Cвой Джарвис на языке программирования Python
Привет, любитель Python! Эта статья с телеграм канала PythonGuru, подпишись если любишь Python!
Я думаю что все знают голосового помощника Джарвиса из фильма «Железный человек». И много кто мечтал сделать голосового помощника своими руками. В этой статье мы его напишем.
Создаём в папке вот такие файлы:
Открываем файл functions.py и импортируем библиотеки и остальные файлы:
После этого вставляем данный код и вписываем в строку alias название помощника(у нас pythonguru):
Дальше подключаем микрофон и голос самого помощника
Если у вас не работает микрофон то пробуйте менять значение device_index=1 (например на device_index=2)
Далее вставляем весь этот код (функции разговора ассистента, фунции прослушки микрофона и возможности самого ассистента):
Этот файл будет служить для запуска всего ассистента
С его помощью мы будем открывать любые сайты.
Самый простейший калькулятор на пайтоне
Как видите сделать своего голосового помощника на Python не так уж сложно, главное иметь знания об основах языка и всё получится.
Совершенствуй знания по Python каждый день у нас на телеграм канале, PythonGuru.
Помогите пожалуйста реализовать на Manjaro linux
скорее-всего у тебя новая версия питона. Попробуй откатить до 3.6 или скачать готовый установочный пакет, вместо установки через pip.
Скачай отсюда whl файл PyAudio под твою версию питона и ОС
https://www.lfd.uci.edu/
gohlke/pythonlibs/#pyaudio
введи в консоль: pip install название файла PyAudio
например:
pip install PyAudio‑0.2.11‑cp38‑cp38‑win_amd64.whl
Простой интерпретатор с нуля на Python (перевод) #1

Вещь, которая привлекла меня изучать компьютерную науку была компилятором. Я думал, что это все магия, как они могут читать даже мой плохо написанный код и компилировать его. Когда я прошел курс компиляторов, я стал находить этот процесс очень простым и понятным.
Сущность языка IMP
Прежде всего, давайте обсудим, для чего мы будем писать интерпретатор. IMP есть нереально простой язык со следующими конструкциями:
Присвоения (все переменные являются глобальные и принимают только integer):
Составные операторы (разделенные ;):
Это всего-лишь игрушечный язык. Но вы можете расширить его до уровня полезности как у Python или Lua. Я лишь хотел сохранить его настолько простым, насколько смогу.
А вот тут пример программы, которая вычисляет факториал:
Язык IMP не умеет читать входные данные (input), т.е. в начале программы нужно создать все нужные переменные и присвоить им значения. Также, язык не умеет выводить что-либо: интерпретатор выведет результат в конце.
Структура интерпретатора
Ядро интерпретатора является ничем иным, как промежуточным представлением (intermediate representation, IR). Оно будет представлять наши IMP-программы в памяти. Так как IMP простой как 3 рубля, IR будет напрямую соответствовать синтаксису языка; мы создадим по классу для каждой единицы синтаксиса. Конечно, в более сложном языке вы хотели бы использовать еще и семантическую представление, которое намного легче для анализа или исполнения.
Процессом разделения символов на токены называется лексинг (lexing), а занимается этим лексер (lexer). Токены являют собой короткие, удобоваримые строки, содержащие самые основные части программы, такие как числа, идентификаторы, ключевые слова и операторы. Лексер будет пропускать пробелы и комментарии, так как они игнорируются интерпретатором.
Процесс сборки токенов в AST называется парсингом. Парсер извлекает структуру нашей программы в форму, которую мы можем исполнить.
Эта статься будет сосредоточена исключительно на лексере. Сначала мы напишем общую лекс-библиотеку а затем уже лексер для IMP. Следующие части будут сфокусированы на парсере и исполнителе.
Лексер
По правде говоря, лексические операции очень просты и основываются на регулярных выражениях. Если вы с ними не знакомы, то можете прочитать официальную документацию.
Входными данными для лексера будет простой поток символов. Для простоты мы прочитаем инпут в память. А вот выходящими данными будет список токенов. Каждый токен включает в себя значение и метку (тег, для идентификации вида токена). Парсер будет использовать это для построения дерева (AST).
Итак, давайте сделаем обычнейший лексер, который будет брать список регэкспов и разбирать на теги код. Для каждого выражения он будет проверять, соответствует ли инпут текущей позиции. Если совпадение найдено, то соответствующий текст извлекается в токен, наряду с тегом регулярного выражения. Если регулярное выражение ни к чему не подходит, то текст отбрасывается. Это позволяет нам избавиться от таких вещей как комментарии и пробелы. Если вообще ничего не совпало, то мы рапортуем об ошибке и скрипт становится героем. Этот процесс повторяется, пока мы не разберем весь поток кода.
Вот код из библиотеки лексера:
Отметим, что порядок передачи в регулярные выражения является значительным. Функция lex будет перебирать все выражения и примет только первое найденное совпадение. Это значит, что при использовании этой функции, первым делом нам следует передавать специфичные выражения (соответствующие операторам и ключевым словам), а затем уже обычные выражения (идентификаторы и числа).
Лексер IMP
С учетом кода выше, создание лексера для нашего языка становится очень простым. Для начала определим серию тегов для токенов. Для языка нужно всего лишь 3 тега. RESERVED для зарезервированных слов или операторов, INT для чисел, ID для идентификаторов.
Теперь мы определим выражения для токенов, которые будут использованы в лексере. Первые два выражения соответствуют пробелам и комментариям. Так как у них нету тегов, лексер их пропустит.
После этого следуют все наши операторы и зарезервированные слова.
Наконец, нам нужны выражения для чисел и идентификаторов. Обратите внимание, что регулярным выражениям для идентификаторов будут соответствовать все зарезервированные слова выше, поэтому очень важно, чтобы эти две строчки шли последними.
Когда наши регэкспы определены, мы можем создать обертку над функцией lex:
Если вы дочитали до этих слов, то вам, скорее всего, будет интересно как работает наше чудо. Вот код для теста:
Скачать полный исходный код: imp-interpreter.tar.gz
Автор оригинальной статьи — Jay Conrod.
UPD: Спасибо пользователю zeLark за исправление бага, связанного с порядком определения шаблонов.
Как объединить 5 языков программирования в одном Python проекте?
На сегодняшний день существует несколько тысяч языков программирования, каждый из которых создавался с определенной целью, пытаясь изменить и улучшить недостатки своих предшественников. Так, например, появился язык Kotlin, который был нацелен на замену Java в мобильной разработке. В 2010 году увидел свет язык Rust, разработчики которого пытались создать быстрый и безопасный язык, который закрывал бы многие недостатки C/C++.
Сейчас практически никто не ставит цели создать универсальный язык для всех задач и всех платформ, так как в каждой области есть свои потребности и нюансы для языка. Например, если в системной разработке требуется следить за памятью, то в местах, где нужно написать простой рабочий продукт, можно пренебречь тем, сколько памяти использует язык для своей работы.
Но что делать, если необходимо использовать несколько языков программирования в одном проекте?
Зачастую бывает так, что один язык не очень хорошо может справляться с теми задачами, которые нужно решить. Для этого программист может без проблем пересесть на другой язык. Но что делать, если уже имеется какая-то часть кода, которая написана на одном языке программирования, а другая часть кода на другом? Например, есть приложение, написанное на Python и есть какие-то структуры, модули или методы, которые написаны на Java (C/C#/JS) и уже оптимизированы с учетом этого языка, а переписывание этого кода на Python может занять много времени, да и код на Python будет выполняться намного медленнее и использовать больше памяти.
Можно попробовать объединить все эти наработки в одно приложение. Благо на сегодняшний день уже реализовано много библиотек, которые позволят без лишних проблем это сделать.
Цель статьи: попробовать написать одно приложение, где будет использоваться код, написанный на 5 разных языках программирования.
В качестве примера языки будут реализовать следующее: Cи будет проверять число на простоту методом квадратного корня, C# проверит число на простоту методом Милера-Рабина, Java проверит число на простоту методом Ферма, Python будет раскладывать число на множители, а JS будет высчитывать сумму числового ряда для полученных множителей.
Для того, чтобы запустить код Java из Python необходимо создать maven java проект (я пользуюсь IntellIJ). В нем создать модуль (я назвал его pkg_java) и в нем создать класс (название: JavaPrime) с логикой проверки числа на простоту методом Ферма:
 Создание jar-артефакта
Создание jar-артефакта
Модуль Java был успешно загружен, теперь можно пользоваться тестом Ферма.
Для того, чтоб запустить C# код в Python, нужно для начала создать библиотеку классов C# (я использовал VS2019):
Назовем проект is_prime_csharp (данный проект в будущем будет импортироваться в Python с таким же названием). Реализуем логику алгоритма Милера-Рабин:
Теперь модуль C# готов к работе, методом Милера-Рабина для проверки числа на простоту можно пользоваться.
Для связи С с Python сначала реализуем алгоритм квадратного корня для проверки числа на простоту:
Модуль C успешно загружен.
JavaScript
В main.py пропишем логику запуска программы:
С такой структурой программы:
 структура Python проекта
структура Python проекта
И вызовем метод JS из Python:
Python
Для начала реализуем метод факторизации чисел:
Результат
Программа имеет простой графический интерфейс:
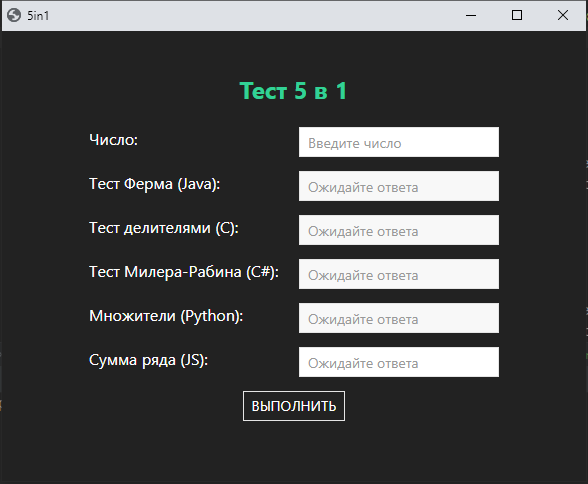 интерфейс итоговой программы
интерфейс итоговой программы
Необходимо ввести число в поле “Число” и нажать кнопку “выполнить”. После чего через JS обработать нажатие данной кнопки и вызвать метод из Python:
Теперь можно запустить программу и проверить, будет ли всё вместе работать:
 Тест программы простым число 12421
Тест программы простым число 12421  Тест программы составным числом 12879
Тест программы составным числом 12879
Вывод
Связать несколько языков программирования вместе в одной программе возможно, но это не совсем хорошая идея, так как при запуске программы на стороннем ПК надо быть уверенным, что у пользователя установлены нужные сервисы/зависимости/ПО, например, стоит ли JVM. Для быстрой проверки работоспособности каких-то идей, модулей, логики можно попробовать использовать подход, описанный в статье. Данный способ позволяет экономить кучу времени, вместо того, чтобы мучаться и переписывать код на другой язык в надежде, что всё будет работать как надо. Этот способ может подойти в тех случаях, когда нет возможности разработать адекватную микросервисную архитектуру приложения, а нужно использовать несколько разных кусков кода/модулей.
Как итог, получилось связать Python + JS + Java + C + C# (+ HTML + CSS) в одной программе, сделав при этом полноценное десктопное приложение, которое работает быстро без лишних задержек при обращении к методам, написанным на другом языке. В таком подходе есть плюсы: можно использовать фишки других языков (например, использовать преимущества скорости в C, Java, C# с (или без) использованием многопоточности, задействующей несколько ядер процессора, а также можно реализовывать структуры, которые будут использовать меньше памяти нежели Python).
Пишем свой язык программирования без мам, пап и бизонов. Часть 0: теория
Тема написания своего ЯПа не дает мне покоя уже около полугода. Я не ставил перед собой цель «убить» CoffeeScript, TypeScript, ELM, тысячи их, я просто хотел понять кухню и как они вообще пишутся.
К моему неприятному удивлению, большинство из этих языков используют Jison (Bison для JavaScript), а это не совсем попадало под мою задачу — «понять», так как по сути дела Jison делает все за вас, собирает AST по заданным вами правилам (Jison как таковой отличный инструмент, который делает за вас львиную долю работы, но сейчас не о нем).
В конечном итоге я методом проб и ошибок (а если сказать точнее, чтения статей и реверс инжиниринга) научился писать свои полноценные языки программирования от разбития исходного текста на лексемы до его трансляции в JS код.
Стоит заметить, что данное руководство не привязано к JavaScript, он выбран исключительно из соображений скорости разработки и читаемости, так что вы можете написать свой «лисп»/»питон»/»ваш абсолютно новый синтаксис» на любом знакомом вам языке.
Также до момента написании компилятора (в нашем случае транслятора), процесс написания языка не отличается от процессов создания языков компилируемых в ASM/JVM bitcode/LLVM bitcode/etc, а это значит, что данное руководство не ограничивается созданием языка трансляцируемого в JavaScript.
Весь код, который будет написан в данной (и последующих статьях), лежит на Github’е. Тегами обозначены начало и концы статей для удобства.
Немного теории
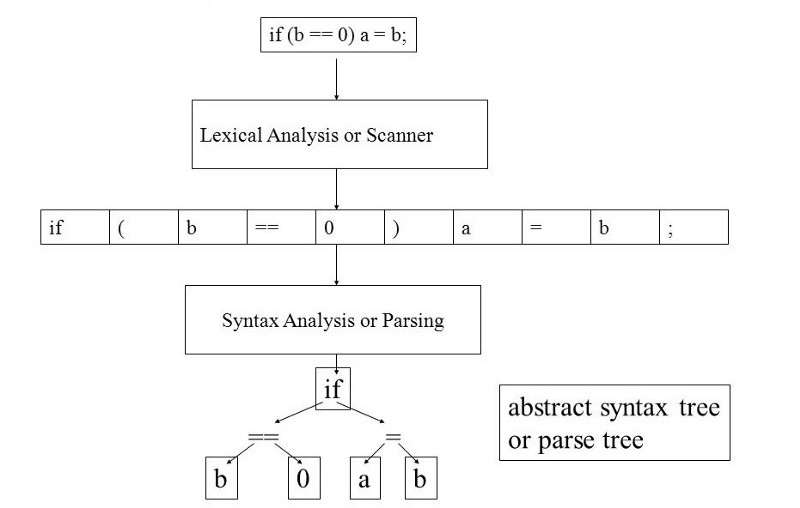
Не углубляясь в википедийность, процесс трансляции исходного кода в конечный JS код протекает следующим образом:
Что тут происходит:
1) Lexer
Исходный код нашей программы разбивается на лексемы. По-простому это нахождение в исходном тексте ключевых слов, литералов, символов, идентификаторов и т.д.
Т.е. на выходе из этого (CoffeeScript):
Мы получаем это (сокращенная запись):
Так-как CoffeeScript отступо-чувствительный и не имеет явного выделения блока скобками < и >, блоки отделяются отступами ( INDENT ом и OUTDENT ом), которые по сути заменяет скобки.
2) Parser
Парсер составляет AST из токенов (лексем). Он обходит весь массив и рекурсивно подбирает подходящие паттерны, основываясь на типи токена или их последовательности.
Из полученных токенов в пункте 1, parser составит, примерно такое дерево (сокращенная запись):
Не стоит пугаться объема дерева, на деле он генерируется рекурсивно и его создание не вызывает трудностей.
3) Compiler
Построение конечного кода по AST. Этот пункт можно заменить на компиляцию в байткод, или даже рантайм, но в рамках данной серии статей мы рассмотрим реализацию транслятора в другой язык программирования.
Компилятор (читай транслятор) преобразует Абстрактно-Синтаксическое Дерево в JavaScript код:
Вот и все. Большинство компиляторов работают именно по такому принципу (с незначительными изменениями. Иногда добавляют процесс стримминга исходного текста в поток символов, иногда напротив объединяют парсинг и компиляцию в один этап, но не нам их судить).
Habrlang
Итак, разобравшись с теорией, нам предстоит собрать свой язык программирования, у которого будет примерно следующий синтаксис (что-бы не особо париться, мы будем делать смесь из Ruby, Python и CoffeeScript):
В следующей главе вы реализуем все основные классы нашего транслятора, и научим его транслировать комментарии Habrlang‘а в JavaScript.
Создаем свой язык программирования с блэкджеком и компилятором
В этом пособии с соответствующими примерами кода рассказываем о том, как написать при помощи Python свой язык программирования и компилятор к нему.
Введение
Изучение компиляторов и устройства языков программирования по видеоурокам и руководствам – дело для новичков тяжелое. В этих материалах нередко отсутствуют важные составляющие. Цель публикации – помочь людям, ищущим способ создать свой язык программирования и компилятор. Пример игрушечный, но позволит понять, с чего начать и в каком направлении двигаться.
Системные требования
Если вы незнакомы с нижеприведенными понятиями, не беспокойтесь – мы проясним необходимость этих компонентов далее, по ходу создания компилятора. В качестве лексера и парсера используется PLY. В роли низкоуровневого языка-посредника для генерации оптимизированного кода выступает LLVMlite.
Таким образом, к системе предъявляются следующие требования:
Свой язык программирования: с чего начать?
Начнем с того, что назовем свой язык программирования. В качестве примера он будет называться TOY. Пусть пример программы на языке TOY выглядит следующим образом:
Любой язык программирования включает множество составляющих его компонентов. Чтобы не застрять в мелочах, возьмем в качестве микропрограммы вызов одной функции нашего языка:
Как для этой однострочной программы формально описать грамматику языка? Чтобы это сделать, необходимо использовать расширенную Бэкус – Наурову форму (РБНФ) (англ. Extended Backus–Naur Form ( EBNF )). Это формальная система определения синтаксиса языка. Воплощается она при помощи метаязыка, определяющего в одном документе всевозможные грамматические конструкции. Чтобы в деталях разобраться с тем, как работает РБНФ, прочтите эту публикацию.
Создаем РБНФ (EBNF)
Создадим РБНФ, которая опишет минимальный функционал нашей микропрограммы. Начнем с операции суммирования:
Соответствующая РБНФ будет выглядеть следующим образом:
Дополним язык операцией вычитания:
В соответствующем РБНФ изменится первая строка:
Наконец, опишем функцию print:
В этом случае в РБНФ появится новая строка, описывающая работу с выражениями:
В таком ключе развивается описание грамматики языка. Как же научить компьютер транслироваться эту грамматику в бинарный исполняемый код? Для этого нужен компилятор.
Компилятор
Компилятор – это программа, переводящая текст ЯП на машинный или другие языки. Программы на TOY в этом руководстве будут компилироваться в промежуточное представление LLVM IR (IR – сокращение от Intermediate Representation) и затем в машинный язык.
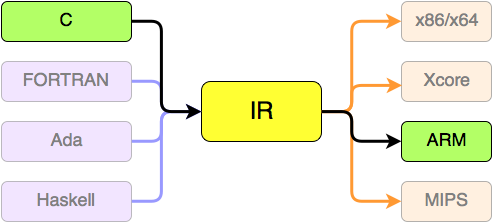
Использование LLVM позволяет оптимизировать процесс компиляции без изучения самого процесса оптимизации. У LLVM действительно хорошая библиотека для работы с компиляторами.
Наш компилятор можно разделить на три составляющие:
Для лексического анализатора и парсера мы будем использовать RPLY, очень близкий к PLY. Это библиотека Python с теми же лексическими и парсинговыми инструментами, но с более качественным API. Для генератора кода будем использовать LLVMLite – библиотеку Python для связывания компонентов LLVM.
1. Лексический анализатор
Итак, первый компонент компилятора – лексический анализатор. Роль этого компонента заключается в том, чтобы разделять текст программы на токены.
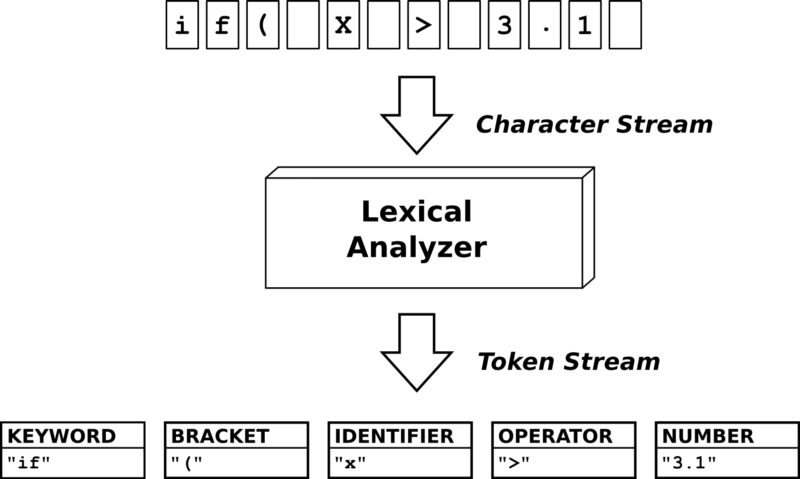
Воспользуемся последней структурой из примера для РБНФ и найдем токены. Рассмотрим команду:
Наш лексический анализатор должен разделить эту строку на следующий список токенов:
Напишем код компилятора. Для начала создадим файл lexer.py, в программном коде которого будут определяться токены. Для создания лексического анализатора воспользуемся классом LexerGenerator библиотеки RPLY.
Создадим основной файл программы main.py. В этом файле мы впоследствии объединим функционал трех компонентов компилятора. Для начала импортируем созданный нами класс Lexer и определим токены для нашей однострочной программы:
При запуске main.py мы увидим на выходе вышеописанные токены. Вы можете изменить названия своих токенов, но для простоты согласования с функциями парсера их лучше оставить как есть.
2. Синтаксический анализатор
Второй компонент компилятора – синтаксический анализатор (он же парсер). Его роль – синтаксический анализ текста программы. Данный компонент принимает список токенов на входе и создает на выходе абстрактное синтаксическое дерево (АСД). Эта концепция более трудна, чем идея списка токенов, поэтому мы настоятельно рекомендуем хотя бы по приведенным выше ссылкам изучить принципы работы парсеров и синтаксических деревьев.
Чтобы воплотить в жизнь синтаксический анализатор, будем использовать структуру, созданную на этапе РБНФ. К счастью, анализатор RPLY использует формат, схожий с РБНФ. Самое сложное – присоединить синтаксический анализатор к АСД, но когда вы поймете идею, это действие станет действительно механическим.
Во-первых, создадим файл ast.py. Он будет содержать все классы, которые могут быть вызваны парсером, и создавать АСД.
Во-вторых, нам необходимо создать сам анализатор. Для этого в новом файле parser.py аналогично лексеру используем класс ParserGenerator из библиотеки RPLY:
Наконец, обновляем файл main.py, чтобы объединить возможности синтаксического и лексического анализаторов:
Теперь при запуске main.py мы получим значение 6. и оно действительно соответствует нашей однострочной программе «print(4 + 4 – 2);».
Таким образом, при помощи двух этих компонентов мы создали работающий компилятор, интерпретирующий язык TOY. Однако компилятор по-прежнему не создает исполняемый машинный код и не оптимизирован. Для этого мы перейдем к самой сложной части руководства – генерации кода с помощью LLVM.
3. Генератор кода
Третья и последняя часть компилятора – это генератор кода. Его роль заключается в том, чтобы преобразовывать АСД в машинный код или промежуточное представление. В нашем случае будет происходить преобразование АСД в промежуточное представление LLVM (LLVM IR).
LLVM может оказаться действительно сложным для понимания инструментом, поэтому обратите внимание на документацию LLVMlite. LLVMlite не имеет реализации для функции печати, поэтому вы должны определить собственную функцию.
Чтобы начать, создадим файл codegen.py, содержащий класс CodeGen. Этот класс отвечает за настройку LLVM и создание/сохранение IR-кода. В нем мы также объявим функцию печати.
Теперь обновим основной файл main.py, чтобы вызывать методы CodeGen:
Как вы можете видеть, для того, чтобы обработка происходила классическим образом, входная программа была вынесена в отдельный файл input.toy. Это уже больше похоже на классический компилятор. Файл input.toy содержит все ту же однострочную программу:
Еще одно изменение – передача парсеру методов module, builder и printf. Это сделано, чтобы мы могли отправить эти объекты АСД. Таким образом, для получения объектов и передачи их АСД необходимо изменить parser.py:
Наконец, самое важное. Мы должны изменить файл ast.py, чтобы получать эти объекты и создавать LLMV АСД, используя методы из библиотеки LLVMlite:
После изменений компилятор готов к преобразованию программы на языке TOY в файл промежуточного представления LLVM output.ll. Далее используем LLC для создания файла объекта output.o и GCC для получения конечного исполняемого файла:
Теперь вы можете запустить исполняем файл, для создания которого вами использовался свой язык программирования:
Следующие шаги
Мы надеемся, что после прохождения этого руководства вы разобрались в общих чертах в концепции РБНФ и трех основных составляющих компилятора. Благодаря этим знаниям вы можете создать свой язык программирования и написать оптимизированный компилятор при помощи Python. Мы призываем вас не останавливаться на достигнутом и добавить в свой язык и компилятор другие важные составляющие:
Итоговый программный код вы также найдете на GitHub.