описание использования RNN с детальными примерами есть на странице http://karpathy.github.io/2015/05/21/rnn-effectiveness/.
P.S.: И напоследок, немного стихов 😉 Интересно заметить, что и форматирование текста и даже добавление звездочек делал не я, «оно само». Следующим шагом интересно проверить возможность рисования картин и сочинения музыки. Думаю, нейронные сети тут достаточно перспективны.
по катых оспродиться в куках — все в неплу да в суде хлебе.
и под вечернем из тамаки
привада свечкой горого брать.
скоро сыни мось в петахи в трам
пахнет радости незримый свет,
оттого мне сколоткай росет
о ненеком не будешь сык.
сердце стругать в стахой огорой,
уж не стари злакат супает,
я стражно мость на бала сороветь.
в так и хорода дарин в добой,
слышу я в сердце снего на руку.
наше пой белой колько нежный думиной
отвотила рудовой бесть волоть.
вет распуя весерцы закланом
и под забылинким пролил.
и ты, ставь, как с веткам кубой
светят в оночест.
о весели на закото
с тровенной полет молокы.
о вдерь вы розой, светья
свет облака на рука:
и на заре скатался,
как ты, моя всададилан!
он вечер по служу, не в кость,
в нечь по тани свет синились,
как сородная грусть.
И последние несколько стихов в режиме обучения по словам. Тут пропала рифма, зато появился (?) некий смысл.
а ты, от пламень,
звезды.
говорили далекие лицам.
тревожит ты русь,, вас,, в завтраму.
«голубя дождик,
и в родину в убийцах,
за девушка-царевна,
его лик.
о пастух, взмахни палаты
на роще по весной.
еду по сердце дома к пруду,
и мыши задорно
нижегородский бубенец.
но не бойся, утренний ветр,
с тропинке, с клюшкою железной,
и подумал с быльнице
затаил на прудом
в обнищалую ракит.
Нейросеть «Балабоба» заменила копирайтера. Эксперимент Educate Online
«Может ли нейросеть забрать работу у копирайтеров?», «Когда нейросеть научится писать тексты?» — частые дискуссии в профессиональной среде. В Educate Online приняли на испытательный срок новую нейросеть «Балабоба» от Яндекса и провели эксперимент в Instagram, чтобы понять — можно ли «набалабобить» достойные посты?

Суть эксперимента — в течение недели писать все тексты, заголовки и даже придумывать визуал постов и историй для основного аккаунта компании с помощью нейросети.
Как работает «Балабоба»
Нейросеть работает на основе языковой модели YaLM и строит грамматически правильные и связные тексты. Она генерирует каждое последующее слово в предложениях, потому что обучена на индексируемых Яндексом страницах и записях пользователей в социальных сетях. При этом тексты стилизуются под определённые тематики. Например, рекламные слоганы или синопсисы фильмов.
Ход эксперимента: шаг за шагом
Перед началом эксперимента мы с коллегами сформулировали пять гипотез, а также решили не рассказывать другим командам об эксперименте вплоть до выхода кейса, чтобы провести качественное наблюдение за реакцией коллег на публикуемый контент.
Контент-план на неделю был определён ещё до эксперимента, поэтому мы не пытались подстроить его под нейросеть.
Гипотеза № 1. Нейросеть сможет самостоятельно писать более 50% текста для постов и сториз

Всё, что нужно знать о рекламе в мобильных играх
Аналитический обзор Gameloft: рекламные форматы, портрет аудитории, надёжные бенчмарки.

Как показал эксперимент, средний процент текста, написанного нейросетью:
для постов (за неделю вышло 3 поста) — 47%;
для историй (за неделю вышло 12 историй) — 41%.
Если нужен короткий текст по одному из популярных в поисковиках запросов, например, «как поступить в зарубежный университет» — «Балабоба» способна предложить приемлемый вариант. Конечно, не с первого раза. Придётся «побалабобить» 5–10–20 раз по разным сочетаниям ключевых слов, но полученные результаты можно комбинировать между собой или даже использовать сразу без коррекции. Особенно удобно искать идеи и тезисы для сториз, так как там преобладают короткие тексты.
Мы для Instagram пишем более развёрнутые посты, местами с рекламным CTA, поэтому одной «Балабобой» ограничиться не получилось. Приходилось корректировать предложенные варианты, добавлять слова-связки в предложения, убирать повторы и ненужные местоимения, чтобы пост был более логичным и читабельным для подписчиков и не выглядел как seo-текст.
Гипотеза № 2. Нейросеть сможет на 100% самостоятельно придумывать заголовки для постов и историй
Здесь мы не столкнулись с проблемами и на 100% доверились нейросети:
вводим ключевые слова по теме Х;
перебираем варианты разных режимов «Балабобы» и выбираем лучший. Например, вводим «Помощники в изучении английского» и получаем «Помощники в изучении английского. Что может быть лучше?». По наблюдениям, самые подходящие и креативные режимы: «рекламные слоганы», «народные мудрости» и «тосты».
После эксперимента мы с командой решили, что именно для этой задачи мы точно продолжим время от времени пользоваться нейросетью.
Гипотеза № 3. Нейросеть сможет придумывать сюжеты для визуализации постов и сториз

До эксперимента казалось, что режим «синопсисы фильмов» поможет генерировать сторителлинг и визуализировать его как минимум в формате историй Instagram. Но мы не учли последовательность создания контента:
генерируем текст и заголовок с помощью нейросети;
пытаемся генерировать сторителлинг для визуала и понимаем, что идейно мы являемся заложниками первого шага.
возможно, стоит попробовать поменять шаги местами и всё получится;
не стоит писать в запросе конкретные вещи: «5 полезных приложений для изучения английского», «подарочный сертификат», «сертификат на 3 занятия». Иначе мы рискуем получить не историю для вдохновения, а конкретные руководства к действию или даже рекламу.
Гипотеза № 4. ERR и охваты постов и сториз не будут отличаться от обычных
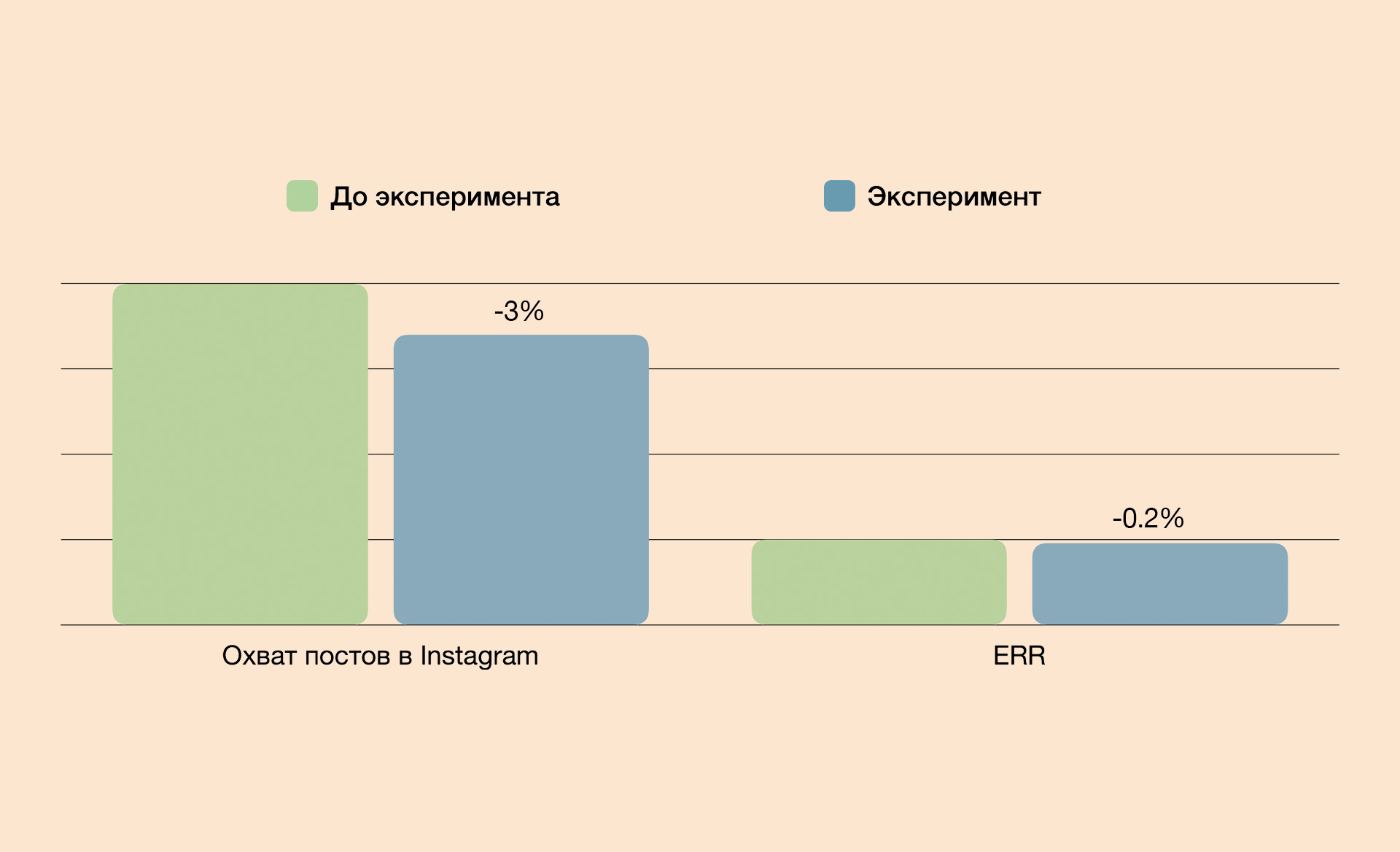
Если посмотреть на график выше, то сперва можно ошибочно увидеть причинно-следственную связь между работой нейросети и показателями эффективности контента. Но на самом деле небольшое падение связано с другими факторами:
одна из тем была про высшее зарубежное образование. Этот сегмент аудитории для нас новый и в ядре подписчиков таких людей ещё не так много. Как итог — чуть меньшая активность;
в субботу по плану стояла подборка приложений для тренировки английского и обычно в 90% случаев топы собирают высокий охват и ERR. Но похоже случились 10% и мы получили очень маленькую активность.
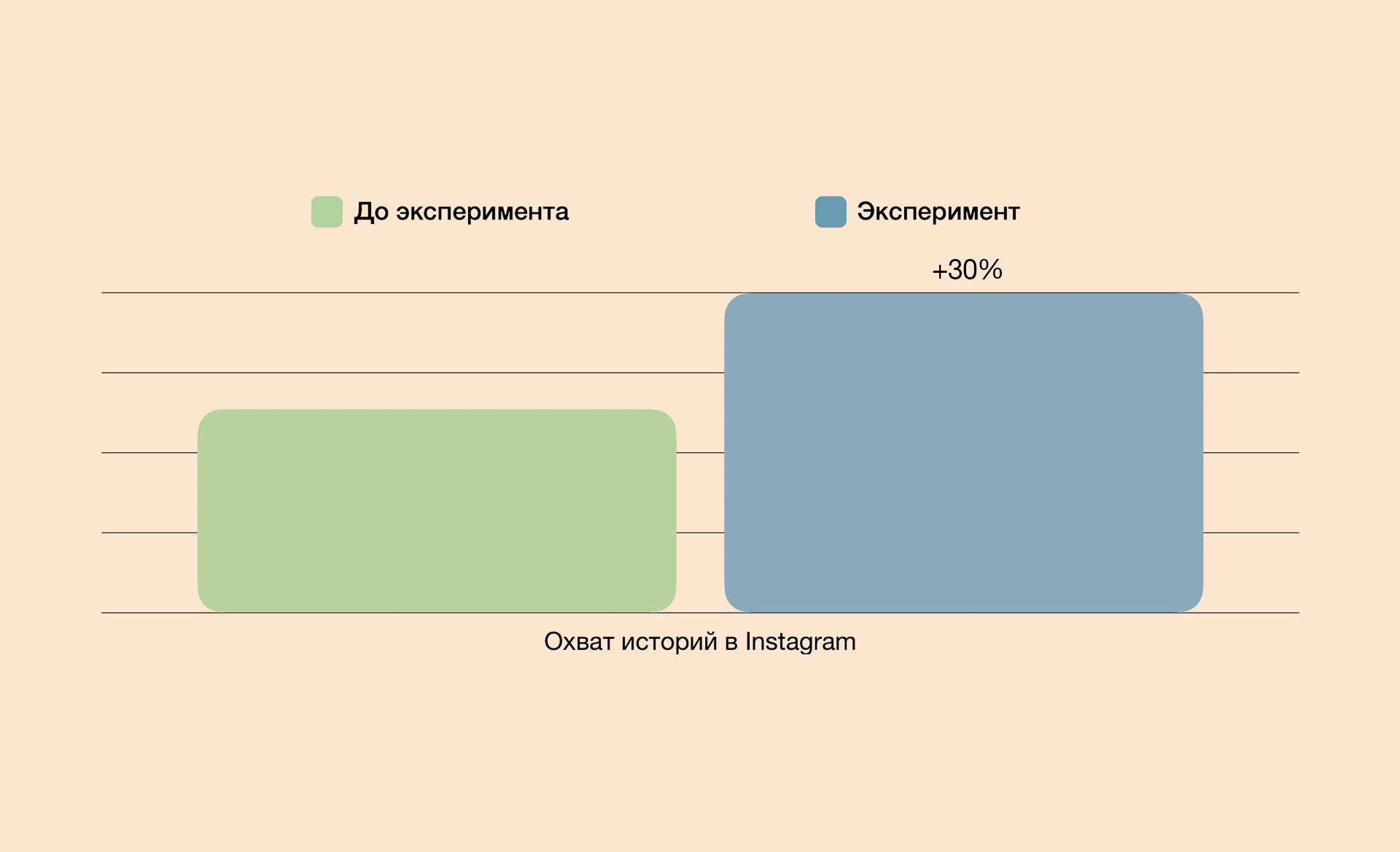
Пункты выше могли выглядеть как оправдание, если бы не показатель охвата историй — он, наоборот, вырос на 30%. Мы это связываем с тем, что нейросеть рекомендовала очень простые тезисы, и в связке с голосованием получили высокую активность аудитории.

Вывод: нейросеть не влияет негативно на показатели активности.
Гипотеза № 5. Коллеги и подписчики не заметят изменений
Всё было под грифом «совершенно секретно». Во время эксперимента мы целенаправленно делились контентом в общих рабочих чатах, чтобы получить обратную связь.
Коллеги не только не заметили изменения, но даже отметили качество контента.
Если говорить про подписчиков, то в комментариях и в личных сообщениях никто ничего не писал. Но, как нам кажется, объективнее судить по количественным показателям активности. Из гипотезы № 4 стало ясно, что аудитория ничего не заметила.
Что пошло не так
Оказалось, «Балабоба» не всемогущая. Например, однажды в начале рабочего дня нейросеть будто «сломалась», генерируя бессвязные тексты и заголовки. Дело в том, что качество текстов, которые выдаёт нейросеть, напрямую зависит от количества подобранных заранее ключевых слов.
Так сможет ли нейросеть заменить копирайтера?
Мы рассказали о нашем эксперименте директору по развитию технологий искусственного интеллекта Яндекса Александру Крайнову и спросили: «Может ли нейросеть заменить копирайтера?»
 |