От парсера афиши театра на Python до Telegram-бота. Часть 1

Я очень люблю оперу и балет, но не очень — отдавать большие деньги за билеты. Ежедневный просмотр сайта театра с тыканьем в каждую кнопку ужасно утомлял, а внезапно появлявшиеся билеты по 170 рублей на супер-составы бередили душу.
Чтобы автоматизировать это дело появился скриптик, который бежит по афише и собирает информацию о самых дешевых билетах на выбранный месяц. Запросы из серии «выдай список всех опер в марте на старой и новой сцене до 1000 рублей». Подруга обронила «а ты не Telegram-бота делаешь?». Такого в плане не было, но почему бы и нет. Бот родился, хоть и крутился на домашнем ноутбуке.
Потом Telegram заблокировали. Мысль запулить бота на рабочий сервер растаяла, да и интерес, чтобы довести функционал до ума, угас. Под катом рассказываю о судьбе сыщика дешевых билетов с самого начала и о том, что с ним сталось после года использования.
1. Зарождение идеи и постановка задачи

Хотелось за прогон скрипта получать ограниченный набор интересующих спектаклей. Главным критерием, как уже говорилось, была цена на билет.
API сайта и билетной системы в открытом доступе нет, поэтому было принято решение (не мудрствуя лукаво) пропарсить HTML-страницы, по тегам выдергивая нужное. Открываем главную, жмем F12 и изучаем структуру. Выглядело адекватно, так что дело быстро дошло до 1й реализации.
Понятно, что такой подход не масштабируется на другие сайты с афишами и посыпется, если текущую структуру решат сменить. Если у читателей есть идеи, как сделать стабильнее без API, пишите в комментарии.
2. Первая реализация. Минимальный функционал

Из html-страницы нам надо считать чистые URL-адреса, чтобы потом пройтись по ним и посмотреть ценник. Примерно так происходит сборка списка линков.
После изучения структуры страницы с покупкой билетов, помимо порога по цене, решила дать возможность пользователю также выбрать:
Вышло около 150 строк кода. В этом варианте, с описанными минимальными функциями скрипт живее всех живых и запускается регулярно с периодом в пару дней. Все остальные модификации либо были не допилены (шило утихло) и поэтому неактивны, либо не более выигрышные по функциям.
3. Расширение функционала
На втором этапе решила отслеживать изменение цен, храня ссылки на интересующие спектакли в отдельном файле (точнее URL на них). В первую очередь это актуально для балетов — сильно дёшево на них бывает редко и в общую бюджетную выдачу они не попадут. Но с 5 тысяч до 2х падение значимо, особенно если спектакль с звездным составом, и его хотелось отследить.
Чтобы это сделать надо сначала добавить URL-адреса для отслеживания, а потом периодически «перетряхивать» их и сравнивать новую цену со старой.
Обновление цен запускалось в начале главного скрипта, отдельно не выносилось. Может, не так изящно, как хотелось бы, но свою задачу решает. Так что вторым дополнительным функционалом стал мониторинг снижения цен на интересующие спектакли.
Дальше рождался Telegram-бот, не так легко-быстро-задорно, но все же родился. Чтобы не собирать все в одну кучу, история о нем (а также о нереализованных идеях и попытке проделать такое с сайтом Большого театра) будет во второй части статьи.
ИТОГ: затея удалась, пользователь(я) доволен. Потребовалась пара выходных разобраться, как взаимодействовать с html-страницами. Благо Python язык-почти-для-всего и готовые модули помогают вбить гвоздь не задумываясь о физике работы молотка.
Надеюсь, кейс будет полезен хабравчанам и, возможно, сработает как волшебный пендель, чтобы сделать наконец давно сидящую в голове хотелку.
Блог об аналитике, визуализации данных, data science и BI
Дашборд первых 8 месяцев жизни малыша
Анализ рынка вакансий аналитики и BI: дашборд в Tableau
Анализ альбомов Земфиры: дашборд в Tableau
Гайд по современным BI-системам
Сбор информации о подписчиках Telegram-канала
На 2021 год боты в Telegram так и не имеют метода, позволяющего получать информацию о подписчиках канала. Тем не менее, существует достаточно сложное в освоении Telegram API и построенная на нём библиотека Telethon. Сегодня мы посмотрим, как при помощи библиотеки выгрузить информацию о подписчиках своего канала.
Создание приложения
Для начала необходимо создать приложение, через которое будут отправляться запросы к API. Перейдите на https://my.telegram.org и авторизуйтесь в Telegram-аккаунте:

После успешной авторизации перейдите на страницу API development tools:

Заполните все поля и жмите на создание приложения:

Из полученной конфигурации нам необходим app api_id и app api_hash:

Запрос к API
Импортируем telethon — он поможет сформировать запрос, и pandas — полученный ответ мы запишем в DataFrame.
Вводим api_id, api_hash, наш номер телефона и ссылку на канал, информацию о подписчиках которого хотим получить. Доступ к информации о подписчиках есть только у администраторов канала.
Создаём новую сессию — вместо session_name можно подставить любое другое название. Методы в библиотеке работают асинхронно, поэтому ответа от них требуется ожидать:
Собираем все каналы текущего пользователя. Из ссылки забираем часть с именем канала и вытаскиваем из словаря нужный:
Подписчиков, доступ к которым не ограничен приватностью, можно получить методом get_participants. С 20 июля 2018 года Telegram установил ограничение в 200 подписчиков для вызова метода, и установка параметра aggressive на True поможет получить всех подписчиков за раз.
Из полученных библиотечных структур извлекаем информацию о пользователях — их имена и телефоны:
Из четырёх списков собираем DataFrame и пишем его в csv-таблицу:
Результат работы — такая таблица:

Для запуска в Jupyter Notebook описанный ниже код можно просто вставить в ячейку, но при запуске из Python-файла будет такая ошибка:
Устранить проблему можно, записав весь код в асинхронную функцию. Целиком выглядеть код будет так:
От парсера афиши театра на Python до Telegram-бота. Часть 2

Продолжаем историю о разработке Telegram-бота для поиска билетов — HappyTicketsBot, начало можно почитать в первой части.
Во второй расскажу о самом боте, поделюсь кодом, а также идеями, которым скорее всего не суждено стать реальностью. Большая часть функционала к моменту создания бота уже была написана в формате скрипта, поэтому основной задачей стояло наладить интерфейс взаимодействия с пользователем через Telegram-messenger. Получилось не так болтологически, как в 1й части, так что attention — много кода.
Спойлер: HappyTicketsBot так и не улетел крутиться на иностранный сервер, он локальный и русский, но однажды запуск (верю) состоится =)
UPDATE: После расшаривания бота среди театральной публики о нем написали в СМИ. Резко нахлынул поток пользователей. Через пару дней игры «подними сразу, как упало» бот и на сервер улетел, и пережил ряд улучшений. Я довольна=)
1. Старт с нуля
Дольше всего заняло освоение идеологии декораторов, про них читала в этой статье. Там в двух частях и очень понятно.
2. Сценарий взаимодействия бота с пользователем. Базовый поиск
Как уже упомянуто в предисловии и 1-й части статьи, почти весь код парсинга был готов. Оставалось изменить способ задания параметров поиска. Исходя из этого и был построен сценарий поведения бота. Команды, доступные для пользователя, ограничиваются следующим набором:
Для того, чтобы запоминать состояние пользователя, они сохраняются в базе. Для работы с ней используются модули Vedis (конфигуратор баз данных типа ключ-значение, почитать документацию) и Enum (работа с перечислениями, подробнее 1, 2).
В отдельном файле-конфигурации Myconfig.py задаем параметры бота (в том числе полученный от Telegram уникальный token) и перечисляем статусы, в которых может находиться пользователь. Их вышло немного.
В итоге получаем незамысловатую цепочку перехода статусов из одного в другой.

Для хранения используем БД Vedis. Инициализация пользователя, приславшего сообщение, всегда осуществляется через message.chat.id.
Ниже пример хендлера, который активизируется по команде /find. Как можно заметить, в этом примере нет никакого ввода данных — есть только смена статуса на «S_ENTER_MONTH». Увидев сообщение о вводе номера, пользователь его вводит и отправляет сообщение. При получении сообщения со статусом S_ENTER_MONTH, инициируется следующий этап. В случае ошибок ввода статус не меняется.
Если бот получает сообщение от пользователя со статусом S_ENTER_MONTH, то запускается приведенный ниже хендлер. Идеалогически также происходит на других этапах сценария базового поиска.
Помимо стандартного поиска, есть возможность сохранять интересные спектакли.
3. Отслеживание изменения цен
Пользователь может добавить в список интересов URL, чтобы получить оповещение, когда цена снизится. Мы помним, что у нас остался незадейстованный в базовом поиске статус — S_ENTER_URL. В
В результате, по команде /checkURL пользователь может получить такой результат (сейчас понимаю, что надо бы название спектакля тоже выводить, но это вещи из серии «руки не дошли»).
Окей, ладно. Искать можем, отслеживать можем. Пара друзей начали пользоваться ботом, захотелось узнать кто они и что же они ищут. Эту информацию хорошо писать в логи.
4. Пишем активность и ошибки в логи
В этом нам поможет модуль Logging. Запись информации происходит только на этапе завершения базового поиска, в хендлере, в котором статус пользователя переходит из S_ENTER_PLACE в S_START. Запись ошибок, в свою очередь, происходит при их возникновении.
Много сказать о том, как модуль работает, я не смогу, поэтому лучше обратиться к информации вовне.
Из-за разрыва соединения бот периодически падал, поэтому ошибка интернет соединения отлавливалась и бот перезапускался автоматом через 10 секунд. Но это не всегда спасало, поэтому держала запущенным TeamViewer, чтобы при необходимости поднять.
5. Нереализованное
У нас получился бот, заменяющий функционал скрипта, но позволяющий получать информацию в удобной форме внутри мессенджера. Основные мои потребности он закрыл.
Разборки с модулями и написание стройных хендлеров длились около месяца в режиме работы по выходным и иногда по вечерам. В конце этого периода интерес уже стал угасать и функционал застрял на начальной точке. Пробиться через принципы работы на webhook-ах с наскока не удалось, а потом и Telegram заблокировали. До этого был план запулить крутиться back-end на рабочий сервер, но… vpn ради этого там ставить не будут =)
Вот что осталось в планах, некоторые из которых может и реализуются однажды томным летним/зимним вечером:
Лень оказалась двигателем прогресса и она же его остановила. До выгрузки бота на сторонний сервер дело не дошло, все-таки это требует более широких компетенций и знаний в области Web. Проект выдался интересным и позволил освоить чуть лучше Python, увидеть еще одну его грань (помимо привычного Machine learning-а), а также подарил много чудесных вечеров в театре по бросовой цене. Спасибо ему за это, поставленные задачи он закрывал на ура.
Как ни старалась, в статье всё равно получилось много кода и мало текста. Буду рада пояснить непонятное или мало описанное в комментариях =)
Урок 4. Пишем Telegram-бота для получения результатов парсинга
Игорь Parsemachine,
опубликовано 23 ноября в 18:09
Продолжаем серию уроков по разработке парсера на Python. Сегодня мы создадим небольшого Telegram-бота для получения файлов с результатом последнего парсинга. Предположим, ваш парсер запускается раз в сутки или с другой периодичностью, и вы хотите в любой момент получить актуальную версию выгрузки.
В предыдущем уроке мы отправляли по завершении парсинга файлы с результатом в чат Telegram.
Шаг 1. Подготовка
Удалим из скрипта предыдущих уроков отправку результата в Telegram и переименуем скрипт в main.py. Создадим еще один файл bot.py, в котором будем писать код нашего бота.
Установим библиотеку python-telegram-bot:
Как и в предыдущем уроке токен получим у @BotFather. 
Объявим глобальную переменную TELEGRAM_TOKEN:
Шаг 2. Структура бота
Вообще, есть два варианта получения обновлений от Telegram:
1. Периодическое опрашивание Telegram на предмет появления запросов от пользователей.
2. Вебхуки – указываем Telegram API endpoint, по которому нужно сообщить о появлении обновлений.
Сегодня мы используем первый вариант.
У нас будет две кнопки, которые отображаются после отправки команды /start :
1. «Получить JSON» для получения последней актуальной выгрузки в формате JSON.
2. «Получить XLSX» – аналогично для Excel-таблицы.
Шаг 3. Программирование
Пойдем по порядку согласно структуре. Создади объект Updater, указав наш токен. Передадим параметр use_context=True для обратной совместимости, что рекомендуется библиотекой:
Теперь напишем обработчик команды /start – мы будем отправлять текст пользователю и две кнопки для получения файлов JSON и XLSX соответственно.
Напишем обработчики кнопок – получаем нужный файл и отправляем его в диалог вместе с датой и временем последней его модификации (используя средства операционной системы, библиотека os ):
Зарегистрируем наши обработчики:
Опрашиваем Telegram на наличие обновлений:
Запускаем бот, пишем /start и видим две кнопки. Нажимаем любую из них, получаем файлы с результатом парсинга! К каждому файлу подписано время его последнего изменения.
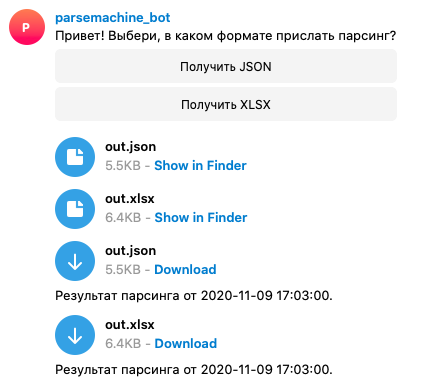
На этом все, спасибо за внимание!
Если у вас возникли какие-то вопросы, можете задать их в комментариях к этой статье или под видео на YouTube. Предлагайте темы следующих уроков.
Спасибо за внимание!
0 комментариев
Для того, чтобы оставить комментарий, вам нужно быть зарегистрированным пользователем.
Введите свой e-mail для получения ссылки на регистрацию аккаунта ниже.
Пишем простой граббер для Telegram чатов на Python

Leo Matyushkin

В данном туториале мы научимся собирать данные и сообщения участников чатов и каналов Telegram, а также сохранять эту информацию в виде JSON-файлов, которые далее легко анализировать или экспортировать в базы данных.
Для указанных задач будет использоваться Python не ниже версии 3.5, а также высокоуровневая библиотека для работы с Telegram API – Telethon. Установить библиотеку можно с помощью менеджера пакетов pip :
Регистрируем в Telegram новое приложение
Вводим пришедший в Telegram численно-буквенный код и попадаем на страницу регистрации нового приложения. Заполняем форму, достаточно первых двух граф:
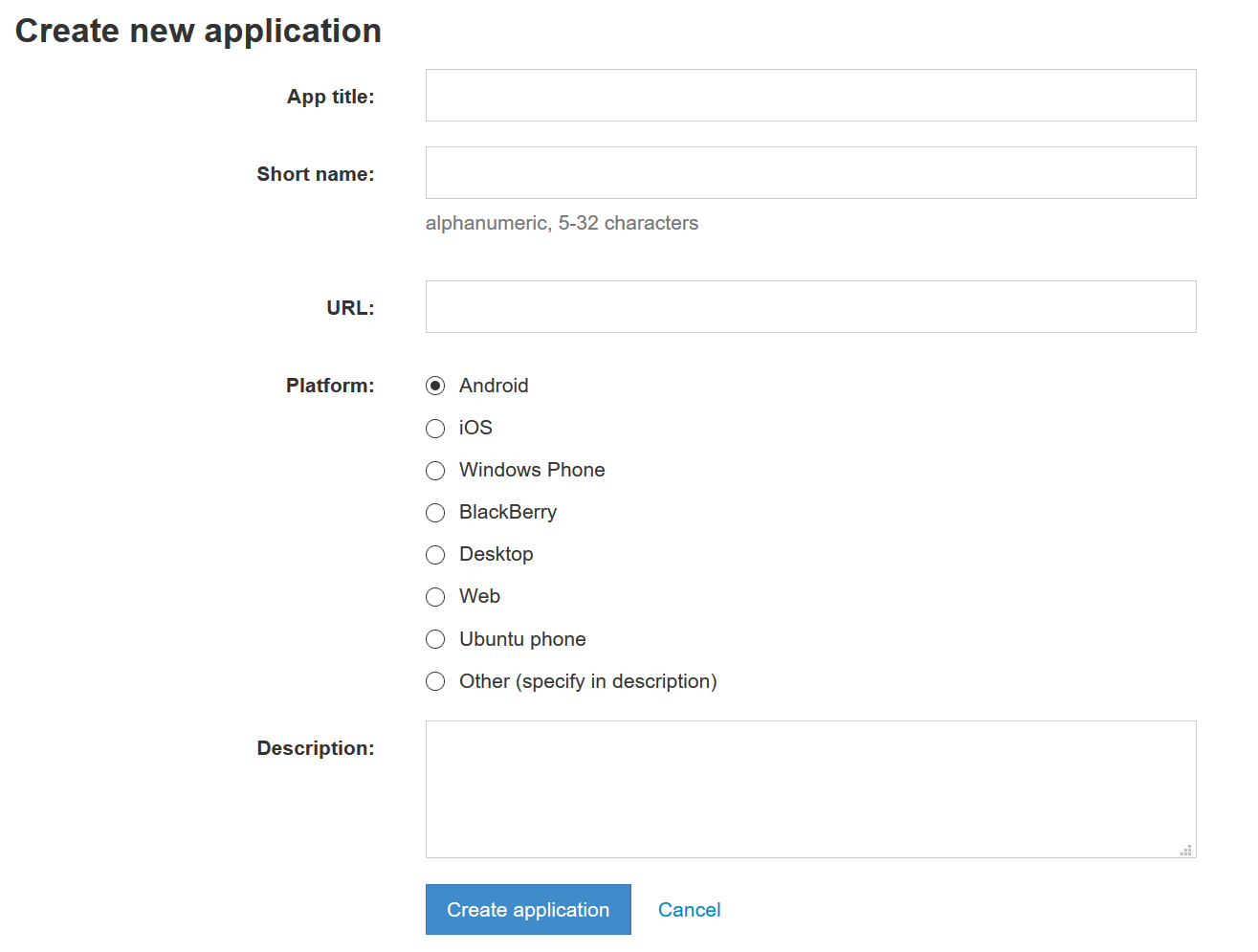
В результате попадаем на страницу конфигурации приложения. Находим оба параметра, а также доступные MTProto-сервера и открытые (публичные) ключи.
Избегая проблем с безопасностью, сохраняем учетные данные в отдельном файле config.ini следующей структуры:
Создаем клиент Telegram
Начнем с импорта библиотек.
Встроенные модули configparser и json применяем соответственно для чтения параметров и вывода данных. Из библиотеки Telethon импортируем класс клиента Telegram и класс исключений. Внутренний модуль connection необходим при использовании прокси-сервера. Остальные элементы модуля telethon.tl используются для запросов необходимых нам списков (участников канала/чата и их сообщений).
Теперь считаем учетные данные из config.ini :
Создадим объект клиента Telegram API:
При первом запуске платформа запросит номер телефона, и вслед – код подтверждения. Так же, как если бы вы входили в учетную запись в приложении или браузере.
Для сбора, обработки и сохранения информации мы создадим две функции:
Касательно написания вызова функций стоит оговориться, что Telethon является асинхронной библиотекой. Поэтому в коде используются операторы async и await. В связи с этим функция main полностью будет выглядеть так:
Заметим, что из-за асинхронности Telethon может некорректно работать в средах, использующих те же подходы (Anaconda, Spyder, Jupyter).
Собираем данные об участниках
Telegram не выводит все запрашиваемые данные за один раз, а выдает их в пакетном режиме, по 100 записей за каждый запрос.
Самый простой способ сохранить собранные данные в структурированном виде – воспользоваться форматом JSON. Базы данных, такие как MySQL, MongoDB и т. д., стоит рассматривать лишь для очень популярных каналов и большого количества сохраняемой информации. Либо если вы планируете такое расширение в будущем.
В JSON-файле можно хранить и всю информацию о каждом пользователе, но обычно достаточно лишь нескольких параметров. Покажем на примере, как ограничиться набором определенных данных:
Собираем сообщения
Ситуация со сбором сообщений идентична сбору сведений о пользователях. Отличия сводятся к трем пунктам:
Таким образом, с помощью Python и Telethon мы написали скрипт, собирающий и сохраняющий данные и реплики участников сообществ Telegram.