Как написать, упаковать и распространять библиотеку на Python
В этом уроке вы узнаете все, что вам нужно знать о написании, упаковке и распространении собственных пакетов.
Как написать библиотеку Python
Библиотека Python представляет собой согласованный набор модулей Python, который организован как пакет Python. В общем, это означает, что все модули живут под одним и тем же каталогом и этот каталог находится на пути поиска Python.
Давайте быстро напишем небольшой пакет Python 3 и проиллюстрируем все эти понятия.
Пакет Pathology
Во многих случаях сценарий может быть установлен в любом месте, поэтому вы не можете использовать абсолютные пути, а рабочий каталог может быть установлен на любое значение, поэтому вы не можете использовать относительный путь. Если вы хотите получить доступ к файлу в подкаталоге или родительском каталоге, вы должны иметь возможность определить текущий каталог сценариев.
Вот как вы это делаете в Python:
Чтобы получить доступ к файлу с именем ‘file.txt’ в подкаталоге данных в каталоге текущего скрипта, вы можете использовать следующий код:print(open(str(script_dir/’data/file.txt’).read())
С пакетом pathology у вас есть встроенный метод script_dir, и вы используете его следующим образом:
Да, это глоток свежего воздуха. Пакет патологии очень прост. Он выводит свой собственный класс Path из Pathlib Path и добавляет статический script_dir(), который всегда возвращает путь вызывающего скрипта.
Из-за кросс-платформенной реализации pathlib.Path вы можете получить непосредственно от него и должны быть получены из определенного подкласса (PosixPath или WindowsPath). Разрешение dir-файла сценария использует модуль проверки, чтобы найти вызывающего, а затем его атрибут имени файла.
Тестирование пакета патологии
Всякий раз, когда вы пишете нечто более сложное, вы должны его протестировать. Модуль патологии не является исключением. Вот тесты с использованием стандартной модульной тестовой платформы:
Путь Python
Обратите внимание, что первая пустая строка вывода представляет текущий каталог, поэтому вы можете импортировать модули из текущего рабочего каталога, что бы это ни было. Вы можете напрямую добавлять или удалять каталоги в / из sys.path.
Вы также можете определить переменную среды PYTHONPATH, и есть несколько других способов ее контролировать. Стандартные site-packages включены по умолчанию, и именно там устанавливаются пакеты, которые вы устанавливаете с помощью pip.
Как упаковать библиотеку Python
Теперь, когда у нас есть наш код и тесты, давайте упакуем все это в нужную библиотеку. Python обеспечивает простой способ через модуль настройки. Вы создаете файл setup.py в корневом каталоге вашего пакета. Затем, чтобы создать исходный дистрибутив, вы запустите: python setup.py sdist
Чтобы создать двоичный дистрибутив, называемый колесом, вы запускаете: python setup.py bdist_wheel
Вот файл setup.py пакета патологии:
Давайте построим дистрибутив источника:
Предупреждение связано с тем, что я использовал нестандартный файл README.md. Это безопасно поэтому игнорируем. Результатом является файл tar-gzipped в каталоге dist:
И вот двоичное распределение:
Пакет патологии содержит только чистые модули Python, поэтому можно создать универсальный пакет. Если ваш пакет включает расширения C, вам нужно будет создать отдельное колесо для каждой платформы:
Для более глубокого погружения в тему упаковки библиотек Python ознакомьтесь, как писать свои собственные пакеты Python.
Как раздавать пакет Python
Python имеет центральный репозиторий пакетов, называемый PyPI (индекс пакетов Python). Когда вы устанавливаете пакет Python с помощью pip, он загружает пакет из PyPI (если вы не укажете другой репозиторий). Чтобы распространять наш пакет патологии, нам нужно загрузить его в PyPI и предоставить некоторые дополнительные метаданные, которые требуется PyPI. Шаги:
Создайте аккаунт
Вы можете создать учетную запись на веб-сайте PyPI. Затем создайте файл .pypirc в своем домашнем каталоге:
В целях тестирования вы можете добавить «pypitest» индексный сервер в ваш .pypirc файл:
Зарегистрируйте свой пакет
Если это первый выпуск вашего пакета, вам необходимо зарегистрировать его с помощью PyPI. Используйте команду register setup.py. Она попросит вас ввести пароль. Обратите внимание, что я указываю его на тестовый репозиторий:
Загрузите свой пакет
Для более глубокого погружения в тему распространения ваших пакетов ознакомьтесь с разделом «Пакеты Python».
Заключение
В этом уроке мы прошли полноценный процесс написания библиотеки Python, ее упаковки и распространения через PyPI. На этом этапе у вас должны быть все инструменты для написания и обмена вашими библиотеками с остальным миром.
Кроме того, не стесняйтесь посмотреть, что у нас есть для продажи и для изучения на рынке, и, пожалуйста, задавайте любые вопросы и предоставляйте свою ценную обратную связь, используя приведенный ниже канал.
Как создать свою собственную библиотеку AutoML в Python с нуля
Библиотеки и сервисы AutoML вошли в мир машинного обучения. Для дата-сайентиста это очень полезные инструменты, но иногда они должны быть адаптированы к потребностям бизнес-контекста, в котором работает дата-сайентист. Вот почему вам нужно создать свою собственную библиотеку AutoML. В преддверии старта нового потока курса «Машинное обучение» мы делимся материалом, в котором описано, как это сделать на Python.

Что должна делать библиотека AutoML?
Библиотека AutoML — это любая часть программного обеспечения, автоматизирующая некоторые самые сложные (и скучные) части конвейера машинного обучения. Применение AutoML ускорит процесс машинного обучения и поможет избежать ошибок. Библиотека AutoML должна автоматизировать такие действия:
Подход
Здесь я расскажу о конвейере классификации с такой сеткой настроек:
Мы перевели нашу задачу в задачу гиперпараметрической оптимизации, которую мы можем решить. Пространство гиперпараметров конвейера очень велико, поэтому воспользуемся случайным поиском, чтобы найти лучший набор значений таких гиперпараметров. Наш объект будет принимать фрейм данных Pandas на вход для обучения, а метод “обучения” выполнит необходимую оптимизацию, чтобы найти лучшую модель и лучшие настройки для фазы предварительной обработки. Посмотрим на код.
Мы создадим объект под названием MyAutoMLClassifier и будем обучать и тестировать его на наборе данных о раке молочной железы. Вы можете найти весь код в моём репозитории на GitHub.
Импортируем библиотеки:
Теперь мы можем приступить к определению класса MyAutoMLClassifier. Его конструктор будет принимать скоринговую функцию, которая будет использоваться в k-кратной кросс-валидации и в количестве итераций случайного поиска. В этом примере их значениями по умолчанию будут «balanced accuracy» — сбалансированная точность и 50.
Теперь мы можем начать писать метод «обучения» — самый важный метод. Во-первых, мы должны определить различные значения категориальных переменных, чтобы применить унитарное кодирование.
Теперь для категориальных переменных нужно определить конвейер предварительной обработки. Этот конвейер заменит пустые значения, используя наиболее часто встречающееся значение, и унитарно закодирует новые значения. В то же время мы собираемся определить конвейер для числовых переменных, который будет очищен в соответствии с определяемым позже и масштабирован в соответствии с преобразователем масштаба, который мы установим в части случайного поиска. Всё это, наконец, включается в настройки ColumnTransformer, который выполнит всю предварительную обработку.
Наконец, мы должны определить конвейер ML, который строится на этапе предварительной обработки, подбора признаков и самой модели. Сейчас мы можем установить модель в LogisticRegression, она будет изменена позже случайным поиском.
Затем можно вычислить количество признаков (это понадобится в части подбора признаков) и создать пустой список, содержащий оптимизационную сетку в соответствии с синтаксисом, необходимым RandomSearchCV.
Теперь мы можем начать добавлять модели в нашу сетку оптимизации. Начнём с логистической регрессии:
Как мы видим, создаётся объект, который изменит масштабирование между RobustScaler, StandardScaler и MinMaxscaler. Затем будет изменена стратегия очистки между средним и медианным значениями и выбраны объекты от 1 до общего числа объектов с шагом 5. Наконец, сама модель установлена. Случайный поиск будет проверять случайные комбинации этой сетки, в поиске той, которая максимизирует показатели производительности при кросс-валидации.
Теперь мы можем добавить другие модели с их собственными гиперпараметрами и нуждами в смысле предварительной обработки. Например, деревья не требуют никакого масштабирования, но SVM — да. Мы можем добавить столько моделей, сколько захотим, оптимизируя их гиперпараметры в одной сетке.
Итак, мы ищем наилучшее сочетание стратегии очистки, процедуры масштабирования, набора признаков, значений модели и гиперпараметров — всё в одной и той же процедуре поиска. Это ядро любой библиотеки AutoML и может быть расширено по нашему желанию.
Теперь у нас есть завершённая сетка оптимизации, так что мы можем, наконец, применить случайный поиск, чтобы найти лучшие параметры конвейера и сохранить результаты в свойствах нашего объекта. Случайный поиск будет применять 5-кратную кросс-валидацию с помощью функции скоринга и количества итераций, выбранных в конструкторе класса.
Метод обучения завершён. Теперь мы можем добавить методы «predic» и «predict_proba», как и любую другую модель sklearn, и наш MyAutoMLClassifier закончен.
Сейчас можно импортировать набор данных, разделить его на наборы обучения и тестирования, создать экземпляр MyAutoMLClassifier и обучить его.
С помощью всего лишь одной строки кода мы делаем все сложные вещи с помощью AutoML. После обучения модели мы можем рассчитать сбалансированную точность в тестовом наборе и посмотреть, какие параметры модели и предварительной обработки были выбраны:
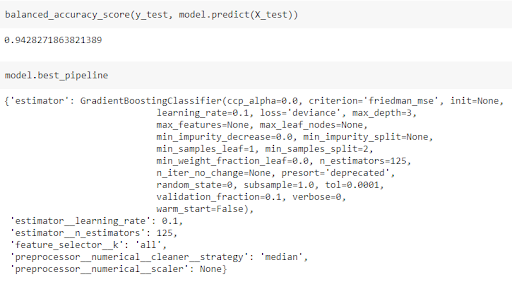
Мы используем классификатор дерева градиентного бустинга со всеми функциями и численную стратегию очистки, основанную на медианном значении. Скорость обучения модели равна 0,1, а число обучающихся на данных объектов — 125. Это результат применения AutoML.
Заключение
Библиотеки AutoML — это очень полезные инструменты для дата-сайентита, и они действительно помогают сэкономить много времени. В соответствии с бизнес-контекстом, над которым мы работаем, нам может потребоваться работать только с определёнными моделями или процедурами очистки, поэтому нам нужна своя версия AutoML. Пример в этой статье легко адаптируется к задаче регрессии и может быть интегрирован с другими моделями, такими как нейронные сети.
Как создать свой первый open source проект на Python (17 шагов)
Каждый разработчик ПО должен знать как создать библиотеку с нуля. В процессе работы Вы можете многому научиться. Только не забудьте запастись временем и терпением.
Может показаться, что создать библиотеку с открытым исходным кодом сложно, но Вам не нужно быть потрепанным жизнью ветераном своего дела, чтобы разобраться в коде. Также как Вам не нужна мудреная идея продукта. Но точно понадобятся настойчивость и время. Надеюсь, что данное руководство поможет Вам создать первый проект с минимальной затратой и первого, и второго.
В этой статье мы пошагово разберем процесс создания базовой библиотеки на Python. Не забудьте заменить в приведенном ниже коде my_package, my_file и т.п. нужными вам именами.
Шаг 1: Составьте план
Мы планируем создать простую библиотеку для использования в Python. Данная библиотека позволит пользователю легко конвертировать блокнот Jupyter в HTML-файл или Python-скрипт.
Первая итерация нашей библиотеки позволит вызвать функцию, которая выведет определенное сообщение.
Теперь, когда мы уже знаем, что хотим делать, нужно придумать название для библиотеки.
Шаг 2: Дайте имя библиотеке
Придумывать имена сложно. Они должны быть короткими, уникальными и запоминающимися. Также они должны быть написаны строчными буквами, без прочерков и прочих знаков препинания. Подчеркивание не рекомендуется. В процессе создания библиотеки убедитесь, что придуманное Вами имя доступно на GitHub, Google и PyPi.
Если Вы надеетесь и верите, что однажды Ваша библиотека получит 10000 звезд GitHub, то стоит проверить, доступно ли данное имя в социальных сетях. В данном примере я назову свою библиотеку notebookc, потому что это имя доступное, короткое и более-менее описывает суть моей задумки.
Шаг 3. Настройте среду
Убедитесь, что у вас установлены и настроены Python 3.7, GitHub и Homebrew. Если вам нужно что-то из этого, вот подробности:
Python
Скачайте Python 3.7 здесь и установите его.
GitHub
Если у вас нет учетной записи GitHub, перейдите по этой ссылке и оформите бесплатную подписку. Посмотрите, как установить и настроить Git здесь. Вам потребуется утилита командной строки. Перейдите по ссылкам, скачайте и установите все, что Вам понадобится, придумайте юзернейм и укажите электронную почту.
Homebrew
Homebrew — менеджер библиотек для Mac. Инструкции по установке найдете здесь.
Начиная с Python 3.6 рекомендуется использовать venv для создания виртуальной среды для разработки библиотек. Существует множество способов управления виртуальными средами с помощью Python и все они со временем изменяются. Можете ознакомиться с обсуждением здесь, но, как говорится, доверяй, но проверяй.
Начиная с версии Python 3.3 venv входит в систему по умолчанию. Обратите внимание, что venv устанавливает pip и setuptools начиная с Python 3.4.
Создайте виртуальную среду Python 3.7 с помощью следующей команды:
Замените my_env вашим именем. Активируйте среду таким образом:
Теперь вы должны наблюдать (my_env) (или имя, которое вы выбрали для вашей виртуальной среды) в крайнем левом углу терминала.
Теперь давайте настроим GitHub.
Шаг 4: Создайте организацию в GitHub
GitHub — лидер на рынке реестров контроля версий. Еще две популярные опции — GitLab и Bitbucket. В данном гиде мы будем использовать именно GitHub.
Вам придется часто обращаться к Git и GitHub, поэтому если Вы не знакомы с системой, то можете обратиться к моей статье.
Создайте новую организацию в GitHub. Следуйте инструкциям. Я назвал свою организацию notebooktoall. Вы можете создать репозиторий под своей личной учетной записью, но одна из целей работы — научиться создавать проект с открытым исходным кодом для более широкого сообщества.

Шаг 5: Настройте GitHub Repo
Создайте новый репозиторий. Я назвал свой notebookc.
Рекомендую выбрать лицензию в списке Выбрать лицензию. Она определяет, что могут делать пользователи Вашего репозитория. Одни лицензии позволяют больше других. Если Вы ничего не выбираете, то автоматически начинают действовать стандартные законы об авторских правах. Узнайте больше о лицензиях здесь.
Для этого проекта я выбрал третью версию Открытого лицензионного соглашения GNU, потому что она популярная, проверенная и “гарантирует пользователям свободу использования, изучения, обмена и изменения программного обеспечения” — источник.
Шаг 6: Клонируйте и добавьте директории
Выберите, куда Вы хотите клонировать Ваш репозиторий или выполните следующую функцию:
git clone https://github.com/notebooktoall/notebookc.git
Подставьте свою организацию и репозиторий.
Ваши исходные папки и файлы должны выглядеть так:
.git
.gitignore
LICENSE
README.rst
Создайте вложенную папку для основных файлов проекта. Я советую назвать ее так же, как и вашу библиотеку. Убедитесь, что в имени нет пробелов.
Создайте файл с именем __init__.py в основной вложенной папке. Этот файл пока останется пустым. Он необходим для импорта файлов.
Содержимое моей директории notebookc выглядит следующим образом:
.git
.gitignore
LICENSE
README.rst
notebookc/__init__.py
notebookc/notebookc.py
Шаг 7: Скачайте и установите requirements_dev.txt
На верхнем уровне директории проекта создайте файл requirements_dev.txt. Часто этот файл называют requirements.txt. Назвав его requirements_dev.txt, Вы показываете, что эти библиотеки могут устанавливаться только разработчиками проекта.
В файле укажите, что должны быть установлены pip и wheel.
Обратите внимание, что мы указываем точные версии библиотек с двойными знаками равенства и полными номерами версии.
Закрепите версии вашей библиотеку в requirements_dev.txt
Соавтор, который разветвляет репозиторий проекта и устанавливает закрепленные библиотеки require_dev.txt с помощью pip, будет иметь те же версии библиотеки, что и Вы. Вы знаете, что эта версия будет работать у них. Кроме того, Read The Docs будет использовать этот файл для установки библиотек при сборке документации.
В вашей активированной виртуальной среде установите библиотеку в файл needs_dev.txt с помощью следующей команды:
Настоятельно рекомендую обновлять эти библиотеки по мере выхода новых версий. На данный момент установите любые последние версии, доступные на PyPi.
В следующей статье расскажу, как установить инструмент, облегчающий этот процесс. Подпишитесь, чтобы не пропустить.
Шаг 8: Поработайте с кодом
В целях демонстрации давайте создадим базовую функцию. Свою собственную крутую функцию сможете создать позже.
Вбейте следующее в Ваш основной файл (для меня это notebookc/notebookc/notebookc.py):
Вот наша функция во всей красе.
Строки документа начинаются и заканчиваются тремя последовательными двойными кавычками. Они будут использованы в следующей статье для автоматического создания документации.
Сохраните изменения. Если хотите освежить память о работе с Git, то можете заглянуть в эту статью.
Шаг 9: Создайте setup.py
Файл setup.py — это скрипт сборки для вашей библиотеки. Функция setup из Setuptools создаст библиотеку для загрузки в PyPI. Setuptools содержит информацию о вашей библиотеке, номере версии и о том, какие другие библиотеки требуются для пользователей.
Вот мой пример файла setup.py:
Обратите внимание, что long_description установлен на содержимое файла README.md. Список требований (requirements), указанный в setuptools.setup.install_requires, включает в себя все необходимые зависимости для работы вашей библиотеки.
В отличие от списка библиотек, требуемых для разработки в файле require_dev.txt, этот список должен быть максимально разрешающим. Узнайте почему здесь.
Ограничьте список install_requires только тем, что Вам надо — Вам не нужно, чтобы пользователи устанавливали лишние библиотеки. Обратите внимание, что необходимо только перечислить те библиотеки, которые не являются частью стандартной библиотеки Python. У Вашего пользователя и так будет установлен Python, если он будет использовать вашу библиотеку.
Наша библиотека не требует никаких внешних зависимостей, поэтому Вы можете исключить четыре библиотеки, перечисленных в примере выше.
Соавтор, который разветвляет репозиторий проекта и устанавливает закрепленные библиотеки с помощью pip, будет иметь те же версии, что и Вы. Это значит, что они должны работать.
Измените информацию setuptools так, чтобы она соответствовала информации вашей библиотеки. Существует множество других необязательных аргументов и классификаторов ключевых слов — см. перечень здесь. Более подробные руководства по setup.py можно найти здесь и здесь.
Сохраните свой код в локальном репозитории Git. Пора переходить к созданию библиотеки!
Шаг 10: Соберите первую версию
Twine — это набор утилит для безопасной публикации библиотек Python на PyPI. Добавьте библиотеку Twine в следующую пустую строку файла require_dev.txt таким образом:
Затем закрепите Twine в Вашей виртуальной среде, переустановив библиотеки needs_dev.txt.
Затем выполните следующую команду, чтобы создать файлы библиотеки:
На компьютере пользователя pip будет по мере возможности устанавливать библиотеки как wheels/колеса. Они устанавливаются быстрее. Когда pip не может этого сделать, он возвращается к исходному архиву.
Давайте подготовимся к загрузке нашего колеса и исходного архива.
Шаг 11: Создайте учётную запись TestPyPI
PyPI — каталог библиотек Python (Python Package Index). Это официальный менеджер библиотек Python. Если файлы не установлены локально, pip получает их оттуда.
TestPyPI — это работающая тестовая версия PyPI. Создайте здесь учетную запись TestPyPI и подтвердите адрес электронной почты. Обратите внимание, что у Вас должны быть отдельные пароли для загрузки на тестовый сайт и официальный сайт.
Шаг 12: Опубликуйте библиотеку в PyPI
Используйте Twine для безопасной публикации вашей библиотеки в TestPyPI. Введите следующую команду — никаких изменений не требуется.
Вам будет предложено ввести имя пользователя и пароль. Не забывайте, что TestPyPI и PyPI имеют разные пароли!
При необходимости исправьте все ошибки, создайте новый номер версии в файле setup.py и удалите старые артефакты сборки: папки build, dist и egg. Перестройте задачу с помощью python setup.py sdist bdist_wheel и повторно загрузите с помощью Twine. Наличие номеров версий в TestPyPI, которые ничего не значат, особой роли не играют — Вы единственный, кто будет использовать эти версии библиотек.
После того, как Вы успешно загрузили свою библиотеку, давайте удостоверимся, что Вы можете установить его и использовать.
Шаг 13: Проверьте и используйте установленную библиотеку
Создайте еще одну вкладку в командном интерпретаторе и запустите другую виртуальную среду.
Вот официальные инструкции по установке вашей библиотеки из TestPyPI:
Вы можете заставить pip загружать библиотеки из TestPyPI вместо PyPI, указав это в index-url.
Если хотите, чтобы pip также извлекал и другие библиотеки из PyPI, Вы можете добавить — extra-index-url для указания на PyPI. Это полезно, когда тестируемая библиотека имеет зависимости:
Если у вашей библиотеки есть зависимости, используйте вторую команду и подставьте имя вашей библиотеки.
Вы должны увидеть последнюю версию библиотеки, установленного в Вашей виртуальной среде.
Чтобы убедиться, что Вы можете использовать свою библиотеку, запустите сеанс IPython в терминале следующим образом:
Импортируйте свою функцию и вызовите ее со строковым аргументом. Вот как выглядит мой код:
После я получаю следующий вывод:
(Когда-нибудь я конвертирую для тебя блокнот, Джефф)
Шаг 14: Залейте код на PyPI
Загрузить код можно так:
Обратите внимание, что Вам нужно обновить номер версии в setup.py, если Вы хотите залить новую версию в PyPI.
Отлично, теперь давайте загрузим нашу работу на GitHub.
Шаг 15: Залейте библиотеку на GitHub
Убедитесь, что Ваш код сохранен.
Моя папка проекта notebookc выглядит так:
Шаг 16: Создайте и объедините PR
Шаг 17: Обновите рабочую версию на GitHub
Создайте новую версию библиотеки на GitHub, кликнув на релизы на главной странице репозитория. Введите необходимую информацию о релизе и сохраните.
На сегодня достаточно!
Мы научимся добавлять другие файлы и папки в будущих статьях.
А пока давайте повторим шаги, которые мы разобрали.
Итог: 17 шагов к рабочей библиотеке
Узнайте подробности, как получить востребованную профессию с нуля или Level Up по навыкам и зарплате, пройдя платные онлайн-курсы SkillFactory:
Как создать свою собственную библиотеку AutoML в Python с нуля
Библиотеки и сервисы AutoML вошли в мир машинного обучения. Для дата-сайентиста это очень полезные инструменты, но иногда они должны быть адаптированы к потребностям бизнес-контекста, в котором работает дата-сайентист. Вот почему вам нужно создать свою собственную библиотеку AutoML. В преддверии старта нового потока курса «Машинное обучение» мы делимся материалом, в котором описано, как это сделать на Python.

Что должна делать библиотека AutoML?
Библиотека AutoML — это любая часть программного обеспечения, автоматизирующая некоторые самые сложные (и скучные) части конвейера машинного обучения. Применение AutoML ускорит процесс машинного обучения и поможет избежать ошибок. Библиотека AutoML должна автоматизировать такие действия:
Подход
Здесь я расскажу о конвейере классификации с такой сеткой настроек:
Мы перевели нашу задачу в задачу гиперпараметрической оптимизации, которую мы можем решить. Пространство гиперпараметров конвейера очень велико, поэтому воспользуемся случайным поиском, чтобы найти лучший набор значений таких гиперпараметров. Наш объект будет принимать фрейм данных Pandas на вход для обучения, а метод “обучения” выполнит необходимую оптимизацию, чтобы найти лучшую модель и лучшие настройки для фазы предварительной обработки. Посмотрим на код.
Мы создадим объект под названием MyAutoMLClassifier и будем обучать и тестировать его на наборе данных о раке молочной железы. Вы можете найти весь код в моём репозитории на GitHub.
Импортируем библиотеки:
Теперь мы можем приступить к определению класса MyAutoMLClassifier. Его конструктор будет принимать скоринговую функцию, которая будет использоваться в k-кратной кросс-валидации и в количестве итераций случайного поиска. В этом примере их значениями по умолчанию будут «balanced accuracy» — сбалансированная точность и 50.
Теперь мы можем начать писать метод «обучения» — самый важный метод. Во-первых, мы должны определить различные значения категориальных переменных, чтобы применить унитарное кодирование.
Теперь для категориальных переменных нужно определить конвейер предварительной обработки. Этот конвейер заменит пустые значения, используя наиболее часто встречающееся значение, и унитарно закодирует новые значения. В то же время мы собираемся определить конвейер для числовых переменных, который будет очищен в соответствии с определяемым позже и масштабирован в соответствии с преобразователем масштаба, который мы установим в части случайного поиска. Всё это, наконец, включается в настройки ColumnTransformer, который выполнит всю предварительную обработку.
Наконец, мы должны определить конвейер ML, который строится на этапе предварительной обработки, подбора признаков и самой модели. Сейчас мы можем установить модель в LogisticRegression, она будет изменена позже случайным поиском.
Затем можно вычислить количество признаков (это понадобится в части подбора признаков) и создать пустой список, содержащий оптимизационную сетку в соответствии с синтаксисом, необходимым RandomSearchCV.
Теперь мы можем начать добавлять модели в нашу сетку оптимизации. Начнём с логистической регрессии:
Как мы видим, создаётся объект, который изменит масштабирование между RobustScaler, StandardScaler и MinMaxscaler. Затем будет изменена стратегия очистки между средним и медианным значениями и выбраны объекты от 1 до общего числа объектов с шагом 5. Наконец, сама модель установлена. Случайный поиск будет проверять случайные комбинации этой сетки, в поиске той, которая максимизирует показатели производительности при кросс-валидации.
Теперь мы можем добавить другие модели с их собственными гиперпараметрами и нуждами в смысле предварительной обработки. Например, деревья не требуют никакого масштабирования, но SVM — да. Мы можем добавить столько моделей, сколько захотим, оптимизируя их гиперпараметры в одной сетке.
Итак, мы ищем наилучшее сочетание стратегии очистки, процедуры масштабирования, набора признаков, значений модели и гиперпараметров — всё в одной и той же процедуре поиска. Это ядро любой библиотеки AutoML и может быть расширено по нашему желанию.
Теперь у нас есть завершённая сетка оптимизации, так что мы можем, наконец, применить случайный поиск, чтобы найти лучшие параметры конвейера и сохранить результаты в свойствах нашего объекта. Случайный поиск будет применять 5-кратную кросс-валидацию с помощью функции скоринга и количества итераций, выбранных в конструкторе класса.
Метод обучения завершён. Теперь мы можем добавить методы «predic» и «predict_proba», как и любую другую модель sklearn, и наш MyAutoMLClassifier закончен.
Сейчас можно импортировать набор данных, разделить его на наборы обучения и тестирования, создать экземпляр MyAutoMLClassifier и обучить его.
С помощью всего лишь одной строки кода мы делаем все сложные вещи с помощью AutoML. После обучения модели мы можем рассчитать сбалансированную точность в тестовом наборе и посмотреть, какие параметры модели и предварительной обработки были выбраны:
Мы используем классификатор дерева градиентного бустинга со всеми функциями и численную стратегию очистки, основанную на медианном значении. Скорость обучения модели равна 0,1, а число обучающихся на данных объектов — 125. Это результат применения AutoML.
Заключение
Библиотеки AutoML — это очень полезные инструменты для дата-сайентита, и они действительно помогают сэкономить много времени. В соответствии с бизнес-контекстом, над которым мы работаем, нам может потребоваться работать только с определёнными моделями или процедурами очистки, поэтому нам нужна своя версия AutoML. Пример в этой статье легко адаптируется к задаче регрессии и может быть интегрирован с другими моделями, такими как нейронные сети.