Как создать простого командного бота в Python

Итак, как часто вы узнаете погоду или время у Siri, Алисы или Google? Сейчас на рынке существует несколько видов ботов. Некоторые из них более сложные, способные поддерживать непрерывный диалог, а другие просто выполняют различные предварительно запрограммированные действия.
В этой статье мы расскажем, как создать бота, который выполняет определенные действия. С его помощью вы сможете проверять наличие товаров, запрашивать время и погоду и даже извлекать данные с веб-страниц. Если вас заинтересовала такая технология, рекомендуем начать с этого простого бота.
Итак, создаем набор данных, но сначала определим некоторые понятия.
Например, функция приветствия:
Итак, нам потребуется:
Разделим все на 3 главные части или класса: считыватель функций бота, модель бота и загрузчик бота. Вот какие данные необходимо будет импортировать:
Считыватель функций бота
Этот класс предназначен для чтения yml-файла с функциями. Для данной модели бота понадобится 4 выхода: лемматизатор, слова, классы и функции. Бот, которого мы создаем, — простой классификатор. В нем каждый тег является классом, а токенизированные и лемматизированные слова — вводимыми данными.
Модель бота
Вводимыми данными для модели бота будет список токенизированных слов для шаблона. Мы лемматизируем каждое слово, чтобы привести его к начальной форме и составить список связанных с ним слов. Затем создадим массив из слов с обозначением 1, если в текущем шаблоне найдено либо не найдено совпадение между словами. Для вывода создадим двоичную матрицу для репрезентации каждого тега. Все это сделаем с помощью алгоритма order_data (внутри класса BotModelCreator ), который будет выполняться в рамках инициализации (при создании класса).
Вторая и самая интересная часть — это построение модели. На входе модели бота будет список слов. В случае приветствия функция будет равна 23 (всего разных слов). Затем — вывод возможных тегов (в данном случае 2), которые были заданы. Для этой модели мы будем использовать простую нейронную сеть, но вы можете попробовать более продвинутую или сеть с другой архитектурой по вашему выбору. Архитектура представляет собой два плотных слоя 32 и 16 с функцией активации RELU и выдачей 0,5.
Теперь, когда у нас есть все — от последовательности ввода до алгоритмов обучения, остается только натренировать бота. Сначала нужно загрузить все модели и создать данные для бота, а затем и саму модель. Можно оставить сообщение по умолчанию равным 0 (если вы хотите регистрировать в логе информацию об обучении, измените его на 1 или 2).
Теперь нам нужно сохранить все файлы модели, которые необходимы для использования бота.
Наконец у нас есть файлы, модель обучена, но что теперь? Как взаимодействовать с получившимся ботом? Для этого нужно создать новый класс, который может загружаться из файла или передавать объект bot_model для прогнозирования тега. Также нужен метод, который использует для ввода текст и возвращает ответ от бота. Можно добавить и защиту от незнакомых команд: если пользователь отправит предложение, в котором нет нужного слова из созданного выше списка слов, бот ответит: «Я вас не понимаю, пожалуйста, повторите».
Для тестирования нужно только создать объект загрузчика бота и сообщить ему некоторый текст. Теперь единственное, что остается сделать, — это добавить больше функций с тегами, шаблонами и ответами, чтобы сделать бота «умнее».
Мелкая питонячая радость #14: ботнеты, распознавание текстов и генератор статических сайтов
Самое поразительное из того, что я увидел за последние 2 недели — тулкит на Python для создания ботнетов. Конечно же, он написан в исследовательских и учебных целях, но, тем не менее, эта штука дает энтузиастам компьютерной безопасности доступ к реализациям целого набора весьма опасных функций.
Знакомьтесь! byob, легальный и публичный тулкит для ботнетов.

Первое, что стоит отметить, byob предназначен лишь только для выполнения кода в целевых системах – автоматически сканить сети на баги, эксплуатировать их и заражать компы эта софтина вам не позволит (макины хакеры всплакнули и закрыли вкладку с этой статьей). Такое ограничение, в общем, логично для исследовательской программы.
Byob умеет генерировать целевой код, который затем нужно выполнить на атакуемой системе. Этот целевой код способен нанести ощутимый ущерб компу жертвы. В целевой код можно зашивать различные наборы команд на ваш вкус.
Byob.modules.escalate — повышение привилегий пользователя в удаленной системе.
Byob.modules.ransom — шифровальщик файлов и генератор биткоин-кошельков для вымогательств.
Byob.modules.keylogger, byob.modules.screenshot, byob.modules.screenshot — функции хищения конфиденциальной инфы.
А еще модули сканирования портов, пакетов, отправки смс и другие мелкие полезности.
Byob позволяет генерить целевой код под разные платформы — Win, OS X, Linux. Код, сгенерированный byob, умеет играть в кошки-мышки с компом жертвы — обходить файерволы, прятаться от антивирусов и противостоять анализу со стороны безопасников. Ну и, конечно же, у вас всегда есть моментальный доступ в консоль жертвы.
Все это приправлено админкой для управления вашим ботнетом.
Nikola
В 2020-м году Python стал вторым в мире по популярности языком программирования. Было бы странно, если бы у такого популярного языка не было бы инструментов для быстрого создания и публикации элементарных сайтов. Конечно, есть фреймворки и даже CMS на Python, но это слишком большие и сложные решения для тех, кто хочет быстро собрать небольшой набор простых страниц.
В мире Python за быстрое создание блогов и простых сайтов отвечает Nikola.
Nikola — генератор статических сайтов на Python. Задаем контент в markdown/html/jupyter файлах, применяем шаблон к контенту, рендерим — и получаем набор статических html файлов, готовых к выгрузке на ваш сервер.
Nikola идеально подходит для
Блогов программистов и дата сайентистов. Работа с сайтом из консоли, простая вставка фрагментов Jupyter, вставка сниппетов с кодом — из коробки в этой программе есть все, что нужно для ведения технического блога.
Небольших сайтов для ваших open-source продуктов — документация к вашим программам, чейнджлоги.
Маленьких лендингов для ваших проектов. Nikola позволяет легко и удобно управлять Jinja2 шаблонами для сайтов.
Создаем новый проект
Добавляем тестовый блогопост на сайт
Смотрим, что у нас получилось.
Nikola во многом заточен под ведение блога, но, конечно же, есть возможность добавлять обычные статические страницы.
Безусловно, есть более гибкие и мощные инструменты вроде Gatbsy (на Node), но программистам на Python, конечно же, приятно видеть и использовать инструменты создания статических сайтов на языке, который они любят, ценят и уважают.
Easyocr
Когда речь идет о распознавании текста в изображениях, первым делом разработчики вспоминают о pytesseract — питонячей обвязке OCR решения от Google. И Tesseract действительно неплохо справляется со своими обязанностями.
Если же у вас стоит задача распознавания отдельных надписей на фото, да еще и с небходимостью вычисления координат каждой надписи — стоит посмотреть в сторону easyocr.
Easyocr — решение на основе pytorch. Из коробки поддерживаются многие популярные языки и алфавиты. Ключевое отличие от tesseract — наличие метаданных о надписях на картинке: координаты и condifence rate на каждую надпись. Easyocr — хорошее решение для чтения номеров телефонов, названий компаний на вывесках, дорожных знаков и прочих коротких фрагментов текста.
Благодаря тому, что решение написано на pytorch, easyocr можно допиливать и модифицировать относительно малой кровью. Например, расширить поддержку некоторых языков, добавить распознавание хитрых кастомных шрифтов или улучшить поддержку чтения каких-то специфических фрагментов текста (например, номерных знаков).
В ответе видно координаты и confidence rate.
На сегодня все, прошлые питонячие радости смотрите по ссылке.
Теория создания ботнета на Python.
midinjer
Заблокирован

midinjer
Заблокирован
Добрый вечер, пользователи форума 🙂
Занимаюсь я, значится программированием (больше как хобби, с профессией не связано).
И недавно, листая форум, заинтересовался созданием ботнета.
Немного погуглив как это работает.. не увидел проблемы.
Мы по сути просто заражаем компьютер и удаленно даём ему некоторые комманды.
Так собственно и не увидев проблемы, решил попробовать сделать нечто подобное..
Это, скорее, просто записки, так сказать, мысли вслух. Тапками не кидать :(06-SES):
Я решил ‘выебнуться’ и ни как не компилить программу. Всё будет выполнять исключительно Python скриптом.
p.S. тут не уверен, как будет действовать антивирь с защитой от всяких ‘интернет угроз’. Мой аваст молчит в тряпочку.
Благо python из коробки умеет работать со всем этим чудом (правда не умею я, но тут на помощь пришёл github с его тоннами туториалов, так что через часика мог уже и я :(53-SES):)
Собственно, лирическая часть окончена, переходим к технической:
Подключаем единственный модуль, который нам необходим
Всё это при том, что я не пытался ничего скрывать, криптовать или хоть как то обходить какую бы то ни было защиту.
Итак, что мы имеем: возможность полностью контролировать компьютер жертвы, за счёт того, что скрипт может выполнять ЛЮБЫЕ python скрипты (а следовательно делать можно что угодно, если аккуратно), получая их от сервера и банально записывая в любой текстовый файл и затем самостоятельно его импортируя в себя.
Что остаётся сделать: убрать файл из процессов, ибо там их светится аж два (python + скрипт), но это к сожалению силами python не решается (читай: я дурачок, win32api не знать, английский тоже, так что документацию тоже не читать). Но работа скрипта никаких нагрузок не даёт (
7к килобайт нагрузка), так что зачем вам вообще туда лезть? я вот не лажу, пока не прижмёт ))
Вообщем, это просто записки, тапками не бросайте. Написал, мол, вдруг кому будет интересно ))
Если будут вопросы, задавайте, буду рад ответить ))




midinjer
Заблокирован
midinjer
Заблокирован
Оказалось, что если бот 5 минут ничего не делает, соединение разрывается, потому в конце каждого прохода цикла, если бот ничего не сделал впихнул вызов функции, которая пингует серверу, мол ‘я тута’, что бы не кикало.
Выглядит функция так:
Далее научил бота делать хоть что-то полезное:
1. По команде ‘console TEXT’ выполняется консольная команда через cmd.exe (сама команда вместо слова TEXT). Выполняет всё, что выполняется из под ‘не админской’ консолькой (а это довольно много всякой фигни).
2. Выполнять любые python скрипты (в данный момент работает так: бот получает ссылку, заходит по ней, копирует текст скрипта, создаёт рядышком этот скрипт и вызывает его). Работает по команде ‘python URL’.
2.5. Научил импортировать сторонние модули для python (можно делать как п.2, но в начале скрипта принудительно импортирую модуль request, ставится через pip install в консоли)
Далее попробовал решить проблему с отображением программы в диспетчере задач. Пока что единственное что придумал (реализовал, вродь работает), это запускать скрипт как Службу Windows. Там в службах столько всякого бреда, что даже если захочешь, нифига не найдёшь (не, не усли захочешь, то конечно найдёшь, но.. я вот туды никогда не захожу, а если и зайду, то разберусь что к чему онли с помощью гугла). В процессах больше ни python, ни сам скрипт не светятся. Единственная проблема: при установки софтинки (готового билда) теперь выскакивает дэбильное окошко, мол вы точно хотите установить (тобишь запрашивает права). Это впринципе не проблема, ибо винда постоянно при установки всяких игрушек с кряками и ломаного софта это просит, но всё равно обидно, как решить пока что не знаю.
Создание простого разговорного чатбота в python
Как вы думаете, сложно ли написать на Python собственного чатбота, способного поддержать беседу? Оказалось, очень легко, если найти хороший набор данных. Причём это можно сделать даже без нейросетей, хотя немного математической магии всё-таки понадобится.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.

Поиск ответа в диалоговом датасете
Год назад меня попросили показать ребятам, которые прежде не занимались анализом данных, какое-нибудь вдохновляющее приложение машинного обучения, которое можно собрать самостоятельно. Я попробовал собрать вместе с ними бота-болталку, и у нас это действительно получилось за один вечер. Процесс и результат нам понравились, и написал об этом в своем блоге. А теперь подумал, что и Хабру будет интересно.
Итак, начинаем. Наша задача — сделать алгоритм, который на любую фразу будет давать уместный ответ. Например, на «как дела?» отвечать «отлично, а у тебя?». Самый простой способ добиться этого — найти готовую базу вопросов и ответов. Например, взять субтитры из большого количества кинофильмов.
Я, впрочем, поступлю ещё более по-читерски, и возьму данные из соревнования Яндекс.Алгоритм 2018 — это те же диалоги из фильмов, для которых работники Толоки разметили хорошие и неплохие продолжения. Яндекс собирал эти данные, чтобы обучать Алису (статьи о её кишках 1, 2, 3). Собственно, Алисой я и был вдохновлен, когда придумывал этого бота. В таблице от Яндекса даны три последних фразы и ответ на них (reply), но мы будем пользоваться только самой последней из них (context_0).

Векторизация текстов
Теперь говорим о том, как превратить тексты в числовые векторы, чтобы осуществлять по ним приближённый поиск.
Мы уже познакомились с библиотекой pandas в Python — она позволяет загружать таблицы, осуществлять поиск в них, и т.п. Теперь затронем библиотеку scikit-learn (sklearn), которая позволяет более хитрые манипуляции с данными — то, что называется машинным обучением. Это значит, что любому алгоритму сперва нужно показать данные (fit), чтобы он узнал о них что-то важное. В результате алгоритм «научится» делать с этими данными что-то полезное — преобразовывать их (transform), или даже предсказывать неизвестные величины (predict).
В данном случае мы хотим преобразовать тексты («вопросы») в числовые векторы. Это нужно, чтобы можно было находить «близкие» друг к другу тексты, пользуясь математическим понятием расстояние. Расстояние между двумя точками можно рассчитать по теореме Пифагора — как корень из суммы квадратов разностей их координат. В математике это называется Евклидовой метрикой. Если мы сможем превращать тексты в объекты, у которых есть координаты, то мы сможем вычислять Евклидову метрику и, например, находить в базе вопрос, наиболее всего похожий на «о чём ты думаешь?».
Самый простой способ задать координаты текста — это пронумеровать все слова в языке, и сказать, что i-тая координата текста равна числу вхождений в него i-того слова. Например, для текста «я не могу не плакать» координата слова «не» равна 2, координаты слов «я», «могу» и «плакать» равны 1, а координаты всех остальных слов (коих десятки тысяч) равны 0. Такое представление теряет информацию о порядке слов, но всё равно работает неплохо.
Проблема в том, что у слов, которые встречаются часто (например, частиц «и» и «а») координаты будут несоразмерно большие, хотя информации они несут мало. Чтобы смягчить эту проблему, координату каждого слова можно поделить на логарифм числа текстов, где такое слово встречается — это называется tf-idf и тоже работает неплохо.

Проблема только одна: в нашей базе 60 тысяч текстовых «вопросов», в которых содержится 14 тысяч различных слов. Если превратить все вопросы в векторы, получится матрица 60к*14к. Работать с такой не очень классно, поэтому дальше мы поговорим о сокращении размерности.
Сокращение размерности
Мы уже поставили задачу создания болталочного чатбота, скачали и векторизовали данные для его обучения. Теперь у нас есть числовая матрица, представляющая реплики пользователей. Она состоит из 60 тысяч строк (столько было реплик в базе диалогов) и 14 тысяч столбцов (столько в них было различных слов). Сейчас наша задача — сделать её поменьше. Например, представить каждый текст не 14123-мерным, а всего лишь 300-мерным вектором.
Достичь этого можно, умножив нашу матрицу размера 60049х14123 на специально подобранную матрицу проекции размера 14123х300, в итоге получим результат 60049х300. Алгоритм PCA (метод главных компонент) подбирает матрицу проекции так, чтобы исходную матрицу можно было потом восстановить с наименьшей среднеквадратической ошибкой. В нашем случае получилось сохранить около 44% об исходной матрице, хотя размерность сократилась почти в 50 раз.

За счёт чего возможно такое эффективное сжатие? Напомним, что исходная матрица содержит счётчики упоминания отдельных слов в текстах. Но слова, как правило, употреблятся не независимо друг от друга, а в контексте. Например, чем больше раз в тексте новости встречается слово «блокировка», тем больше раз, скорее всего в этом тексте встретится также слово «телеграм». А вот корреляция слова «блокировка», например, со словом «кафтан» отрицательная — они встречаются в разных контекстах.
Так вот, получается, что метод главных компонент запоминает не все 14 тысяч слов, а 300 типовых контекстов, по которым эти слова потом можно пытаться восстановить. Столбцы матрицы проекции, соответствующие синонимичным словам, обычно похожи друг на друга, потому что эти слова часто встречаются в одном контексте. А значит, можно сократить избыточные измерения, не потеряв при этом в информативности.
Во многих современных приложениях матрицу проекции слов вычисляют нейросети (например, word2vec). Но на самом деле простой линейной алгебры для практически полезного результата уже достаточно. Метод главных компонент вычислительно сводится к SVD, а оно — к расчёту собственных векторов и собственных чисел матрицы. Впрочем, программировать это можно, даже не зная деталей.
Поиск ближайших соседей
В предыдущих разделах мы закачали в python корпус диалогов, векторизовали его, и сократили размерность, а теперь хотим наконец научиться искать в нашем 300-мерном пространстве ближайших соседей и наконец-то осмысленно отвечать на вопросы.
Поскольку научились отображать вопросы в Евклидово пространство не очень высокой размерности, поиск соседей в нём можно осуществлять довольно быстро. Мы воспользуемся уже готовым алгоритмом поиска соседей BallTree. Но мы напишем свою модель-обёртку, которая выбирала бы одного из k ближайших соседей, причём чем ближе сосед, тем выше вероятность его выбора. Ибо брать всегда одного самого близкого соседа — скучно, но не завязываться на сходство совсем — опасно.
Поэтому мы хотим превратить найденные расстояния от запроса до текстов-эталонов в вероятности выбора этих текстов. Для этого можно использовать функцию softmax, которая ещё часто стоит на выходе из нейросетей. Она превращает свои аргументы в набор неотрицательных чисел, сумма которых равна 1 — как раз то, что нам нужно. Дальше полученные «вероятности» мы можем использовать для случайного выбора ответа.

Фразы, которые будет вводить пользователь, надо пропускать через все три алгоритма — векторизатор, метод главных компонент, и алгоритм выбора ответа. Чтобы писать меньше кода, можно связать их в единую цепочку (pipeline), применяющую алгоритмы последовательно.
В результате мы получили алгоритм, который по вопросу пользователя способен найти похожий на него вопрос и выдать ответ на него. И иногда это ответы даже звучат почти осмысленно.

Публикация бота в Telegram
Мы уже разобрались, как сделать чатбота-болталку, который бы выдавал примерно уместные ответы на запросы пользователя. Теперь показываю, как выпустить такого чатбота в Телеграм.
Проще всего использовать для этого готовую обёртку Telegram API для питона — например, pytelegrambotapi. Итак, пошаговая инструкция:
Полный код к статье я намеренно не выкладываю — вы получите гораздо больше удовольствия и полезного опыта, когда напечатаете его сами, и получите работающего бота в результате собственных усилий. Ну или если вам очень лень это делать, можете поболтать с моей версией ботика.
Создаем чат-бот в Python с помощью nltk

Nov 20, 2019 · 5 min read

Чат-бот — это искусственный интеллект, который может имитировать разговор с пользователем на естественном языке через мессенджеры, веб-сайты, мобильные приложения, телефон и т.д. Чат-боты можно использовать в различных отраслях и для разных задач.
Мы напишем простой чат-бот, используя библиотеку nltk ( набор инструментов обработки естественного языка, Natural Language Toolkit). Это ведущая платформа создания программ на Python для работы с данными на “человеческом” языке.
Импортируем необходимые библиотеки:

Импортируем набор данных в блок данных pandas:
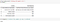
Данные выше содержат 1592 еди н ицы и две колонки контекста, который может быть логически выведен в виде запроса, а текстовый ответ является ответом на этот запрос. Если открыть набор данных в Excel, видно, что в нем существуют нулевые значения; также мы можем обнаружить, что данные расположены в различных кластерах, то есть за вопросами одного типа в одном месте следуют вопросы аналогичного типа.
Нулевые значения передаются для того же типа вопросов, ответ на которые может быть почти одинаковым и в подобной группе вопросов; ответ дается на первый вопрос, остальные остаются с нулевым значением. Таким образом, мы можем использовать ffill(), возвращающий значение предыдущего ответа вместо нуля, как показано ниже:

По шагам:

Давайте рассмотрим подробнее первый шаг — нормализацию текста — где мы преобразуем данные в нижний регистр, затем удаляем специальные символы и выполняем лемматизацию.
Давайте создадим функцию, которая преобразует данный текст в нижний регистр и удалит специальные символы и числа.

Мы видим, что текст чист. Токенизация слов — это процесс преобразования обычных текстовых строк в список токенов.

Функция pos_tag возвращает части речи каждого токена, таким образом функция-лемматизатор определяет части речи токена и преобразует токен в корневое слово, как показано ниже: