Опыт автоматизации регрессионного визуального тестирования на Java + Selenium Webdriver + aShot
В этой статье я бы хотел рассказать о своем опыте автоматизации визуального регрессионного тестирования.
Введение
Заняться автоматизацией визуального тестирования я решил после того, как случайно обнаружил небольшой баг в верстке. В проекте меняли дизайн одной страницы, и изменения задели не относящиеся к задаче страницы.
Решив, что проверять внешний вид страниц сайта вручную не вариант, я занялся автоматизацией.
Нужно было простое решение с удобными отчетами. Чтобы можно было писать автотесты без каких либо ограничений, сравнивать скриншоты страниц и элементов сайта и использовать разные браузеры.
После непродолжительных поисков готового решения / фреймворка было решено что проще будет написать свое решение с нужным функционалом и форматом отчетов. Из просмотренных вариантов подходящим показался только Galen Framework, но его я нашел уже после того как написал свое решение.
После внедрения и тестирования автотестов я решил немного доработать тесты и создать отдельный проект, чтобы потом использовать его на других сайтах и проектах.
О проекте
VisualRegressionBoilerplate — это относительно простой проект с определенной структурой.
Что-то вроде boilerplate шаблона / проекта для визуальных автотестов.
Проект предназначен для небольших сайтов / проектов. Для тех, кому нужно простое решение, без сложных фреймфорков.
Возможности
Используемые технологии
Как начать работать с проектом
Как писать тесты
В общем-то как угодно. Каких либо ограничений нет. Можно использовать паттерн page object или что-то другое.
Все что нужно, это использовать следующие функции для сравнения скриншотов:
Сравнение скриншотов страницы:
Сравнение скриншотов страницы с игнорированием одного элемента:
Сравнение скриншотов страницы с игнорированием нескольких элементов:
Сравнение скриншотов элемента страницы — элемент можно искать по css локатору
Либо можно передать объект класса WebElement
Возможные проблемы
Резюме
На данный момент в проекте примерно 50 тестов — страницы и разные элементы страниц.
Через баш скрипт автотесты запускаются и сайт тестируется сразу в трех расширениях (mobile, tablet, desktop).
Есть некоторые проблемы из-за динамичного контента и из-за того что некоторые элементы сайта не всегда успевают загружаться вовремя, но со своей задачей автотесты вполне справляются.
Зачем и как писать тесты? — Java: Автоматическое тестирование
Какую главную задачу должны решать тесты? Этот вопрос невероятно важен. Ответ на него даёт понимание того, как правильно писать тесты и как писать их не нужно.
Вот один из вариантов его реализации:
Что мы делаем после написания метода? Проверяем, как он работает. Например, пишем простейшую программу и пытаемся вызвать этот метод с различными аргументами:
Таким нехитрым способом убеждаемся, что метод работает. По крайней мере для тех аргументов, которые мы передали в него. Если во время проверки заметили ошибки, то исправляем метод и повторяем всё заново.
Фактически, весь этот процесс и есть тестирование. Но не автоматическое, а ручное. Задача такого тестирования — убедиться, что код работает как надо. И нам совершенно без разницы, как конкретно реализован этот метод. Это и есть главный ответ на вопрос, заданный в начале урока.
Тесты проверяют, что код (или приложение) работает корректно. И не заботятся о том, как конкретно написан код, который они проверяют.
Автоматические тесты
Всё, что требуется от автоматических тестов — повторить проверки, которые мы выполняли, делая ручное тестирование. Для этого достаточно старого доброго if и исключений.
Теперь для запуска теста вам достаточно лишь вызвать метод capitalizeTest() в вашем методе main и выполнить программу.
Из примера выше видно, что тесты — это точно такой же код, как и любой другой. Он подчиняется тем же правилам, например, стандартам кодирования. А ещё он может содержать ошибки. Но это не значит, что надо писать тесты на тесты. Избежать всех ошибок невозможно, да и не нужно, иначе стоимость разработки стала бы неоправданно высокой. Обнаруженные ошибки в тестах исправляются, и жизнь продолжается дальше 😉
В коде тесты, как правило, складывают в специальную директорию. Обычно она называется tests, хотя встречаются и другие варианты. В наших упражнениях дерево проекта будет выглядеть вот так:
Структура этой директории зависит от того, на базе чего пишутся тесты, например, на базе какого фреймворка. В простых случаях, она отражает структуру исходного кода. Если предположить, что наш метод capitalize(text) определён в файле src/hexlet/SomeClass.java, то его тест лучше поместить в файл tests/hexlet/SomeClassTest.java. Слово Test в имени класса с тестами, используется только для более явного обозначения цели файла.
В этом уроке мы не будем пока пользоваться фреймворками и, чтобы упростить компиляцию и запуск программы, мы будем рассматривать вот такое упрощённое дерево проекта:
Теперь при любых изменениях, затрагивающих тестируемый метод, важно не забывать компилировать и запускать тесты. Если всё хорошо, то код молча выполнится, а если есть ошибка, то будет выведено сообщение об ошибке.
Как пишутся тесты
Тесты — это не магия. Нам, как разработчикам, нужно самостоятельно импортировать тестируемые методы, вызывать их с необходимыми аргументами и проверять, что методы возвращают ожидаемые значения.
Если поменялась сигнатура метода (входные или выходные параметры, его имя), то придётся переписывать тесты. Если сигнатура осталась той же, но поменялись внутренности метода:
Тогда тесты должны продолжать работать без изменений.
Хорошие тесты ничего не знают про внутреннее устройство проверяемого кода. Это делает их более универсальными и надёжными.
Сколько и какие нужно писать проверки?
Невозможно написать тесты, которые гарантируют 100% работоспособность кода. Для этого потребовалось бы реализовать проверки всех возможных аргументов, что физически неосуществимо. С другой стороны, без тестов вообще нет никаких гарантий, только честное слово разработчиков.
При написании тестов нужно ориентироваться на разнообразие входных данных. У любого метода есть один или несколько основных сценариев использования. Например, в случае capitalize — это любое слово. Достаточно написать ровно одну проверку, которая покрывает этот сценарий. Дальше нужно смотреть на «пограничные случаи». Это ситуации, в которых код может повести себя по-особенному:
Для capitalize пограничным случаем будет пустая строка:
Добавив тест на пустую строку, мы увидим, что вызов показанного в начале урока метода capitalize завершается с ошибкой. Внутри него идёт обращение к первому индексу строки без проверки его существования. Исправленная версия кода:
В большом числе ситуаций пограничные случаи требуют отдельной обработки, наличия условных конструкций. Тесты должны быть построены таким образом, чтобы они затрагивали каждую такую конструкцию. Но не забывайте, что условные конструкции могут порождать хитрые связи. Например, два независимых условных блока порождают 4 возможных сценария:
Комбинация всех возможных вариантов поведения метода называется цикломатической сложностью. Это число показывает все возможные пути кода внутри метода. Цикломатическая сложность — хороший ориентир для понимания того, сколько и какие тесты нужно написать.
Иногда пограничные случаи не связаны с условными конструкциями. Особенно часто такие ситуации встречаются там, где есть вычисления границ слов или массивов. Такой код может работать в большинстве ситуаций, но только в некоторых может давать сбой:
Собирая всё вместе
В конечном итоге в этом уроке мы получили такую структуру директорий:
Автоматизация тестирования с нуля. Часть 1
Добрый день, уважаемые читатели.
Хочу рассказать об опыте построения системы автоматизации тестирования, когда на проекте или совсем нет тестирования, или ее степень минимальная.
Надеюсь статьи будет полезна начинающим автотестерам.
Когда делать автотесты?
Краткий ответ — как можно раньше.
А полный будет раскрыть ниже. В любом случае, когда проект работает 3 года, и все проверялось вручную, жить становится очень монотонно. И парк из 5000 сценариев автоматизировать за месяц-два проблематично. Как правило в таких проектах придется начинать прорабатывать сценарии заново. Потому что это окажется быстрее. И не факт, что старые получится автоматизировать без существенных изменений.
Почему?
Потому что автотетсы:
Накопленные сценарии
Чем больше парк автоматизированных сценариев, там больше вероятность найти регрессию, особенно если при каждом запуске данные изменяются.
Если автотест проходил стабильно и на какой-то ветке упал, то или меняли требования, или баг, или инфраструктура подвела.
Непредвзятость
Если меняли требования — автотест должен отправиться на переделку вместе с переделкой основного функционала. Именно поэтому тестировщики принимают участи в согласовании ТЗ.
Если прогон теста автоматически линкуется к задаче, то никто не сможет сказать, что это не тестировалось. Или наоборот, сможет. В общем проблем точно становится меньше.
Скорость
Если каждый тест удовлетворяет занудным условиям:
Предусловие — Тест — Постусловие
То такие тесты легко автоматизировать.
А потом легко распараллелить. Потому что они получаются независимыми.
Количество потоков — сколько выдержат тестовые сервера и чтобы не мешать другим.
Второй момент это сама по себе скорость. В ручном режиме прокликать создание товара, его поиск и покупку в интернет магазине это 5 минут. 4 браузера. Итого 20 минут. На всего лишь одном небольшом сценарии.
Автотест по этому сценарию проходит за 1,5 минуты. Но на 8 браузерах. (Последняя и предпоследняя версии каждого браузера).
С чего начать?
С пользовательских сценариев.
Ценность атомарных тестов все время падает, особенно на микросервисах. И вообще, в идеальном мире это зона ответственности программиста. Такие ошибки должны быть обнаружены на этапе юнит-тестирования.
QA должен работать от user story. Потому что программист обычно и не знает ее, и не хочет знать.
Соответственно логика 1 тест — 1 пользовательский кейс (бизнес сценарий) наиболее приближена к реальности.
Есть конечно сложности с подготовкой данных, например в случае интернет-магазина процесс оплаты картой требует наличия вещей в корзине, и или данных для нового пользователя, или данных авторизации существующего.
Да, иногда предусловия занимают больше времени, чем тест, но при переиспользовании сценариев сложности не несет.
Какие сценарии автоматизировать
Наименее подверженные изменениям в ближайшей перспективе. Чтобы автоматизация хоть сколько-то прожила.
Или наиболее часто используемые. Есть смысл помогать ручному тестированию в генерации тестовых данных. Например в доске объявлений есть смысл автоматизировать создание объявлений, т.к. далее любой сценарий требует созданного объявления.
Что конкретно делать?
Обычно в проектах есть
Поэтому предлагаю заняться Бэкэндом и Фронтом.
Выбираем сценарий
Допустим, у нас есть интернет-магазин.
Есть админка, есть клиентский и админский фронт.
Есть API, которое все это обслуживает.
С чего начать автоматизацию?
Есть клиенты, есть сотрудники.
У клиента первый кейс — просмотр и поиск товара, добавление его в корзину, и оформление.
У сотрудника самый распространенный кейс — добавление карточки товара.
Какой кейс автоматизируем первым? И как?
Самое важное для магазина — продажи.
Поэтому клиентская история наиболее важна для бизнеса. Поэтому найти товар, поместить в корзину и завершить оформление с любым способом оплаты это первое, что нужно сделать.
По API. Но без фронта. Тут можно поспорить, но скорее всего дизайн поменяется 2-3 раза еще, а вот бэкэнд вряд ли. Так что на 1 этапе придется интерфейс проверять вручную.
Далее сделать проверки на API редактирования карточки товара и ее фронт.
И вернуться к клиентскому. На этом этапе уже будет статистика наиболее частых действий пользователей, и наиболее частых путей клиента. Да, Яндекс Метрика и Вебвизор помогают и тестировщикам.
Нет никакого смысла на первом этапе проверять, работает ли функция оплаты на счет фирмы через сгенерированную платежку, если этой функцией пользуется 0,5% посетителей. Конечно можно задать менеджеру вопрос зачем это тут нужно, но тут не об этом.
Допустим у нас 40% человек платят на сайте картой, 30% наличкой, 20% наложенным платежом и 10% все остальные способы.
Какой тип оплаты будем проверять первым? Конечно картой.
То есть мы должны четко представлять, какой сценарий самый важный для бизнеса в данный момент. И его качество обеспечивать в первую очередь.
Постусловия
Мы насоздавали всего-всего в тестах. Намусорили. Надо бы за собой убрать. Нужно заранее предусмотреть, в каких тестах мы будем за собой убирать, а в каких — нет.
Если товар можно оставить в магазине, и ничего страшного не произойдет, то добавление прав администратора обычному пользователю нужно вернуть. А то следующий тест, связанный с правами может упасть. Или хуже — пройти позитивно, хотя должен был упасть.
Странности
Есть странный подход, когда автоматизируют сценарии, в которых пользователи находили баг. Обычно это очень экзотические сценарии, и тратить ресурс на них нет смысла. Была ситуация когда сломался функционал обновления данных банка-контрагента. Сбоила синхронизация со справочником БИК.
То есть новый БИК не обновлялся. Но новый банк заводился нормально.
Есть ли смысл автоматизировать этот сценарий? Если контрагенты меняются каждый день — может быть. И тогда это была недоработка планирования.
Если это делается 5-6 раз в год, то может лучше более приоритетной задачей заняться?
Что будет дальше?
В следующей статье я расскажу как быстро начать тестировать API, встроить эти тесты в релизы, распараллелить тесты, как подбирать данные для тестов и что нам это даст.
Напомню про эффект пестицида, и как его свети к минимуму.
Технологии: Java + maven + testng + allure + RestAssured + Pict.
Пишем автотест с использованием Selenium Webdriver, Java 8 и паттерна Page Object
В этой статье рассматривается создание достаточного простого автотеста. Статья будет полезна начинающим автоматизаторам.
Материал изложен максимально доступно, однако, будет значительно проще понять о чем здесь идет речь, если Вы будете иметь хотя бы минимальные представления о языке Java: классы, методы, etc.
Создание проекта
Запустим Intellij IDEA, пройдем первые несколько пунктов, касающихся отправки статистики, импорта проектов, выбора цветовой схемы и т.д. — просто выберем параметры по умолчанию.
В появившемся в конце окне выберем пункт «Create New Project», а в нем тип проекта Maven. Окно будет иметь вид:
Нажмем «Next». Откроется следующее окно:
Groupid и Artifactid — идентификаторы проекта в Maven. Существуют определенные правила заполнения этих пунктов:
Нажмем «Finish»: IDE автоматически откроет файл pom.xml:
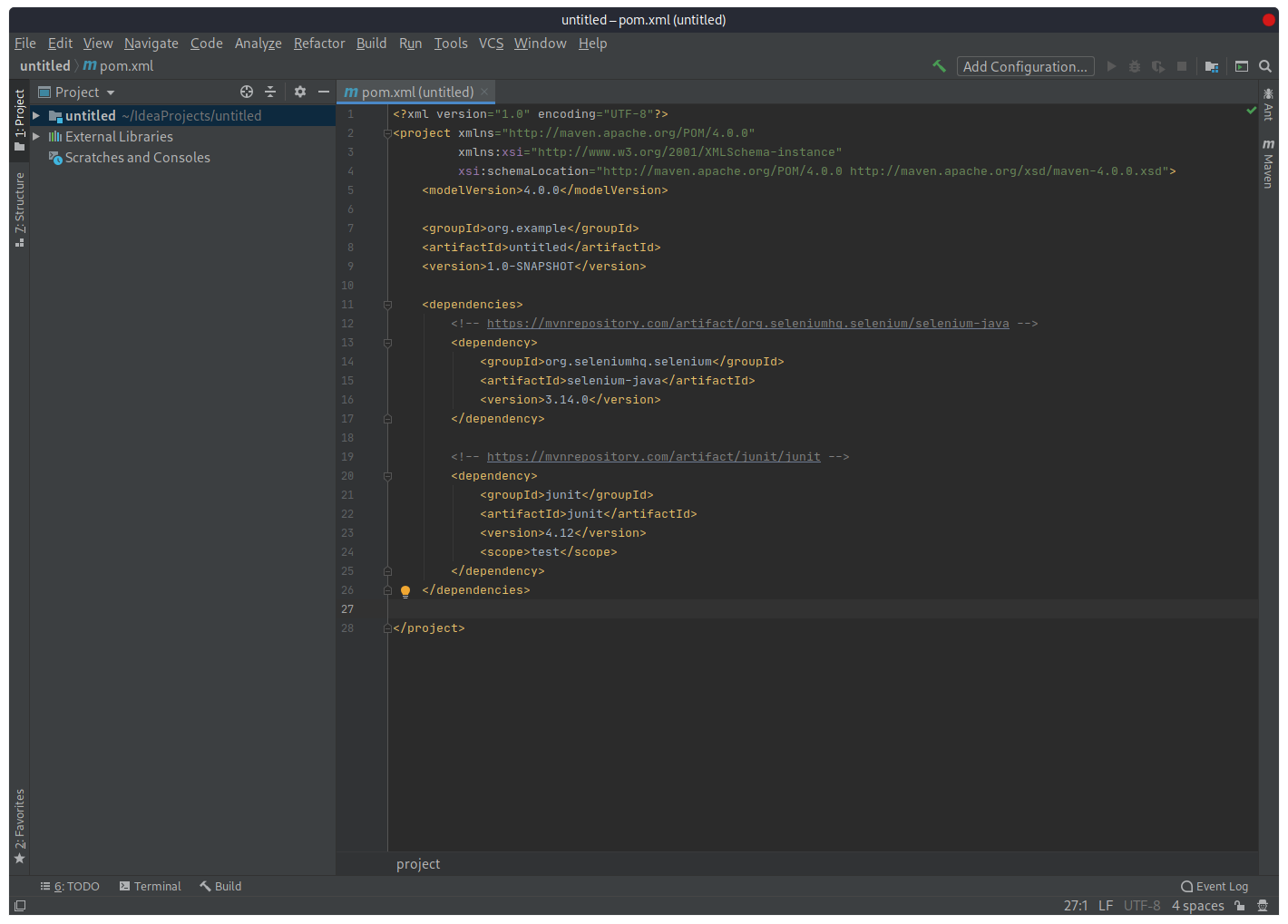
В нем уже появилась информация о проекте, внесенная на предыдущем шаге: Groupid, Artefiactid, Version. Pom.xml — это файл который описывает проект. Pom-файл хранит список всех библиотек (зависимостей), которые используются в проекте.
Для этого автотеста необходимо добавить две библиотеки: Selenium Java и Junit. Перейдем на центральный репозиторий Maven mvnrepository.com, вобьем в строку поиска Selenium Java и зайдем в раздел библиотеки:
Выберем нужную версию (в примере будет использована версия 3.14.0). Откроется страница:
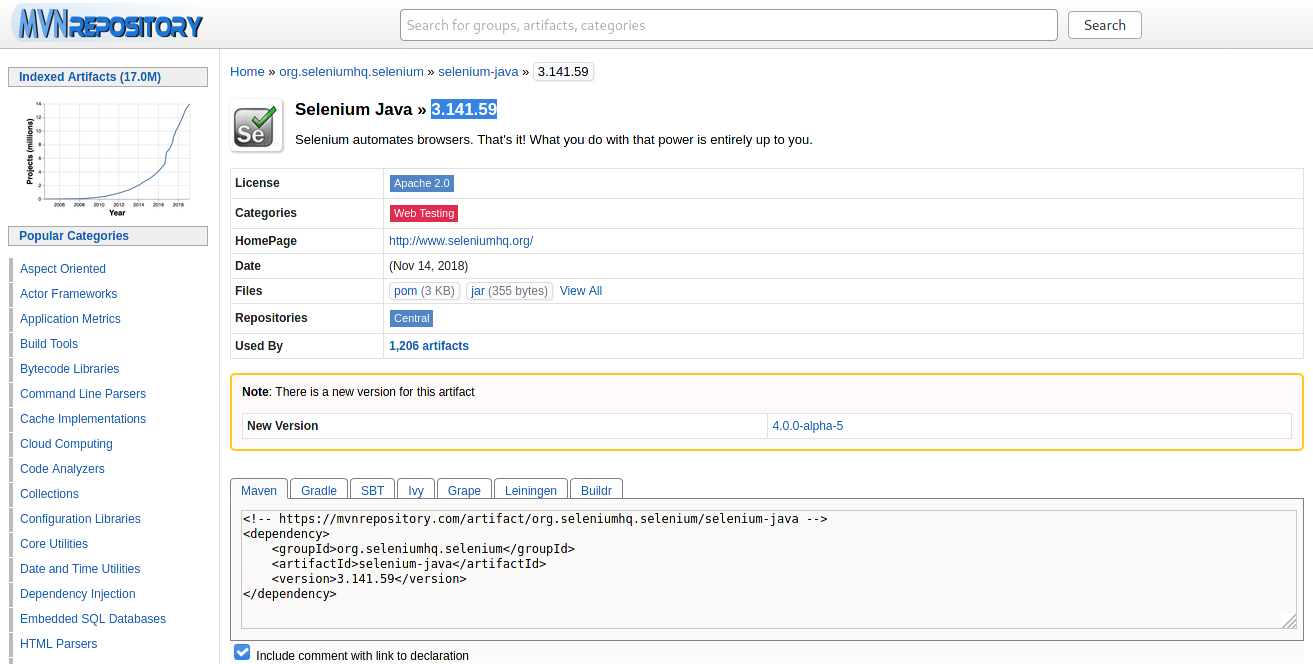
Копируем содержимое блока «Maven» и вставим в файл pom.xml в блок
Таким образом библиотека будет включена в проект и ее можно будет использовать. Аналогично сделаем с библиотекой Junit (будем использовать версию 4.12).
Создание пакета и класса
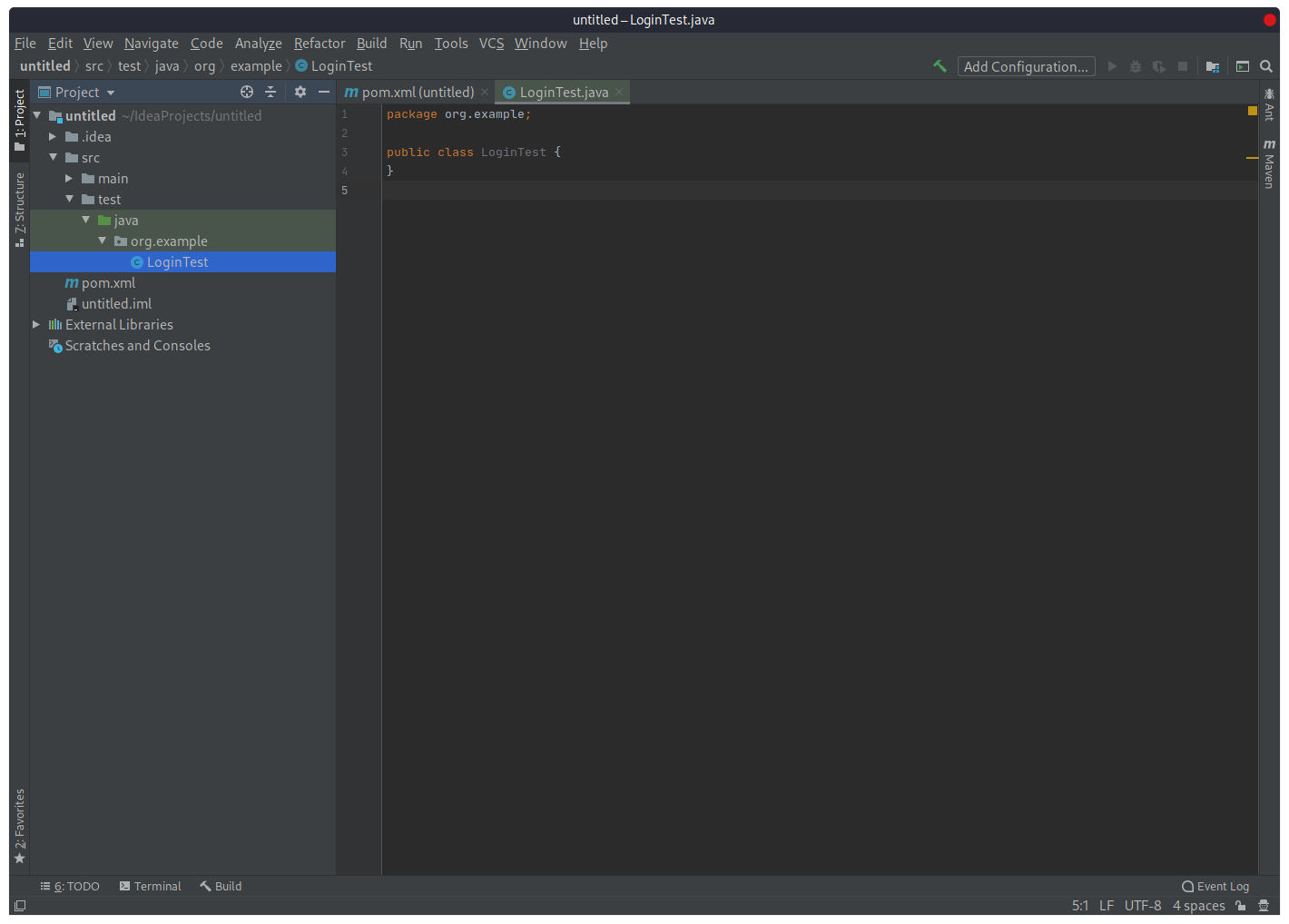
Раскроем структуру проекта. Директория src содержит в себе две директории: «main» и «test». Для тестов используется, соответственно, директория «test». Откроем директорию «test», кликом правой клавиши мыши по директории «java» выберем пункт «New», а затем пункт «Package». В открывшемся диалоговом окне необходимо ввести название пакета. Имя базового пакета должно носить тоже имя, что и Groupid — «org.example».
Следующий шаг — создание класса Java, в котором пишется код автотеста. Кликом правой клавиши мыши по названию пакета выберем пункт «New», а затем пункт «Java Class».
В открывшемся диалоговом окне необходимо ввести имя Java класса, например, LoginTest (название класса в Java всегда должно начинаться с большой буквы). В IDE откроется окно тестового класса:
Настройка IDE
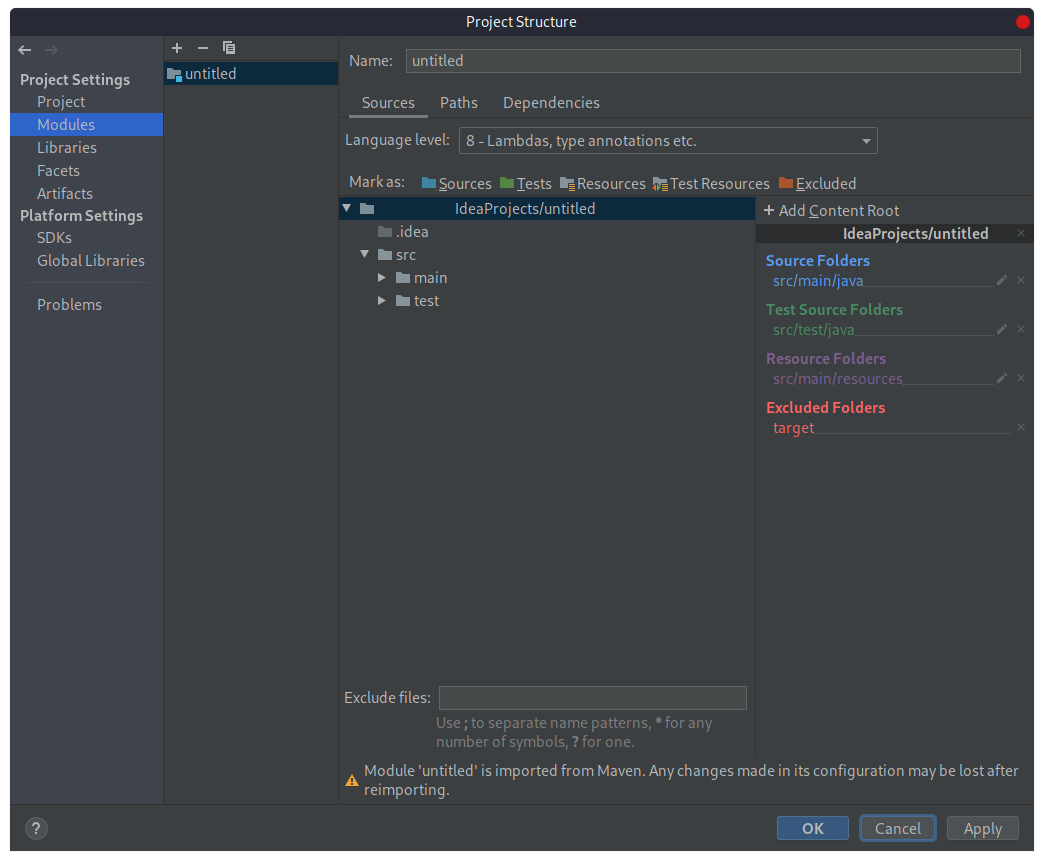
Прежде чем начать, необходимо настроить IDE. Кликом правой клавиши мыши по названию проекта выберем пункт «Open Module Settings». В открывшемся окне во вкладке «Sources» поле «Language level» по умолчанию имеет значение 5. Необходимо изменить значение поля на 8 (для использования всех возможностей, присутствующих в этой версии Java) и сохранить изменения:
Далее необходимо изменить версию компилятора Java: нажмем меню «File», а затем выберем пункт Settings.
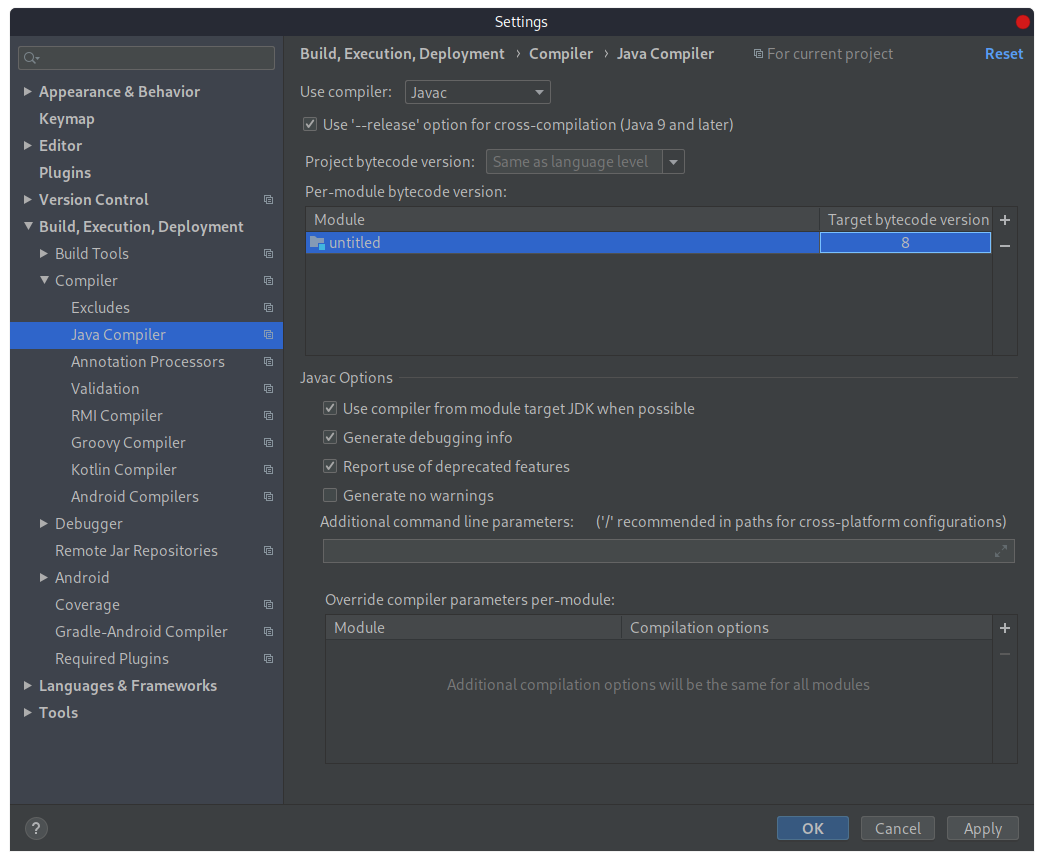
Test Suite
Тест считается успешно пройденным в случае, когда пользователю удалось выполнить все вышеперечисленные пункты.
Для примера будет использоваться аккаунт Яндекс (учетная запись заранее создана вручную).
Первый метод
В классе LoginTest будет описана логика теста. Создадим в этом классе метод «setup()», в котором будут описаны предварительные настройки. Итак, для запуска браузера необходимо создать объект драйвера:
Чтобы ход теста отображался в полностью открытом окне, необходимо сказать об этом драйверу:
Случается, что элементы на страницах доступны не сразу, и необходимо дождаться появления элемента. Для этого существуют ожидания. Они бывают двух видов: явные и неявные. В примере будет использовано неявное ожидание Implicitly Wait, которое задается вначале теста и будет работать при каждом вызове метода поиска элемента:
Таким образом, если элемент не найден, то драйвер будет ждать его появления в течении заданного времени (10 секунд) и шагом в 500 мс. Как только элемент будет найден, драйвер продолжит работу, однако, в противном случае тест упадем по истечению времени.
Для передачи драйверу адреса страницы используется команда:
Выносим настройки
Для удобства вынесем название страницы в отдельный файл (а чуть позже и некоторые другие параметры).
Создадим в каталоге «test» еще один каталог с названием «resources», а в нем обычный файл «conf.properties», в который поместим переменную:
а также внесем сюда путь до драйвера
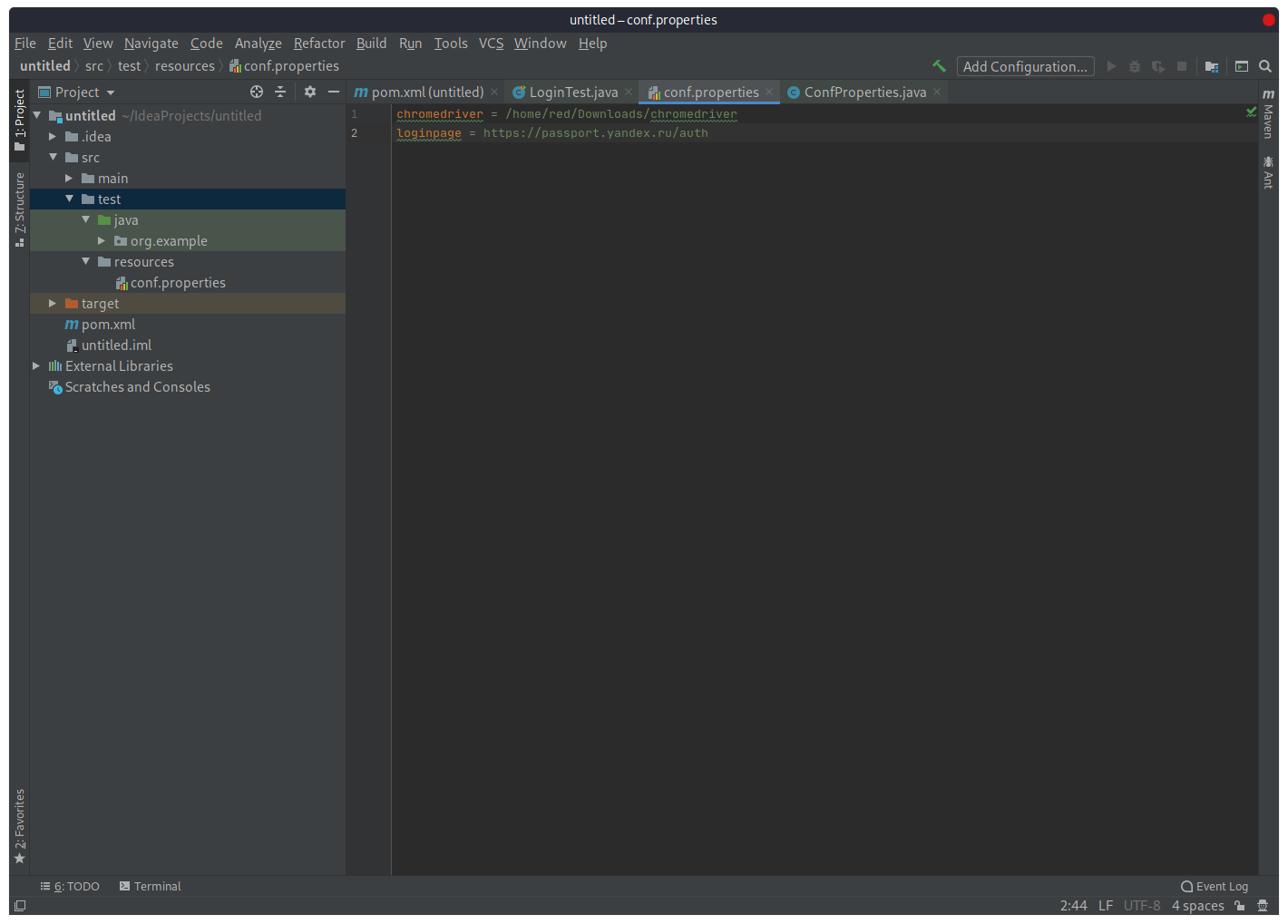
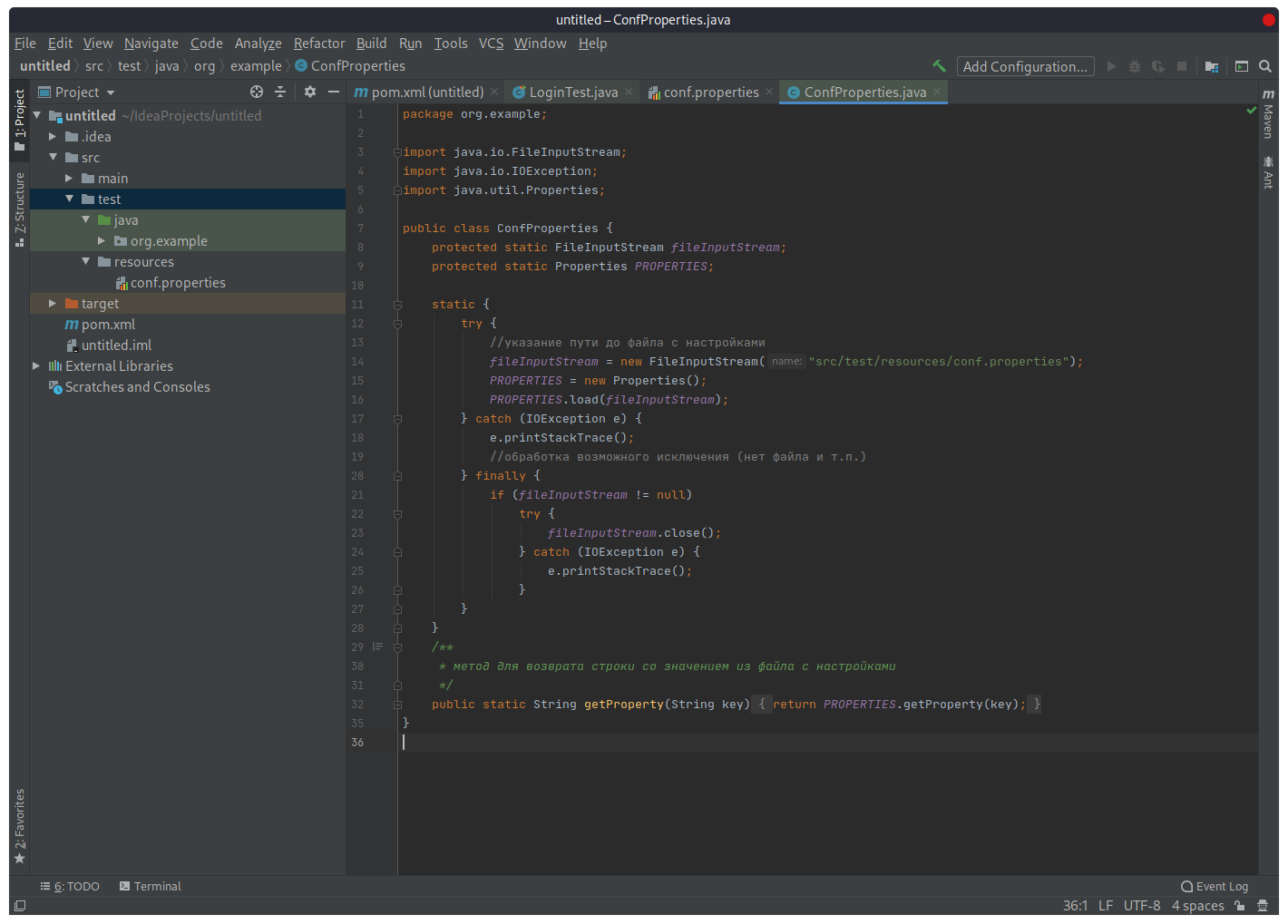
В пакете «org.example» создадим еще один класс «ConfProperties», который будет читать записанные в файл «conf.properties» значения:
Обзор первого метода
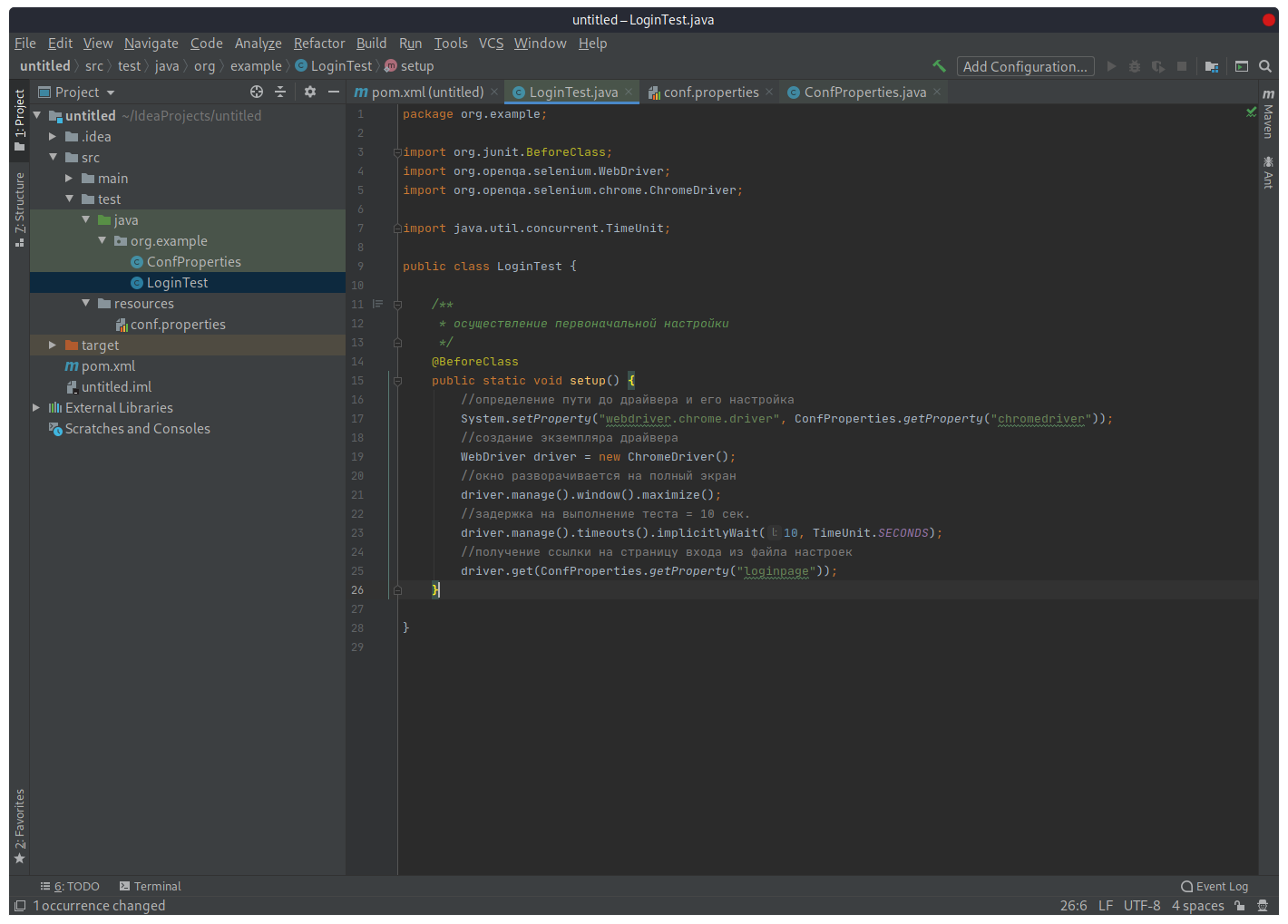
Метод «setup()» пометим аннотацией Junit «@BeforeClass», которая указывает на то, что метод будет выполняться один раз до выполнения всех тестов в классе. Тестовые методы в Junit помечаются аннотацией Test.
Page Object
При использовании Page Object элементы страниц, а также методы непосредственного взаимодействия с ними, выносятся в отдельный класс.
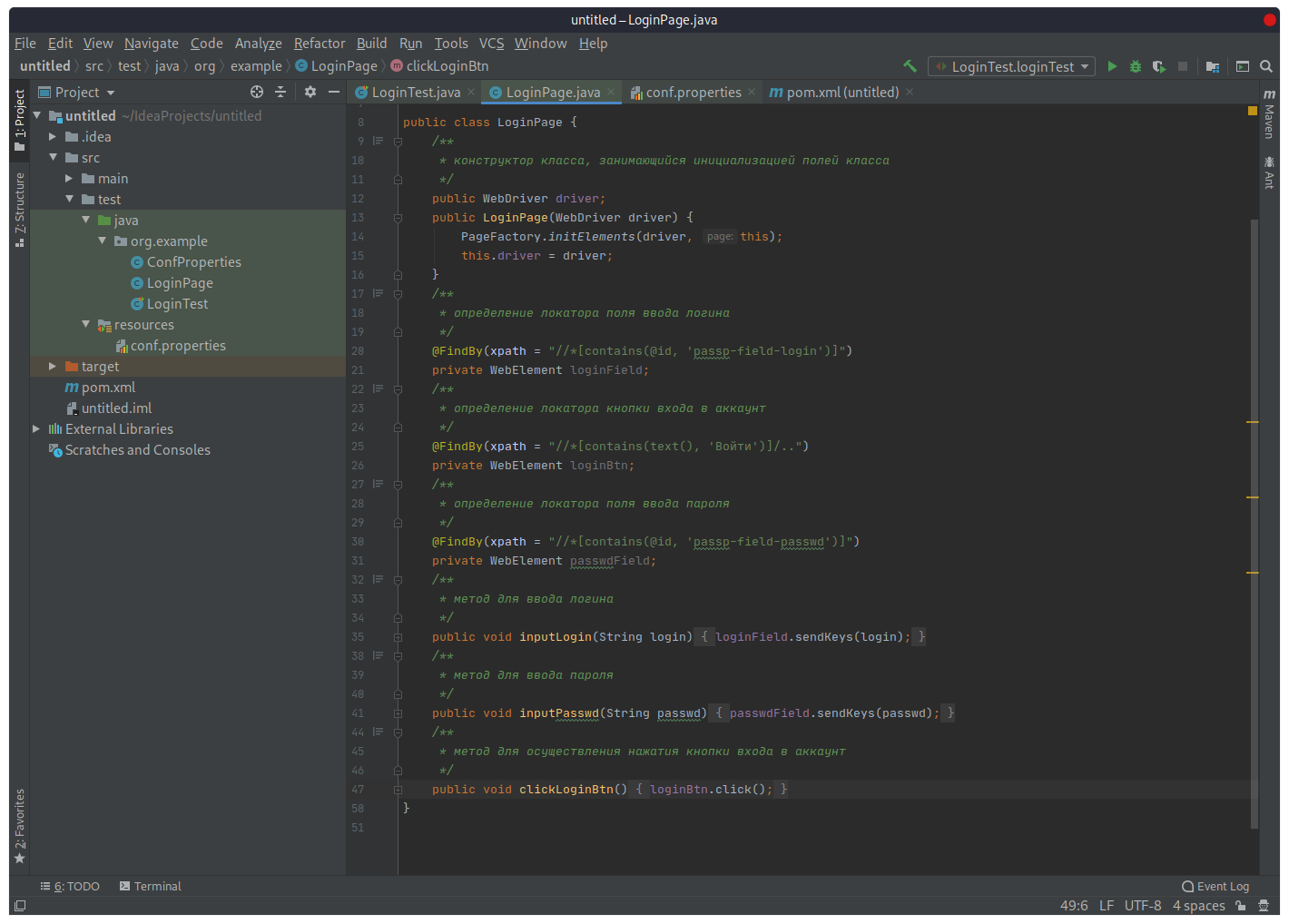
Создадим в пакете «org.example» класс LoginPage, который будет содержать локацию элементов страницы логина и методы для взаимодействия с этими элементами.
Откроем страницу авторизации в сервисах Яндекс (https://passport.yandex.ru/auth) в браузере Chrome. Для определения локаторов элементов страницы, с которыми будет взаимодействовать автотест, воспользуемся инструментами разработчика. Кликом правой кнопки мыши вызовем меню «Просмотреть код». В появившейся панели нажмем на значок курсора (левый верхний угол панели разработчика) и наведем курсор на интересующий нас элемент — поле ввода логина.
Для локации элементов в Page Object используется аннотация @FindBy.
Напишем следующий код:
Таким образом мы нашли элемент на страницу и назвали его loginField (элемент доступен только внутри класса LoginPage, т.к. является приватным).
Однако, такой длинный и страшный xpath использовать не рекомендуется (рекомендую к прочтению статью «Не так страшен xpath как его незнание». Если присмотреться, то можно увидеть, что поле ввода логина имеет уникальный id:
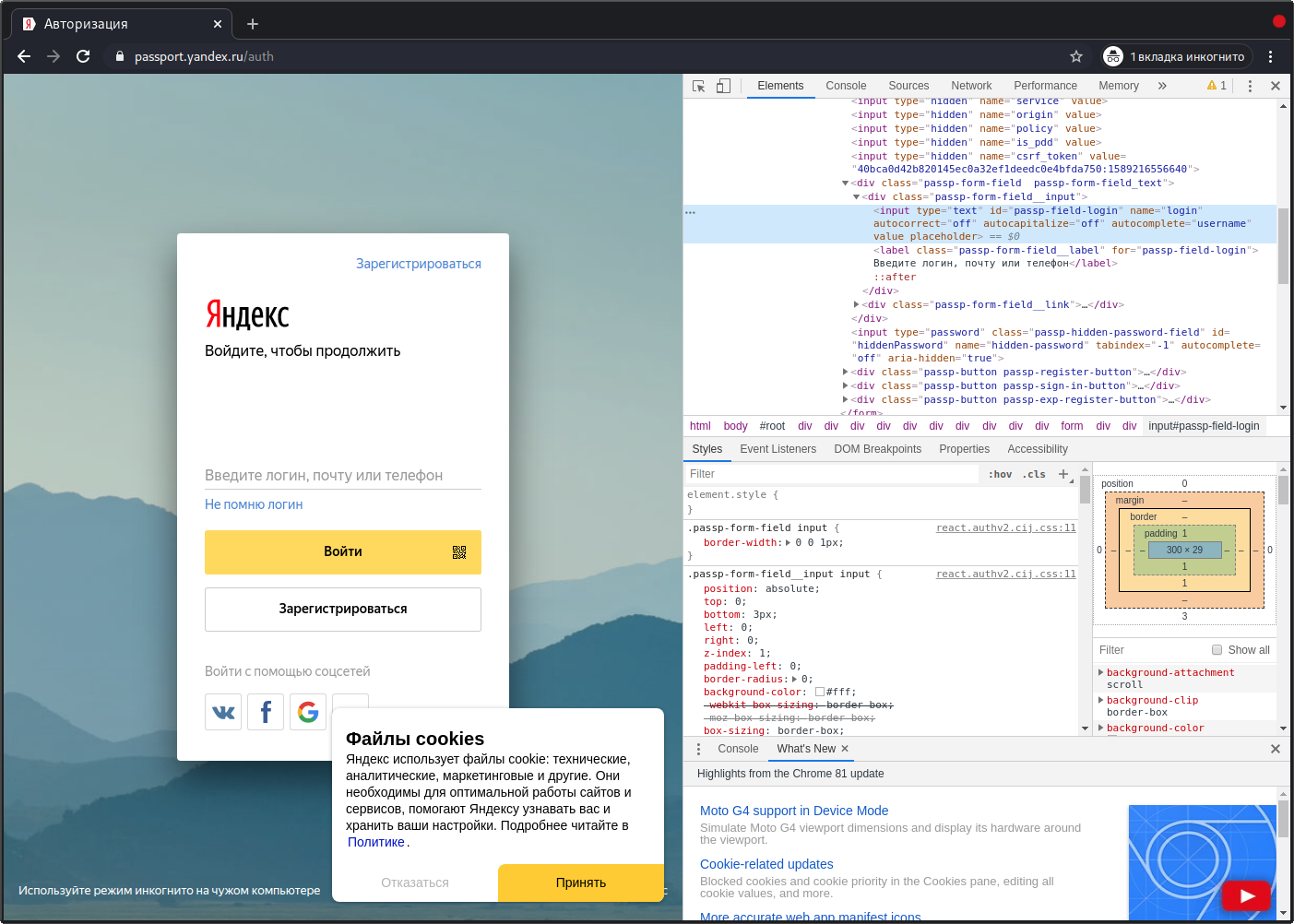
Воспользуемся этим и изменим поиск элемента по xpath:
Теперь вероятность того, что поле ввода пароля будет определено верно даже в случае изменения местоположения элемента на странице, возросла.
Аналогично изучим следующие элементы и получим их локаторы.
А теперь напишем методы для взаимодействия с элементами.
Метод ввода логина:
Метод ввода пароля:
Метод нажатия кнопки входа:
Для того, чтобы аннотация @FindBy заработала, необходимо использовать класс PageFactory. Для этого создадим конструктор и передадим ему в качестве параметра объект Webdriver:
После авторизации мы попадаем на страницу пользователя. Т.к. это уже другая страница, в соответствии с идеологией Page Object нам понадобится отдельный класс для ее описания. Создадим класс ProfilePage, в котором определим локаторы для имени пользователя (как показателя успешного входа в учетную запись), а также кнопки выхода из аккаунта. Помимо этого, напишем методы, которые будут получать имя пользователя и нажимать на кнопку выхода.
Итого, страница ввода логина будет иметь следующий вид:
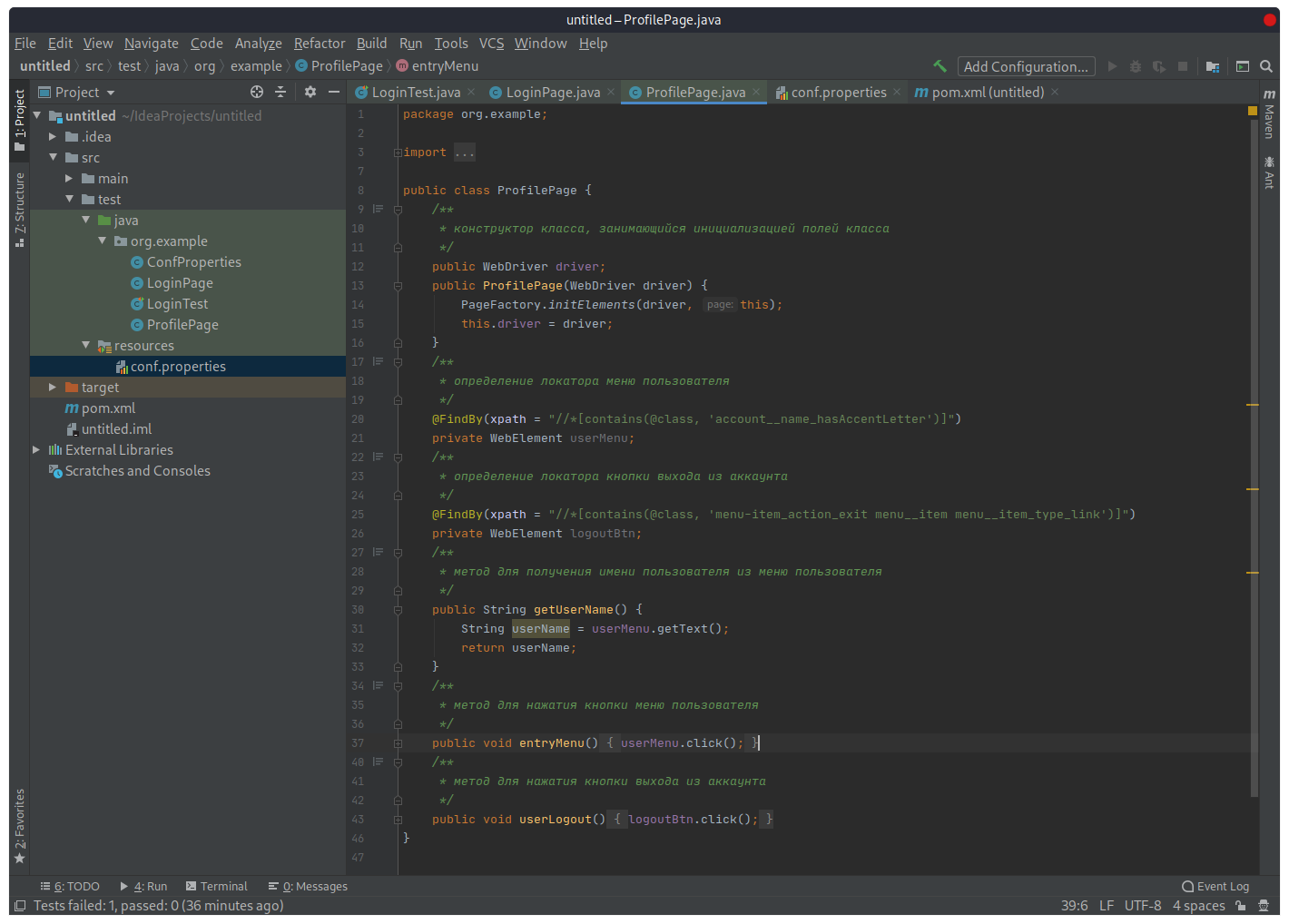
Интересный момент: в метод getUserName() пришлось добавить еще одно ожидание, т.к. страница «тяжелая» и загружалась довольно медленно. В итоге тест падал, потому что метод не мог получить имя пользователя. Метод getUserName() с ожиданием:
Вернемся к классу LoginTest и добавим в него созданные ранее классы-страницы путем объявления статических переменных с соответствующими именами:
Сюда же вынесем переменную для драйвера
В аннотации @BeforeClass создаем экземпляры классов созданных ранее страниц и присвоим ссылки на них. Создание экземпляра происходит с помощью оператора new. В качестве параметра указываем созданный перед этим объект driver, который передается конструкторам класса, созданным ранее:
А создание экземпляра драйвера приведем к следующему виду (т.к. он объявлен в качестве переменной):
Теперь можно перейти непосредственно к написанию логики теста. Создадим метод loginTest() и пометим его соответствующей аннотацией:
Осталось лишь корректно все завершить. Создадим финальный метод и пометим его аннотацией @AfterClass (методы помеченные этой аннотацией выполняются один раз, после завершения всех тестовых методов класса).
В этом методе осуществляется вход в меню пользователя и нажатие кнопки «Выйти», чтобы разлогиниться.
Последняя строка нужна для закрытия окна браузера.
Обзор теста
Запуск автотеста
Для запуска автотестов в Intellij Idea имеется несколько способов:
В результате выполнения автотеста, в консоли Idea я вижу, что тестовый метод loginTest() пройден успешно: