Учимся писать парсер сайта своими руками
Сегодня я приведу вам в пример, который возможно понадобиться начинающим парсерам и возможно вы найдете в нем ценную информацию. В комментариях очень хотелось бы увидеть возможные изменения для упрощения задачи, так что всегда рад услышать ваши мнения.
Передо мной стояла задача заполнить интернет магазин товарами в количестве свыше 50 тыс наименований. Оригиналы товаров лежали на сайтах поставщиков.
Особо заморачиваться с кодом и решением я не стал, поэтому сделал все максимально просто и быстро.
Прикрепленные файлы буду выкладывать на проекте моих друзей и партнеров 2file.ru Будьте уверены что все ссылки всегда будут действующими и вы всегда сможете скачать любой файл из данной инструкции. +размер файлов не ограничен, нет времени ожидания и нет рекламмы.
Ок, теперь у нас стоит апач, есть скачанный сайт. Далее для удобства я перенес все скачанные странички в папку xampp для дальнейшей работы с ними. Чтобы не усложнять код, я переименовал все страницы в порядковые номера чтобы получилось 1.html, 2.html… и так далее. Сделать это очень просто. Например через total commender в меню файлы-групповое переименование. Далее в папке с переименованными страницами я создал index.php файл. Теперь начнем разбираться в коде:
Первой строчкой я указываю на открытие 132.html, в котором будет осуществляться выборка данных.
Открыв любую скачанную страницу, мы видим что интересующая нас информация находится между тегами.
Один из моих примеров это
Далее осуществляется вывод полученных данных на экран и спуск на строчку вниз br.
Для выдирания нескольких результатов из одной страницы, можно использовать код на подобии:
Должно получится что-то вроде (значение1, значение2, значение3 <br>)
Теперь немного дополним наш код чтобы прогнать все наши скачанные страницы. Решил сделать с помощью цикла и получилось что-то вроде этого:
Отлично, теперь мы видим что-то вроде этого:
значение#значение#значение
значение#значение#значение
Для удобства дальнейшей работы я использовал #. Теперь копируем все что получилось, загоняем в excel, нажимаем данные-текст по столбцам и ставим # в качестве разделителя столбцов. Отлично, мы получили таблицу с результатами нашего парсинга. УРА
Дальнейшая работа зависит от вашей фантазии и цели. Спасибо за внимания, надеюсь на инвайт.
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
И сделаем наш первый get-запрос.
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Получаем такой код.
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
Пишем простой парсер web страниц
Здравствуйте. Меня зовут Сережа. Я хочу рассказать о том, как я писал простейшего вэб паука. 
Поскольку это некоммерческий проект, созданный исключительно на моём энтузиазме, при работе я руководствовался следующим:
1. Минимум необходимых функций (сканирование web, сохранение необходимого в БД, простенький UI для доступа)
2. 0 финансовых затрат:
— В качестве сервера использую нетбук, который покупал в свое время для учебы acer aspare ONE KAV60, весьма бюджетный даже на момент покупки (2008 год), сейчас его процессора atom в 1600 МГц не хватает даже для нормальной работы в MS OFFICE
— Интернет — проводной домашний. Благо IP уже пол года не менялся, не пришлось заказывать статический
3. Минимум временых затрат. Проект делался после работы и дачи.
В качестве ПО использованы:

Наш робот будет через определённые промежутки времени сканировать ресурс в поиске новых комментариев, которые будет вносить в БД, дабы всегда можно было посмотреть, что не понравилось модератору.
Нам потребуются следующие модули:
В основе нашего робота будет 2 функции:
Этой функцией мы запрашиваем главную страницу ресурса и ищем элементы с классом «.to-comments». В них хранятся ссылки на страницы с комментариями. Поскольку эти элементы идут впаре, нам нужен только каждый второй.
В данной функции нам очень помогает модуль jsdom. Он преобразует html код в DOM дерево, в котором мы легко можем найти нужный элемент.
Как мы видим, эта функция вызывает get_comments()
Здесь мы также пробегаемся по дереву, ищем элементы с классом «comment», выделяем из них нужные элементы: id комментария, автора, отсеиваем удаленные комменты, убираем спецсимволы, немного переделываем код (убираем превьюшки) и заносим всё это в БД. В таблице comments поле id уникально, поэтому mySQL сама следит, чтобы не было дублированных комментариев.
Нам осталось завести таймер, пробуждающий робота каждые 5 минут. В node.JS это можно реализовать при помощи модуля croneJob — аналог планировщика crone в linux.
На этом пока всё. Наш паук научился лазить по ресурсу и сохранять комментарии. Если хотите могу написать статью, про вэб интерфейс к этому роботу или про плагин хрома для этого робота.
API для всех и каждого: создаем мощный парсер веб-сайтов без единой строки кода

Содержание статьи
Часто возникает задача периодически парсить какой-нибудь сайт на наличие новой информации. Например, если ты пишешь агрегатор контента с новостного сайта или форума, в котором нет поддержки RSS. Проще всего написать скрепер на Питоне и разобрать полученный HTML через beautifulsoup или регулярками. Однако есть более элегантный способ — самому сделать недостающие API для сайта и получать ответы в привычном JSON, как будто бы у сайта есть нативный API.
Не будем далеко ходить за примером и напишем парсер контента с «Хакера». Как ты знаешь, сайт нашего журнала сейчас не предоставляет никакого API для программного получения статей, кроме RSS. Однако RSS не всегда удобен, да и выдает далеко не всю нужную информацию. Исправим это!
Постановка задачи
Ответ должен быть таким:
Фреймворк для веба
WrapAPI — это довольно новый (пара месяцев от роду) сервис для построения мощных кастомных парсеров веба и предоставления к ним доступа по API. Не пугайся, если ничего не понял, сейчас поясню на пальцах. Работает так:
Немного о приватности запросов
Ты наверняка уже задумался о том, насколько безопасно использовать чужой сервис и передавать ему параметры своих запросов с приватными данными. Тем более что по умолчанию для каждого нового API-проекта будет создаваться публичный репозиторий и запускать API из него сможет любой желающий. Не все так плохо:
Приготовления
Несколько простых шагов перед началом.
Это расширение нам понадобится для того, чтобы перехватывать запросы, которые мы собираемся эмулировать, и быстро направлять их в WrapAPI для дальнейшей работы. По логике работы это расширение очень похоже на связку Burp Proxy + Burp Intruder.
 Для работы с WrapAPI нужно повторно авторизоваться еще и в расширении в консоли разработчика Chrome
Для работы с WrapAPI нужно повторно авторизоваться еще и в расширении в консоли разработчика Chrome
Xakep #210. Краткий экскурс в Ethereum
Отлавливаем запросы
Теперь нужно указать WrapAPI, какой HTTP-запрос мы будем использовать для построения нашего API. Идем на сайт «Хакера» и открываем консоль разработчика, переключившись на вкладку WrapAPI.
Для получения постов я предлагаю использовать запрос пагинации, он доступен без авторизации и может отдавать по десять постов для любой страницы «Хакера», возвращая HTML в объекте JSON (см. ниже).
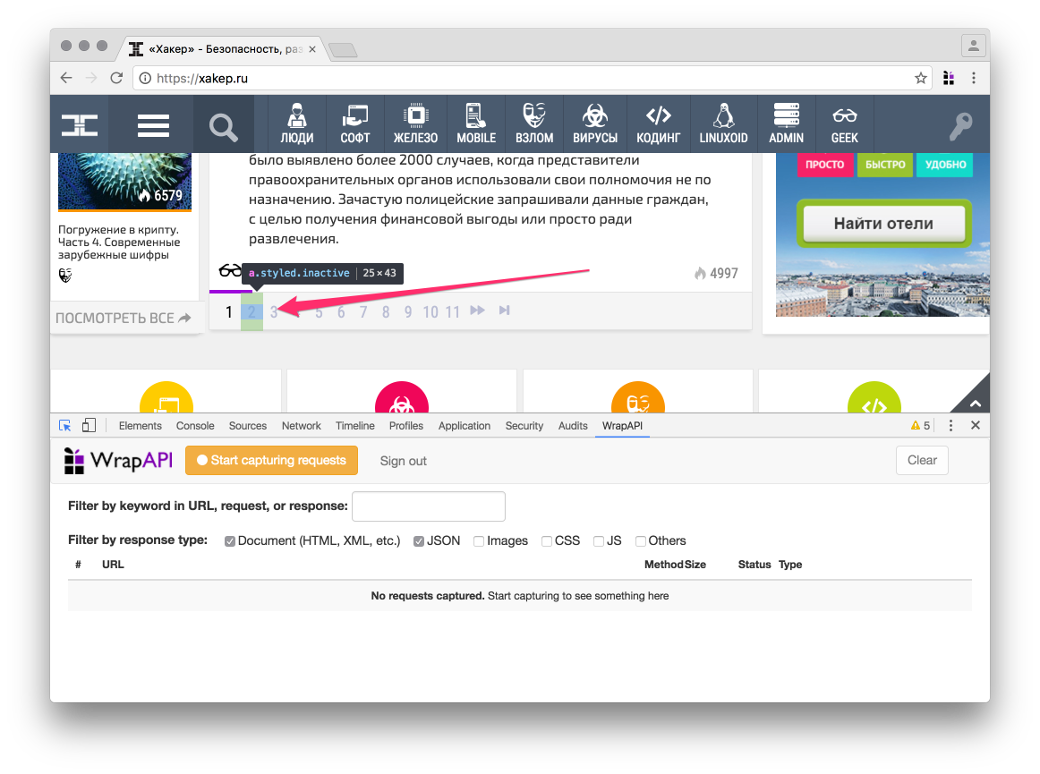 Запросы, которые генерятся по нажатию на ссылки пагинатора, будем использовать как образец
Запросы, которые генерятся по нажатию на ссылки пагинатора, будем использовать как образец
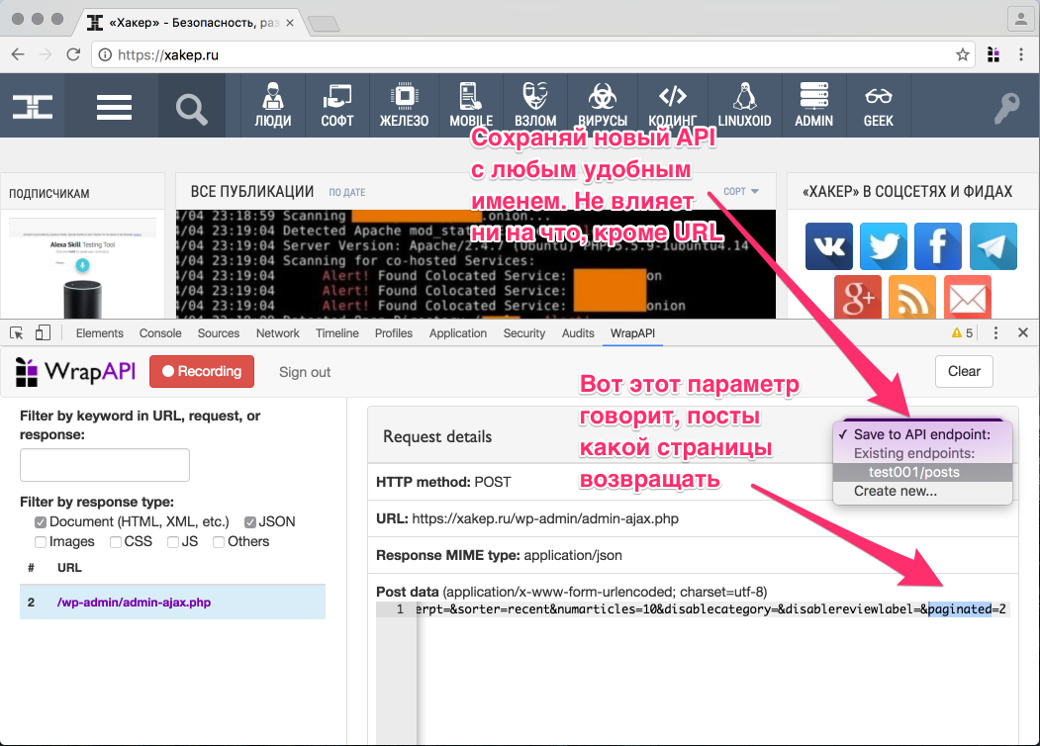 Запрос пойман, сохраняем его на сервер WrapAPI
Запрос пойман, сохраняем его на сервер WrapAPI
Конфигурируем WrapAPI
После того как ты выбрал нужное имя для твоего репозитория (я взял test001 и endpoint posts ) и сохранил его на сервер WrapAPI через расширение для Chrome, иди на сайт WrapAPI и открывай репозиторий. Самое время настраивать наш API.
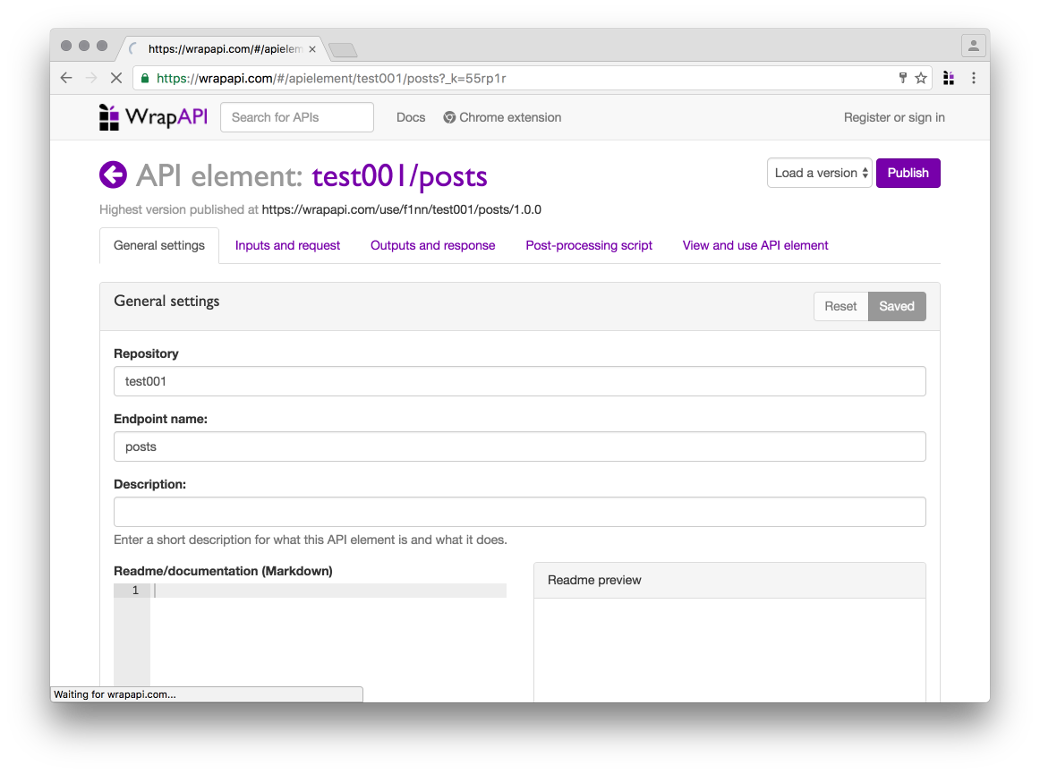 Обзор нашего будущего API
Обзор нашего будущего API
Переходи на вкладку Inputs and request. Здесь нам понадобится указать, с какими параметрами WrapAPI должен парсить запрашиваемую страницу, чтобы сервер отдал ему валидный ответ.
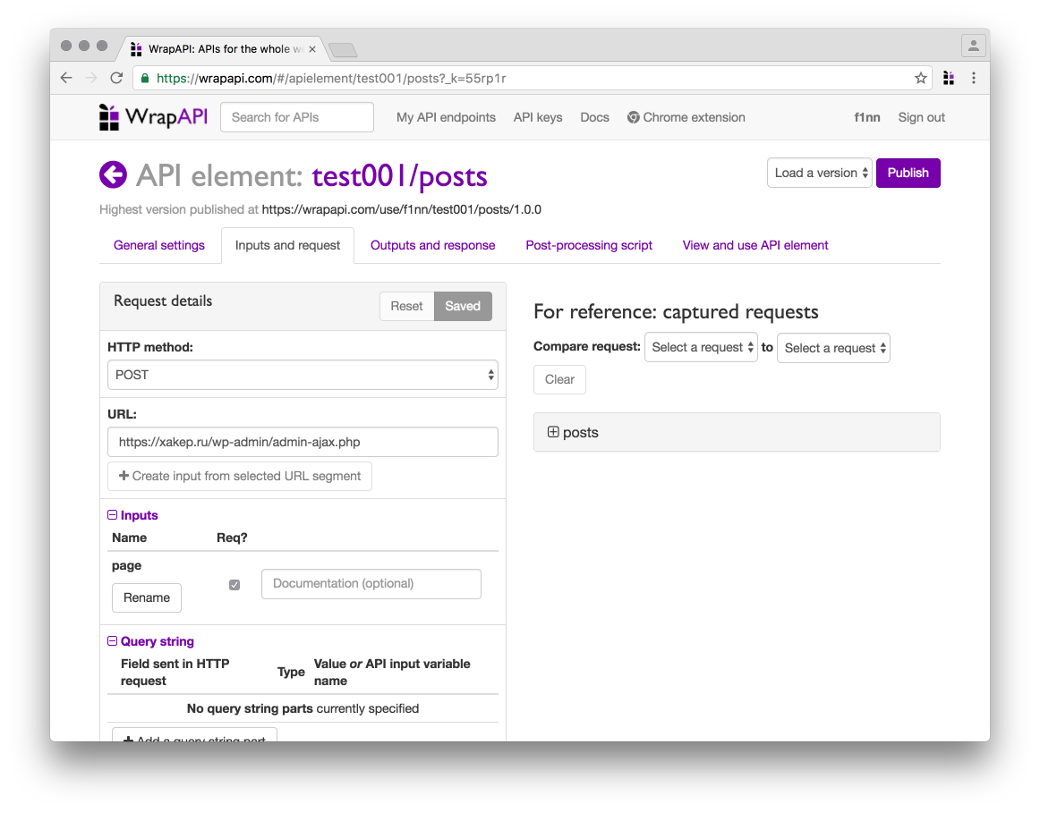 Конфигурируем входные параметры запроса
Конфигурируем входные параметры запроса
Заголовки запроса ниже можно не трогать, я использовал стандартные из Chromium. Если парсишь не «Хакер», а данные с какого-нибудь закрытого сервера, можешь подставить туда нужные куки, хедеры, basic-auth и все, что нужно. Одним словом, ты сможешь настроить свой запрос так, чтобы сервер безо всяких подозрений отдал тебе контент.
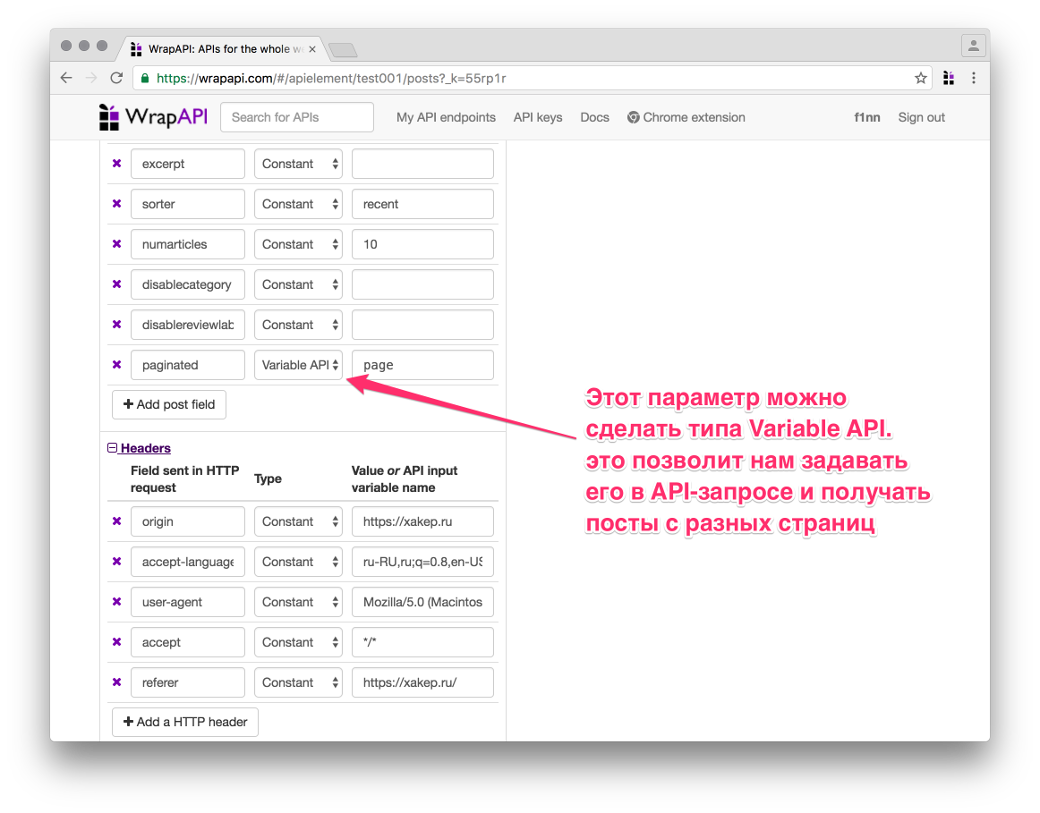 Выставляем необходимые POST-параметры в формате form/urlencoded, чтобы наш запрос отработал правильно
Выставляем необходимые POST-параметры в формате form/urlencoded, чтобы наш запрос отработал правильно
Учим WrapAPI недостающим фичам
Теперь нужно указать WrapAPI, как обрабатывать полученный результат и в каком виде его представлять. Переходи на следующую вкладку — Outputs and response.
 Шаг настройки постпроцессоров полученного контента
Шаг настройки постпроцессоров полученного контента
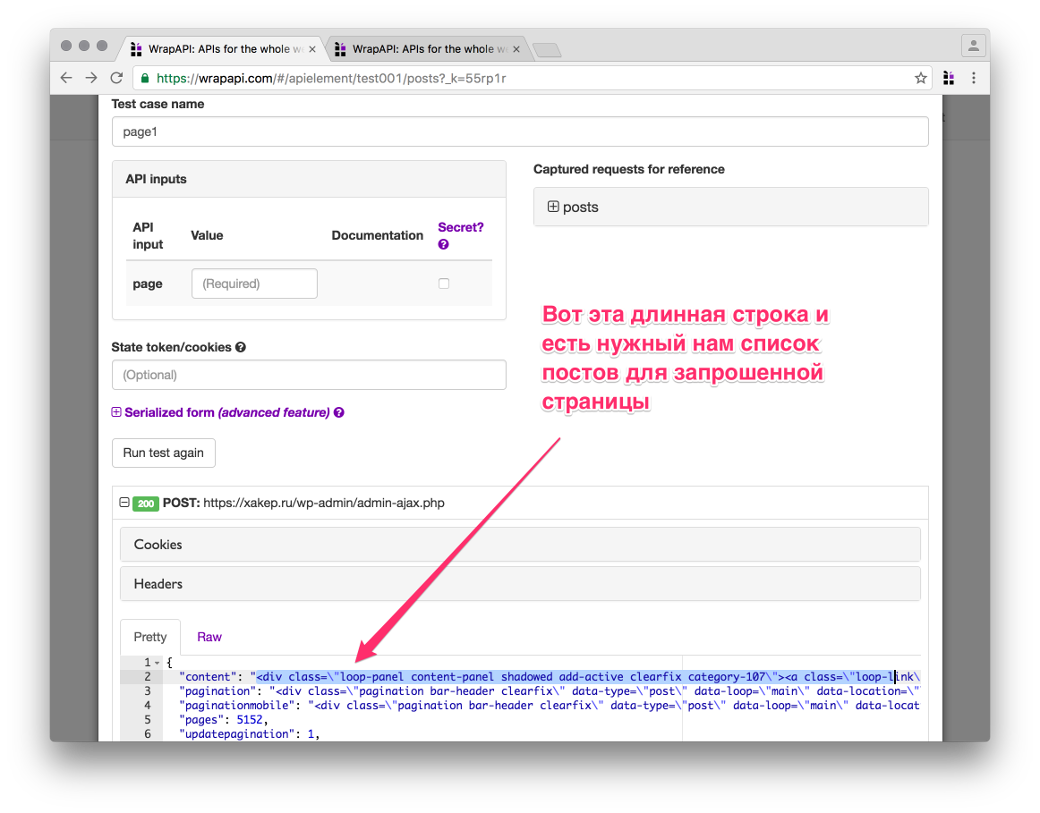 Тестовый кейс page1, ответ сервера
Тестовый кейс page1, ответ сервера
JSON output
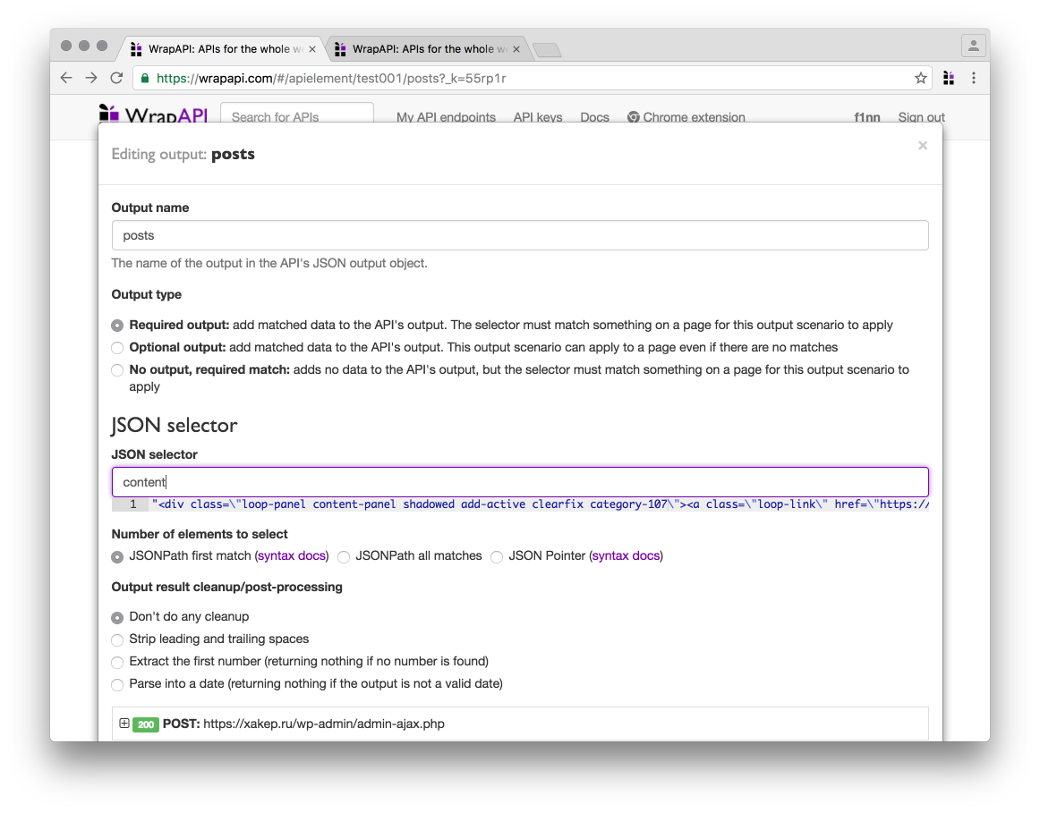 JSON output для получения значения атрибута content на выход
JSON output для получения значения атрибута content на выход
CSS output
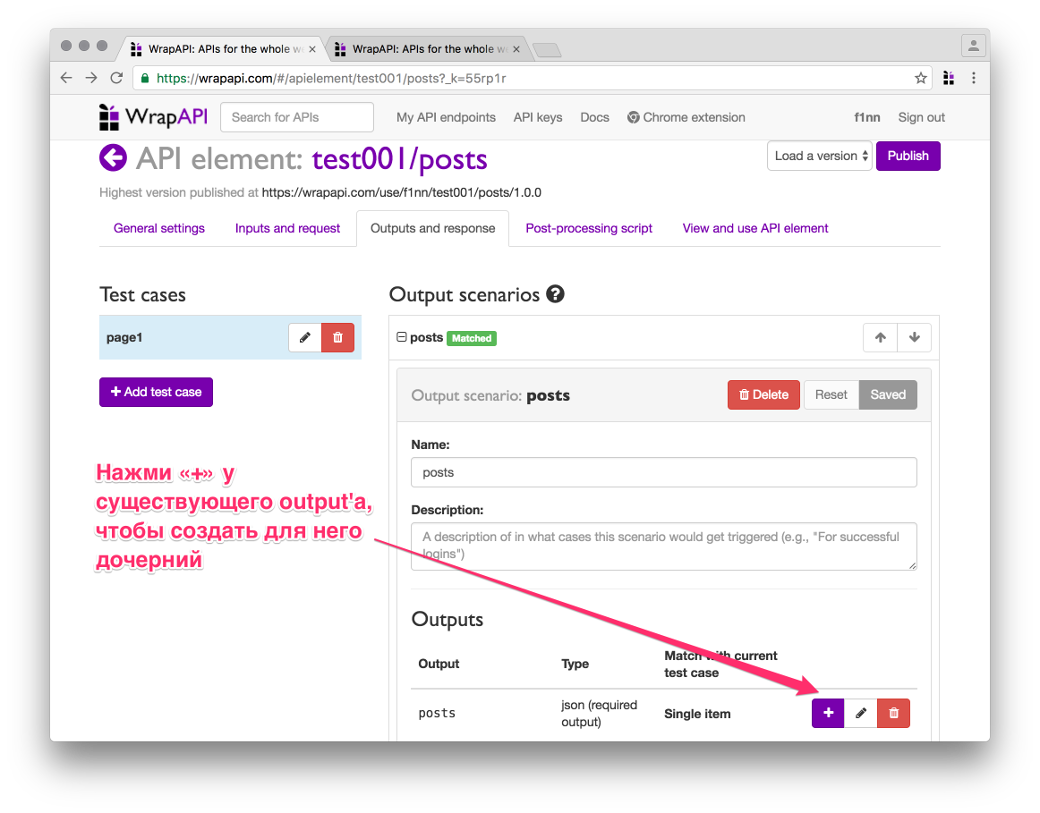 Создаем дочерний CSS output
Создаем дочерний CSS output
 Задаем параметры получения данных из HTML-верстки
Задаем параметры получения данных из HTML-верстки
На выходе в ключе titles у нас окажется массив заголовков, которые вернул CSS output. Согласись, уже неплохо, и все это — без единой строки кода!
 Полученные заголовки новостей
Полученные заголовки новостей
Как получить остальные параметры
Признаться, мне пришлось немного поломать голову, чтобы обойти эти ограничения. Я сделал много дочерних по отношению к JSON аутпутов CSS — по одному на каждый из параметров. Они выводят мне в итоговый результат несколько массивов: один с заголовками, один с превью статьи, один с датами и так далее.
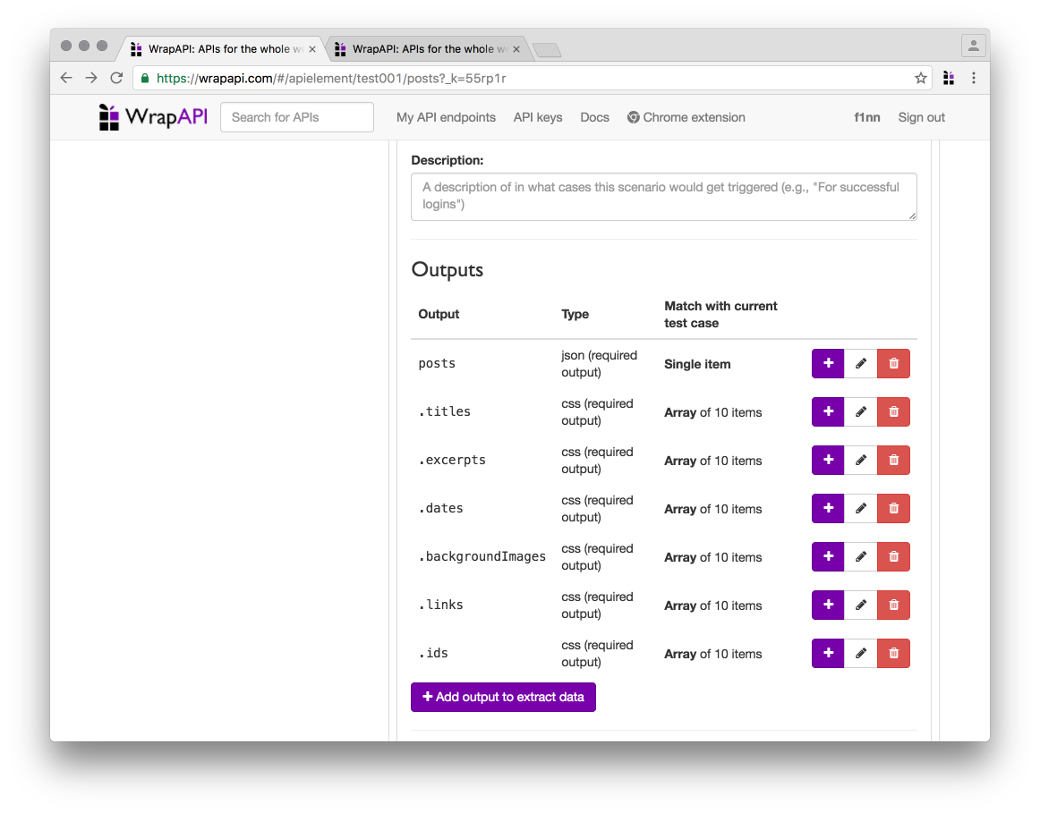 Массив дочерних аутпутов, каждый из которых выбирает свой атрибут постов
Массив дочерних аутпутов, каждый из которых выбирает свой атрибут постов
В итоге у меня получился вот такой массив данных:
Приводим все в порядок
Сейчас наш API уже выглядит вполне читаемым, осталось решить две проблемы:
Решить эти проблемы нам поможет следующая вкладка — Post-processing script. Она позволяет написать небольшой синхронный скрипт на JavaScript, который может сделать что-то с нашим контентом перед тем, как он отправится на выход.
Я набросал небольшой скрипт, который быстро собрал все компоненты в единый массив постов, а также почистил URL картинки. Останавливаться на этом подробнее смысла нет, все, я думаю, и так предельно ясно.
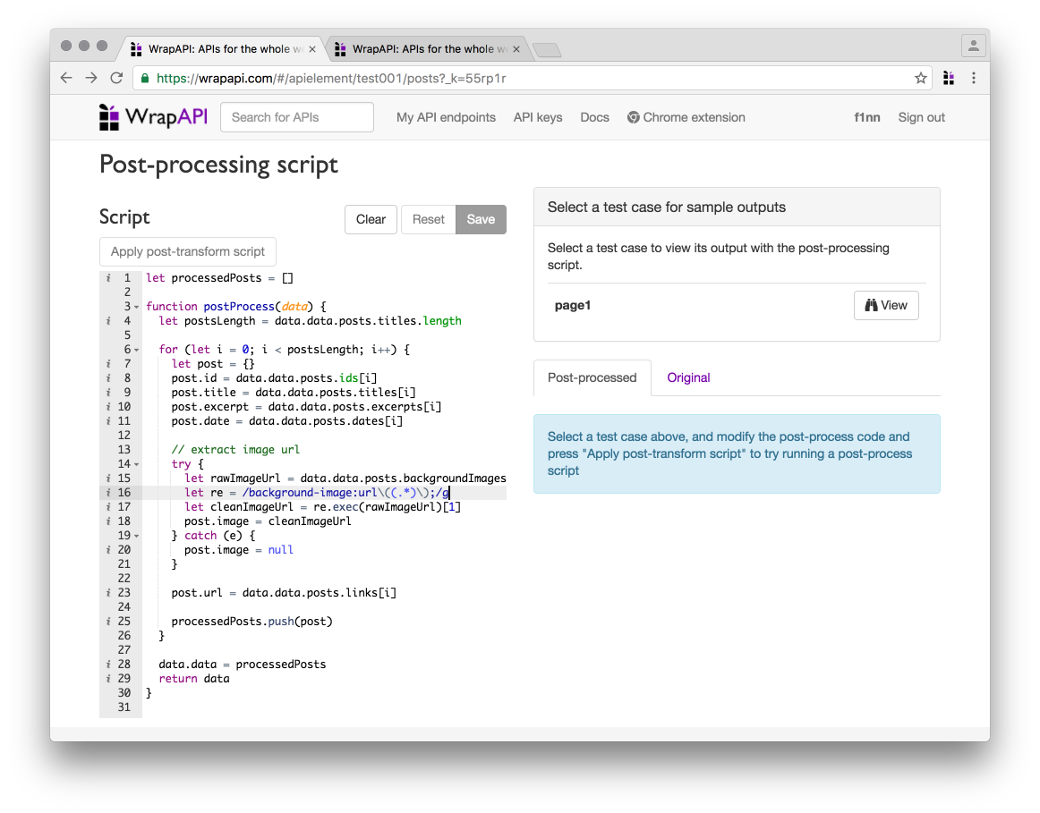 Пишем скрипт для постпроцессинга данных
Пишем скрипт для постпроцессинга данных
Тестируем результат
Перед тем как пробовать наш запрос, нужно получить API-ключ. Ключи WrapAPI бывают двух типов:
 Получение ключей доступа к API
Получение ключей доступа к API
У меня вышел вот такой запрос:
Ответ сервера показан на скриншоте. Победа! ?
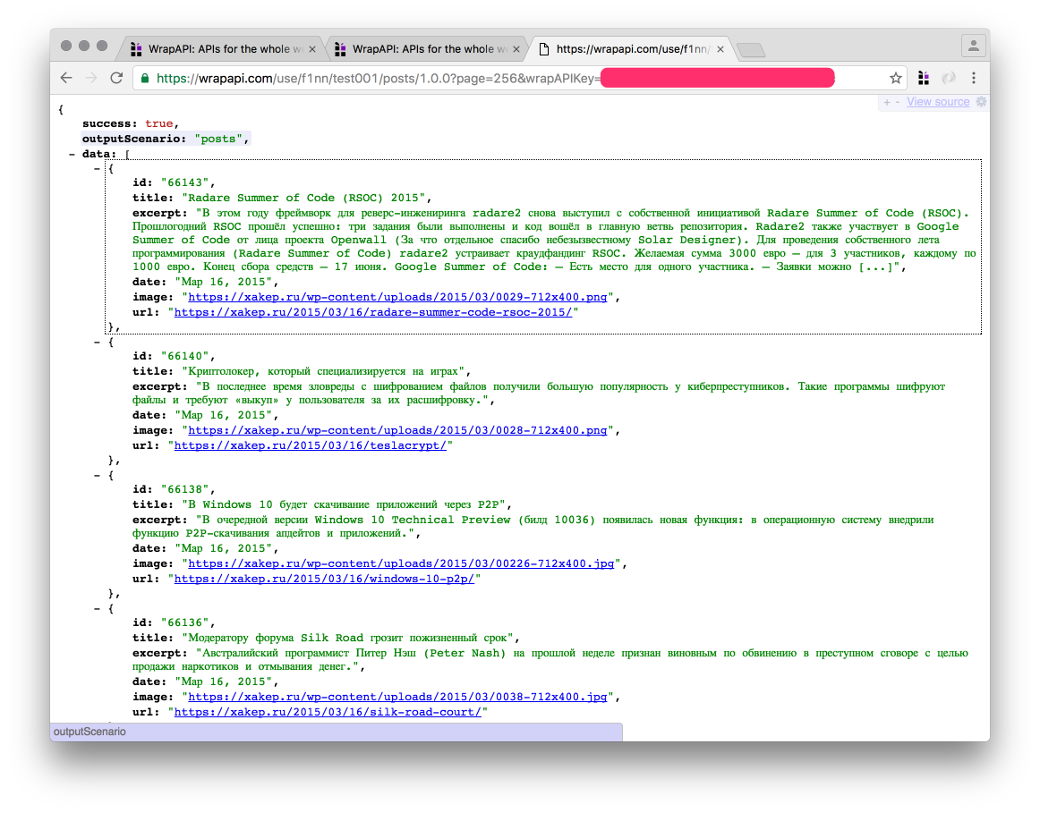 Десять постов с 256-й страницы «Хакера» (?page=256)
Десять постов с 256-й страницы «Хакера» (?page=256)
Выводы
Как видишь, WrapAPI — это мощный и очень эффективный способ построения парсеров веб-контента, который помогает обойтись без программирования или почти без него. Поначалу он кажется слишком перегруженным и нелогичным, но со временем ты убедишься, что он содержит ровно столько опций, сколько действительно нужно для эффективного скрэпинга веба. Сервис имеет гибкие параметры конфигурирования запросов, а постпроцессинг полученных ответов позволяет преобразовать практически любой HTTP response в красивый API. Дерзай, строй свои парсеры!

Илья Русанен
Главный редактор ][, занимаюсь разработкой и безопасностью
Написание парсера с нуля: так ли страшен черт?
Очевидно, что парсер нужно было переписать на C#, но при мысли о написании парсера с нуля вдруг находилась дюжина других срочных дел. Таким образом таск перекидывался и откладывался практически полгода и казался непосильным, а в итоге был сделан за 4 дня. Под катом я расскажу об удобном способе, позволившим реализовать парсер достаточно сложной грамматики без использования сторонних библиотек и не тронуться умом, а также о том, как это позволило улучшить язык LENS.
Но обо всем по порядку.
Первый блин
Как было сказано выше, в качестве ядра парсера мы использовали библиотеку FParsec. Причины данного выбора скорее исторические, нежели объективные: понравился легковесный синтаксис, хотелось поупражняться в использовании F#, и автор библиотеки очень оперативно отвечал на несколько вопросов по email.
Главным недостатком этой библиотеки для нашего проекта оказались внешние зависимости:
Другой проблемой было отображение ошибок. Лаконичная запись грамматики на местном DSL при некорректно введенной программе выдавала нечитаемую ошибку c перечислением ожидаемых лексем:
Хотя кастомная обработка ошибок и возможна, DSL для нее явно не предназначен. Описание грамматики уродливо распухает и становится абсолютно неподдерживаемым.
Еще одним неприятным моментом была скорость работы. При «холодном старте» компиляция любого, даже самого простого скрипта занимала на моей машине примерно 350-380 миллисекунд. Судя по тому, что повторный запуск такого же скрипта занимал уже всего-то 5-10 миллисекунд, задержка была вызвана JIT-компиляцией.
Сразу оговорюсь — для большинства реальных задач время разработки куда критичнее, чем пара дополнительных библиотек или сотни миллисекунд, которые тратятся на разбор. С этой точки зрения написание рукопашного парсера является скорее учебным или эзотерическим упражнением.
Немного теории
Сферический парсер в вакууме представляет собой функцию, которая принимает исходный код, а возвращает некое промежуточное представление, по которому удобно будет сгенерировать код для используемой виртуальной машины или процессора. Чаще всего это представление имеет древовидную структуру и называется абстрактным синтаксическим деревом — АСД (в иностранной литературе — abstract syntactic tree, AST).
Итак, на входе мы имеем строку. Набор символов. Работать с ней в таком виде напрямую не слишком удобно — приходится учитывать пробелы, переносы строк и комментарии. Для упрощения себе жизни разработчики парсеров обычно разделяют разбор на несколько проходов, каждый из которых выполняет какую-то одну простую задачу и передает результат своей работы следующему:
Лексический анализатор
Все лексемы изначально стоит поделить на 2 типа — статические и динамические. К первым относятся те лексемы, которые можно выразить обычной строкой — ключевые слова и операторы. Лексемы типа идентификаторов, чисел или строк проще описать регулярным выражением.
Синтаксический анализатор
Тут пытливый читатель спросит:
— Как это, просто вызываются по порядку? А как же опережающие проверки? Например, так:
Признаюсь, свой первый серьезный парсер я написал именно так. Однако это плохая идея!
Другая проблема — смешение зон ответственности. Чтобы грамматика была расширяемой, правила должны быть как можно более независимы друг от друга. Данный подход требует, чтобы внешнее правило знало о составе внутренних, что увеличивает связность и осложняет поддержку при изменении грамматики.
Так зачем нам вообще опережающие проверки? Пусть каждое правило само знает о том, насколько далеко нужно заглянуть вперед, чтобы убедиться, что именно оно наиболее подходящее.
Рассмотрим на примере выше. Допустим, у нас есть текст: a.1 = 2 :
С их помощью реализация приведенной выше грамматики становится практически тривиальной:
Атрибут DebuggerStepThrough сильно помогает при отладке. Поскольку все вызовы вложенных правил так или иначе проходят через Attempt и Ensure, без этого атрибута они будут постоянно бросаться в глаза при Step Into и забивать стек вызовов.
Преимущества данного метода:
Операторы и приоритеты
Неоднократно я видел в описаниях грамматик примерно следующие правила, показывающие приоритет операций:
Теперь представим, что у нас есть еще булевы операторы, операторы сравнения, операторы сдвига, бинарные операторы, или какие-нибудь собственные. Сколько правил получается, и сколько всего придется поменять, если вдруг придется добавить новый оператор с приоритетом где-то в середине?
Вместо этого, можно убрать из грамматики вообще все описание приоритетов и закодить его декларативно.
Теперь для добавления нового оператора необходимо лишь дописать соответствующую строчку в инициализацию списка приоритетов.
Добавление поддержки унарных префиксных операторов оставляю в качестве тренировки для особо любопытных.
Что нам это дало?
Написанный вручную парсер, как ни странно, стало гораздо легче поддерживать. Добавил правило в грамматику, нашел соответствующее место в коде, дописал его использование. Backtracking hell, который частенько возникал при добавлении нового правила в старом парсере и вызывал внезапное падение целой кучи на первый взгляд не связанных тестов, остался в прошлом.
Итого, сравнительная таблица результатов:
| Параметр | FParsec Parser | Pure C# |
| Время парсинга при 1 прогоне | 220 ms | 90 ms |
| Время парсинга при дальнейших прогонах | 5 ms | 6 ms |
| Размер требуемых библиотек | 800 KB + F# Runtime | 260 KB |
Скорее всего, возможно провести оптимизации и выжать из синтаксического анализатора больше производительности, но пока и этот результат вполне устраивает.
Избавившись от головной боли с изменениями в грамматике, мы смогли запилить в LENS несколько приятных вещей:
Цикл for
Используется как для обхода последовательностей, так и для диапазонов:
Композиция функций
С помощью оператора :> можно создавать новые функции, «нанизывая» существующие:
Частичное применение возможно с помощью анонимных функций: