Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
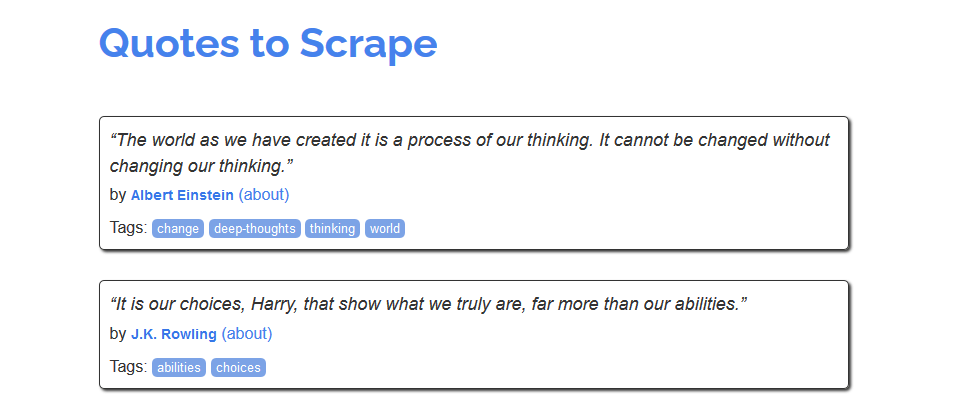
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.
Создание скрипта скрапинга
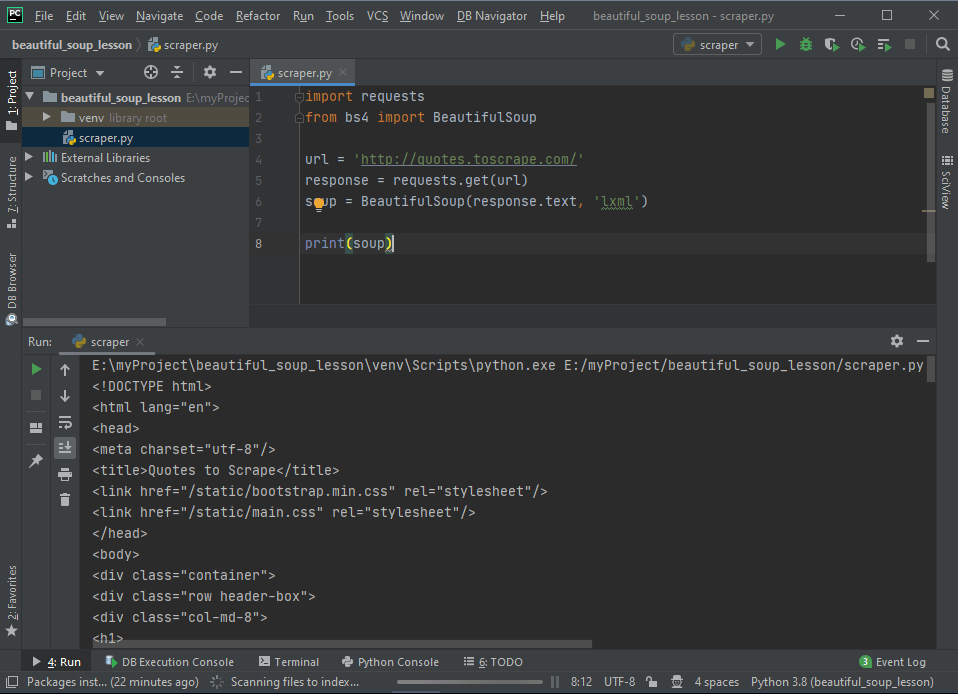
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
Прохождение по структуре HTML
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.

Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.
Парсинг HTML-разметки
Пишем изящный парсер на Питоне
довольно общеупотребительны. Код выше лёгким движением руки программиста (и тяжёлым движением руки комитета по стандартизации) превращается в:
Стало чуть-чуть лучше, хотя всё ещё не выглядит идеально. В Python нет и такого, но если вы ненавидите if в Python-коде так же сильно, как я, и хотите научиться быстро писать простые парсеры, то добро пожаловать под кат. В этой статье мы попытаемся написать короткий и изящный парсер для JSON на Python 2 (без каких-либо дополнительных модулей, конечно же).
Что такое парсинг и с чем его едят
Парсинг (по-русски «синтаксический анализ») — это бессмертная задача разобрать и преобразовать в осмысленные единицы нечто, написанное на некотором фиксированном языке, будь то язык программирования, язык разметки, язык структурированных запросов или главный язык жизни, Вселенной и всего такого. Типичная последовательность этапов решения задачи выглядит примерно так:
Модельная задача
Написание парсера проиллюстрируем на простом, но не до конца тривиальном примере — парсинге JSON. Грамматика выглядит примерно так:
Здесь нет правил для string и number — они, вместе со всеми строками в кавычках, будут нашими токенами.
Парсим JSON
Полноценный токенайзер мы писать не станем (это скучно и не совсем тема статьи) — будем работать с целой строкой и бить её на токены по мере необходимости. Напишем две первые функции:
(Я обещал без if’ов, но это последние, чесслово!)
Для всего остального напишем одну функцию, генерящую простенькие функции-парсеры:
Итого, по какому принципу мы строим наши функции:
Парсим правило с ветвлением
Ну уж нет, эти if достали меня!
Но на второй взгляд мы увидим, что каждая опция может занимать всего одну строчку!
При этом эффективность остаётся на прежнем уровне — каждая функция начнёт выполняться (а стало быть, делать работу, проверяя регулярные выражения) только тогда, когда предыдущая не даст результата. return гарантирует, что лишняя работа не будет выполнена, если где-то в середине списка парсинг удался.
Парсим последовательности конструкций
С этим мощным (пусть и страшноватым) инструментом наша функция перепишется в виде:
Ну а дописать функцию parse_comma_separated_values — раз плюнуть:
Приведёт ли такое решение к бесконечной рекурсии? Нет! Однажды функция parse_comma не найдёт очередной запятой, и до последующей parse_comma_separated_values выполнение уже не дойдёт.
Идём дальше! Объект:
Ну, что там дальше?
Собственно, всё! Остаётся добавить простую интерфейсную функцию:
130 строк. Попробуем запустить:
Заключение
Конечно, я рассмотрел далеко не все ситуации, которые могут возникнуть при написании парсеров. Иногда программисту может потребоваться ручное управление выполнением, а не запуск последовательности chain ов и sequence ов. К счастью, это не так неудобно в рассмотренном подходе, как может показаться. Так, если нужно попытаться распарсить необязательную конструкцию и сделать действие в зависимости от её наличия, можно написать:
Несмотря на неполноту и неакадемичность изложения, я надеюсь, что эта статья будет полезна начинающим программистам, а может, даже удивит новизной подхода программистов продвинутых. При этом я прекрасно отдаю себе отчёт, что это просто новая форма для старого доброго рекурсивного спуска; но если программирование — это искусство, разве не важна в нём форма если не наравне, то хотя бы в степени, близкой к содержанию.
Как обычно, не откладывая пишите в личку обо всех обнаруженных неточностях, орфографических, грамматических и фактических ошибках — иначе я сгорю от стыда!
Почему стоит научиться «парсить» сайты, или как написать свой первый парсер на Python
В этой статье я постараюсь понятно рассказать о парсинге данных и его нюансах.

Для начала давайте разберемся, что же действительно означает на первый взгляд непонятное слово — парсинг. Прежде всего это процесс сбора данных с последующей их обработкой и анализом. К этому способу прибегают, когда предстоит обработать большой массив информации, с которым сложно справиться вручную. Понятно, что программу, которая занимается парсингом, называют — парсер. С этим вроде бы разобрались.
Перейдем к этапам парсинга.
И так, рассмотрим первый этап парсинга — Поиск данных.
Так как нужно парсить что-то полезное и интересное давайте попробуем спарсить информацию с сайта work.ua.
Для начала работы, установим 3 библиотеки Python.
pip install beautifulsoup4
Без цифры 4 вы ставите старый BS3, который работает только под Python(2.х).
pip install requests
pip install pandas
Теперь с помощью этих трех библиотек Python, можно проанализировать нашу веб-страницу.
Второй этап парсинга — Извлечение информации.
Попробуем получить структуру html-кода нашего сайта.
Давайте подключим наши новые библиотеки.
И сделаем наш первый get-запрос.
Статус 200 состояния HTTP — означает, что мы получили положительный ответ от сервера. Прекрасно, теперь получим код странички.
Получилось очень много, правда? Давайте попробуем получить названия вакансий на этой страничке. Для этого посмотрим в каком элементе html-кода хранится эта информация.
У нас есть тег h2 с классом «add-bottom-sm», внутри которого содержится тег a. Отлично, теперь получим title элемента a.
Хорошо, мы получили названия вакансий. Давайте спарсим теперь каждую ссылку на вакансию и ее описание. Описание находится в теге p с классом overflow. Ссылка находится все в том же элементе a.
Получаем такой код.
И последний этап парсинга — Сохранение данных.
Давайте соберем всю полученную информацию по страничке и запишем в удобный формат — csv.
После запуска появится файл test.csv — с результатами поиска.
«Кто владеет информацией, тот владеет миром» (Н. Ротшильд).
Парсим на Python: Pyparsing для новичков
Парсинг (синтаксический анализ) представляет собой процесс сопоставления последовательности слов или символов — так называемой формальной грамматике. Например, для строчки кода:
имеет место следующая грамматика: сначала идёт ключевое слово import, потом название модуля или цепочка имён модулей, разделённых точкой, потом ключевое слово as, а за ним — наше название импортируемому модулю.
В результате парсинга, например, может быть необходимо прийти к следующему выражению:
Данное выражение представляет собой словарь Python, который имеет два ключа: ‘import’ и ‘as’. Значением для ключа ‘import’ является список, в котором по порядку перечислены названия импортируемых модулей.
Для парсинга как правило используют регулярные выражения. Для этого имеется модуль Python под названием re (regular expression — регулярное выражение). Если вам не доводилось работать с регулярными выражениями, их вид может вас испугать. Например, для строки кода ‘import matplotlib.pyplot as plt’ оно будет иметь вид:
К счастью, есть удобный и гибкий инструмент для парсинга, который называется Pyparsing. Главное его достоинство — он делает код более читаемым, а также позволяет проводить дополнительную обработку анализируемого текста.
В данной статье мы установим Pyparsing и создадим на нём наш первый парсер.
Вначале установим Pyparsing. Если Вы работаете в Linux, в командной строке наберите:
В Windows Вам необходимо в командной строке, запущенной с правами администратора, предварительно зайти в каталог, где лежит файл pip.exe (например, C:\Python27\Scripts\), после чего выполнить:
Другой способ — это зайти на страницу проекта Pyparsing на SourceForge, скачать там инсталлятор для Windows и установить Pyparsing как обычную программу. Полную информацию о всевозможных способах установки Pyparsing можно получить на странице проекта.
Перейдём к парсингу. Пусть s — следующая строка:
В результате парсинга мы хотим получить словарь:
Сначала необходимо импортировать Pyparsing. Запустите например Python IDLE и введите:
Звёздочка * выше означает импорт всех имён из pyparsing. В результате это может нарушить рабочее пространство имён, что приведёт к ошибкам в работе программы. В нашем случае * используется временно, потому что мы пока не знаем, какие классы из Pyparsing мы будем использовать. После того, как мы напишем парсер, мы заменим * на названия использованных нами классов.
При использовании pyparsing, парсер вначале пишется для отдельных ключевых слов, символов, коротких фраз, а потом из отдельных частей получается парсер для всего текста.
Начнём с того, что у нас в строке есть название модуля. Формальная грамматика: в общем случае название модуля — это слово, состоящее из букв и символа нижнего подчёркивания. На pyparsing:
Word — это слово, alphas — буквы. Word(alphas + ‘_’) — слово, состоящее из букв и нижнего подчёркивания. module_name переводится как название модуля. Теперь читаем всё вместе: название модуля — это слово, состоящее из букв и символа нижнего подчёркивания. Таким образом, запись на Pyparsing очень близка к естественному языку.
Полное имя модуля — это название модуля, потом точка, потом название другого модуля, потом снова точка, потом название третьего модуля и так далее, пока по цепочке не дойдём до искомого модуля. Полное имя модуля может состоять из имени одного модуля и не иметь точек. На pyparsing:
ZeroOrMore дословно переводится как «ноль или более», а это означает, что содержимое в скобках может повторяться несколько раз или отсутствовать. В итоге читаем полностью вторую строчку парсера: полное имя модуля — это название модуля, после которого ноль и более раз идут точка и название модуля.
После полного названия модуля идёт необязательная часть ‘as plt’. Она представляет собой ключевое слово ‘as’, после которого идёт имя, которое мы сами дали импортируемому модулю. На pyparsing:
Optional дословно переводится как «необязательный», а это означает, что содержимое в скобках может быть, а может отсутствовать. В сумме получаем: «необязательное выражение, состоящее из слова ‘as’ и названия модуля.
Полная инструкция импорта состоит из ключевого слова import, после которого идёт полное имя модуля, потом необязательная конструкция ‘as plt’. На pyparsing:
В итоге имеем наш первый парсер:
Теперь надо распарсить строку s:
Вывод можно улучшить, преобразовав результат в список:
Теперь будем совершенствовать парсер. Прежде всего, мы бы не хотели видеть в выводе парсера слово import и точку между названиями модулей. Для подавления вывода используется Suppress(). С учётом этого наш парсер выглядит так:
Как видно из двух строчек выше, чтобы дать результату парсинга имя, нужно выражение парсера поставить в скобки, и после этого выражения в скобках дать название результата. Давайте посмотрим, что изменилось. Для этого выполним код:
Теперь мы можем отдельно извлекать цепочку модулей для импорта искомого и наше название для него. Осталось сделать так, чтобы парсер возвращал словарь. Для этого используется так называемое ParseAction — действие в процессе парсинга:
lambda — это анонимная функция в Python, t — аргумент этой функции. Потом идёт двоеточие и выражение словаря Python, в который мы подставляем нужные нам данные. Когда мы вызываем asList(), мы получаем список. Имя модуля после as всегда одно, и список t.import_as.asList() всегда будет содержать только одно значение. Поэтому мы берём единственный элемент списка (он имеет индекс ноль) и пишем asList()[0].
Проверим парсер. Выполним parse_module.parseString(s).asList() и получим:
Мы почти достигли цели. Так как у полученного списка единственный аргумент, добавим [0] в конце строки для парсинга текста: parse_module.parseString(s).asList()[0]
Мы получили то, что хотели.
Достигнув цели, необходимо вернуться к ‘from pyparsing import *’ и поменять звёздочку на те классы, которые нам пригодились:
В итоге наш код имеет следующий вид:
Мы рассмотрели совсем простой пример и лишь небольшую часть возможностей Pyparsing. За бортом — создание рекурсивных выражений, обработка таблиц, поиск по тексту с оптимизацией, резко ускоряющей сам поиск, и многое другое.
В заключение пару слов о себе. Я аспирант и ассистент МГТУ им. Баумана (кафедра МТ-1 „Металлорежущие станки“). Увлекаюсь Python, Linux, HTML, CSS и JS. Моё хобби — автоматизация инженерной деятельности и инженерных расчётов. Считаю, что могу быть полезным Хабру, делясь своими знаниями о работе в Pyparsing, Sage и некоторыми особенностями автоматизации инженерных расчётов. Также знаю среду SageMathCloud, которая является мощной альтернативой Wolfram Alpha. SageMathCloud заточена на проведение расчётов на Python в облаке. При этом Вам доступна консоль (Ubuntu под капотом), Sage, IPython и LaTeX. Есть возможность совместной работы. Помимо кода на Python SageMathCloud поддерживает html, css, js, coffescript, go, fortran, scilab и многое другое. В настоящее время среда бесплатна (достаточно стабильная бета-версия), потом будет будет работать по системе Freemium. На текущий момент времени эта среда не освещена на Хабре, и я хотел бы восполнить этот пробел.
Благодарю Дарью Фролову и Никиту Коновалова за помощь в редактировании статьи.
Веб-парсинг на Python
Веб-парсинг на Python – это гораздо больше, чем просто извлечение контента с помощью селекторов CSS. Благодаря приемам и идеям из этой статьи вы сможете более надежно, быстро и эффективно собирать данные.
Начинаем
Сперва установите все необходимые библиотеки, запустив pip install.
Чтобы не запрашивать HTML каждый раз, мы можем сохранить его в HTML-файле и уже оттуда загружать BeautifulSoup. Чисто для демонстрации давайте сделаем это вручную. Самый простой способ – это просмотреть исходный код страницы, скопировать и вставить его в файл. Важно посетить страницу без входа в систему, как это сделал бы поисковый робот.
Получение HTML-кода может показаться простой задачей, но это далеко не так. Вообще эта тема тянет на отдельную полноценную статью, так что здесь мы затронем ее лишь вскользь. Мы советуем использовать статический подход из примера ниже, поскольку многие сайты после нескольких запросов начнут перенаправлять вас на страницу входа. Некоторые покажут капчу, и в худшем случае ваш IP будет забанен.
После статической загрузки из файла мы сможем делать сколько угодно попыток запросов, не имея проблем проблем с сетью и не опасаясь блокировки.
Изучите сайт перед тем, как начать писать код
Прежде чем начать писать программу, нужно понять содержание и структуру страницы. Это можно сделать довольно просто при помощи браузера. Мы будем использовать DevTools Chrome, но в других браузерах есть аналогичные инструменты.
Например, мы можем открыть любую страницу продукта на Amazon. Беглый просмотр покажет нам название продукта, цену, доступность и многие другие поля. Перед копированием всех этих селекторов мы рекомендуем потратить пару минут на поиск скрытых входных данных, метаданных и сетевых запросов.
Пользуясь Chrome DevTools или аналогичными инструментами, проявляйте осторожность. Контент, который вы увидите, возможно, был изменен в результате работы JavaScript и сетевых запросов. Да, это утомительно, но иногда нужно исследовать исходный HTML, чтобы избежать запуска JavaScript.
Дисклеймер: мы не будем включать URL-запрос в фрагменты кода для каждого примера. Все они похожи на первый. И помните: сохраняйте HTML-файл локально, если собираетесь протестировать его несколько раз.
Скрытые инпуты
Скрытые инпуты позволяют разработчикам включать поля ввода, которые конечные пользователи не могут видеть или изменять. Многие формы используют их для включения внутренних идентификаторов или токенов безопасности.
В продуктах Amazon мы видим, что их довольно много. Некоторые из них будут доступны в других местах или форматах, но иногда они уникальны. В любом случае имена скрытых инпутов обычно более стабильны, чем имена классов.

Метаданные
Хотя некоторый контент отображается через пользовательский интерфейс, его может быть проще извлечь с помощью метаданных. Например, можно получить количество просмотров в числовом формате и дату публикации в формате ГГГГ-ММ-ДД для видео на YouTube. Да, эти данные можно увидеть на сайте, но их можно получить и с помощью всего пары строк кода. Несколько минут на написание кода точно окупятся.
XHR-запросы
Некоторые сайты загружают пустой шаблон и вставляют в него все данные через XHR-запросы. В таких случаях проверки исходного HTML будет недостаточно. Нам нужно исследовать сеть, в частности XHR-запросы.
Возьмем, к примеру, Auction. Заполните форму с любым городом и выполните поиск. Вы будете перенаправлены на страницу результатов, которая, пока выполняются запросы для введенного вами города, представляет собой страницу-каркас.
Это вынуждает нас использовать headless-браузер, который может выполнять JavaScript и перехватывать сетевые запросы. Иногда вы можете вызвать конечную точку XHR напрямую, но обычно для этого требуются файлы cookie или другие методы аутентификации. Или вас могут немедленно забанить, поскольку это не обычный путь пользователя. Будьте осторожны.
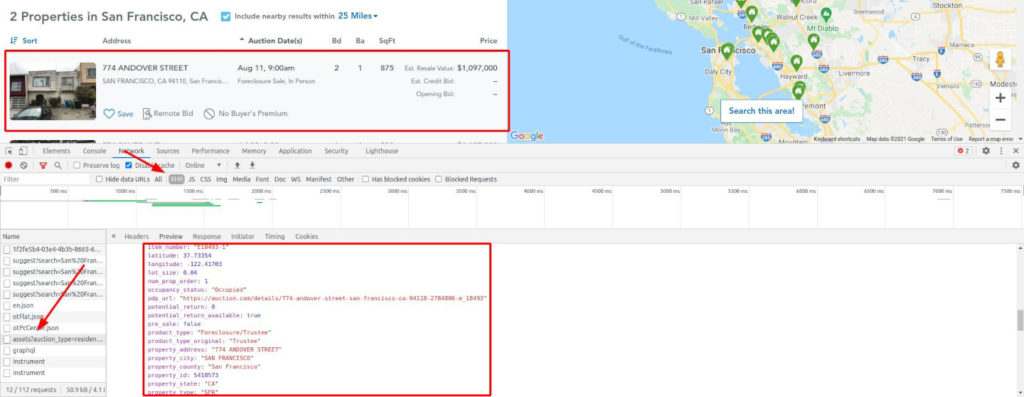
Мы наткнулись на золотую жилу! Взгляните еще раз на изображение.
Все возможные данные, уже очищенные и отформатированные, готовы к извлечению. А также геолокация, внутренние идентификаторы, цена в числовом виде без форматирования, год постройки и т. д.
Рецепты и хитрости для извлечения надежного контента
Уймите свой пыл ненадолго. Получить все с помощью селекторов CSS – это вариант, но есть еще множество других опций. Давайте рассмотрим больше инструментов и идей. Тогда вы сможете самостоятельно принимать решения, зная обо всех альтернативах.
Получение внутренних ссылок
Теперь мы начнем использовать BeautifulSoup для получения значимого контента. Эта библиотека позволяет нам получать контент по идентификаторам, классам, псевдоселекторам и т.д. Мы рассмотрим лишь небольшую часть ее возможностей.
В этом примере со страницы будут извлечены все внутренние ссылки. Упростим себе задачу и будем считать внутренними только ссылки, начинающиеся с косой черты. В более полном варианте следует проверить домен и поддомены.
Получив все эти ссылки, мы можем убрать дубликаты и поставить их в очередь для последующего парсинга. Поступая таким образом, мы могли бы создать поискового робота для всего сайта, а не только для одной страницы. Однако это уже совсем другая тема, ведь количество страниц для сканирования может увеличиваться, как снежный ком.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Будьте осторожны, выполняя это автоматически. Вы можете получить сотни ссылок за несколько секунд, что приведет к слишком большому количеству запросов к одному и тому же сайту. При неосторожном обращении можно нарваться на капчу или бан.
Извлечение ссылок на социальные сети и электронную почту
Другой распространенной задачей парсинга является извлечение ссылок на соцсети и email-адресов. Точного определения для «ссылок на соцсети» нет, поэтому мы будем получать их, основываясь на домене. Что касается email-адресов, то здесь есть два варианта: ссылки «mailto» и проверка всего текста.
Для примера мы будем использовать тестовый сайт.
Для начала получим все ссылки, как в предыдущем примере. Затем переберем их, проверяя, есть ли среди них домены соцсетей или «mailto». Если да, добавим такие URL-адреса в список и выведем конечный список на экран.
Эту задачу можно решить и с помощью регулярных выражений. Конечно, если вы не дружите с regexp, это немного сложнее. Основная идея в том, что мы ищем совпадение текста с заданным паттерном.
В нашем случае паттерн — некоторое количество символов (в основном, букв и цифр), за которым идет знак @, а затем опять символы (домен), точка и еще от двух до четырех символов (домен верхнего уровня. Этому паттерну будет соответствовать, например, test@example.com.
Обратите внимание, что этот паттерн несовершенен: он не учитывает составные домены верхнего уровня, такие как co.uk.
Наше регулярное выражение можно запустить для всего контента (HTML) или только для текста. Мы используем HTML, хотя при этом полученные email-адреса будут дублироваться (они есть и в тексте, и в href).
Автоматический парсинг таблиц
HTML-таблицы все еще широко применяются на сайтах. Мы можем воспользоваться этим, поскольку они обычно структурированы и хорошо отформатированы.
Используя в качестве примера список самых продаваемых альбомов из Википедии, мы извлечем все значения в датафрейм pandas. Это простой пример, но со всеми данными нужно обращаться так, как если бы они были получены из набора данных.
Другой способ – использовать pandas и напрямую импортировать HTML, как показано ниже. При таком подходе все будет сделано за нас: первая строка будет соответствовать заголовкам, а остальные будут вставлены как контент с правильным типом. read_html() возвращает массив, поэтому мы берем первый элемент, а затем удаляем столбец, у которого нет содержимого.
Попав в датафрейм, мы можем выполнить любую операцию. Например — упорядочить по продажам, поскольку pandas преобразовала некоторые столбцы в числа. Или вывести сумму продаж. Здесь это не очень полезно, но идея понятна.
Извлечение информации не из HTML, а из метаданных
Как было замечено ранее, есть способы получить важные данные, не полагаясь на визуальный контент. Давайте рассмотрим пример с «Ведьмаком» от Netflix. Мы попробуем получить список актеров. Легко, правда?
Что, если бы мы сказали вам, что актеров и актрис четырнадцать? Вы попытаетесь получить все имена? Не прокручивайте дальше, если хотите попробовать самостоятельно.
Помните: актеров больше, чем кажется на первый взгляд. Вы знаете троих – поищите их в исходном HTML. Честно говоря, внизу есть еще одно место, где показан весь состав, но постарайтесь его избегать.
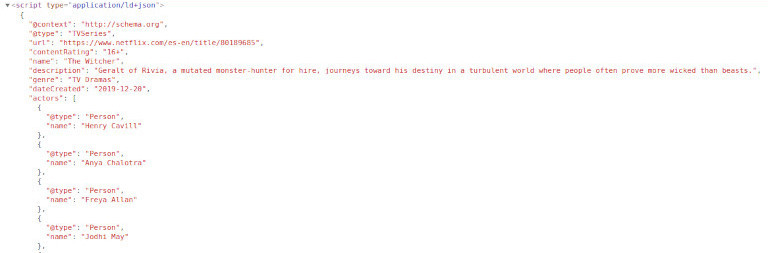
Netflix включает фрагмент Schema.org со списком актеров и актрис и многими другими данными. Как и в примере с YouTube, иногда удобнее использовать этот подход. Например, даты обычно отображаются в «машинном» формате, который более удобен при парсинге.
Разберем следующий пример, используя Instagram-профиль Билли Айлиш. После посещения нескольких страниц вы будете перенаправлены на страницу входа. Будьте осторожны при парсинге Instagram и используйте для тестирования локальный HTML-код.
Взгляните на исходный HTML. Заголовок и описание включают подписчиков, подписки и количество постов. Это может быть проблемой, поскольку они имеют строковый формат, но мы можем с этим справиться. Если мы хотим только эти данные, нам не понадобится headless-браузер. Отлично!
Скрытая информация о продукте в онлайн-магазине
Комбинируя некоторые из уже рассмотренных методов, мы хотим извлечь невидимую информацию о продукте. Наш первый пример — это eCommerce-магазин Shopify – Spigen.
Мы сможем извлечь требуемые данные наверняка: не из имени продукта и не из «хлебных крошек», поскольку мы не можем быть уверены в их надежности.

Другой пример со Shopify: nomz. Мы хотим извлечь количество оценок и среднее значение, доступные в HTML. Однако средняя оценка скрыта от просмотра с помощью CSS.
Здесь есть тег, поставленный исключительно для скринридеров, рядом с которым расположены средняя оценка и счетчик. Последние включают текст, что не является проблемой. Но мы можем добиться большего.
Это несложно, если вы изучите исходный код. Схема продукта будет первым, что вы увидите. Применяя то, чему вы научились на примере с Netflix, получите первый блок «ld + json», проанализируйте JSON, и весь контент будет доступен!
И последнее. Мы воспользуемся атрибутами данных, которые также распространены в eCommerce. Просматривая страницу с бейсбольными битами онлайн-магазина Marucci Sports, мы видим, что у каждого продукта есть несколько полезных точек данных. Цена в числовом формате, идентификатор, название продукта и категория. У нас есть все данные, которые нам могут понадобиться.
Отлично! Мы получили все данные с этой страницы. Теперь нужно проделать это со второй, а затем с третьей. Действуя постепенно, мы с большей вероятностью не нарвемся на бан.
Не забудьте преобразовать эти данные и сохранить их в CSV-файлах или в базе данных. Вложенные поля непросто экспортировать ни в один из этих форматов.
Итоги
Сегодня мы поговорили о веб-парсинге на Python. Нам бы хотелось, чтобы вы усвоили три урока: