Создание базы данных SQL и работа с таблицами в SQL
В этой статье мы рассмотрим создание базы данных SQL и создание таблицы SQL, используя команды в клиенте mysql. Предполагается, что этот инструмент запущен и подключен к серверу базы данных MySQL.
Создание новой базы данных MySQL
Новая база данных создается с помощью оператора SQL CREATE DATABASE, за которым следует имя создаваемой базы данных. Для этой цели также используется оператор CREATE SCHEMA. Например, для создания новой базы данных под названием MySampleDB в командной строке mysql нужно ввести следующий запрос:
Если все прошло нормально, команда сгенерирует следующий вывод:
Если указанное имя базы данных конфликтует с существующей базой данных MySQL, будет выведено сообщение об ошибке:
В этой ситуации следует выбрать другое имя базы данных или использовать опцию IF NOT EXISTS. Она создает базу данных только в том случае, если она еще не существует:
Создание таблицы SQL
Новые таблицы добавляются в существующую базу данных с помощью оператора CREATE TABLE SQL. За оператором CREATE TABLE следует имя создаваемой таблицы, а далее через запятые список имен и определений каждого столбца таблицы:
CREATE TABLE имя_таблицы ( определение имени_столбца, определение имени_таблицы …, PRIMARY KEY = (имя_столбца) ) ENGINE = тип_движка;
В определении столбца задается тип данных, может ли столбец быть NULL, AUTO_INCREMENT. Оператор CREATE TABLE также позволяет указать столбец (или группу столбцов) в качестве первичного ключа.
Прежде чем будет создавать таблицу, нужно выбрать базу данных. Это делается с помощью оператора SQL USE:
Значения NULL и NOT NULL
Если для столбца указано значение NULL, тогда пустые строки будут добавляться в таблицу. И наоборот, если столбец определяется как NOT NULL, тогда пустые строки не будут добавлены.
Первичные ключи
Первичный ключ — это столбец, используемый для идентификации записей в таблице. Значение столбца первичного ключа должно быть уникальным. Если несколько столбцов объединены в первичный ключ, то комбинация значений ключей должна быть уникальной для каждой строки.
Первичный ключ определяется с помощью оператора PRIMARY KEY во время создания таблицы. Если используется несколько столбцов, они разделяются запятой:
В следующем примере создается таблица с использованием двух столбцов в качестве первичного ключа:
AUTO_INCREMENT
Когда столбец определяется с помощью AUTO_INCREMENT, его значение автоматически увеличивается каждый раз, когда в таблицу добавляется новая запись. Это удобно при использовании столбца в качестве первичного ключа. Благодаря AUTO_INCREMENTне нужно писать инструкции SQL для вычисления уникального идентификатора для каждой строки.
AUTO_INCREMENT может быть присвоен только одному столбцу в таблице. И он должен быть проиндексирован (например, объявлен в качестве первичного ключа).
Значение AUTO_INCREMENT для столбца можно переопределить, указав новое при выполнении инструкции INSERT.
Можно запросить у MySQL самое последнее значение AUTO_INCREMENT, используя функцию last_insert_id() следующим образом:
Определение значений по умолчанию при создании таблицы
Значения по умолчанию используются, когда значение не определено при вставке в базу данных.
Значения по умолчанию задаются с помощью ключевого слова DEFAULT в операторе CREATE TABLE. Например, приведенный ниже запрос SQL задает значение по умолчанию для столбца sales_quantity:
Типы движков баз данных MySQL
Движки различных типов могут сочетаться в одной базе данных. Например, некоторые таблицы могут использовать движок InnoDB, а другие — MyISAM. Если во время создания таблицы движок не указывается, то по умолчанию MySQL будет использовать MyISAM.
Чтобы указать тип движка, который будет использоваться для таблицы, о поместите соответствующее определение ENGINE= после определения столбцов таблицы:
Пожалуйста, опубликуйте ваши комментарии по текущей теме статьи. За комментарии, отклики, лайки, дизлайки, подписки низкий вам поклон!
Пожалуйста, опубликуйте ваши мнения по текущей теме материала. За комментарии, отклики, подписки, дизлайки, лайки низкий вам поклон!
Руководство по разработке структуры и проектированию базы данных
Этапы создания базы данных
Надлежащим образом структурированная база данных:
Основные этапы разработки базы данных:
Анализ требований: определение цели базы данных
Вот несколько способов сбора информации перед созданием базы данных:
Начните со сбора существующих данных, которые будут включены в базу. Затем определите типы данных, которые нужно сохранить. А также объекты, которые описывают эти данные. Например:
Структура базы данных: построение блоков
Чтобы преобразовать списки данных в таблицы, начните с создания таблицы для каждого типа объектов, таких как товары, продажи, клиенты и заказы. Вот пример:
Каждая строка таблицы называется записью. Записи включают в себя информацию о чем-то или о ком-то, например, о конкретном клиенте. Столбцы (также называемые полями или атрибутами) содержат информацию одного типа, которая отображается для каждой записи, например, адреса всех клиентов, перечисленных в таблице.

Чтобы при проектировании модели базы данных обеспечить согласованность разных записей, назначьте соответствующий тип данных для каждого столбца. К общим типам данных относятся:
В визуальном представлении БД каждая таблица будет представлена блоком на диаграмме. В заголовке каждого блока должно быть указано, что описывают данные в этой таблице, а ниже должны быть перечислены атрибуты:

При проектировании информационной базы данных необходимо решить, какие атрибуты будут служить в качестве первичного ключа для каждой таблицы, если таковые будут. Первичный ключ ( PK ) — это уникальный идентификатор для данного объекта. С его помощью вы можете выбрать данные конкретного клиента, даже если знаете только это значение.
Атрибуты, выбранные в качестве первичных ключей, должны быть уникальными, неизменяемыми и для них не может быть задано значение NULL ( они не могут быть пустыми ). По этой причине номера заказов и имена пользователей являются подходящими первичными ключами, а номера телефонов или адреса — нет. Также можно использовать в качестве первичного ключа несколько полей одновременно ( это называется составным ключом ).
Создание связей между сущностями
Теперь, когда данные преобразованы в таблицы, нужно проанализировать связи между ними. Сложность базы данных определяется количеством элементов, взаимодействующих между двумя связанными таблицами. Определение сложности помогает убедиться, что вы разделили данные на таблицы наиболее эффективно.
Каждый объект может быть взаимосвязан с другим с помощью одного из трех типов связи:
Связь «один-к одному»
Когда существует только один экземпляр объекта A для каждого экземпляра объекта B, говорят, что между ними существует связь « один-к одному » ( часто обозначается 1:1 ). Можно указать этот тип связи в ER-диаграмме линией с тире на каждом конце:

Если при проектировании и разработке баз данных у вас нет оснований разделять эти данные, связь 1:1 обычно указывает на то, что в лучше объединить эти таблицы в одну.
Чтобы гарантировать, что данные соотносятся правильно, в нужно будет включить, по крайней мере, один идентичный столбец в каждой таблице. Скорее всего, это будет первичный ключ.
Связь «один-ко-многим»
Эта связи возникают, когда запись в одной таблице связана с несколькими записями в другой. Например, один клиент мог разместить много заказов, или у читателя может быть сразу несколько книг, взятых в библиотеке. Связи « один- ко-многим » ( 1:M ) обозначаются так называемой «меткой ноги вороны», как в этом примере:

Связь «многие-ко-многим»
Когда несколько объектов таблицы могут быть связаны с несколькими объектами другой. Говорят, что они имеют связь « многие-ко-многим » ( M:N ). Например, в случае студентов и курсов, поскольку студент может посещать много курсов, и каждый курс могут посещать много студентов.
На ER-диаграмме эти связи отображаются с помощью следующих строк:

При проектировании структуры базы данных реализовать такого рода связи невозможно. Вместо этого нужно разбить их на две связи « один-ко-многим ».
Каждая запись в таблице связей будет соответствовать двум сущностям из соседних таблиц. Например, таблица связей между студентами и курсами может выглядеть следующим образом:

Обязательно или нет?
Другим способом анализа связей является рассмотрение того, какая сторона связи должна существовать, чтобы существовала другая. Необязательная сторона может быть отмечена кружком на линии. Например, страна должна существовать для того, чтобы иметь представителя в Организации Объединенных Наций, а не наоборот:

Два объекта могут быть взаимозависимыми ( один не может существовать без другого ).
Рекурсивные связи
Иногда при проектировании базы данных таблица указывает на себя саму. Например, таблица сотрудников может иметь атрибут «руководитель», который ссылается на другое лицо в этой же таблице. Это называется рекурсивными связями.
Лишние связи
Лишние связи — это те, которые выражены более одного раза. Как правило, можно удалить одну из таких связей без потери какой-либо важной информации. Например, если объект « ученики » имеет прямую связь с другим объектом, называемым « учителя », но также имеет косвенные отношения с учителями через « предметы », нужно удалить связь между « учениками » и « учителями ». Так как единственный способ, которым ученикам назначают учителей — это предметы.
Нормализация базы данных
После предварительного проектирования базы данных можно применить правила нормализации, чтобы убедиться, что таблицы структурированы правильно.
В то же время не все базы данных необходимо нормализовать. В целом, базы с обработкой транзакций в реальном времени ( OLTP ), должны быть нормализованы.
Базы данных с интерактивной аналитической обработкой ( OLAP ), позволяющие проще и быстрее выполнять анализ данных, могут быть более эффективными с определенной степенью денормализации. Основным критерием здесь является скорость вычислений. Каждая форма или уровень нормализации включает правила, связанные с нижними формами.
Первая форма нормализации
Первая форма нормализации ( сокращенно 1NF ) гласит, что во время логического проектирования базы данных каждая ячейка в таблице может иметь только одно значение, а не список значений. Поэтому таблица, подобная той, которая приведена ниже, не соответствует 1NF :

Возможно, у вас возникнет желание обойти это ограничение, разделив данные на дополнительные столбцы. Но это также противоречит правилам: таблица с группами повторяющихся или тесно связанных атрибутов не соответствует первой форме нормализации. Например, приведенная ниже таблица не соответствует 1NF :

Вместо этого во время физического проектирования базы данных разделите данные на несколько таблиц или записей, пока каждая ячейка не будет содержать только одно значение, и дополнительных столбцов не будет. Такие данные считаются разбитыми до наименьшего полезного размера. В приведенной выше таблице можно создать дополнительную таблицу « Реквизиты продаж », которая будет соответствовать конкретным продуктам с продажами. « Продажи » будут иметь связь 1:M с « Реквизитами продаж ».
Вторая форма нормализации
Вторая форма нормализации ( 2NF ) предусматривает, что каждый из атрибутов должен полностью зависеть от первичного ключа. Каждый атрибут должен напрямую зависеть от всего первичного ключа, а не косвенно через другой атрибут.
Например, атрибут « возраст » зависит от « дня рождения », который, в свою очередь, зависит от « ID студента », имеет частичную функциональную зависимость. Таблица, содержащая эти атрибуты, не будет соответствовать второй форме нормализации.
Кроме этого таблица с первичным ключом, состоящим из нескольких полей, нарушает вторую форму нормализации, если одно или несколько полей не зависят от каждой части ключа.
Таким образом, таблица с этими полями не будет соответствовать второй форме нормализации, поскольку атрибут « название товара » зависит от идентификатора продукта, но не от номера заказа:
Третья форма нормализации
Третья форма нормализации ( 3NF ) : каждый не ключевой столбец должен быть независим от любого другого столбца. Если при проектировании реляционной базы данных изменение значения в одном не ключевом столбце вызывает изменение другого значения, эта таблица не соответствует третьей форме нормализации.

Многомерные данные
Некоторым пользователям может потребоваться доступ к нескольким разрезам одного типа данных, особенно в базах данных OLAP. Например, им может потребоваться узнать продажи по клиенту, стране и месяцу. В этой ситуации лучше создать центральную таблицу, на которую могут ссылаться таблицы клиентов, стран и месяцев. Например:

Правила целостности данных
Правило целостности ссылок требует, чтобы каждый внешний ключ, указанный в одной таблице, сопоставлялся с одним первичным ключом в таблице, на которую он ссылается. Если первичный ключ изменяется или удаляется, эти изменения необходимо реализовать во всех объектах, на которые ссылается этот ключ в базе данных.
Правила целостности бизнес-логики обеспечивают соответствие данных определенным логическим параметрам. Например, время встречи должно быть в пределах стандартных рабочих часов.
Добавление индексов и представлений
Индекс — это отсортированная копия одного или нескольких столбцов со значениями в возрастающем или убывающем порядке. Добавление индекса позволяет быстрее находить записи. Вместо повторной сортировки для каждого запроса система может обращаться к записям в порядке, указанном индексом.
Хотя индексы ускоряют извлечение данных, они могут замедлять добавление, обновление и удаление данных, поскольку индекс нужно перестраивать всякий раз, когда изменяется запись.
Представление — это сохраненный запрос данных. Представления могут включать в себя данные из нескольких таблиц или отображать часть таблицы.
Расширенные свойства
После того как схема базы данных будет готова можно уточнить БД с помощью расширенных свойств, таких как справочный текст, маски ввода и правила форматирования, которые применяются к конкретной схеме, представлению или столбцу. Преимущество этого метода заключается в том, что, поскольку эти правила хранятся в самой базе, представление данных будет согласовано между несколькими программами, которые обращаются к данным.
SQL и UML
Унифицированный язык моделирования ( UML ) — это еще один визуальный способ выражения сложных систем, созданных на объектно-ориентированном языке. Некоторые из концепций, упомянутых в этом руководстве, известны в UML под разными названиями. Например, объект в UML известен, как класс.
Сейчас UML используется не так часто. В наши дни он применяется академически и в общении между разработчиками программного обеспечения и их клиентами.
Системы управления базами данных
Проектируемая структура базы данных зависит от того, какую СУБД вы используете. Некоторые из наиболее распространенных:
Подходящую систему управления базами данных можно выбирать исходя из стоимости, установленной операционной системы, наличия различных функций и т. д.
Пожалуйста, опубликуйте свои мнения по текущей теме материала. За комментарии, дизлайки, подписки, лайки, отклики низкий вам поклон!
Пожалуйста, оставляйте свои мнения по текущей теме материала. За комментарии, подписки, отклики, лайки, дизлайки низкий вам поклон!
Основы правил проектирования базы данных
Введение
Как это часто бывает, архитектору БД нужно разработать базу данных под конкретное решение.
Однажды в пятницу вечером, возвращаясь на электричке домой с работы, я подумал о том, как бы я создал сервис по найму сотрудников в разные компании. Ведь ни один из существующих сервисов не позволяет быстро понять насколько подходит тебе кандидат. Нет возможности создать сложные фильтры, включающие или исключающие совокупность определенных навыков, проектов или позиций. Максимум, что обычно предлагают сервисы — фильтры по компаниям и частично по навыкам.
В данной статье я позволю себе немного разбавить строгое изложение материала, смешав техническую информацию с не техническими примерами из жизни.
Для начала, разберем создание базы данных в MS SQL Server для сервиса поиска соискателей на работу.
Этот материал можно перенести и на другую СУБД такую как MySQL или PostgreSQL.
Основы правил проектирования
Для проектирования схемы базы данных, нужно вспомнить 7 формальных правил и саму концепцию нормализации и денормализации. Они и лежат в основе всех правил проектирования.
Опишем более детально 7 формальных правил:
1.1) с обязательной связью:
Реализовать данную связь можно двумя способами:
1.1.1) в одной сущности (таблице):

Рис.1. Сущность Citizen
Здесь таблица Citizen представляет собой сущность гражданина, а атрибут (поле) PassportData содержит все паспортные данные гражданина и не может быть пустым (NOT NULL).
1.1.2) в двух разных сущностях (таблицах):

Рис.2. Отношение сущностей Citizen и PassportData
Здесь таблица Citizen представляет собой сущность гражданина, а таблица PassportData — сущность паспортных данных гражданина (самого паспорта). Сущность гражданина содержит атрибут (поле) PassportID, который ссылается на первичный ключ таблицы PassportData. В свою очередь сущность паспортных данных содержит атрибут (поле) CitizenID, которое ссылается на первичный ключ CitizenID таблицы Citizen. Поле PassportID таблицы Citizen не может быть пустым (NOT NULL). Также здесь важно поддерживать целостность поля CitizenID таблицы PassportData, чтобы обеспечить связь один к одному. Иными словами, поле PassportID таблицы Citizen и поле CitizenID таблицы PassportData должны ссылаться на одни и те же записи как если бы это была одна сущность (таблица), представленная в пункте 1.1.1.
1.2) с необязательной связью:
Реализовать данную связь можно двумя способами:
1.2.1) в одной сущности (таблице):

Рис.3. Сущность Person
Таблица Person представляет собой сущность человека, а атрибут (поле) PassportData содержит все его паспортные данные и может быть пустым (NULL).
1.2.2) в двух сущностях (таблицах):
2.1) с обязательной связью:
примером могут выступать родитель и его дети. У каждого родителя есть как минимум один ребенок.
Реализовать данную связь можно двумя способами:
2.1.1) в одной сущности (таблице):
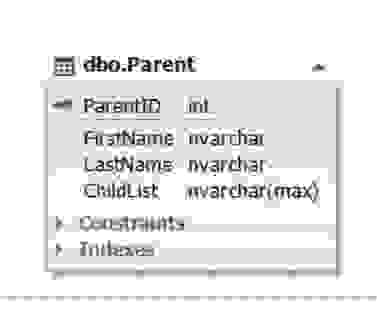
Рис.5. Сущность Parent
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле не может быть пустым (NOT NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.1.2) в двух сущностях (таблицах):
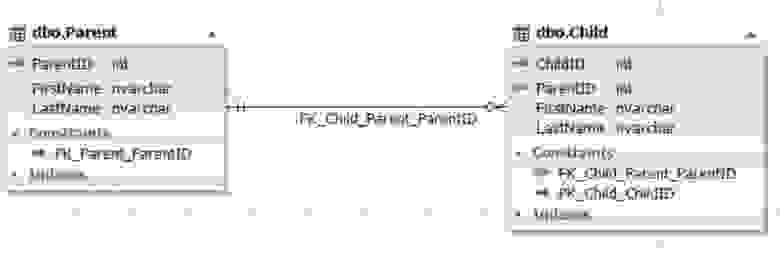
Рис.6. Отношение сущностей Parent и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child не может быть пустым (NOT NULL).
2.2) с необязательной связью:
примером может выступать человек, у которого могут быть дети или их может не быть.
Реализовать данную связь можно двумя способами:
2.2.1) в одной сущности (таблице):
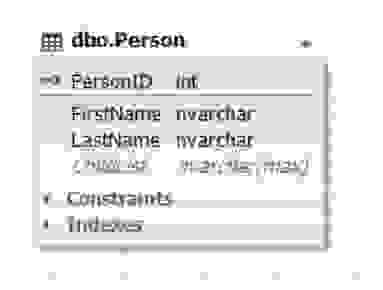
Рис.7. Сущность Person
Таблица Parent представляет сущность родителя, а атрибут (поле) ChildList содержит информацию о детях. Данное поле может быть пустым (NULL). Обычно типом поля ChildList выступают неполно структурированные данные (NoSQL) такие как XML, JSON и т д.
2.2.2) в двух сущностях (таблицах):

Рис.8. Отношение сущностей Person и Child
Таблица Parent представляет сущность родителя, а таблица Child — сущность ребенка. У таблицы Child есть поле ParentID, ссылающееся на первичный ключ ParentID таблицы Parent. Поле ParentID таблицы Child может быть пустым (NULL).
2.2.3) в одной сущности со ссылкой на саму себя при условии, что у сущностей (таблиц) родителя и ребенка будут одинаковые наборы атрибутов (полей) без учета ссылки на родителя:
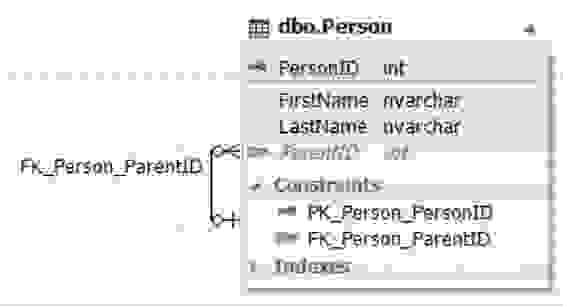
Рис.9. Сущность Person со связью на саму себя
Сущность (таблица) Person содержит атрибут (поле) ParentID, который ссылается на первичный ключ PersonID этой же таблицы Person и может содержать пустое значение (NULL).
Примером может выступить недвижимость: она может быть в собственности как одного человека, так и нескольких. С другой стороны, один человек может владеть несколькими домами или долями нескольких домов.
Реализовать данное отношение, с привлечением NoSQL, можно так же, как в описанных выше отношениях. Однако, в рамках реляционной модели обычно такое отношение реализуют через 3 сущности (таблицы):
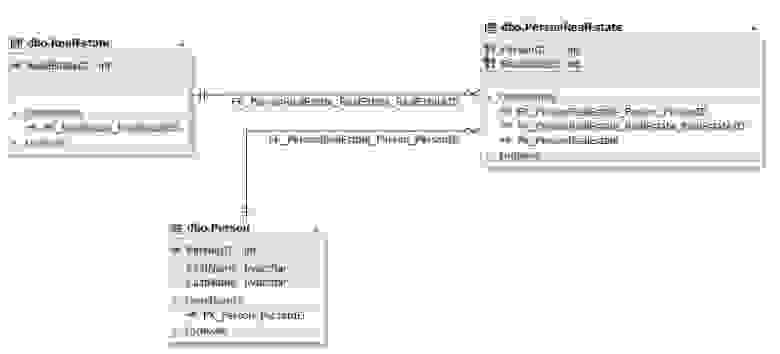
Рис.10. Отношение сущностей Person и RealEstate
Таблицы Person и RealEstate представляют соответственно сущности человека и недвижимости. Связываются данные сущности (таблицы) через сущность (таблицы) PersonRealEstate. Атрибуты (поля) PersonID и RealEstateID ссылаются на первичные ключи PersonID таблицы Person и RealEstateID таблицы RealEstate соответственно. Обратите внимание, что для таблицы PersonRealEstate пара (PersonID; RealEstateID) всегда является уникальной и потому может выступать первичный ключем для самой связующей сущности PersonRealEstate.
Также данное отношение можно реализовать через более чем три сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
Отношения один ко многим и многие к одному можно реализовать через более чем две сущности. Для этого добавляются нужные атрибуты, которые ссылаются на первичные ключи необходимых соответствующих сущностей. Такая реализация схожа с примерами, описанными выше в пунктах 1.1.2 и 1.2.2.
А где же семь формальных правил?
Говоря о нормализации, нужно понимать ее суть. Нормализация ведет к уменьшению повторяемости хранения информации, а следовательно и к уменьшению возможности появления аномалий в данных. Однако, нормализация при дроблении сущностей приводит к более сложным построениям запросов для манипуляций с данными (вставки, модификации, выборки и удаления).
Обратным процессом нормализации называется денормализация. Это упрощение построения запросов доступа к данным за счет укрупнения и вложенности сущностей (например, как было показано выше в пунктах 2.1.1 и 2.2.1 с помощью неполно-структурированных данных (NoSQL)).
Вот и вся суть правил проектирования баз данных.
А вы уверены, что поняли отношения в семи формальных правилах? Именно поняли, а не узнали? Ведь знать и понимать — две совершенно разных концепции.
Объясню более детально. Спросите себя, можете ли вы за пару часов набросать пусть и укрупненную по сущностям, но модель базы данных для любой предметной области и для любой информационной системы? (тонкости и детали можно достроить, поспрашивав аналитиков и представителей заказчиков). Если вопрос вас удивил, и вы думаете, что это невозможно, значит вы знаете семь формальных правил, но не понимаете их.
Почему-то многие источники игнорируют тот факт, что эти отношения были не придуманы, а выявлены. Они изначально существуют в реальном мире как между субъектами, так и между субъектами и объектами.
Также, эти отношения могут меняться, переходя из один к одному к одному ко многим, многие к одному или многие ко многим. Обязательность связи может меняться или остаться неизменной.
Позволю себе рассказать об одном случае, когда от знания семи формальных правил я пришел именно к пониманию этих отношений.
В свое время меня смущало то, что в ВУЗе я знал эти семь формальных правил, но на производственной практике (ВУЗ отправляет студентов в различные компании для приобретения профессионального опыта) очень долго строил модели баз для разных предметных областей. Я задумался и понял, что не понимаю этих отношений.
Мне помогло наблюдение за людьми, а суть отношений раскрылась в сновидении. Этот сон я перескажу в упрощенной форме: только то, что позволяет лучше понять именно эти семь формальных правил — без детализации всего остального.
Сон был про семью, в которой есть отец, мать и дети. Отец погибает в автомобильной катастрофе, а мать начинает пить, и детей в итоге забирают в детский дом. Эти дети надолго остаются без родителей. Затем у некоторых детей появляются попечители, их тоже несколько.
Вы проследили, какие отношения были между субъектами, и как менялись эти отношения?
Давайте присмотримся внимательнее.
Надеюсь, теперь вы значительно приблизились к пониманию этих семи формальных правил.
Поняв семь формальных правил, вы сможете без труда спроектировать модель базы данных любой сложности для любой информационной системы.
Также вы увидите, что реализовать отношение можно разными способами, а сами отношения могут меняться. Модель (схема) базы данных — это «снимок» отношений между сущностями в определенный момент времени. Именно поэтому важно определить как сами сущности — образы объектов из реального мира или предметной области, так и их отношения между собой с учетом изменений в будущем.
Хорошо спроектированную модель базы данных с учетом изменения отношений в реальности или в предметной области не понадобится менять годами или даже десятилетия. Это особенно важно для хранилищ данных, где изменения влекут пересохранение больших объемов данных (от нескольких гигабайт до многих терабайт).
Важно запомнить, что таблицы в реляционной модели — это отношения сущностей, а строки (кортежи) — это экземпляры этих отношений. Но чтобы было проще, под таблицами часто понимаются сущности, а под строками таблицы — экземпляры сущностей. Их отношения выражаются через связи в форме внешних ключей.
Проектирование схемы базы данных для поиска соискателей на работу
После того, как мы описали основы правил проектирования БД в первой части, давайте создадим схему базы данных для поиска соискателей на работу.
Для начала, определим, что важно для сотрудников из компании, которые ищут кандидатов:
2.1) позиции, которые занимал соискатель в данных компаниях
2.2) навыки и умения, которыми соискатель пользовался в работе
2.3) проекты, в которых участвовал соискатель;
а также продолжительность работы соискателя на каждой позиции и в каждом проекте, длительность использования каждого навыка и умения
Для начала выявим нужные сущности:
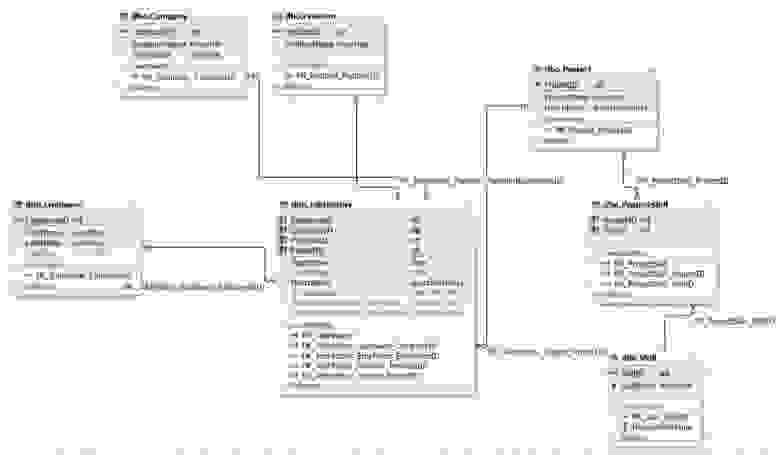
Рис.11. Схема базы данных для поиска соискателей на работу
Здесь таблица JobHistory выступает как сущность истории работы каждого соискателя. То есть, это резюме, которое педставляет отношения многие ко многим между сущностями сотрудник, компания, позиция и проект.
Проекты и навыки относятся друг другу как многие ко многим и потому связываются между собой через сущность (таблицу) ProjectSkill.
Когда вы понимаете отношения между субъектами и между субъектами и объектами — уже упомянутые семь формальных правил — эту или схожую схему можно реализовать «на коленке»: на листке бумаги, мене чем за час. И это еще с учетом усталости после плодотворного рабочего дня.
Здесь можно было упростить схему добавления данных, если «навыки» вложить в сущность «проекты» через неполно структурированные данные (NoSQL) в виде XML, JSON или просто перечислять названия навыков через точку с запятой. Но это бы усложнило выборку с группировкой по навыкам и фильтрацию по отдельным навыкам.
Подобная модель лежит в основе базы данных проекта Geecko.
Как видите, ничего сложного в проектировании информационных систем в части проектирования базы данных нет. Это всего лишь отражение объектов и субъектов из реальности, перенесенное в «сущности» схемы базы данных. Отношения между этими сущностями фиксируются на определенный момент времени, с учетом будущих изменений.
Что именно мы возьмем из реальности и вложим в сущность схемы, и какие отношения построим в модели, будет зависеть от того, что мы хотим от информационной системы в общем, здесь и в будущем. Иными словами — какие данные мы хотим получить в текущий момент времени и через определенное время в будущем.
Немного лирики
После того, как вы внедрите модель в работу, остановитесь на миг и подумайте: только что был создан новый маленький мир. В нем есть свои сущности из реального мира и свои отношения. Да, это цифровой мир, но он теперь будет развиваться своей дорогой. Он будет общаться (интегрироваться) с другими системами (мирами), тоже созданными по своим правилам. Данные будут течь в этих системах, как кровь в живом организме.
А перед сном подумайте о том, что семь формальных правил были всегда, и что они окружают нас всюду. Не больше и не меньше, всегда семь. Все отношения реальной жизни можно разложить на эти семь формальных правил. А когда вы думаете или видите сны, как там сущности относятся друг к другу — не по тем же семи формальным правилам?
Вообще, я уверен, что эти отношения (семь формальных правил) выявил очень хороший психотерапевт, возможно — женщина. Это было очень давно, задолго до появления самого понятия информационных технологий. И самое интересное, что эти отношения живут вне базы данных и ИТ — последние лишь используют их для моделирования информационных систем.
Но мы немного отошли от темы. Я лишь призываю в момент создания новой системы подойти к этому процессу с душой. И тогда поверьте, случится момент творения. Спроектированная таким образом система будет живее всех живых в цифровом мире.
Послесловие
Диаграммы для примеров были реализованы с помощью инструмента Database Diagram Tool for SQL Server. Однако, подобный функционал есть и в DBeaver.