Robots.txt
Файл robots.txt является одним из самых важных при оптимизации любого сайта. Его отсутствие может привести к высокой нагрузке на сайт со стороны поисковых роботов и медленной индексации и переиндексации, а неправильная настройка к тому, что сайт полностью пропадет из поиска или просто не будет проиндексирован. Следовательно, не будет искаться в Яндексе, Google и других поисковых системах. Давайте разберемся во всех нюансах правильной настройки robots.txt.
Для начала короткое видео, которое создаст общее представление о том, что такое файл robots.txt.
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
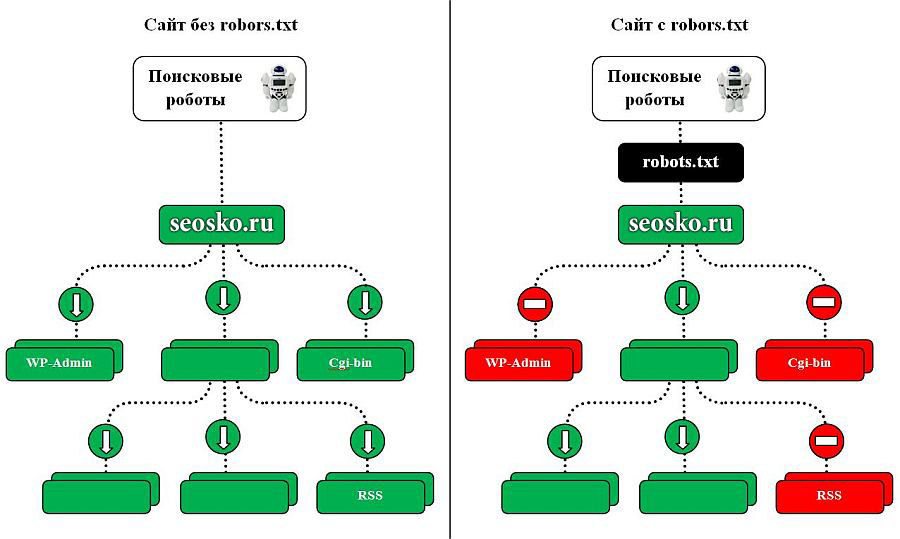
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:
User-agent: *
Для конкретного бота:
User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:
user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Disallow закрывает от индексирования страницы и разделы сайта.
Allow принудительно открывает для индексирования страницы и разделы сайта.
Но здесь не все так просто.
* — это любое количество символов, в том числе и их отсутствие. При этом в конце строки звездочку можно не ставить, подразумевается, что она там находится по умолчанию.
$ — показывает, что символ перед ним должен быть последним.
# — комментарий, все что после этого символа в строке роботом не учитывается.
Примеры использования:
Disallow: *?s=
Disallow: /category/$
Следующие ссылки будут закрыты от индексации:
http://site.ru/?s=
http://site.ru/?s=keyword
http://site.ru/page/?s=keyword
http://site.ru/category/
Следующие ссылки будут открыты для индексации:
http://site.ru/category/cat1/
http://site.ru/category-folder/
Во-вторых, нужно понимать, каким образом выполняются вложенные правила.
Помните, что порядок записи директив не важен. Наследование правил, что открыть или закрыть от индексации определяется по тому, какие директории указаны. Разберем на примере.
Allow: *.css
Disallow: /template/
http://site.ru/template/ — закрыто от индексирования
http://site.ru/template/style.css — закрыто от индексирования
http://site.ru/style.css — открыто для индексирования
http://site.ru/theme/style.css — открыто для индексирования
Allow: *.css
Allow: /template/*.css
Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Директива для указания главного зеркала сайта (в большинстве случаев: с www или без www). Обратите внимание, что главное зеркало указывается БЕЗ http://, но С https://. Также если необходимо, то указывается порт.
Директива поддерживается только ботами Яндекса и Mail.Ru. Другими роботами, в частности GoogleBot, команда не будет учтена. Host прописывается только один раз!
Пример 1:
Host: site.ru
Пример 2:
Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Смысл директив:
Request-rate: 1/5 — загружать не более одной страницы за пять секунд
Visit-time: 0600-0845 — загружать страницы только в промежуток с 6 утра до 8:45 по Гринвичу.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
Пример robots.txt
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях.
Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Как составить правильный robots.txt для Яндекса и Google [инструкция]
Примеры готового файла robots.txt. Решения для сайтов на WordPress, Битрикс, OpenCart и Joomla.
Вебмастер может направить поисковых ботов на страницы, которые считает обязательными для индексирования, и скрыть те, которых в выдаче быть не должно. Для этого предназначен файл robots.txt. Команда сервиса для анализа сайта PR-CY составила гайд об этом файле: для чего он нужен, из каких команд состоит, как составить его по правилам и проверить.
Зачем нужен robots.txt
С помощью этого файла можно повлиять на поведение ботов Яндекса и Google. Файл robots.txt содержит указания для краулеров, предназначенных для индексирования сайта. Он состоит из списка команд, которые рекомендуют либо просканировать, либо пропустить конкретные страницы или целые разделы сайта. Если боты «прислушаются» к этим пожеланиям, то не будут посещать закрытые страницы или индексировать определенный тип контента.
Закрывают обычно дублирующие страницы, служебные, неинформативные, страницы с GET-параметрами или просто неважные для пользователей.
Как надежно закрыть страницу от ботов
Поисковики не воспринимают robots.txt как список жестких правил, это только рекомендации. Даже если в robots стоит запрет, страница может появиться в выдаче, если на нее ведет внешняя или внутренняя ссылка.
Страница, доступ к которой запретили только в robots.txt, может попасть в выдачу и будет выглядеть так:
 Главная страница сайта в выдаче, но описание бот составить не смог
Главная страница сайта в выдаче, но описание бот составить не смог
Если вы точно не хотите, чтобы страница попала в индекс, недостаточно запретить сканирование в файле robots.txt. Один из вариантов, подходящий для служебных страниц, — запаролить ее. Бот не сможет просканировать содержимое страницы, если она доступна только пользователям, авторизованным через логин и пароль.
Если страницы нельзя закрыть паролем, но не хочется показывать их ботам, есть вариант применить директивы «noindex» и «nofollow». Для этого нужно добавить их в секцию HTML-кода страницы:
Чтобы робот правильно интерпретировал «noindex» и «nofollow» и не добавил страницу в индекс, не закрывайте одновременно доступ к ней в файле robots.txt. Так бот не получит доступа к странице и не увидит запрещающих директив.
Требования поисковых систем к файлу robots.txt
Каким должен быть файл, как его оформить и куда размещать — в этом и Яндекс, и Google солидарны:
Подробные рекомендации для robots.txt от Яндекса читайте здесь, от Google — здесь.
Дальше рассмотрим, каким образом можно давать рекомендации ботам.
Как правильно составить robots.txt
Файл состоит из списка команд (директив) с указанием страниц, на которые они распространяются, и адресатов — имён ботов, к которым команды относятся.
Директиву Clean-param воспринимают только боты Яндекса, а в остальном в 2021 году команды для ботов Google и Яндекса одинаковы.
Основные обозначения файла
User-agent — какой бот должен прореагировать на команду. После двоеточия указывают либо конкретного бота, либо обобщают всех с помощью символа *.
Пример. User-agent: * — все существующие роботы, User-agent: Googlebot — только бот Google.
Disallow — запрет сканирования. После косого слэша указывают, на что распространяется команда запрета.
Пустое поле в Disallow означает разрешение на сканирование всего сайта:
А эта запись запрещает всем роботом сканировать весь сайт:
Если речь идет о новом сайте, проследите, чтобы в файле robots.txt не осталась эта запись, после того как разработчики выложат сайт на рабочий домен.
Эта запись разрешает сканирование боту Google, а всем остальным запрещает:
Отдельно прописывать разрешения необязательно. Доступным считается всё, что вы не закрыли.
В записях важен закрывающий косой слэш, его наличие или отсутствие меняет смысл:
Disallow: /about/ — запись закрывает раздел «О нас», доступный по ссылке https://example.com/about/
Disallow: /about — закрывает все ссылки, которые начинаются с «/about», включая раздел https://example.com/about/, страницу https://example.com/about/company/ и другие.
Каждому запрету соответствует своя строка, нельзя перечислить несколько правил сразу. Вот неправильный вариант записи:
Правильно оформить их раздельно, каждый с новой строки и своим Disallow:
Allow означает разрешение сканирования, с помощью этой команды удобно прописывать исключения. Для примера запись запрещает всем ботам сканировать весь альбом, но делает исключение для одного фото:
А вот и отдельная команда для Яндекса — Clean-param. Директиву используют, чтобы исключить дубли страниц, которые могут появляться из-за GET-параметров или UTM-меток. Clean-param распознают только боты Яндекса. Вместо нее можно использовать Disallow, эту команду понимают в том числе и гуглоботы.
Допустим, на сайте есть страница page=1 и у нее могут быть такие параметры:
Каждый образовавшийся адрес в индексе не нужен, достаточно, чтобы там была общая основная страница. В этом случае в robots нужно задать Clean-param и указать, что ссылки с дополнениями после «sid» в страницах на «/index.php» индексировать не нужно:
Clean-param: sid /index.php
Если параметров несколько, перечислите их через амперсанд:
Clean-param: sid&utm&ref /index.php
Строки не должны быть длиннее 500 символов. Такие длинные строки — редкость, но из-за перечисления параметров такое может случиться. Если указание получилось сложным и длинным, его можно разделить на несколько. Примеры найдете в Справке Яндекса.
Sitemap — ссылка на карту сайта. Если карты сайта нет, запись не нужна. Сама по себе карта не обязательна, но если сайт большой, то лучше ее создать и дать ссылку в robots, чтобы ботам было проще разобраться в структуре.
Обозначим также два важных спецсимвола, которые используются в robots:
* — предполагает любую последовательность символов после этого знака;
$ — указывает на то, что на этом элементе необходимо остановиться.
Пример. Такая запись:
запрещает роботу индексировать страницу site.com/catalog/category1, но не запрещает индексировать страницу site.com/catalog/category1/product1.
Лучше не заниматься сбором команд вручную, для этого есть сервисы, которые работают онлайн и бесплатно. Инструмент для генерации robots.txt бесплатно соберет нужные команды: открыть или закрыть сайт для ботов, указать путь к sitemap, настроить ограничение на посещение избранных страниц, установить задержку посещений.
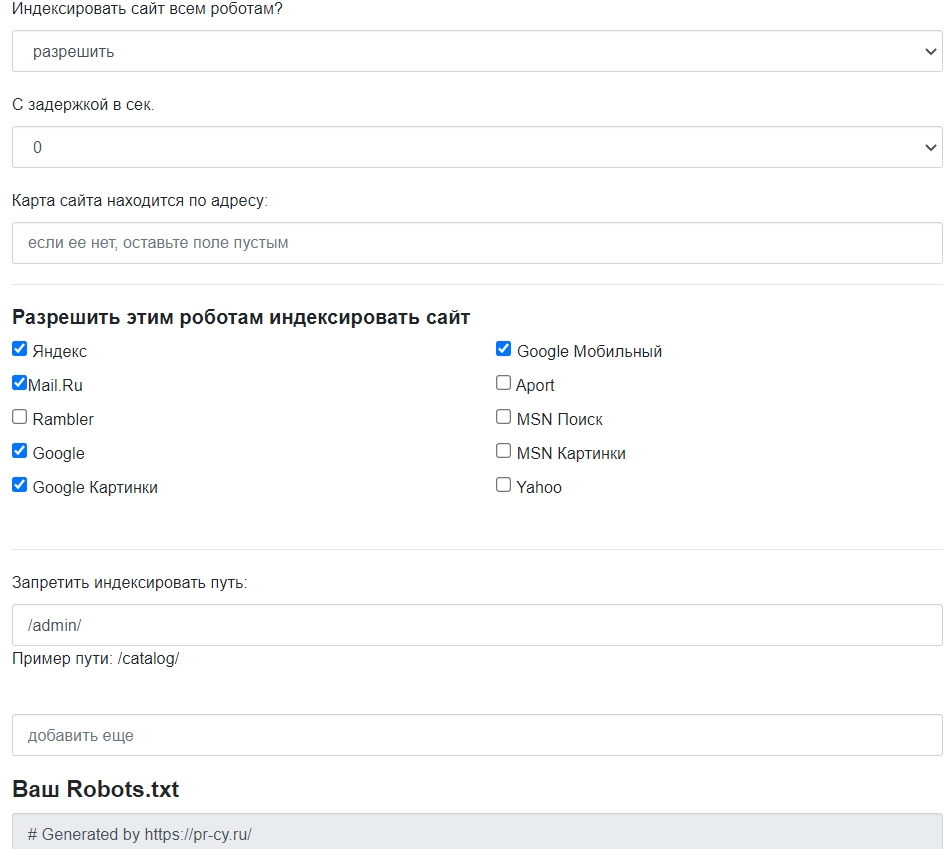 Настройки файла в инструменте
Настройки файла в инструменте
Есть и другие бесплатные генераторы файла, которые позволят быстро создать robots и избежать ошибок. У популярных движков есть плагины, с ними собирать файл еще проще. О них расскажем ниже.
Как проверить правильность robots.txt
После создания файла и добавления в корневой каталог будет не лишним проверить, видят ли его боты и нет ли ошибок в записи. У поисковых систем есть свои инструменты:
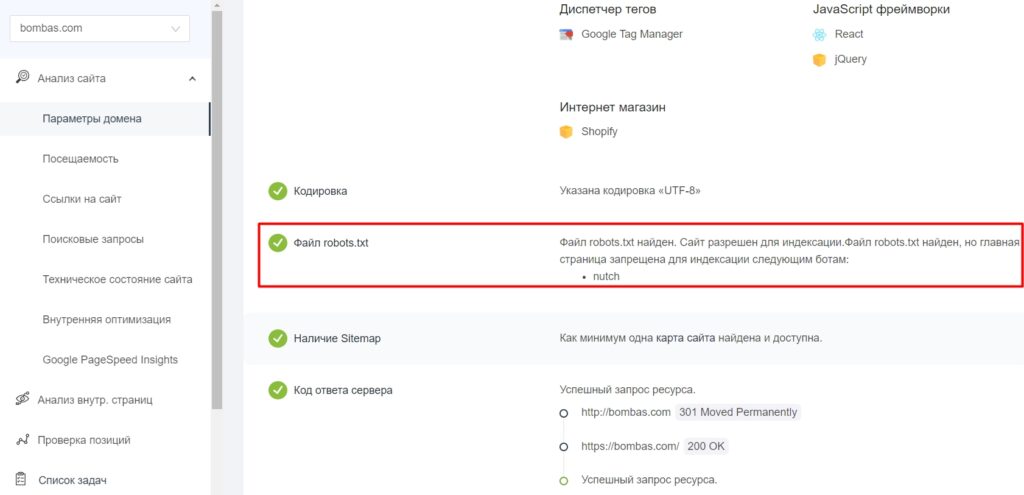 Фрагмент проверки сайта сервисом pr-cy.ru/analysis
Фрагмент проверки сайта сервисом pr-cy.ru/analysis
В «Важных событиях» отобразятся даты изменения файла.
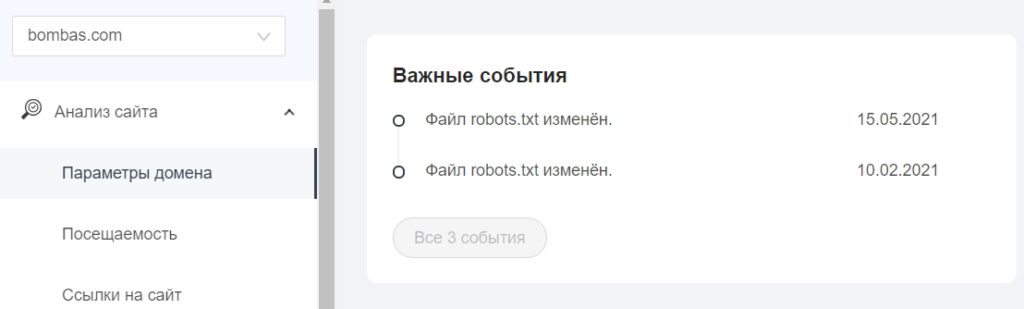 Оповещения в интерфейсе
Оповещения в интерфейсе
Правильный robots.txt для разных CMS: примеры готового файла
Файл robots.txt находится в корневой папке сайта. Чтобы создать или редактировать его, нужно подключиться к сайту по FTP-доступу. Некоторые системы управления (например, Битрикс) предоставляют возможность редактировать файл в административной панели.
Посмотрим, какие возможности для редактирования файла есть в популярных CMS.
WordPress
У WP много бесплатных плагинов, которые формируют robots.txt. Эта опция предусмотрена в составе общих SEO-плагинов Yoast SEO и All in One SEO, но есть и отдельные, которые отвечают за создание и редактирование файла, например:
Пример robots.txt для контентного проекта на WordPress
Это вариант файла для блогов и других проектов без функции личного кабинета и корзины.
User-agent: * # установили общие правила для роботов
Disallow: /cgi-bin # закрыли системную папку, которая находится на хостинге
Disallow: /? # обобщили все параметры запроса на главной странице сайта
Disallow: /wp— # все специальные WordPress-файлы: /wp-json/, /wp-content/plugins, /wp-includes
Disallow: *?s= # здесь и далее перечисление запросов поиска
Disallow: */trackback # закрыли трекбеки — уведомления о появлении ссылки на статью
Disallow: */feed # новостные ленты полностью
Disallow: */rss # rss-ленты
Disallow: */embed # все встраивания
Disallow: /xmlrpc.php # файл API WP
Disallow: *utm*= # все ссылки, у которых прописаны UTM-метки
Disallow: *openstat= # все ссылки, у которых прописаны openstat-метки
Allow: */uploads # открыли доступ к папке с файлами uploads
Allow: /*/*.js # открыли доступ к js-скриптам внутри /wp-, уточнили /*/ для приоритета
Allow: /*/*.css # доступ к css-файлам внутри /wp-, также уточнили /*/ для приоритета
Allow: /wp-*.png # доступ к картинкам в плагинах, папке cache и других в формате png
Allow: /wp-*.jpg # то же самое для формата jpg
Allow: /wp-*.jpeg # для формата jpeg
Allow: /wp-*.gif # и для анимаций в gif
Allow: /wp-admin/admin-ajax.php # открыли доступ к этому файлу, чтобы не блокировать JS и CSS для плагинов
Sitemap: https://example.com/sitemap.xml # указали ссылку на карту сайта (вместо https://example.com нужно подставить сой домен)
Пример robots.txt для интернет-магазина на WordPress
Похожий файл, но со спецификой интернет-магазина на платформе WooCommerce на базе WordPress. Закрываем то же самое, что в предыдущем примере, плюс страницу корзины, а также отдельные страницы добавления в корзину и оформления заказа пользователем.
Как создать и правильно настроить Robots.txt
Robots.txt является стандартом исключений для роботов, принятым консорциумом W3C 30 января 1994 года. Его использует большая часть современных поисковиков, как рекомендацию к индексированию проекта.
Зачем Robots.txt нужен для SEO?
Robots играет одну из важнейших ролей для поисковой оптимизации.
В нем ненужные страницы, не содержащие полезной для пользователей информации, исключаются из поиска, указывается путь к Sitemap.
Если допустить ошибку в инструкциях и директивах, сайт может полностью пропасть из поискового индекса. Важно уметь корректно настраивать данный файл, так как от этого зависит видимость вашего сайта в поисковых системах и дальнейший рост объема трафика на проекте.
Поэтому SEO специалисты, изучая сайт, который им нужно будет продвигать, первым делом проверяют именно роботс.
Где находится и как создать?
Файл robots.txt располагается в корневой директории сайта. К примеру, на сайте https://webmasterie.ru путь к файлу robots будет таким: https://webmasterie.ru/robots.txt.
Ручное создание robots.txt
Для самостоятельного создания файла достаточно воспользоваться любым текстовым редактором:
Затем загружаете файл в корневой каталог сайта – папку с названием вашего ресурса, где также располагаются индексный файл index.html и файлы движка, на базе которого сделан сайт. Для загрузки robots.txt на сервер используют:
Есть движки управления сайтами, у которых есть встроенная функция, позволяющая создать файл роботс в администраторской панели сайта. Если же ее нет, можно установить специальные модули или плагины.
Вообще нет разницы, каким из вышеперечисленных методов создавать данный текстовый файл.
Онлайн генераторы
Вариант для ленивых – онлайн сервисы, генерирующие роботс автоматически. В интернете можно найти множество подобных инструментов, к примеру, на сайте CY-PR.
Такой вариант хорошо подходит владельцам огромного количества сайтов, потому что для всех них будет сложно вручную прописать практически одни и те же инструкции.
Автоматически сгенерированные файлы robots.txt могут потребовать самостоятельной корректировки, поэтому иметь базовые знания синтаксиса и правил написания файла все равно нужно.
Готовые шаблоны
В Сети нет проблем отыскать шаблоны готового robots.txt для популярных движков по типу WordPress, Joomla, Drupal и так далее. В шаблон лишь избавляет от многократного написания стандартных директив и учитывает нюансы определенного движка сайта. Но и тут нужны знания, потому что сам по себе шаблон не предоставит корректно настроенный файл и каждый проект может быть индивидуален.
Как редактировать?
После создания файла Robots вы можете его редактировать в ходе оптимизации ресурса. Делается это непосредственно в текстовом файле robots.txt с соблюдением правил и синтаксиса файла. После редактирования robots.txt выгружайте на сайт обновленную версию файла. Так же для определенных CMS существуют плагины и дополнения, которые позволяют редактировать данный файл прям в админ панели.
Директивы Robots.txt
В Robots.txt прописываются директивы для роботов поисковых систем, тем самым помогая им понять, какие страницы/разделы индексировать, а какие – нет. Рассмотрим, какие директивы что означают:
1. User-Agent. Это обязательная директива, определяющая, к какому роботу будут применяться прописанные ниже правила. По сути, это обращение к конкретному роботу или всем поисковым ботам. Все файлы начинаются именно с этой строчки.
2. Disallow. Самая распространенная директива, запрещающая индексировать отдельные страницы или целые разделы веб-сайта. Здесь зачастую указывают:
3. Allow. Противоположная Disallow директива, разрешающая поисковому роботу обход конкретных страниц или разделов сайта. Здесь, как и в Disallow, допускается применение спецсимволов.
4. Sitemap. Данная директива сообщает ботам расположение XML карты сайта. Нужно указывать полный URL. Она важна для поисковых машин Google и Яндекс, так как при обходе сайта в первую очередь они обращаются именно к Sitemap, где показана структура ресурса со внутренними ссылками, приоритетами индексации страниц и датами их создания или изменения.
5. Clean-param. Запрещает ботам обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц. В основном проблема динамических параметров встречается на сайтах интернет-магазинов, а именно в URL-адресах для передачи данных по источникам сессий, персональных идентификаторов посетителей.
6. Crawl-delay (уже не поддерживается Яндекс и Google). Инструкция ограничивает частоту посещений одного бота в интервал времени. То есть, он задает в секундах минимальный промежуток времени между окончанием загрузки одного документа и началом загрузки следующего. Благодаря данной директиве снижается нагрузка на сервер, чтобы роботы не посещали сайт слишком часто. Проблема актуальна на крупных сайтах с большим количеством страниц.
Важно! Яндекс отказался от Crawl-delay. Вот какой ответ я получил от поисковика:

7. Host (уже не поддерживается Яндекс). Раньше это была межсекционная инструкция чисто для Яндекса, никакие другие поисковики ее не понимали. Она служила для указания главному роботу Яндекса главного зеркала сайта, если есть доступ к сайту по нескольким доменам. Но с марта месяца 2018 года Яндекс больше не использует директиву Host. Ее функции взял на себя раздел “Переезд сайта в Вебмастере” и 301 редирект.
Что нужно исключать из индекса
1. В первую очередь роботам следует запретить включать в индекс любые дубли страниц. Доступ к странице должен осуществляться только по одному URL. Обращаясь к сайту, поисковый бот по каждому УРЛу должен получать в ответ страницу с уникальным содержанием. Дубли часто появляются у CMS в процессе создания страниц. Так, один и тот же документ можно найти по техническому УРЛ http://site.ru/?p=391&preview=true и ЧПУ http://site.ru/chto-takoe-seo. Нередко дубли появляются и из-за динамических ссылок. Нужно их всех скрывать от индекса с помощью масок:
2. Все страницы с неуникальным контентом. Такие документы рекомендуется скрыть от поисковых машин до того, как они попадут в индекс.
3. Все страницы, применяемые при работе сценариев. К таким страницам относят такие, где есть подобные сообщения: “Спасибо за ваш отзыв!”.
4. Страницы, включающие индикаторы сессий. Для подобных страниц тоже рекомендуется использовать директиву Disallow:
5. Все файлы движка управления сайтом. К ним относятся файлы шаблонов, администраторской панели, тем, баз и прочие:
6. Бесполезные для пользователей страницы и разделы. Без какого-либо содержания, с неуникальным контентом, результаты поиска, несуществующие и так далее.
Держите файл robots.txt в чистоте, и тогда ваш сайт будет индексироваться быстрее и лучше, а ранжироваться выше.
Структура Robots.txt
Так выглядит стандартный шаблон структуры файла robots обычного веб-сайта:
Как видно из инструкции выше, файл содержит блоки с инструкциями и начинается он, как я уже упоминал выше, с правила User-agent, указывающего, к какому роботу идет обращение и прописываются директивы ниже.
Вот несколько примеров директив User-agent для роботов разных поисковиков:
Оптимизаторы в robots.txt эти три директивы используют чаще всего. Это общие роботы поисковиков, но есть также и инструкции, описываемые для ботов, индексирующих, например, только новостные разделы:
В них тоже допускается прописывать определенные директории.
Таким образом мы разрешаем обходить сайт только роботам Яндекса и Google:
После каждого правила User-agent следуют инструкции для робота, указанного в данной строке. Чаще всего применяются команды Disallow. Allow прописываются редко, так как отсутствие противоположной директории равносильно разрешению на индексацию.
Кириллица в файле Robots
Писать кириллические символы в директориях robots.txt, а также HTTP-заголовках сервера запрещено.
Чтобы указывать названия кириллических доменов, воспользуйтесь Punycode. URL-адреса указывайте в кодировке, которая соответствует структуре ресурса.
Основные правила, характеристики файла и синтаксис
При создании файла robots.txt необходимо соблюдать синтаксические правила и следовать характеристикам файла, от которых зависит корректность его работы. Рассмотрим их подробнее:
Как проверить Robots.txt?
После загрузки файла на сервер нужно обязательно проверить, доступен ли он, корректно ли написан и нет ли ошибок.
Проверка на сайте
Сделав все верно и загрузив файл в корневой каталог сайта, он станет доступным по ссылке типа site.ru/robots.txt (вместо site.ru указывается URL вашего ресурса).
Это общедоступный файл и его можно посмотреть и изучить у любого сайта.
Проверка на ошибки
Сделать это можно двумя способами:
Здесь вы увидите все ошибки в файле, если они есть, и получите сообщения о серьезных ограничениях в директивах.
Robots.txt в Яндекс и Google
Многие оптимизаторы, делая первые шаги в работе с robots.txt, задаются логичным вопросом о том, почему нельзя указать общий User-agent: * и не указывать для робота каждой поисковой системы одни и те же инструкции. Дело в том, что поисковик Google более позитивно воспринимает директиву User-agent: Googlebot в файле robots, как и Яндекс отдельную директиву User-agent: Yandex.
Прописывая правила отдельно для Google и Яндекс, вы сможете управлять индексацией страниц и разделов веб-ресурса посредством Robots. Более того, применяя персональные User-agent можно запретить индексацию некоторых файлов Google, при этом оставить их доступными для роботов Яндекса, и наоборот.
Максимально допустимый размер текстового документа robots в 32 КБ предоставляет возможность почти любому сайту указать все важнейшие для индексирования инструкции в отдельных юзер-агентах для разных поисковиков. Поэтому не вижу смысла проводить рискованные эксперименты.
Заключение
Файл Robots – это один из ключевых инструментов для успешного SEO-продвижения сайта. С его помощью вы можете непосредственно влиять на включение в индекс различных страниц и разделов веб-ресурса.
Правильно настроенный файл поспособствует экономии краулингового бюджета, который очень ограничен, облегчит жизнь поисковым машинам, которым не придется обходить сотни служебных страниц, разгрузит ваш сервер, уберет из выдачи спам. И самое главное – ваш сайт будет индексироваться быстро и корректно.
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.