Хватит всё подряд называть ИИ

Большинство менеджеров и маркетологов называют искусственным интеллектом всё подряд: пылесосы, игрушечных роботов-трансформеров и даже подбор мобильных тарифов. Это в тренде и хорошо продаётся, только одна проблема — даже учёные не рискуют говорить, что создали ИИ.
Решили разобраться в определениях: можем ли мы вообще говорить об искусственном интеллекте, чем он отличается от машинного обучения и справедливо ли презрительно поднимать брови, когда мы видим очередную рекламу с ИИ.
ИИ для Википедии
Определение искусственного интеллекта из Википедии абстрактно и универсально, как гороскоп.
Искусственный интеллект — это наука и технология создания интеллектуальных машин, особенно интеллектуальных компьютерных программ.
Такая формулировка ни о чём не говорит, потому что неясно, что считать «интеллектуальным» в мире машин. В Википедии про интеллект пишут как про качество психики, а этой штукой обладают только живые существа.
Интеллект (от лат. intellectus «восприятие»; «разумение», «понимание»; «понятие», «рассудок») или ум — качество психики, состоящее из способности приспосабливаться к новым ситуациям, способности к обучению и запоминанию на основе опыта, пониманию и применению абстрактных концепций, и использованию своих знаний для управления окружающей человека средой.
Поэтому в поисках адекватного определения мы пошли на сайты лабораторий и институтов, изучающих искусственный интеллект.
ИИ для учёных
Глобально тема ИИ непростая, потому что даже среди специалистов до сих пор нет общепризнанного определения — каждый понимает искусственный интеллект по-своему.
Поэтому мы решили посмотреть, что изучают лаборатории и кафедры, которые занимаются исследованием ИИ: Московский физико-технический институт, Центр речевых технологий в ИТМО, ИСА РАН, лаборатории в компаниях и корпорациях (например, Сбербанк, Samsung, ВКонтакте) и другие заведения.
В область их изучения, например, попадают:
1) Предиктивная аналитика — интеллектуальный анализ данных, на основе которого алгоритмы могут сделать прогноз. Например, когда Сбербанк принимает решение о выдаче кредита, их технология Big Five анализирует соцсети клиента, составляет психологический портрет и оценивает его благонадёжность.
2) Рекомендательные системы — алгоритмы, которые подбирают объекты под пользователя: контент, товары и предложения. Мы все с этим знакомы: если в минуту нетрезвой грусти поставить на YouTube «Выйду ночью в поле с конем», хостинг запомнит вас как фаната «Любэ» и предложит послушать про батяню комбата.
3) Компьютерное зрение и распознавание изображений — область ИИ, которая обучает компьютеры интерпретировать и «понимать» визуальный мир. Используется, например, в беспилотных автомобилях или в сервисах вроде FindClone, который находит людей во ВКонтакте по фотографии.
4) Синтез, распознавание и генерация речи — то, что умеют делать Siri, Алиса и другие виртуальные ассистенты (подробнее о работе подобных алгоритмов и нашей Lia мы писали в предыдущей статье).
Мы видим, что термин искусственный интеллект используют в задачах, где система анализирует данные и на основе этого принимает «умные» решения.
Но ни один исследователь не говорит, что он создал ИИ — институты лишь изучают алгоритмы, которые выполняют задачи из области ИИ.
ИИ и машинное обучение
Нередко ИИ путают с машинным обучением, но это неверно. ML часто применяется для этих задач, потому что с его помощью удобно провести анализ информации и принять решение. Например, ml-алгоритм предскажет, что с 98% вероятностью человек на картинке — это пользователь смартфона. Значит, телефон можно разблокировать.
Но учёные не приравнивают ML к ИИ. Для них искусственный интеллект — область исследований о том, как заставить машину выполнять нетривиальные задачи. А ML — класс алгоритмов, которые служат для их решения (как винтики в часах).
ИИ для снобов
Те, кто любит докапываться, говорят: «Этот пылесос не умный, потому что он не может приготовить лазанью или поспорить о Канте. ИИ должен быть как оракул, который готов ответить на любой вопрос и решить любую задачу».
Такой идеалистический образ машины как суперчеловека пришёл к нам из кинематографа и искусства. Романтика ИИ — это смышленая робо-девушка из фильма «Она» или «Терминатор», готовый разрулить все проблемы одной левой. Это тебе не чат-бот, который ломается при первом же запросе мимо сценария.
Для того, что снобы имеют в виду под искусственным интеллектом, есть специальное определение: сильный искусственный интеллект или general artificial intelligence. Утопический алгоритм, который справится с любой задачей без подсказок: тот самый герой, способный на всё. Как человек, только непогрешимый.
Теория сильного искусственного интеллекта предполагает, что компьютеры могут приобрести способность мыслить и осознавать себя как отдельную личность (в частности, понимать собственные мысли), хотя и не обязательно, что их мыслительный процесс будет подобен человеческому.
Обычный или как его называют «слабый» искусственный интеллект отличается от «сильного» тем, что пишется под конкретные задачи: например, у беспилотника один алгоритм анализирует дорогу, а другой на основе этих данных понимает, куда ехать. Да, это ML — и да, из области ИИ. Но в отличие от general artificial intelligence не сможет действовать в условиях неопределенности: воспитывать детей или спасать мир.
Возможно, простой ИИ называют слабым потому, что он не оправдывает человеческих надежд. Пока нет сильного интеллекта, нам остаются только простенькие роботы — они хорошо притворяются, но все, кто общался с чат-ботами или даже с Алисой знают, как легко их раскусить.
Хотя маркетологи, конечно, о слабостях не говорят.
ИИ для маркетологов
Менеджеры и маркетологи называют ИИ все smart-девайсы и любую умную фигню, которая умеет что-то делать сама: по квартире ездить, свет включать, товар подбирать.
Недавний пример из рекламного мира: Искусственный интеллект МТС сформирует для вас персональный тариф.
ИИ здесь можно заменить словами «алгоритм» или «ассистент» — для пользователя суть не поменяется, это просто красивое слово.
На баннере, конечно, не пишут, что у МТС под капотом — может, у них есть свой штатный Терминатор. Но скептичные программисты сразу понимают, что скорее всего это несложная реализация, основанная на известных алгоритмах.
Мы ожидаем, что искусственный интеллект будет нас удивлять, а называть им топорные методы это как минимум наивно. Но маркетологи никогда не были скромными (или даже реалистичными).
Как правильно
Искусственный интеллект только начали изучать, поэтому всерьез говорить об ИИ в рекламе всё равно, что называть школьника «начинающим магистром».
Тогда как правильно? Мы думаем, что на данный момент в разговорах об ИИ грамотнее всего использовать определение «алгоритмы машинного обучения» или говорить, что технология построена на алгоритмах ИИ — за это эксперт вам поставит плюс.
Потенциальные пользователи тоже скажут спасибо: несправедливо, что менеджеры ставят большую идею об искусственном интеллекте в один ряд с «умным» пылесосом.
Ведь до настоящего (сильного) искусственного интеллекта нам ещё далеко.
Всё, что вам нужно знать об ИИ — за несколько минут

Приветствую читателей Хабра. Вашему вниманию предлагается перевод статьи «Everything you need to know about AI — in under 8 minutes.». Содержание направлено на людей, не знакомых со сферой ИИ и желающих получить о ней общее представление, чтобы затем, возможно, углубиться в какую-либо конкретную его отрасль.
Знать понемногу обо всё иногда (по крайней мере, для новичков, пытающихся сориентироваться в популярных технических направлениях) бывает полезнее, чем знать много о чём-то одном.
Многие люди думают, что немного знакомы с ИИ. Но эта область настолько молода и растёт так быстро, что прорывы совершаются чуть ли не каждый день. В этой научной области предстоит открыть настолько многое, что специалисты из других областей могут быстро влиться в исследования ИИ и достичь значимых результатов.
Эта статья — как раз для них. Я поставил себе целью создать короткий справочный материал, который позволит технически образованным людям быстро разобраться с терминологией и средствами, используемыми для разработки ИИ. Я надеюсь, что этот материал окажется полезным большинству интересующихся ИИ людей, не являющихся специалистами в этой области.
Введение
Искусственный интеллект (ИИ), машинное обучение и нейронные сети — термины, используемые для описания мощных технологий, базирующихся на машинном обучении, способных решить множество задач из реального мира.
В то время, как размышление, принятие решений и т.п. сравнительно со способностями человеческого мозга у машин далеки от идеала (не идеальны они, разумеется, и у людей), в недавнее время было сделано несколько важных открытий в области технологий ИИ и связанных с ними алгоритмов. Важную роль играет увеличивающееся количество доступных для обучения ИИ больших выборок разнообразных данных.
Область ИИ пересекается со многими другими областями, включая математику, статистику, теорию вероятностей, физику, обработку сигналов, машинное обучение, компьютерное зрение, психологию, лингвистику и науку о мозге. Вопросы, связанные с социальной ответственностью и этикой создания ИИ притягивают интересующихся людей, занимающихся философией.
Мотивация развития технологий ИИ состоит в том, что задачи, зависящие от множества переменных факторов, требуют очень сложных решений, которые трудны к пониманию и сложно алгоритмизируются вручную.
Растут надежды корпораций, исследователей и обычных людей на машинное обучение для получения решений задач, не требующих от человека описания конкретных алгоритмов. Много внимания уделяется подходу «чёрного ящика». Программирование алгоритмов, используемых для моделирования и решения задач, связанных с большими объёмами данных, занимает у разработчиков очень много времени. Даже когда нам удаётся написать код, обрабатывающий большое количество разнообразных данных, он зачастую получается очень громоздким, трудноподдерживаемым и тяжело тестируемым (из-за необходимости даже для тестов использовать большое количество данных).
Современные технологии машинного обучения и ИИ вкупе с правильно подобранными и подготовленными «тренировочными» данными для систем могут позволить нам научить компьютеры «программировать» за нас.

Обзор
Интеллект — способность воспринимать информацию и сохранять её в качестве знания для построения адаптивного поведения в среде или контексте
Это определение интеллекта из (англоязычной) Википедии может быть применено как к органическому мозгу, так и к машине. Наличие интеллекта не предполагает наличие сознания. Это — распространённое заблуждение, принесённое в мир писателями научной фантастики.
Попробуйте поискать в интернете примеры ИИ — и вы наверняка получите хотя бы одну ссылку на IBM Watson, использующий алгоритм машинного обучения, ставший знаменитым после победы на телевикторине под названием «Jeopardy» в 2011 г. С тех пор алгоритм претерпел некоторые изменения и был использован в качестве шаблона для множества различных коммерческих приложений. Apple, Amazon и Google активно работают над созданием аналогичных систем в наших домах и карманах.
Обработка естественного языка и распознавание речи стали первыми примерами коммерческого использования машинного обучения. Вслед за ними появились задачи другие задачи автоматизации распознавания (текст, аудио, изображения, видео, лица и т.д.). Круг приложений этих технологий постоянно растёт и включает в себя беспилотные средства передвижения, медицинскую диагностику, компьютерные игры, поисковые движки, спам-фильтры, борьбу с преступностью, маркетинг, управление роботами, компьютерное зрение, перевозки, распознавание музыки и многое другое.
ИИ настолько плотно вошёл в современные используемые нами технологии, что многие даже не думают о нём как об «ИИ», то есть, не отделяют его от обычных компьютерных технологий. Спросите любого прохожего, есть ли искусственный интеллект в его смартфоне, и он, вероятно, ответит: «Нет». Но алгоритмы ИИ находятся повсюду: от предугадывания введённого текста до автоматического фокуса камеры. Многие считают, что ИИ должен появиться в будущем. Но он появился некоторое время назад и уже находится здесь.
Термин «ИИ» является довольно обобщённым. В фокусе большинства исследований сейчас находится более узкое поле нейронных сетей и глубокого обучения.
Как работает наш мозг
Человеческий мозг представляет собой сложный углеродный компьютер, выполняющий, по приблизительным оценкам, миллиард миллиардов операций в секунду (1000 петафлопс), потребляющий при этом 20 Ватт энергии. Китайский суперкомпьютер под названием «Tianhe-2» (самый быстрый в мире на момент написания статьи) выполняет 33860 триллионов операций в секунду (33.86 петафлопс) и потребляющий при этом 17600000 Ватт (17.6 Мегаватт). Нам предстоит проделать определённое количество работы перед тем, как наши кремниевые компьютеры смогут сравниться со сформировавшимися в результате эволюции углеродными.
Точное описание механизма, применяемого нашим мозгом для того, чтобы «думать» является предметом дискуссий и дальнейших исследований (лично мне нравится теория о том, что работа мозга связана с квантовыми эффектами, но это — тема для отдельной статьи). Однако, механизм работы частей мозга обычно моделируется с помощью концепции нейронов и нейронных сетей. Предполагается, что мозг содержит примерно 100 миллиардов нейронов.
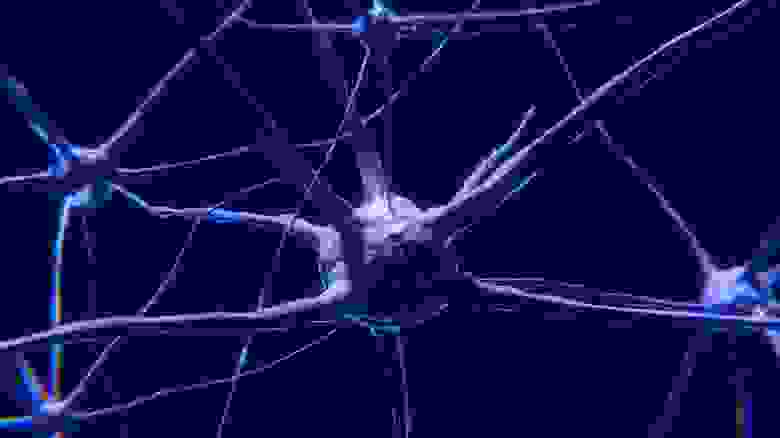
Нейроны взаимодействуют друг с другом с помощью специальных каналов, позволяющих им обмениваться информацией. Сигналы отдельных нейронов взвешиваются и комбинируются друг с другом перед тем, как активировать другие нейроны. Эта обработка передаваемых сообщений, комбинирование и активация других нейронов повторяется в различных слоях мозга. Учитывая то, что в нашем мозгу находится 100 миллиардов нейронов, совокупность взвешенных комбинаций этих сигналов устроена довольно сложно. И это ещё мягко сказано.
Но на этом всё не заканчивается. Каждый нейрон применяет функцию, или преобразование, к взвешенным входным сигналам перед тем, как проверить, достигнут ли порог его активации. Преобразование входного сигнала может быть линейным или нелинейным.
Изначально входные сигналы приходят из разнообразных источников: наших органов чувств, средств внутреннего отслеживания функционирования организма (уровня кислорода в крови, содержимого желудка и т.д.) и других. Один нейрон может получать сотни тысяч входных сигналов перед принятием решения о том, как следует реагировать.
Мышление (или обработка информации) и полученные в результате его инструкции, передаваемые нашим мышцам и другим органам являются результатом преобразования и передачи входных сигналов между нейронами из различных слоёв нейронной сети. Но нейронные сети в мозгу могут меняться и обновляться, включая изменения алгоритма взвешивания сигналов, передаваемых между нейронами. Это связано с обучением и накоплением опыта.
Эта модель человеческого мозга использовалась в качестве шаблона для воспроизведения возможностей мозга в компьютерной симуляции — искуственной нейронной сети.
Искусственные Нейронные Сети (ИНС)
Искусственные Нейронные Сети — это математические модели, созданные по аналогии с биологическими нейронными сетями. ИНС способны моделировать и обрабатывать нелинейные отношения между входными и выходными сигналами. Адаптивное взвешивание сигналов между искусственными нейронами достигается благодаря обучающемуся алгоритму, считывающему наблюдаемые данные и пытающемуся улучшить результаты их обработки.
Для улучшения работы ИНС применяются различные техники оптимизации. Оптимизация считается успешной, если ИНС может решать поставленную задачу за время, не превышающее установленные рамки (временные рамки, разумеется, варьируются от задачи к задаче).
ИНС моделируется с использованием нескольких слоёв нейронов. Структура этих слоёв называется архитектурой модели. Нейроны представляют собой отдельные вычислительные единицы, способные получать входные данные и применять к ним некоторую математическую функцию для определения того, стоит ли передавать эти данные дальше.
В простой трёхслойной модели первый слой является слоем ввода, за ним следует скрытый слой, а за ним — слой вывода. Каждый слой содержит не менее одного нейрона.
С усложнением структуры модели посредством увеличения количества слоёв и нейронов возрастают потенциал решения задач ИНС. Однако, если модель оказывается слишком «большой» для заданной задачи, её бывает невозможно оптимизировать до нужного уровня. Это явление называется переобучением (overfitting).
Архитектура, настройка и выбор алгоритмов обработки данных являются основными составляющими построения ИНС. Все эти компоненты определяют производительность и эффективность работы модели.
Модели часто характеризуются так называемой функцией активации. Она используется для преобразования взвешенных входных данных нейрона в его выходные данные (если нейрон решает передавать данные дальше, это называется его активацией). Существует множество различных преобразований, которые могут быть использованы в качестве функций активации.
ИНС являются мощным средством решения задач. Однако, хотя математическая модель небольшого количества нейронов довольно проста, модель нейронной сети при увеличении количества составляющих её частей становится довольно запутанно. Из-за этого использование ИНС иногда называют подходом «чёрного ящика». Выбор ИНС для решения задачи должен быть тщательно обдуманным, так как во многих случаях полученное итоговое решение нельзя будет разобрать на части и проанализировать, почему оно стало именно таким.

Глубокое обучение
Термин глубокое обучение используется для описания нейронных сетей и используемых в них алгоритмах, принимающих «сырые» данные (из которых требуется извлечь некоторую полезную информацию). Эти данные обрабатываются, проходя через слои нейросети, для получения нужных выходных данных.
Обучение без учителя (unsupervised learning) — область, в которой методики глубокого обучения отлично себя показывают. Правильно настроенная ИНС способна автоматически определить основные черты входных данных (будь то текст, изображения или другие данные) и получить полезный результат их обработки. Без глубокого обучения поиск важной информации зачастую ложится на плечи программиста, разрабатывающего систему их обработки. Модель глубокого обучения же самостоятельно способна найти способ обработки данных, позволяющий извлекать из них полезную информацию. Когда система проходит обучение (то есть, находит тот самый способ извлекать из входных данных полезную информацию), требования к вычислительной мощности, памяти и энергии для поддержания работы модели сокращаются.
Проще говоря, алгоритмы обучения позволяют с помощью специально подготовленных данных «натренировать» программу выполнять конкретную задачу.
Глубокое обучение применяется для решения широкого круга задач и считается одной из инновационных ИИ-технологий. Существуют также другие виды обучения, такие как обучение с учителем (supervised learning) и обучение с частичным привлечением учителя(semi-supervised learning), которые отличаются введением дополнительного контроля человека за промежуточными результатами обучения нейронной сети обработке данных (помогающего определить, в правильном ли направлении движется система).
Теневое обучение (shadow learning) — термин, используемый для описания упрощённой формы глубокого обучения, при которой поиск ключевых особенностей данных предваряется их обработкой человеком и внесением в систему специфических для сферы, к которой относятся эти данные, сведений. Такие модели бывают более «прозрачными» (в смысле получения результатов) и высокопроизводительными за счёт увеличения времени, вложенного в проектирование системы.
На что способен искусственный интеллект сегодня и каков его потенциал

Три типа искусственного интеллекта
На сегодняшний день искусственный интеллект ученые определяют, как алгоритмы, способные самообучаться, чтобы применять эти знания для достижения поставленных человеком целей. Системы машинного обучения (основной подраздел ИИ) автоматизировали процессы во всех жизненно важных областях, включая банкинг, ретейл, медицину, безопасность, промышленность.
Выделяют три вида искусственного интеллекта: слабый (Narrow AI), сильный (AGI) и супер-ИИ (Super AI).
Первый вид используются повсеместно (включая голосовых ассистентов, рекламу в соцсетях, распознавание лиц, поиск романтических партнеров в приложениях и так далее); эти системы слабого ИИ единственные доступные на сегодня.
Сильный ИИ максимально приближен к способностям человеческого интеллекта и наделен по классическому определению Тьюринга самосознанием; по мнению экспертов, AGI сформируется примерно к 2075 году, а спустя еще 30 лет придет время для супер-ИИ.
Супер-ИИ мог бы не просто стать подобным людям, но и превзойти лучшие умы человечества во всех областях, при этом перепрограммируя самого себя, продолжая совершенствоваться и, вероятно, разрабатывая новые системы и алгоритмы самостоятельно.
На что способен искусственный интеллект уже сейчас
Оценить динамику может каждый, кто пользуется автоматическими переводчиками. Еще лет пять назад Google Translate более-менее сносно справлялся с отдельными наборами фраз и предложениями, тогда как сегодня программа переводит большие смысловые блоки, нейросети учитывают контекст, оперируют огромными массивами статистических данных. Сейчас можно читать статьи на хинди, китайском, арабском, не зная языка.
ИИ давно используется в финансовой сфере для оценки платежеспособности заемщика. Есть вам отказали в выдаче кредита на первом этапе ― вас отсеял именно искусственный интеллект. В США в некоторых штатах ИИ применяют в судебной системе для оценки продолжительности тюремных сроков для обвиняемых.
Алгоритмы помогают врачам ставить диагнозы. Например, «СберМедИИ» (входит в экосистему «Сбера») и Лаборатория по искусственному интеллекту Сбербанка совместно разработали приложение AI Resp: нейросеть анализирует голос пациента, дыхание и кашель, чтобы определить вероятность коронавирусной инфекции. Ранее Лаборатория по ИИ и «СберМедИИ» представили онлайн-сервис «КТ Легких», определяющий локализацию и степень поражения легких для диагностики вирусной пневмонии, в том числе COVID-19, по снимкам компьютерной томографии. Также при использовании этого сервиса ИИ позволяет выявлять онкологические заболевания на ранней стадии при анализе КТ грудной клетки и может помогать врачам при диагностике.
На данный момент разработано несколько значимых технологий в сфере искусственного интеллекта.

Искусственный интеллект превосходит людей по IQ и креативности: в викторинах он набирает на 40% больше баллов, по вопросам SAT (тест для оценки знаний абитуриентов США) — на 15% больше баллов, чем средний абитуриент колледжа.
Роль ИИ в экономике
Влияние пандемии на внедрение ИИ в бизнесе
Кризис только ускорил внедрение ИИ, и этот импульс сохранится в дальнейшем, показывают опросы: большинство компаний (52%) стали быстрее внедрять ИИ из-за пандемии, 86% респондентов утверждают, что ИИ становится «основной технологией» в их компании.
Почти три четверти бизнес-лидеров положительно оценивают роль ИИ после пандемии и сопутствующего кризиса. Большинство руководителей (74%) не только ожидают рост эффективности бизнес-процессов, но и создание новых бизнес-моделей (55%), новых продуктов и услуг (54%) — благодаря внедрению ИИ.
По мнению экспертов Оксфордского университета, к 2026 году ИИ напишет эссе, которое сойдет за написанное человеком, заменит водителей грузовиков к 2027 году и станет выполнять работу хирурга к 2053 году. Также ИИ превзойдет людей во всех задачах в течение 45 лет и автоматизирует все рабочие места в течение 120 лет.
Консалтинговая компания Accenture утверждает, что ИИ способен увеличить прибыль компаний в среднем на 38%. По словам экспертов и представителей бизнеса, ИИ помогает компаниям прогнозировать и выявлять проблемы, а также восполняет нехватку навыков сотрудников, хотя до построения бизнес-стратегии искусственным интеллектом еще далеко.
Большинство опрошенных компаний инвестируют в ИИ (90%) и согласны с тем, что данные технологии способствуют развитию бизнеса, выяснили MIT Sloan Management Review и BCG. Тем не менее, компании так и не научились извлекать из ИИ реальную выгоду. И это не единственный проблемный момент в сфере искусственного интеллекта.

Основные вызовы технологии ИИ
Бизнес-процессы
Чтобы компания извлекала прибыль, недостаточно вложить средства в алгоритм и получить первые успешные результаты после запуска пилотного проекта. Внедрение ИИ — это многоуровневый процесс, включающий культурные изменения в компании, найм и обучение специалистов по data science, автоматизацию и построение бизнес-процессов с учетом алгоритмов, и на этом весь список не заканчивается.
«Говоря о внедрениях, необходимо приложить усилия в пропорциях 10–20–70. То есть, примерно 10% усилий должно уйти на создание алгоритма, 20% на построение технологии и 70% на организацию бизнес-процессов. Компания должна быть на определенном уровне технологической зрелости для того, чтобы внедрение ИИ приносило пользу», — говорит Леонид Жуков, генеральный директор Института Искусственного Интеллекта AIRI, старший управляющий директор Лаборатории по искусственному интеллекту Сбербанка.
Выступая на международной конференции Сбера AI Journey 2021, Юрген Шмидхубер, ученый в области искусственного интеллекта, главный научный советник Института Искусственного Интеллекта AIRI и научный руководитель компании NNAISENSE отметил, что компании в основном сосредоточены на своих частных проблемах, а не на развитии технологий искусственного интеллекта: большая часть их прибыли от ИИ приходится на маркетинг и продажу рекламы.
Такие гиганты как Alibaba, Amazon, Facebook, Google массово используют глубокие искусственные нейронные сети, например, Long-Short-Term Memory, чтобы предсказать спрос пользователей и дольше удерживать их на своих платформах, заставляя переходить по большему количеству рекламных объявлений.
Нехватка специалистов
ИИ развивается с высокой скоростью, и то, что называлось полгода назад state-of-the-art (высшим уровнем развития), сегодня может оказаться средней разработкой. Если раньше в сфере искусственного интеллекта была занята узкая прослойка специалистов, сейчас при таком огромном спросе попросту не хватает квалифицированных кадров, способных справиться с постоянно развивающейся технологией, отмечает Жуков.

Спрос на ИИ-специалистов вырос на 74% за 2016–2019 годы, сейчас две из пяти компаний, использующих ИИ на продвинутом уровне, отмечают острую нехватку специалистов, трудности с наймом также возглавляют список проблем в области ИИ.
Проблемы машинного обучения
Качество данных — второе по значимости препятствие для внедрения ИИ, после нехватки специалистов. Для успешных результатов алгоритмам необходимы качественные «вводные», включая размеченные и чистые данные. Неправильно заданные паттерны могут провоцировать систему делать ложные выводы: например, ошибочно сигнализировать о мошеннической транзакции, или осудить невиновного.
На качество влияет и степень предвзятости, или bias, включая гендерные и расовые предрассудки, которым может быть подвержен человек, работающий с алгоритмом.

Количество данных. Помимо качества, компьютеру все еще требуется большой объем данных и ресурсов для выполнения простейших задач. Отличать собак от кошек ИИ научится за три дня, задействуя 10 млн изображений и 16 000 компьютеров, в то время как ребенку хватило бы пары фотографий и нескольких минут. Если бы модель GPT-3 обучали читать и писать статьи не на суперкомпьютере, а на обычном ПК, весь процесс занял бы примерно 500 лет.
«На данный момент перед исследователями ИИ стоят несколько вызовов. Это умение искусственного интеллекта ставить перед собой новые задачи на основе имеющихся знаний; способность обучаться, не забывая полученные знания; и умение учиться разбивать цель на подцели. Преодоление этих проблем приблизит ученых к созданию таких машин, которые смогут лучше понимать человека и помогать достижению все более амбициозных целей», — отмечает Михаил Бурцев, директор по фундаментальным исследованиям Института Искусственного Интеллекта AIRI, заведующий Лабораторией нейронных систем и глубинного обучения МФТИ.
Применение в другом контексте. Хотя искусственный интеллект сегодня способен выполнять различные функции — от распознавания кошек и собак до предсказания поломок на нефтяных платформах, — это все еще узконаправленные задачи. ИИ пока что не умеет применять полученные навыки в непривычных условиях.
Влияние на климат
Проблема потребления энергии искусственным интеллектом напрямую связана с количеством ресурсов, задействованных в обработке данных. Обучение же одной NLP-модели (подобной GPT) требует столько же энергии, сколько автомобиль за весь его срок службы, и производит в пять раз больше CO2.
Во всем мире центры обработки данных потребляют около 200 ТВт·ч электроэнергии в год — больше, чем некоторые страны. В то же время, есть и противоположный эффект — ИИ поможет снизить выбросы парниковых газов на 1,5–4% к 2030 году, согласно отчету Европейского парламента.
Использование ИИ в науке
Машинное обучение стало ключевым инструментом исследователей из разных областей, однако потенциал ИИ в науке еще предстоит раскрыть, отмечает Леонид Жуков. Стимулирование новых открытий с помощью ИИ актуально, например, в области создания новых материалов при помощи вычислений или в прогнозировании изменений климата для разработки стратегий повышения устойчивости к изменениям окружающей среды. Например, в рамках стремления к достижению углеродной нейтральности, ученые из группы поиска новых материалов Института AIRI совместно со Сбербанком разработали прототипы моделей, позволяющих оптимизировать контроль качества на производстве солнечных батарей.
В перспективе машинное обучение может активнее применяться для охраны дикой природы в малодоступных регионах и подсчете особей, понимания сложной органической химии и в исследовании темной материи.