Web crawling with Python
Ari is an expert Data Engineer and a talented technical writer. He wrote the entire Scrapy integration for ScrapingBee and this awesome article.

Web crawling is a powerful technique to collect data from the web by finding all the URLs for one or multiple domains. Python has several popular web crawling libraries and frameworks.
In this article, we will first introduce different crawling strategies and use cases. Then we will build a simple web crawler from scratch in Python using two libraries: requests and Beautiful Soup. Next, we will see why it’s better to use a web crawling framework like Scrapy. Finally, we will build an example crawler with Scrapy to collect film metadata from IMDb and see how Scrapy scales to websites with several million pages.
What is a web crawler?
Web crawling and web scraping are two different but related concepts. Web crawling is a component of web scraping, the crawler logic finds URLs to be processed by the scraper code.
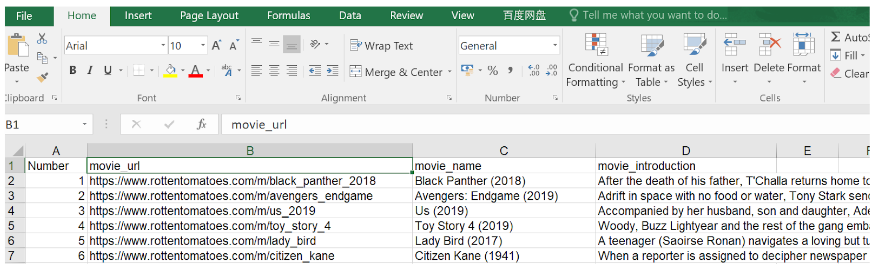
A web crawler starts with a list of URLs to visit, called the seed. For each URL, the crawler finds links in the HTML, filters those links based on some criteria and adds the new links to a queue. All the HTML or some specific information is extracted to be processed by a different pipeline.
Web crawling strategies
In practice, web crawlers only visit a subset of pages depending on the crawler budget, which can be a maximum number of pages per domain, depth or execution time.
Most popular websites provide a robots.txt file to indicate which areas of the website are disallowed to crawl by each user agent. The opposite of the robots file is the sitemap.xml file, that lists the pages that can be crawled.
Popular web crawler use cases include:
Next, we will compare three different strategies for building a web crawler in Python. First, using only standard libraries, then third party libraries for making HTTP requests and parsing HTML and finally, a web crawling framework.
Building a simple web crawler in Python from scratch
To build a simple web crawler in Python we need at least one library to download the HTML from a URL and an HTML parsing library to extract links. Python provides standard libraries urllib for making HTTP requests and html.parser for parsing HTML. An example Python crawler built only with standard libraries can be found on Github.
The standard Python libraries for requests and HTML parsing are not very developer-friendly. Other popular libraries like requests, branded as HTTP for humans, and Beautiful Soup provide a better developer experience.
If you wan to learn more, you can check this guide about the best Python HTTP client.
You can install the two libraries locally.
A basic crawler can be built following the previous architecture diagram.
The code above defines a Crawler class with helper methods to download_url using the requests library, get_linked_urls using the Beautiful Soup library and add_url_to_visit to filter URLs. The URLs to visit and the visited URLs are stored in two separate lists. You can run the crawler on your terminal.
The crawler logs one line for each visited URL.
The code is very simple but there are many performance and usability issues to solve before successfully crawling a complete website.
Next, we will see how Scrapy provides all these functionalities and makes it easy to extend for your custom crawls.
Web crawling with Scrapy
Scrapy is the most popular web scraping and crawling Python framework with 40k stars on Github. One of the advantages of Scrapy is that requests are scheduled and handled asynchronously. This means that Scrapy can send another request before the previous one is completed or do some other work in between. Scrapy can handle many concurrent requests but can also be configured to respect the websites with custom settings, as we’ll see later.
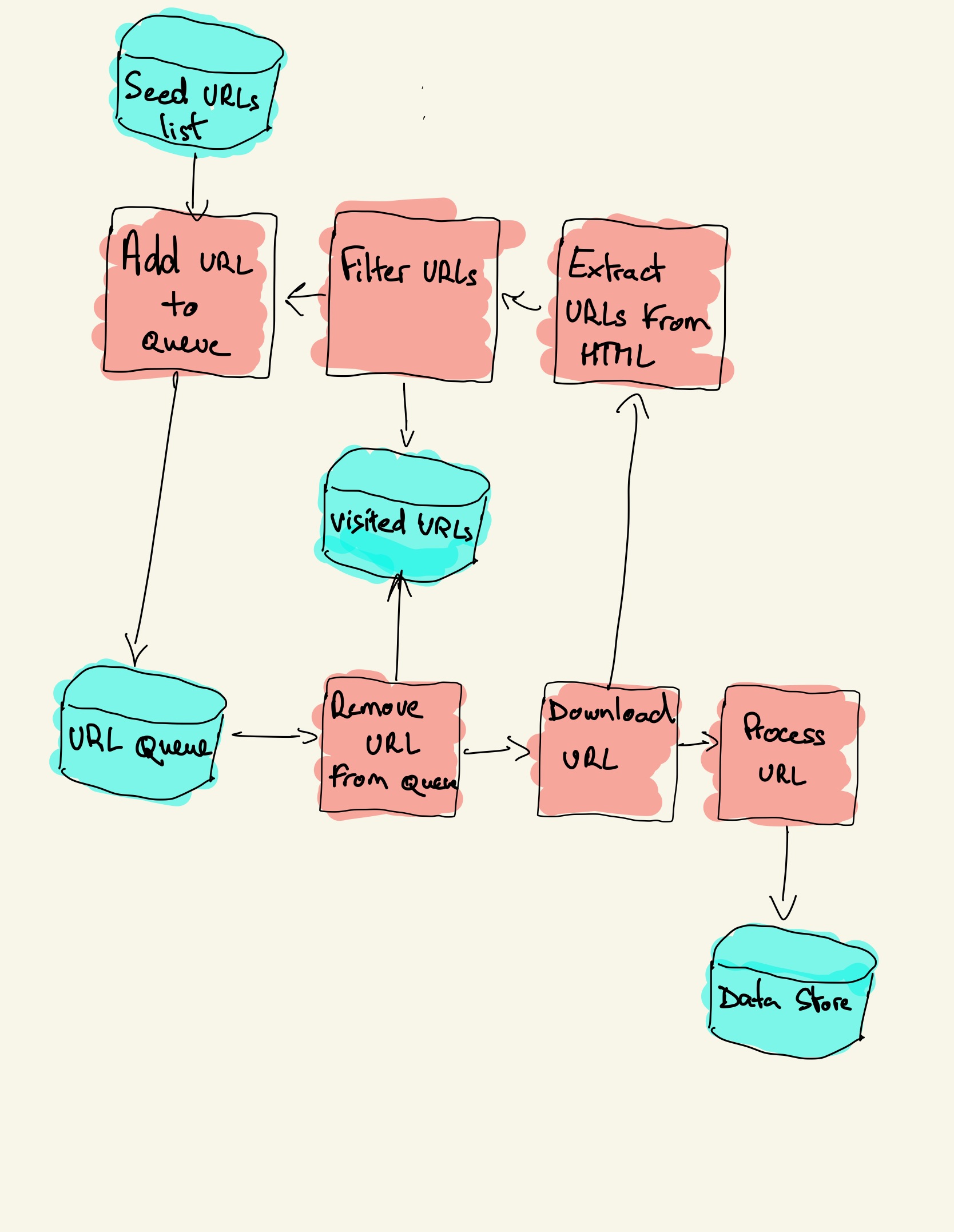
Scrapy has a multi-component architecture. Normally, you will implement at least two different classes: Spider and Pipeline. Web scraping can be thought of as an ETL where you extract data from the web and load it to your own storage. Spiders extract the data and pipelines load it into the storage. Transformation can happen both in spiders and pipelines, but I recommend that you set a custom Scrapy pipeline to transform each item independently of each other. This way, failing to process an item has no effect on other items.
On top of all that, you can add spider and downloader middlewares in between components as it can be seen in the diagram below.

Scrapy Architecture Overview [source]
If you have used Scrapy before, you know that a web scraper is defined as a class that inherits from the base Spider class and implements a parse method to handle each response. If you are new to Scrapy, you can read this article for easy scraping with Scrapy.
Scrapy also provides several generic spider classes: CrawlSpider, XMLFeedSpider, CSVFeedSpider and SitemapSpider. The CrawlSpider class inherits from the base Spider class and provides an extra rules attribute to define how to crawl a website. Each rule uses a LinkExtractor to specify which links are extracted from each page. Next, we will see how to use each one of them by building a crawler for IMDb, the Internet Movie Database.
Building an example Scrapy crawler for IMDb
Before trying to crawl IMDb, I checked IMDb robots.txt file to see which URL paths are allowed. The robots file only disallows 26 paths for all user-agents. Scrapy reads the robots.txt file beforehand and respects it when the ROBOTSTXT_OBEY setting is set to true. This is the case for all projects generated with the Scrapy command startproject.
This command creates a new project with the default Scrapy project folder structure.
Then you can create a spider in scrapy_crawler/spiders/imdb.py with a rule to extract all links.
You can launch the crawler in the terminal.
IMDb redirects from URLs paths under whitelist-offsite and whitelist to external domains. There is an open Scrapy Github issue that shows that external URLs don’t get filtered out when the OffsiteMiddleware is applied before the RedirectMiddleware. To fix this issue, we can configure the link extractor to deny URLs starting with two regular expressions.
Rule and LinkExtractor classes support several arguments to filter out URLs. For example, you can ignore specific URL extensions and reduce the number of duplicate URLs by sorting query strings. If you don’t find a specific argument for your use case you can pass a custom function to process_links in LinkExtractor or process_values in Rule.
For example, IMDb has two different URLs with the same content.
To limit the number of crawled URLs, we can remove all query strings from URLs with the url_query_cleaner function from the w3lib library and use it in process_links.
Now that we have limited the number of requests to process, we can add a parse_item method to extract data from each page and pass it to a pipeline to store it. For example, we can either extract the whole response.text to process it in a different pipeline or select the HTML metadata. To select the HTML metadata in the header tag we can code our own XPATHs but I find it better to use a library, extruct, that extracts all metadata from an HTML page. You can install it with pip install extract.
I set the follow attribute to True so that Scrapy still follows all links from each response even if we provided a custom parse method. I also configured extruct to extract only Open Graph metadata and JSON-LD, a popular method for encoding linked data using JSON in the Web, used by IMDb. You can run the crawler and store items in JSON lines format to a file.
The output file imdb.jl contains one line for each crawled item. For example, the extracted Open Graph metadata for a movie taken from the tags in the HTML looks like this.
The JSON-LD for a single item is too long to be included in the article, here is a sample of what Scrapy extracts from the
Web crawler с использованием Python и Chrome
Добрый день, дорогие друзья.
Недавно, сидя на диване, я задумался о том, что хочется мне сделать своего паука, который что-то бы смог качать с веб сайтов. Но качать он должен был бы не простой загрузкой, а как настоящий милый добрый браузер (т.е. JavaScript чтобы исполнялся).
В моей голове всплыли такие интересные штуки, как Selenium, PhantomJS, Splash и всякое подобное. Все эти штуки были мне немного втягость. Вот какие причины я выявил:
Пробежавшись по документации и готовому проекту, и убедившись что никто толком не реализовал клиент под Python, я решил сделать свой клиент.
Протокол у Chrome Remote Debug достаточно простой. Для начала нам надо запустить Chrome вот с такими параметрами:

Теперь у нас есть API, доступное, по адресу http://127.0.0.1:9222/json/, в котором я обнаружил такие методы как list, new, activate, version, которые используются для управления вкладками.
Также, если мы просто перейдем на http://127.0.0.1:9222/, то сможем перейти на прекрасный веб отладчик, который полностью имитирует стандартный. В нем очень удобно отслеживать как работают апишные методы хрома (окно отладки справа эмулируется внутри окна, а окно браузера — отрисовано на канвасе).

Собственно, перейдя на вкладку list, мы можем узнать, адрес вебсокета, с помощью которого мы сможем общаться с вкладкой.
Дальше мы подсоединяемся через вебсокет к желаемой вкладке, и общаемся с нею. Мы можем:
Тут мы используем систему колбеков. Самые интересные: start и any:
Однако, было одно но, из-за которого я все таки плачу. С помощью remote API нельзя производить перехват и модификацию запросов и ответов. Насколько я понял — это возможно через mojo, который позволяет использовать хром в качестве библиотеки.
Однако, я подумал, что компиляция нестабильного хрома и отсутствие Python прослойки для меня будет большим горем (сейчас есть C++ и JavaScript в процессе разработки).
Пишем свой Google, или асинхронный краулер с rate limits на Python

Меня зовут Александр, я руковожу backend-разработкой в КТS. Сегодня расскажу, как написать асинхронный краулер.
Такая задача часто встречается на практике, когда нужно реализовать периодическую синхронизацию/обкачку между сервисами.
Статья написана по мотивам вебинара, который мы провели в рамках нового курса «Асинхронное программирование на Python для начинающих». Курс стартует 18 октября, поэтому, если вам интересно — загляните посмотреть.
Что будет в статье:
У нас есть краулер, который обкачивает страницы. Это может быть поисковый бот Google, который ходит по сайтам, скачивает данные, кладет в базу и индексирует, или какой-нибудь агрегатор: аптек, маркетплейсов и т.д.
Задача в том, что краулер должен работать и не положить сервис, который он обкачивает.
Код для начала работы:
Краулеру нужно посетить и скачать много страниц, следовательно, много раз обратиться к ресурсу. Мы можем позволить себе отправлять много запросов, но сервис, на который мы приходим, может не выдержать большой нагрузки. Поэтому к источнику данных нужно ходить управляемо — сделать rate-limit.
Если в какой-то момент задача прервалась, или мы сами решили остановить краулер, нужно сделать корректную и аккуратную остановку работы. Для этого начатые задачи должны завершиться, а новые задачи из очереди должны прекратить поступать.
Исходный код
У нас есть сущность Pool. Эта сущность умеет управлять количеством запросов в единицу времени. Pool принимает:
max_rate — максимальное количество запросов
interval — интервал. Если мы передаем значения max_rate = 5 и interval = 1, в секунду может исполняться 5 запросов
concurrent_level — обозначает допустимое количество параллельных запросов
max_rate и concurrent_level могут не совпадать, когда время выполнения запроса больше, чем interval. Например, мы делаем 5 запросов в секунду, как заявлено в переменных, но API все равно отвечает медленнее. Чтобы не положить сервис, мы вводим переменную concurrent_level.
Планировщик
Для начала нужно написать что-то, что позволит делать ровно 5 запросов в секунду, не обращая внимание на время запроса. Для этого мы запустим планировщик, который назовем scheduler. Он будет просыпаться раз в секунду и ставить количество задач, равное max_rate. Планировщик не ждет их исполнения, просто создает 5 задач каждую секунду.
Дополним class Pool и напишем функцию scheduler:
Обратите внимание на две вещи:
функция бесконечная, пока работает наш краулер
раз в период функция выполняет max_rate раз какое-то действие
Задача для краулера
Scheduler должен откуда-то взять задачи, которые нужно запланировать. Для этого нам нужно сделать очередь, которую мы возьмем из библиотеки asyncio. Примитив называется asyncio.Queue(). В class Pool дописываем:
Теперь мы просыпаемся раз в интервал и получаем количество задач, равное max_rate. Но нужно что-то сделать, чтобы они исполнялись.
Для этого в asyncio есть функция create_task. Она запускает выполнение корутины, но при этом не дожидается ее исполнения, а создает фоновую задачу. В create_task передадим метод perform.
Пробный запуск
Давайте попробуем все это запустить. Сделаем функцию start и таким же образом запустим scheduler. Нам нужно не ждать его, а просто запустить в фоне корутину с помощью create_task:
В будущем для корректного завершения работы краулера нужно завершить работу scheduler. Для этого нужно вызвать cancel у задачи, поэтому возвращаемое значение из create_task мы сохраняем в переменную scheduler_task:
Выставим rate-limit на 3 и внутри start запустим наш Pool:
Запускаем и видим, что ничего не произошло:
Это потому, что внутри очереди ничего нет. Мы сделали старт и поспали 5 секунд, а на момент окончания задачи у нас осталась фоновая задача scheduler.
Промежуточный итог
У нас есть Pool с параметрами:
— ограничение количества запросов max_rate
— интервал активизации планировщика interval
— максимальное количество параллельных запросов concurrent_level
Мы написали планировщик scheduler, который работает постоянно, просыпается раз в объявленный интервал, достает из очереди max_rate задач и запускает их исполнение.
Задача task — просто дата-класс с функцией perform. Для описания поведения задачи нужно создать класс-наследник и в нем переопределить perform.
Еще мы написали функцию start, в которой выставили признак работы is_running и в фоне запустили наш планировщик.
Функции put и join
Перед тем, как запустить Pool, попробуем положить туда задачку. Для этого напишем функцию put, которая принимает задачу и кладет ее в нашу внутреннюю очередь.
Дополнительно добавим tid (task_id) и print в код задачи:
И добавим 10 задач перед стартом pool:
Добавим еще кое-что. У стандартной библиотеки queue есть метод join. Тогда краулер будет ждать не 5 секунд, как мы указали в начале, а до тех пор, пока очередь не опустеет:
Запустим и посмотрим, что произойдет:
Хотя все зависло, планировщик работал.
Вы можете увидеть, что задача выполняется 3 секунды. И, несмотря на то, что предыдущие задачи еще не завершились, планировщик все равно создает новые. Это плохо, потому что если API отвечает медленнее, чем мы шлем к нему запросы, есть вероятность «положить» сервис. Эту проблему мы решим чуть позже.
Чтобы join отработал, нужно помечать задачи выполненными. Не будем усложнять код scheduler и сделаем отдельную функцию _worker. В нее перенесем perform и ниже добавим self._queue.task_done(). Это означает, что задачу мы выполнили:
Обратите внимание, что _worker вызывается без await, потому что scheduler не должен ждать его завершения. Иначе он не успеет запланировать задачи.
В scheduler вместо perform нужно передать _worker и task:
Снова попробуем запустить:
Программа завершилась, но осталось предупреждение о том, что scheduler остался работать в фоне. Функцию stop напишем чуть позже.
Semaphore
На этом этапе видим, что:
метод start запускает наш Pool и планировщик scheduler
планировщик раз в секунду ставит новые задачи и запускает _worker
_worker эти задачи выполняет
метод join ждет, пока очередь не станет пустой
Если время выполнения задач больше интервала активизации планировщика (interval), он накидывает дополнительные задачи сверху тех, которые еще не выполнились.
В таком случае количество параллельных запросов к сервису за interval будет больше rate_limit. Поэтому нужно ограничить количество параллельных запросов. Для этого нам потребуется переменная concurrent_level, которая по умолчанию равна rate_limit.
В asyncio есть примитив синхронизации Semaphore. С его помощью можно ограничить количество параллельных исполняемых worker. Если количество запланированных задач больше заданного значения, мы ждем их исполнения. В нашем примере задач 3.
Объявим Semaphore и передадим в него либо concurrent_level, либо max_rate.
Когда worker начинает исполняться, нам нужно занять Semaphore. Для этого используем «асинхронный контекстный менеджер»: async with self._sem. Мы занимаем Semaphore, пока не закончатся операции ниже — await task.perform(self) и self._queue.task_done().
Добавим Semaphore внутрь scheduler, чтобы scheduler не запускал новые worker’ы, если количество параллельных worker’ов уже достигло максимума:
Мы добавили 3 задачи и ждем, пока они исполнятся. Таким образом мы соблюдаем максимальное параллельное количество запросов.
Остановка фонового планировщика
У нас осталась проблема с корректным завершением планировщика. После завершения остановки краулера появляется предупреждение о незавершенной корутине.
Чтобы этого не было, напишем функцию stop:
Теперь после того, как внутри пула закончатся задачи, его нужно корректно остановить. Добавим метод stop в конце функции start:
Теперь все работает корректно.
Мы остановили планировщик, когда задачи в очереди закончились. Но если мы остановим краулер в процессе работы, начнут появляться предупреждения о том, что какая-то задача не завершилась:
А чем больше время выполнения perform, тем больше будет таких уведомлений.
Поэтому нам нужно ожидать, когда все worker завершатся. Для этого введем дополнительную переменную, обозначающую количество параллельно работающих worker: concurrent_workers. Изначально она равна 0. При запуске воркера мы увеличиваем concurrent_workers на 1. При выходе, наоборот, уменьшаем на 1:
Теперь нужно как-то сказать функции stop, что все параллельные worker завершились. Это произойдет, когда is_running будет false и concurrent_workers станет равной 0.
Для этого есть примитив синхронизации Event. В нашем коде мы добавим его в Pool и назовем stop_event. Это переменная, на которой можно ждать await self._stop_event.wait() до тех пор, пока кто-то не вызовет self._stop_event.set():
Если равна, то все worker завершили свою работу, планировщик отменен и не создает новые задачи. В таком случае все компоненты Pool остановлены или завершили свою работу — программу можно завершать.
Но если concurrent_workers не равна 0, нам нужно внутри метода stop подождать событие stop_event:
Когда Pool остановлен, последний работающий worker должен отправить уведомление:
Обновим функцию main, чтобы все корректно работало:
Теперь все работает. После нажатия Ctrl + C выполняются оставшиеся задачи, и программа завершается:
Работа краулера на примере обкачки нашего блога на Хабре
Мы реализовали механику пула на нашей абстрактной задачке task.
Для следующего этапа я подготовил задачу FetchTask.
Внутри функции parcer есть переменная soup, которая объявлена как soup = BeautifulSoup(data, ’lxml’). Дам небольшие пояснения.
BeautifulSoup — парсер для анализа HTML/XML.
lxml — реализация HTML/XML парсера. Из-за GIL мы специально запускаем res внутри функции perform через executor:
GIL — блокировка, которая запрещает параллельные потоки в Python. Но если вы пишите расширение на С, есть возможность «отпустить» GIL.
Парсер lxml написан на С. У себя под капотом он умеет отпускать GIL и выполняться в отдельном потоке. Это относится и к некоторым другим расширениям: https://lxml.de/2.0/FAQ.html#id1
В fetch_task также переопределяем функцию perform, в которой нужно сходить в сеть. Для этого я взял aiohttp client.
В задаче FetchTask мы идем на указанный URL, оттуда получаем данные и запускаем executor для их обработки. Нужно взять все ссылки в документе, перейти на них и тоже обкачать:
В конце мы добавляем в результат новую задачу и увеличиваем на 1 глубину depth.
Например, когда мы поставили задачку habr.com, глубина была равна 1. Мы скачали этот документ, в котором есть и другие ссылки: блоги Mail.ru, Yandex или KTS. Когда мы стали обкачивать следующие страницы, глубина увеличилась до 2. Этот параметр нужен для ограничения количества обкачиваемых ресурсов, фактически — глубины.
Обратите внимание, что у нас есть список посещенных страничек PARSED_URLS. Так мы не будем дважды посещать одни и те же страницы.
Теперь импортируем задачи в краулер из fetch_task и изменяем start:
Выставляем 3 запроса в секунду и смотрим, как наш краулер потихоньку обкачивает Хабр:
Спасибо за внимание
На этом все! Спасибо всем, кто дочитал статью.
Если сталкивались с подобными задачами, пожалуйста, поделитесь своим опытом в комментариях.
Web Crawler in Python

DURATION
categories
share

Topcoder SKILL BUILDER COMPETITIONS
With the advent of the era of big data, the need for network information has increased widely. Many different companies collect external data from the Internet for various reasons: analyzing competition, summarizing news stories, tracking trends in specific markets, or collecting daily stock prices to build predictive models. Therefore, web crawlers are becoming more important. Web crawlers automatically browse or grab information from the Internet according to specified rules.
Classification of web crawlers
According to the implemented technology and structure, web crawlers can be divided into general web crawlers, focused web crawlers, incremental web crawlers, and deep web crawlers.
Basic workflow of web crawlers
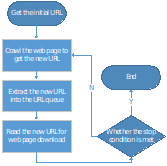
Basic workflow of general web crawlers
The basic workflow of a general web crawler is as follows:
Get the initial URL. The initial URL is an entry point for the web crawler, which links to the web page that needs to be crawled;
While crawling the web page, we need to fetch the HTML content of the page, then parse it to get the URLs of all the pages linked to this page.
Put these URLs into a queue;
Loop through the queue, read the URLs from the queue one by one, for each URL, crawl the corresponding web page, then repeat the above crawling process;
Check whether the stop condition is met. If the stop condition is not set, the crawler will keep crawling until it cannot get a new URL.
Environmental preparation for web crawling
Make sure that a browser such as Chrome, IE or other has been installed in the environment.
Download and install Python
Download a suitable IDL
This article uses Visual Studio Code
Install the required Python packages
Pip is a Python package management tool. It provides functions for searching, downloading, installing, and uninstalling Python packages. This tool will be included when downloading and installing Python. Therefore, we can directly use ‘pip install’ to install the libraries we need.
• BeautifulSoup is a library for easily parsing HTML and XML data.
• lxml is a library to improve the parsing speed of XML files.
• requests is a library to simulate HTTP requests (such as GET and POST). We will mainly use it to access the source code of any given website.
The following is an example of using a crawler to crawl the top 100 movie names and movie introductions on Rotten Tomatoes.
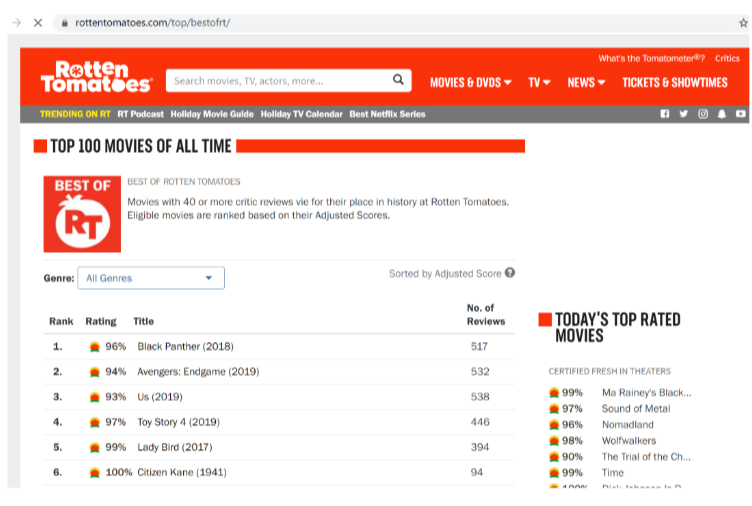
Top100 movies of all time –Rotten Tomatoes
We need to extract the name of the movie on this page and its ranking, and go deep into each movie link to get the movie’s introduction.
1. First, you need to import the libraries you need to use.
2. Create and access URL
Create a URL address that needs to be crawled, then create the header information, and then send a network request to wait for a response.
When requesting access to the content of a webpage, sometimes you will find that a 403 error will appear. This is because the server has rejected your access. This is the anti-crawler setting used by the webpage to prevent malicious collection of information. At this time, you can access it by simulating the browser header information.
3. Parse webpage
4. Extract information
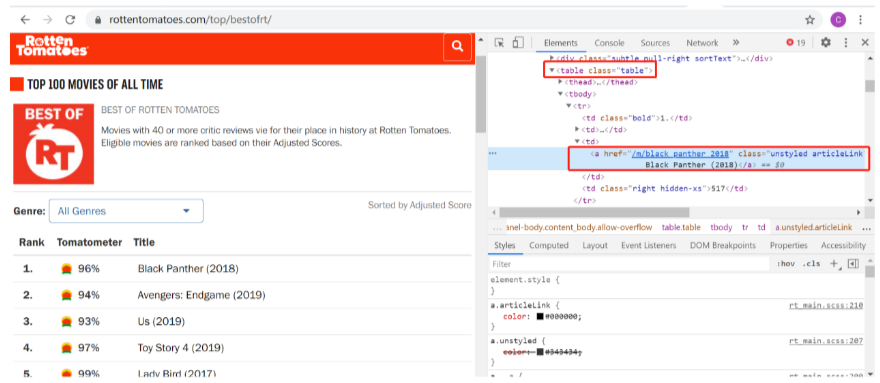
Get an introduction to each movie
After extracting the relevant information, you also need to extract the introduction of each movie. The introduction of the movie is in the link of each movie, so you need to click on the link of each movie to get the introduction.
The output is: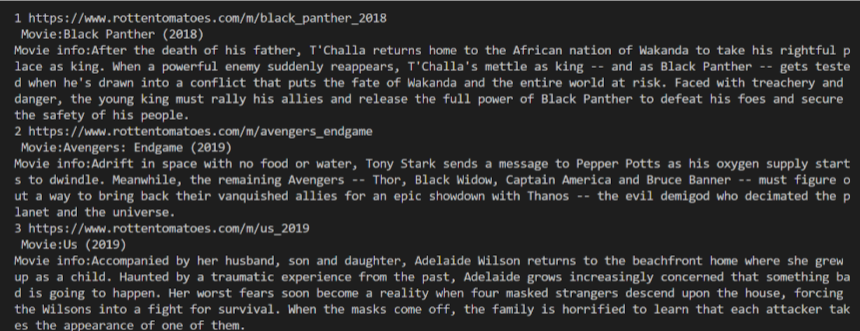
Write the crawled data to Excel
In order to facilitate data analysis, the crawled data can be written into Excel. We use xlwt to write data into Excel.
Import the xlwt library.
from xlwt import *
Create an empty table.
The result is: