Создаем собственный текстовый квест в Telegram
Ростислав Бородин
Для начала давайте познакомимся с Telegram ботами, по ссылке представлено множество примеров таких программ, от прогноза погоды до общения с рандомным собеседником: https://uip.me/2016/04/50-popular-telegram-bots/.
После получения токена нам потребуется установить библиотеку pyTelegramBotApi, как и обычно, это делается через pip:
Пробуем создать бота
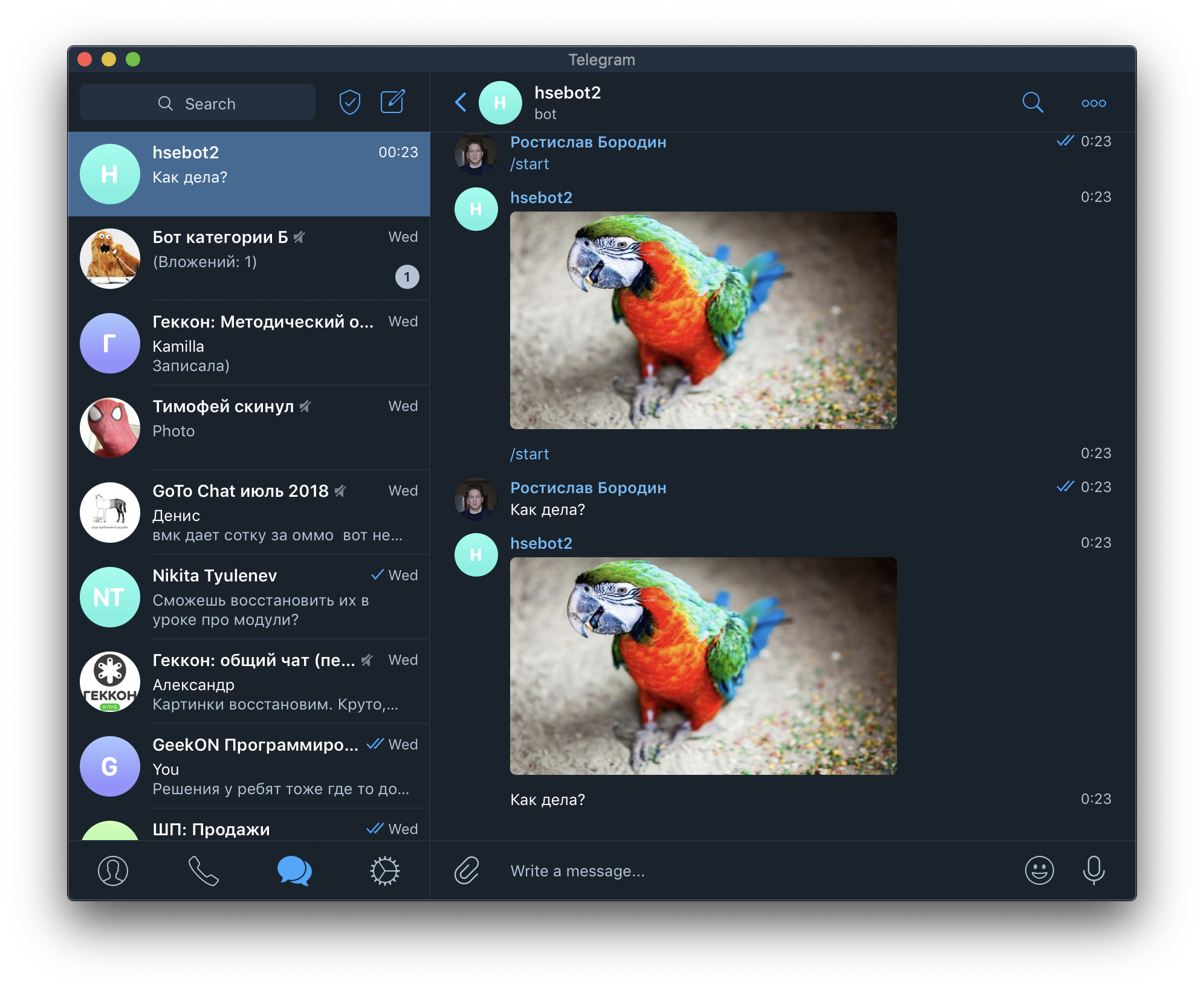
Давайте добавим пояснение к нашему боту, которое объяснит пользователю, что он делает.
Взаимодействуем с несколькими пользователями одновременно
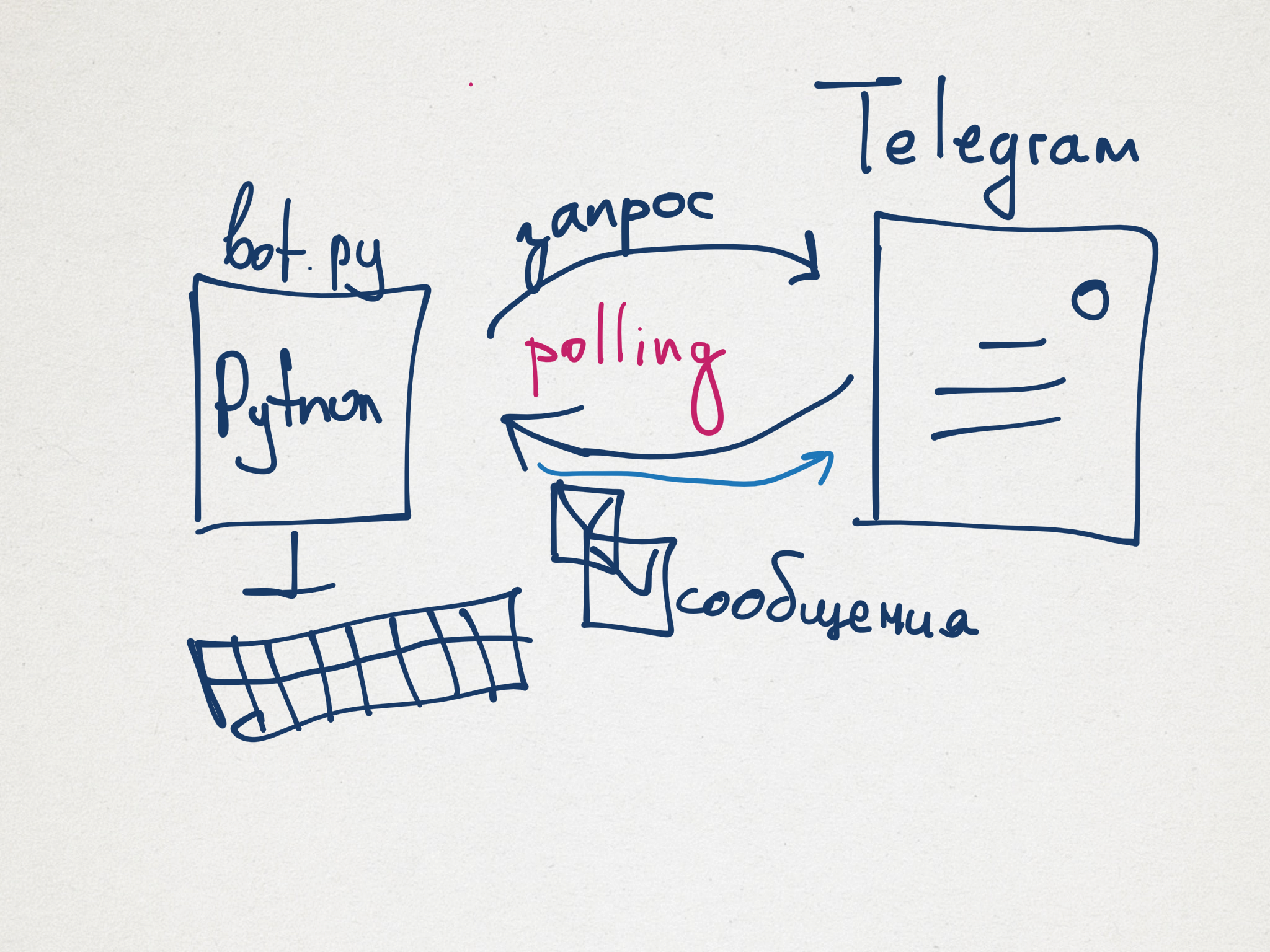
Предположим мы хотим сделать бота, которы будет запоминать какую-то фразу, а затем по просьбе пользователя напоминать ее ему. Чтобы решить эту задачу, нам понадобится где-то хранить последнее сообщение пользователя.
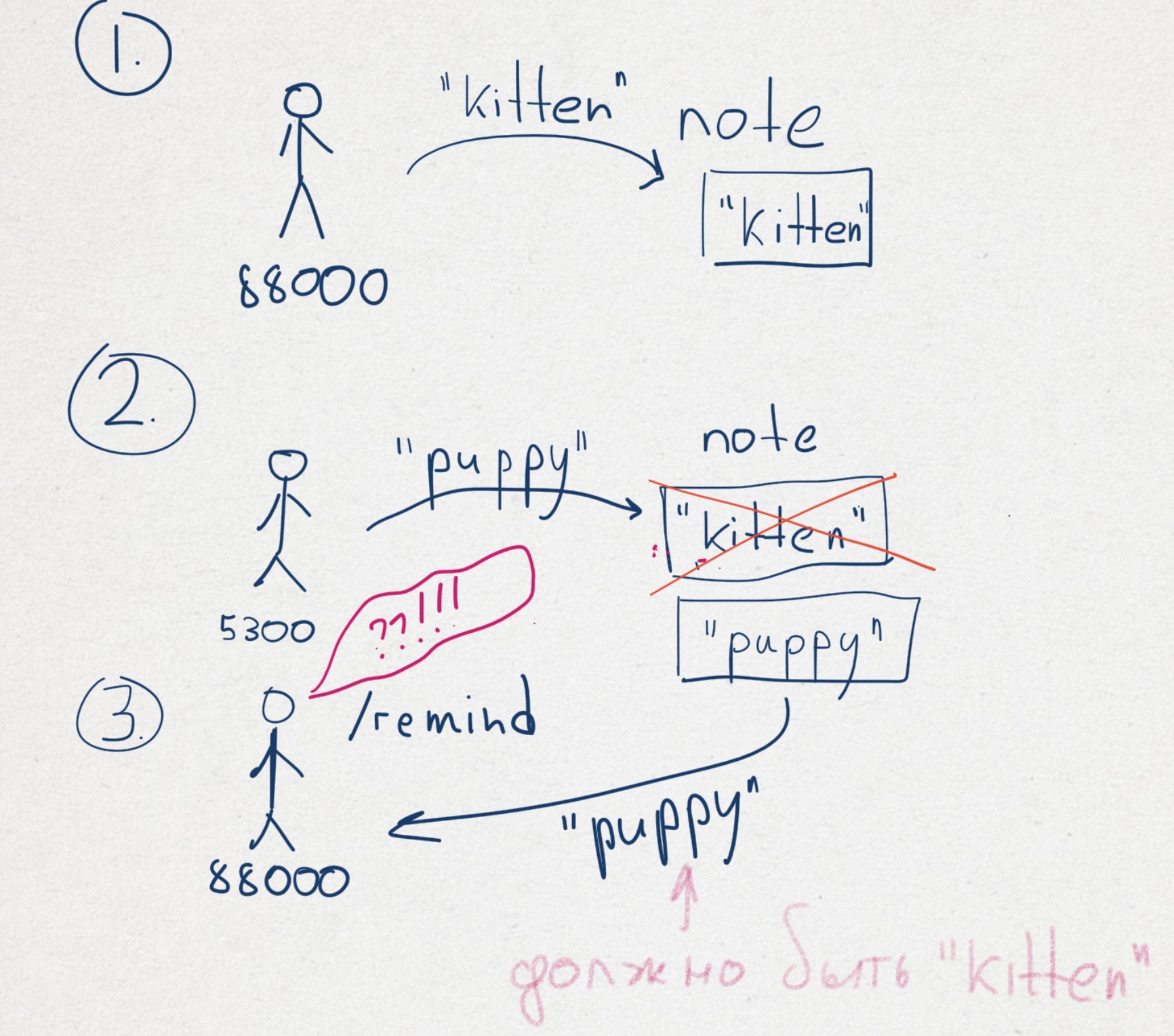
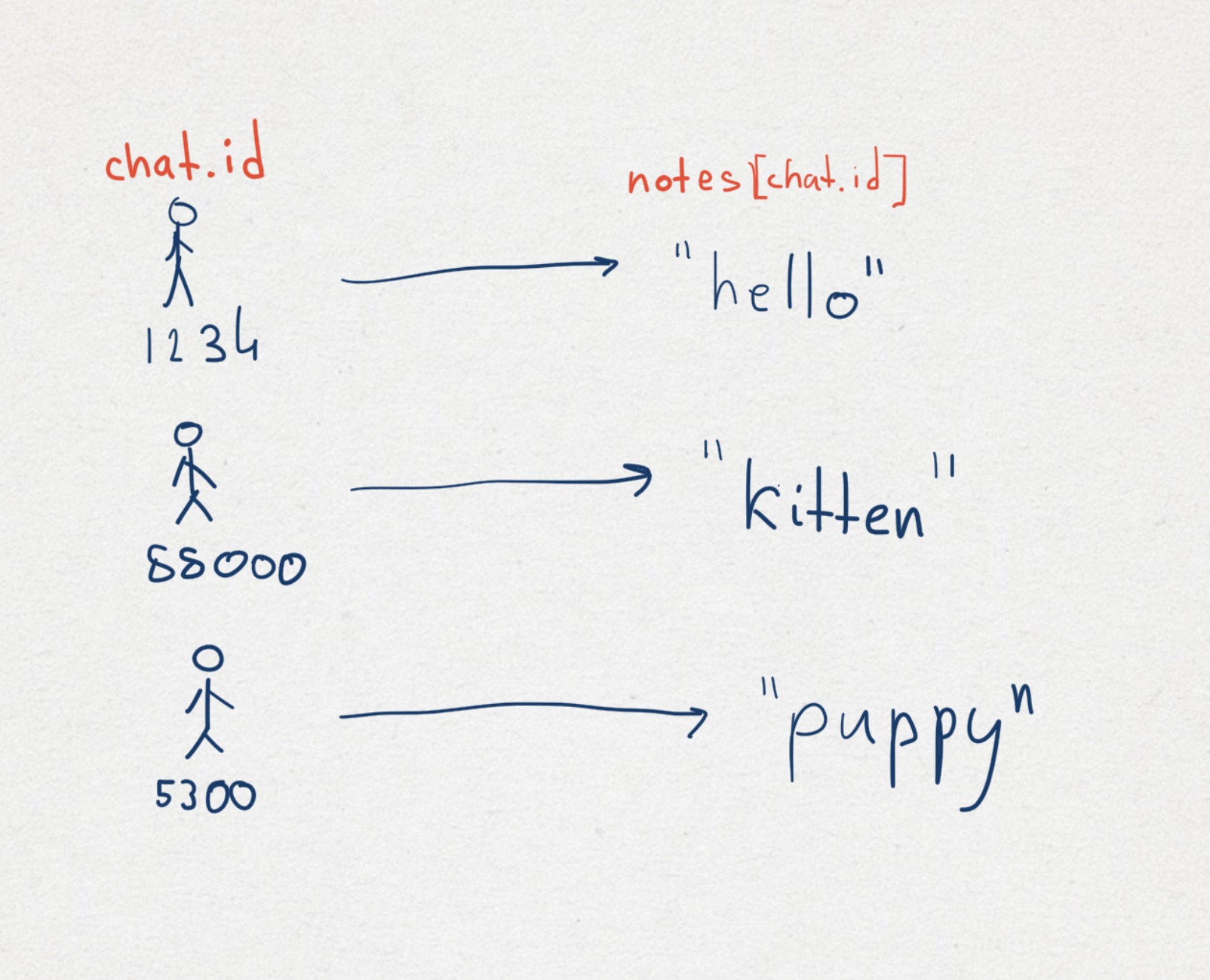
Реализация:
Добавляем кнопки
Следующий пример демонстрирует, как добавить несколько кнопок к сообщению и реагировать на их нажатия.
Простая текстовая RPG в Python
4 ответа
и повторите несколько раз:
Я был бы склонен сделать классы игроков отдельными для классов монстров, поэтому у вас будет структура наследования вроде:
Это позволяет вам больше учитывать дублирование. Например:
Я использовал бы random.choice для этого и разрешаю указать размер моба:
для создания списка используется понимание списка случайно выбранных врагов из кортежа.
Затем запускается commands :
См. запрос пользователя на ввод, пока он не даст действительный ответ для получения дополнительной информации о проверке ввода. Вы можете расширить это, чтобы определить соответствующие параметры для каждого действия и т. Д.
Здесь много кода (258 строк), поэтому я не буду давать полный обзор, а несколько предложений о том, что вы можете улучшить в целом.
В любом случае, надеюсь, это поможет вам в вашем проекте!
Официальное руководство по стилю
У вас есть около 250 нарушений для PEP8, используйте autopep8, чтобы сделать ваш код более удобочитаемым
Словарь
Длинная серия if и elif считается плохим стилем, словарь также позволяет проще добавлять больше классов и опций.
Также обратите внимание, что печать создается из словаря для максимального удобства.
Автономные функции
В функциях Python можно свободно плавать в глобальном пространстве имен, и в них анализируется, что они делают это, когда это имеет смысл, поэтому:
также лучше вернуть значение напрямую (без и промежуточной переменной).
Расширить классы
Цепочка if не очень приятная и станет еще менее приятной, когда добавлено больше символов, вы должны реализовать max_damage или max_power внутри класс игрока, чтобы написать:
Я пишу текстовую игру на Python: первый прототип
В новом выпуске блога о программировании я довожу игру LAM-40 (мы начали писать её в позапрошлом выпуске) до элементарного прототипа, который уже можно испытывать.

Предыдущий выпуск

В прошлый раз мы разобрались, как подготовить компьютер к работе с Python, и теперь можем перейти к написанию игры. В создании любой игры чуть ли не самое важное — это как можно скорее начать её прототипировать, чтобы сразу выявить основные уязвимости и устранить их. У нас, конечно, игра довольно простая, да и главное для нас не её качество, а упражнения с кодом. Тем не менее раннее прототипирование — это полезная привычка в разработке чего угодно, поэтому давайте ей следовать.
Для тех, кто успел подзабыть за две недели суть того, что мы делаем, напомню. LAM-40 — это текстовая игра, где вы играете за человека, которому нужно успеть за девять часов получить справку на 40-м этаже загадочного государственного учреждения, переполненного бюрократами. Каждый этаж учреждения генерируется случайным образом: игроку попадаются бюрократы разного уровня, к каждому из которых нужно искать особый подход, чтобы пройти дальше и добраться до последнего этажа.
Примечание: весь код приводится для Python версии 3.0 и старше, а потому может не работать на более старых версиях.
Для начала давайте вспомним, какой код остался у нас с прошлого раза, и разберёмся, чем мы его хотим дополнить.
У нас есть простенький класс бюрократа, умеющего здороваться с игроком и обладающего двумя характеристиками — рангом и настроением. Задача на сегодня — создать простейший, бесконечно повторяющийся цикл «сражений» с бюрократами, что, по сути, и есть основная механика нашей игры. Получившийся у меня в итоге прототип занял 95 строк — начнём его разбирать по порядку (последняя пустая строка должна быть по стандартам PEP 8, но embed’ы её обрубают).
Строка 2: помимо random, в начале программы мы импортируем модуль sys. Из него нам понадобится функция exit() — возможность выйти из игры, пока что не указанная эксплицитно.
Строки 5–13, 16: я добавил списки положительных и отрицательных реакций бюрократов. Обратите внимание, как используются переносы. Дело в том, что, согласно PEP 8, максимальная длина строки должна быть 79 символов, иначе код будет слишком сложно читать. Именно поэтому для удобства каждое новое высказывание находится на новой строке и написано с тем же отступом, что и предыдущее. Ещё я добавил переменную ACTIONS типа данных string с основными действиями игрока (обычным вопросом, подкупом, мольбой, давлением и угрозой), чтобы не делать слишком длинной строку, где мы будем выводить все эти действия.
Строки 25, 34–44: у класса Bureaucrat появилась характеристика negative логического типа данных (то есть истина или ложь) со значением False. Она показывает, был ли ход игрока удачным — если нет, то её значение становится True, и игра предлагает нам совершить новое действие на том же самом бюрократе, а не создаёт нового бюрократа. Для того чтобы отобразить реакцию бюрократа на действие игрока, используются функции с говорящими названиями react_positively() и react_negatively(), которые меняют значение переменной negative и выводят случайную реакцию бюрократа на случившееся.
Строки 46–85: функция act() выводит на экран все возможные действия игрока и предлагает ему выбрать одно из них, введя первую букву слова. Именно для того, чтобы не загружать эту строку, мы вывели string со всеми действиями в отдельную переменную ACTIONS. Следом за этим идёт ветвление, и мы впервые в этом блоге используем ключевое слово elif — сокращение от else if. Оно задаёт условие помимо того, что указано в if, а блок с ним — следующие за выполнением этих условий действия. В нашем случае мы проверяем, что ввёл игрок. Если он ввёл строчную букву Q, выполнение программы завершится из-за упомянутой ранее функции sys.exit(). Если игрок введёт строчную букву W (wait), то ему выпадет новый бюрократ — это тоже пока что незадокументированная возможность. Если же игрок введёт какой-нибудь другой символ, то программа перейдёт в функцию react(), где ветвление выходит на новый уровень. На текущем этапе я сделал так, что для определённых сочетаний ранга и настроения бюрократа срабатывает лишь одно действие. Более того, есть непобедимые сочетания (например, высокий ранг и плохое настроение), в случае с которыми приходится вводить W, чтобы выпал следующий бюрократ.
Самая большая головная боль на первых порах — это использование ключевого слова self, когда вы ссылаетесь на функцию или характеристику класса внутри этого класса, и оператора сравнения == вместо оператора присваивания = рядом с условными операторами. Вероятно, и о том, и о другом вы будете забывать, так что следите за этим. Кстати, обратите внимание на ключевое слово and, которое используется рядом с операторами ветвления — оно обозначает, что должны выполняться оба условия, находящиеся рядом с ним.
Строки 87–94: наконец, в самом низу заканчивается описание класса и начинается логика основной программы. Мы создаём образец класса Bureaucrat, присваиваем его переменной bureaucrat и используем функцию с приветствием бюрократа. После этого запускаем бесконечный цикл, внутри которого запускаем функцию с выводом и вводом действий игрока, а также условное исполнение создания и приветствия нового бюрократа — в зависимости от того, каково текущее значение bureaucrat.negative. Обратите внимание на две вещи: оператор else при желании можно не использовать, а в случае с логическими типами данных в Python вместо оператора == применяют ключевое слово is.
Первый прототип LAM-40 готов. Конечно, он ещё далёк не то что от финальной, а даже от альфа-версии, поэтому нам предстоит порядочно поработать. Сейчас я вижу кучу проблем с этим прототипом, которые собираюсь устранить в следующий раз:
Нужно полностью изменить структуру кода: текстовые данные из верхней части перенести в отдельную базу, функции раскидать по другим классам, основную логику программы направить в отдельный файл и так далее.
Не обойтись без элемента неожиданности в «сражениях» с бюрократами — иначе игра быстро наскучит. Вероятно, это также поможет избежать дикого ветвления, которое есть сейчас в нижней части кода.
Игре требуется больше разнообразия во фразах, характеристиках, действиях и прочем, а также в том, как всё это выводится, чтобы внести разнообразие в повествовательную часть.
Желательно описывать текстом все действия, что возможны в игре, в том числе выход из неё и ожидание.
Из возможных действий желательно сделать список, а не отдельный string, чтобы туда можно было при определённых условиях добавлять новые действия. Кроме того, на ввод нужно применить функцию upper(), чтобы не требовалось каждый раз вводить строчные буквы. Также надо сделать адекватную реакцию на неверно введённые символы.
В основной логике игры есть повторяющиеся две строчки, нарушающие правило DRY. Да и сам цикл не очень красив — пожалуй, стоит над ним подумать, когда он начнёт расширяться.
Куча мелочей вроде описания функции act(), комментариев к некоторым частям кода, использования sys.exit() и характеристики negative, которая тоже не очень изящное решение. Так что поищу ему альтернативу.
Как видите, работы предстоит полно. Надеюсь, к следующему разу игра примет уже более целостный вид. Если вам что-то непонятно, пишите комментарии под материалом и в социальных сетях — буду рад и любым другим отзывам. Если вы более опытный в программировании человек, чем я, то с удовольствием выслушаю содержательную критику. Спасибо, и до следующего раза!
Полные курсы Python на Codeacademy и Treehouse*
* — платные курсы, но есть пробный период
Развитие программистского мышления на Udacity
Текстовый квест на питоне
Напишите небольшой текстовый квест. Пользователю сообщается, что его персонаж находится в комнате, из которой есть несколько ходов (не менее трёх). Он должен выбрать, в какой из них пойти. В любом из ходов (хотя бы в одном) может быть ещё развилка. Таким образом игрок выбирает ход один или два раза и приходит к какому-то концу — хорошему или нет (для каждого варианта прохождения лабиринта должно быть своё уникальное окончание). Пользователь может выбирать вариант, набрав его номер или слово — на ваше усмотрение, но обязательно дайте ему инструкцию, как сделать выбор. Если пользователь вводит неверный вариант, программа сообщает об ошибке и завершает работу.
Пример работы такой программы:
Вы находитесь в пещере на развилке. Вы можете пойти «налево», «направо» или «прямо». Введите одно из слов в кавычках для выбора.
налево
Вы направились налево. Через некоторое время вы дошли до двух дверей. Вы выберете «левую» или «правую»? правую
Вы смело открыли правую дверь. Но за ней вас подстерегала гигантская подземная жаба, которая проглотила вас целиком!
 Как открыть файл на питоне, чтобы внутри содержимый код работал при открытии на питоне?
Как открыть файл на питоне, чтобы внутри содержимый код работал при открытии на питоне?
Хочу открыть файл, чтобы внутри код работал на питоне: >>> a = open(r’F:\python\py\Madi.
Текстовый квест
Привет всем. Нужно переделать текстовый квест с алгоритмического языка на php. С чего начать? Как.
Текстовый квест
Подскажите, кто может помочь в написании текстового квест на с++?; В универе задали создать.
Текстовый квест
Вечер добрый. Такое дело: я совсем новичок, захотелось написать простенький текстовый КВЕСТ (пока.
Игра на Python за 19 строк

Хеллоу ворлд! Если вам надоели задачки из видео курсов или книг можете сделать эту игру.
Сейчас мы сделаем камень, ножницы, бумага.
Для начала импортируем рандом:
Теперь сделаем бесконечный цикл чтобы не перезапускать игру несколько раз:
Пропишем правила для игроков:
Теперь сделаем выбор для игрока:
player = input(‘Вы выбрали:’)
И вот мы подошли к тому как все-таки реализовать проверку того что написал игрок, а также выход из игры:
if player not in [‘к’, ‘н’, ‘б’, ‘выход’]:
print(‘Не правильный ввод!’)
Теперь пропишем выбор для бота и тут нам поможет рандом:
comp_choice = gen[random.randint(1, 3)]
Что ж мы сделали почти все шаги в игре, но осталось сделать победные комбинации:
Последний и самый простой шаг обозначаем победу или ничью:
if player == comp_choice:
elif (player,comp_choice) in win_combination:
player = input(‘Вы выбрали:’)
if player not in [‘к’, ‘н’, ‘б’, ‘выход’]:
print(‘Не правильный ввод!’)
comp_choice = gen[random.randint(1, 3)]
if player == comp_choice:
elif (player,comp_choice) in win_combination:
Вот и все вы сделали игру и можете похвастаться перед друзьями.
Телеграм-канал @featuresfordev. Там мы делимся своими мыслями в таком формате.

Программирование на python
225 постов 7.6K подписчиков
Правила сообщества
Публиковать могут пользователи с любым рейтингом. Однако!
• уважение к читателям и авторам
• простота и информативность повествования
• тег python2 или python3, если актуально
• код публиковать в виде цитаты, либо ссылкой на специализированный сайт
• допускать оскорбления и провокации
• распространять вредоносное ПО
• просить решить вашу полноценную задачу за вас
Чел, ты рекламируешь свой канал, и даже не вставил свой код нормально. Я редко постам ставлю минусы, но это какое-то жуткое неуважение к читателям.
Вот полный код:
ссылка на гит.
Вы разработчик или где?
код питона без отступов выглядит идеально!
П.С. ты это сделал что бы над ньюбами поиздеваться, да?
Спасибо огромное! Я как раз хотел узнать побольше команд!
Как вариант (исключения не перехватываются, форматирование строк не применяется, Python 3) :
import random
player_win = 0
bot_win = 0
Смысл этого поста? Он обучает разве что копипастить код.
> gen = <1:'к', 2:'н', 3:'б'>> comp_choice = gen[random.randint(1, 3)]
Отступы нужны в коде, без них не полетишь..


Программирование ESP32, ESP8266 на MicroPython
Запланировал небольшой курс по программированию ESP32, ESP8266 на MicroPython. В данном видео ролике рассказываю преимущества и недостатки MicroPython. И провожу небольшое сравнение с Arduino.
Если вы считаете этот учебный курс полезным, пожалуйста, поделитесь им! Чтобы он мог охватить больше людей, которым это может быть интересно.

Надеюсь моя информация будет полезной.
Спасибо! Всем добра!


А надо ли учиться?
Я понимаю, что даже при покупке курса надо будет что-то почитывать дополнительно, но на сколько это реально, например, для того же, скажем, юриста со знанием английского на уровне Pre-Intermediate?
Так много вопросов, много желания начать учиться и изменить жизнь к лучшему, уйти из старой нелюбимой профессии, и столько же здорового реализма, который заставляет сомневаться в собственных возможностях и оценивает память уже не как свежую студенческую, а немного поношенную, что значительно затруднит процесс. И после работы и нервяков голова тупит уже слегонца. И здоровую прокрастинацию никто не отменял. Поделитесь опытом, пожалуйста.
Пы.Сы. Не бейте сильно, если эта тема уже обсуждалась, а я пропустила или мой вопрос кому-то покажется глуповатым.



Ответ на пост «Как войти в IT после 30, мой путь от офисного планктона до Middle Java разработчика в Сбербанке»

Как войти в IT после 30, мой путь от офисного планктона до Middle Java разработчика в Сбербанке

поэтому три года назад, перегорев от творческой работы по раскладыванию пасьянса «косынка», я решил что-то в жизни поменять. Начал с изучения английского. Не стану превращать пост в подробное описание этого процесса, тем более есть уже замечательный пост от @L4rever, на эту тему. Добавлю лишь, что для пополнения словарного запаса мне очень зашёл сайт\приложение memrise который помог мне дотянуть свой словарик до 5000 слов примерно за год в бесплатном режиме. Хоть изучение английского и не имело решающего значения в моей дальнейшей судьбе, но весьма помогло.
Глава 1. Избавление от обязательств и накопление финансовой подушки
Как и у большинства людей старше 25 у меня была ипотека, благо не такая большая, всего на 1,5 миллиона (хоть какие-то преимущества жизни в пригороде провинциального города).
Поэтому прежде чем резко менять свою сферу деятельности, неплохо бы было погасить обязательства. Нужно было заработать денег, с этим вопросом я вышел в интернет.

Интернет рассказал мне о фрилансеров, различных специальностей, всяких копирайтерах, smm менеджерах и так далее. С копирайтингом у меня не особо получилось, за 50 заказов и около 30 часов работы я получил 1500 рублей. Писать тексты было скучно, бесконечные поправки и конкуренция в виде армии школьников за заказ стоимостью 35 рублей, 84 копейки.
Поэтому было решено попробовать второй путь. И тут мне повезло уже на второй день поисков на зарубежной бирже я смог найти заказчика, которому нужно было вести группы в ВК и Facebook для нескольких брендов. Работы было не сильно много, всего на пару часов в день. Платили тоже не супер, 15 тысяч, однако это на 13 500 больше чем зарплата копирайтера, поэтому я приступил к работе.
Также спустя примерно месяц поиска мне удалось найти работу на полный день в службе поддержки одной фирмы электронных сигарет, где зарплата была выше в два раза, чем аналогичные позиции на рынке. В требованиях было знание английского. Разумеется моего текущего уровня знания языка не хватало для прохождения собеседования, но благодаря разговорам с носителем (олды может даже вспомнят) я мог хоть как-то поддерживать разговор. К моему удивлению этого хватило, чтобы:
1) Устроится туда самому.
2) Устроить туда жену, со знанием языка на уровне летспик фромахарт используя хитроумное устройство, в виде наушника и меня с микрофоном.
Благо звонки были только на русском и английский нужен был чтобы в рабочей программке с английским интерфейсом заполнять данные.
Но как не может долго длится волна постов на пикабу, так и эффективные менеджеры не могли долго смотреть на зарплату выше рынка. В итоге через год наш коллектив был распущен, мы с женой остались без работы, но и без ипотеки и даже с финансовой подушкой на пол года. Обдумав все варианты дальнейшей жизни я решил, что:

Глава 2. Куда пойти
Есть люди способные учиться чему-то после работы или в выходные. Они могут потратить свой отпуск на курсы или экзамены, а зимние каникулы на собственные проекты. Я по хорошему завидовал таким людям, но прекрасно осознавал, что я ленивая жопа с низкой самодисциплиной и вот это вот всё мне не подходит. Мне нужны были какие-то курсы, желательно оффлайн, но обязательно с другими людьми рядом, с этим вопросом я вышел в интернет.
UPD. Сейчас многие крупные компании также открыли свои школы, видел такие у Яндекса и ВТБ, поэтому выбор стал шире.

Здание школы в Казани
На удивление не нашёл нормальных постов про эту школу на пикабу, хотя казалось бы тема актуальная. Поэтому расскажу подробно как проходит процесс поступления и обучения.
Так как школа бесплатная и фактически никаких ограничений по возрасту и образованию к поступающим не предъявляет (единственное это возраст 18+), желающих поступить приходит больше, чем существующее количество мест. Поэтому в качестве вступительных экзаменов там есть «Бассейны». Но перед тем как попасть на них нужно пройти две игры на сайте, на память и логику\алгоритмы, после чего записать видеоинтервью с коротким рассказом о себе и ждать приглашения на испытание бассейном.

Нет, плавательные шапочки можно отложить, это не совсем то
Они представляют собой месячное, пробное обучение, где каждый день тебе даётся несколько задач, решение которых ты должен предоставить через день, однако учитывая, что задачи дают ежедневно, фактически ты ограничен одним днём. После чего выполнение таких заданий проверяют два случайным образом выбранных ученика и внутренняя система (мулиннет). Каждую неделю проходит экзамен, по темам, которые ты должен был изучить за эту неделю и финальный экзамен на 28 день обучения.

Так выглядит учебное здание, около 300 рабочих станций с шахматным расположением.
Советую по возможности найти компанию людей и вместе проходить это обучение, так намного проще, если вообще не единственный способ успешно превозмочь все трудности. В феврале 2020 я прошел этот бассейн, первый на тот момент в Казани, школу только открыли. Но потом случился коронавирус, который заморозил сроки старта обучения и до мая я просто сидел дома слегка самообучаясь в ожидании новостей.
В мае мы приступили к обучению, при чём дистанционно из-за ограничений в массовых собраниях, что было неслыханно для школы 21 (Кстати кампус в Москве уже на тот момент работал два года) и добавило сложностей к обучению, ведь я опять остался на самоконтроле и без друзей за соседними компами. Благо в сентябре нам разрешили вернутся в Кампус и надев маски, перчатки, соблюдая дистанцию метр мы начали учится сообща, что было всё же намного лучше, чем ничего. Лучшей мотивацией для меня стала работа в команде, желание не подставить свою команду, да и в целом, коллективная работа более эффективная, особенно когда сталкиваешься с проблемой, которую не можешь решить несколько часов.
Для закрытия 9 уровня мне потребовался ровно год, я это сделал в мае 2021 и начал искать место стажировки, которая кстати в 99% случаев оплачиваемая.
Глава 4. Стажировка и работа

Офис какой-то ИТ-компании
Логично было бы подумать, что раз школа финансируется Сбером, то и работать ты обязан только там. Но это не так. Никаких финансовых или трудовых обязательств у учеников нет, в интернете ходит информация о штрафе в 50к за отчисление, но она устарела, этот штраф был лишь стимулирующей мерой не забрасывать школу, как оказалось она не работает и вызывает массу негатива, поэтому была заменена на дедлайны по набору уровней, при нарушении которых тебя просто отчисляют.
Затем школа помогает тебе состряпать твоё первое резюме и проводит различные ярмарки вакансий, куда приглашаются крупные компании, яндекс, мэйл и другие. Также ты можешь сам искать вакансии в любых фирмах, либо даже организовать собственный стартап, бывало и такое, как были и случаи стажировки в кампусах гугла с переездом в другие страны.
Но естественно самым простым, в плане организации, путём является стажировка в Сбере. Так как они прекрасно знают что ты стажёр и много от тебя ожидать не стоит, не получается таких недоразумений:

Мне опять же повезло, я прошел 4 собеседования в различные команды, по итогу получил 1 предложение на стажировку и 1 сразу в штат. Так не мудрствуя лукаво, в Июне я стал Junior Java разработчиком в Сбере в городе Иннополис (недалеко от Казани). Про город кстати отдельная тема, достойная целого поста, но можно просто почитать посты @veronichka.pb, где она подробно рассказывает о городе и процессе переезда в него.

Ну а спустя пол года, неделю назад, получил повышение (сейчас тру-погроммисты будут меня ругать, так как настоящий мидл это человек с опытом 2-3 года. И честно сказать будут правы, я считаю что получил повышение авансом, но в конце концов кто мы такие чтобы спорить с начальством)))
Касательно работы именно в Сбере, я очень доволен тем, что имею. Особенно сравнивая свой текущий опыт с отношением работодателей в не-айтишном прошлом, даже не беря в расчёт зарплату, а откинуть такой весомый аргумент довольно сложно =D. Коллектив поддерживает меня, несмотря на пробелы в моих знаниях и более низкую эффективность, отпроситься с работы для каких-то дел очень просто, а при необходимости легко можно работать удаленно. Ну и весьма неплохо иметь возможность переключится на другой проект, если текущий для тебя станет скучным, а проектов здесь огромное количество.
Кстати одним из главных аргументов, почему я выбрал именно эту компанию является отсутствие постоянно горящих дедлайнов, из-за чего многие перегорают, как например @OWIII, за вхождением в IT которого я внимательно следил. именно поэтому решил написать пост об этом сейчас, уже пройдя этот путь, а не в процессе его.
В конце хотел бы сказать, что ничего нереального во вхождение в ИТ-сферу нет, да вам будет легче, если вам 20 лет, нет детей и ипотеки, но рядом со мной прошёл путь человек с двумя детьми, ипотекой и 40 годами за плечами, который тоже сейчас работает разработчиком. И это не какая-то единичная ситуация, таких людей буквально сотни, даже на пикабу @vigerf, почитав мои комментарии решился начать свой путь, надеюсь он также поможет ответить на вопросы о школе в комментариях))
Не бойтесь начинать это в 30, 40, любое другое количество лет, намного страшнее как мне кажется, так и не попробовать.


Ползу в направлении мечты. Пост №6

А вот и очередная пятница. Как прошла ваша неделя? Надеюсь, что все было хорошо.
У меня по крайне мере да, даже лучше, все было отлично! Моя мечта уже начала осуществляться (наверное, заметили, что названия поста немного сменилось), и я одной ногой попала в геймдев. Ну может одной ногой это громко сказано, скорее мизинцем одной ноги, но это не важно. Сейчас расскажу поподробнее.
Под прошлым постом оставили коммент типа: “Давай к нам в инди команду.” Ну я подумала, была не была и написала. В итоге пообщались и меня “взяли” стажером. Очень страшно, боюсь, что не справлюсь или что буду делать в начале всё очень медленно. Но потом думаю, что вооот оноо, вооот. Я уже почти тут, в геймдеве, просто побольше упорства и всё получится. Ребята (инди студия с названием Nord Unit) как раз работают с Unity и специализируются на мобильных играх. Сейчас у них в работе имеется проект под названием Great Stairs, на который меня как раз будут подключать. Очень сложно описать, в каком я восторге от всего этого.
В связи с этим, на этой неделе я немного под изучила фотошоп, как нарезать PNG из PSD. Что бы потом использовать эти спрайты в Unity для создания интерфейса. Ну и, собственно, само задание, собрать этот интерфейс. Вроде немного, но с фотошопом я просидела целый день, хотя работы там было на 5 минут. За то, если мне дать такое же задание, я его сделаю уже очень быстро). Теперь осталось собрать макет, который мне дали в Unity. А дальше будет еще интереснее.
Что касается своей учебы, то на этой неделе я занялась противниками. Как я уже писала, он у меня ходит вправо в лево, добавила ему зрение. Оказывается это очень забавно выглядит. Если объяснять по-простому, то у противника имеется линия с шариком на конце, это можно назвать его глазами, в игре конечно она не видна. И когда ты заходишь на этот шарик, то противник тебя видит и начинает преследовать. Сейчас покажу скриншотом.

К сожалению, на этой неделе, полноценных у меня было только три дня. Т.к. в понедельник я ходила на ревакцинацию и весь вторник я провалялась с температурой и головной болью. Ближе к ночи всё прошло, и больше ни каких побочек не было.
И еще, каким-то чудом, видимо благодаря появившейся мотивации, я наконец то смогла вставать уже в 9 утра. Да и к полуночи уже вырубает. В общем, хватило пары пробуждений в выходные в 8 утра, и добавочной мотивации, что бы режим начал восстанавливаться.
Пока из минусов это то, что пока перестала заниматься английским, никак не могу понять, куда его впихнуть по времени. Ну и надо как-то перестроиться снова к тому, чтобы заниматься своими делами по вечерам, а то привыкла всё делать днем.
На следующей неделе надо уже дожать этого противника, сделать нанесение ударов и как раз следующее по очереди будет UI. Как раз будет в плюс к моему пайплайну по сборке UI.
В связи со всем этим, я поднимаю свой статус с лежания в направлении мечты, до ползанья в ее направлении. Главное не останавливаться и всё получится и у меня, и у вас))
Всем суперских выходных и прекрасной пятницы.


Естественный отбор


Бесплатно помогаю пикабушникам учить программирование, часть 27: «Мы составили план обучения по Swift»
Пикабушника @lycrois, которая любезно согласилась помогать мне в обучении программированию, составила план обучения по Swift.
Также мы завели группу в Telegram, где оперативно отвечаем на часто возникающие вопросы: https://t.me/+uKgZmAzvhpRjZjNi
Все это было и будет бесплатно. Добро пожаловать всем желающим =)

Английский для программирования не важен!©

Бесплатно помогаю пикабушникам учить программирование, часть 26: «Критерии прохождения испытательного срока»
В этом посте продолжаю делиться советами о тонкостях работы веб-разработчиком. Начало здесь https://pikabu.ru/story/pomogu_nauchitsya_programmirovat_besplatno_7319642
Чаще всего ответа на этот вопрос никто не знает. Поэтому, если на собеседовании что-то пошло не так и вы не хотите его продолжать, спросите о критериях прохождения испытательного срока у представителя компании. Скорее всего, будет весело =)
Важные прописные истины, о которых часто забывают
А не стоит забывать, что испытательный срок работает в обе стороны: компания проверяет сотрудника и сотрудник проверяет компанию. О 2й части этого тезиса многие забывают а, еще чаще, вовсе и не знают. Поэтому совершенно нормально, по завершению испытательного срока предупредить представителя компании о своем уходе.
Причины продолжить работать в компании по завершению испытательного срока
Это прежде всего. Вам должно нравиться работать на текущем месте. Не для того вас такими красивыми и умными мамы рожала, чтобы идти на ненужные компромиссы, при перегретом рынке труда =)
В моем понимании комфорт на рабочем месте зависит от 2х факторов: технических и организационных.
Под техническими факторами комфорта я понимаю качественный код, который легко поддерживать. Это предполагает, как минимум наличие хорошего уровня тестового покрытия и линтеров кода.
Под организациоными факторами комфорта я понимаю здоровую не конфликтную атмосферу в коллективе, отсутствие жестких переработок и горящих дедлайнов, решение рабочих задач исключительно в рамках своей компетенции.
Он должен быть раз в 4-6 месяцев. Это обусловлено инфляцией и ростом вашей квалификации.
Причины уйти из компании по завершению испытательного срока
Большая текучка кадров.
Частое наличие задач, которые не касаются вашей предметной области
Я очень советую пообщаться напрямую с тимлидом или тех. директором по завершению испытательного срока. Запросите обратную связь о себе, спросите на что обратить внимание вопросах развития в вашей области, узнайте свои слабые места с позиции более опытного сотрудника. Все это очень полезно.
Мой канал в Telegram, где я помогаю новичкам освоить программирование: https://t.me/LearnRubyForPikabu
Уже 37 моих подписчиков дошли до получения работы.
Добро пожаловать всем желающим.
Бесплатно помогаю пикабушникам учить программирование, часть 25: «Не все обещания стоит выполнять»
В этом посте продолжаю делиться советами о тонкостях работы веб-разработчиком. Начало здесь
Этот пост меня побудила написать запись из телеграм канала, который я не укажу по причине параноидальной нелюбви к рекламе. Фрагмент этой записи представлен ниже.

С таким подходом я согласен лишь частично. Мое мнение таково: не все обещания стоит выполнять. Рассмотрим этот подход с 2х сторон.
Обещания, которые стоит выполнять.
Это те обещания, результат выполнения которых зависит полностью от вас. Например, при удаленной работе, есть договоренность быть на ежедневных созвонах в 9:00. Этого стоит придерживаться целиком, полностью и безоговорочно.
Если же случилось что-то форс-мажорное, то обязательно предупредите о своем отсутствии заранее. Это очень хорошая практика, которая срежет многие острые углы.
Что касается фриланса или же работы с заказчиком напрямую, важно помнить: вам простят многие технические ошибки при наличии дисциплины и пунктуальности. Если вы обладаете этими двумя качествами и вы работали с этим заказчиком ранее, смело можете поднимать стоимость выше рынка за последующие работы. Вам пойдут на уступки в этом плане, практически во всех случаях. Вы даже не представляете, насколько сложно сейчас найти специалиста, который пунктуальный и квалифицированный одновременно.
Обещания, которые можно не выполнять.
Здесь речь пойдет о договоренностях, результат выполнениях которых не зависит от вас.
Это задачи, при выполнении которой обнаружились подводные камни. Это может быть ошибки конфигурации, множественные недоработки других сотрудников, внезапно изменившееся техзадание и все такое прочее. Лучшим решением в таких случаях будет предупредить менеджера или заказчика о том, что сроки могут растянуться по вышеописанным причинам.
Нужно понимать, что вас тоже не уведомили, что на проекте будет вот такой нежданчик из-за которого планы могут поменяться, так что вы уже работаете с последствиями неправильных решений, а не являетесь их инициатором.
Также следует понимать, что если можно избежать неприятной ситуации с избыточным уровнем ответственности заранее, то лучше именно так и поступить. Если на вас давят, принуждая назвать сроки завершения задачи, результат выполнения которой зависит не только от вас, лучше не говорить вообще ничего. Чаще всего давление на сотрудников происходит именно потому, что другие способы воздействия не доступны ввиду низкой квалификации руководства. Это нужно помнить и никогда не забывать.
Мой канал в Telegram, где я помогаю новичкам освоить программирование: https://t.me/LearnRubyForPikabu
Уже 37 моих подписчиков дошли до получения работы.
Добро пожаловать всем желающим.

Как я делал систему оптического трекинга

Дело было в далеком 2015 году. В продаже только появились очки виртуальной реальности Oculus DK2, рынок VR игр быстро набирал популярность.
Возможности игрока в таких играх были невелики. Отслеживалось всего 6 степеней свободы движений головы — вращение (инерциалкой в очках) и перемещение в маленьком объеме в зоне видимости инфракрасной камеры, закрепленной на мониторе. Процесс игры представлял собой сидение на стуле с геймпадом в руках, вращение головой в разные стороны и борьбу с тошнотой.
Звучало не очень круто, но я увидел в этом возможность сделать что-то интересное, используя свой опыт в разработке электроники и жажду новых проектов. Как можно было эту систему улучшить?
Конечно, избавиться от геймпада, от проводов, дать возможность игроку свободно перемещаться в пространстве, видеть свои руки и ноги, взаимодействовать с окружением, другими игроками и реальными интерактивными предметами.
1) Берем несколько игроков, надеваем на них VR очки, ноутбук и датчики на руки, ноги и туловище.
2) Берем помещение, состоящее из нескольких комнат, коридоров, дверей, оборудуем его системой трекинга, вешаем датчики и магнитные замки на двери, добавляем несколько интерактивных предметов и создаем игру, в которой геометрия виртуальной локации точно повторяет геометрию реального помещения.
3) Создаем игру. Игра представляет собой многопользовательский квест, в котором несколько игроков надевают на себя оборудование и оказываются в виртуальном мире. В нем они видят себя, видят друг друга, могут ходить по локации, открывать двери и совместно решать игровые задачи.
Эту идею я рассказал своему товарищу, который неожиданно воспринял ее с большим энтузиазмом и предложил взять на себя организационные вопросы. Так мы решили мутить стартап.
Для реализации заявленного функционала, нужно было создать две основные технологии:
1) Костюм, состоящий из датчиков на руках, ногах и торсе, отслеживающий положения частей тела игрока
2) Система трекинга, отслеживающая игроков и интерактивные объекты в 3D пространстве.
Про разработку второй технологии и пойдет речь в этой статье. Может быть, позже напишу и про первую.
Бюджета на все это, конечно, у нас не было, поэтому нужно было сделать все из подручных материалов. Для задачи отслеживания игроков в пространстве я решил использовать оптические камеры и светодиодные маркеры, закрепленные на VR очках. Опыта подобных разработок у меня не было, но я уже что-то слышал про OpenCV, Python, и подумал, что справлюсь.
По задумке, если система знает где расположена камера и как она ориентирована, то по положению изображения маркера на кадре можно определить прямую в 3D пространстве, на которой этот маркер находится. Пересечение двух таких прямых дает итоговое положение маркера.
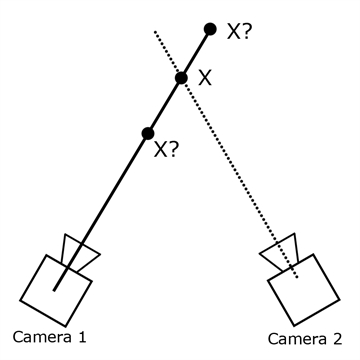
Соответственно, камеры нужно было закрепить на потолке так, чтобы каждая точка пространства просматривалась минимум двумя камерами (лучше больше, чтобы избежать перекрытия обзора телами игроков). Для покрытия трекингом предполагаемого помещения площадью около 100 кв.м., требовалось около 60 камер. Я выбрал первые попавшиеся дешевые на тот момент usb вебки.

Эти вебки нужно к чему-то подключать. Эксперименты показали, что при использовании usb удлинителей (по крайней мере, дешевых), камеры начинали глючить. Поэтому решил разделить вебки на группы по 8 штук и втыкать их в системники, закрепленные на потолке. На моем домашнем компе как раз было 10 usb портов, так что пришло время начинать разработку тестового стенда.
Архитектуру я придумал следующую:
На каждые очки вешается акриловый матовый шарик от гирлянды с вклеенным внутрь RGB светодиодом. Одновременно в игре предполагалось несколько игроков, так что для идентификации решил разделять их по цвету – R, G, B, RG, RB, GB, RB. Вот так это выглядело:

Первая задача, которую нужно выполнить – написать программу поиска шарика на кадре.
Поиск шарика на кадре
Мне нужно было в каждом кадре, пришедшем с камеры, искать координаты центра шарика и его цвет для идентификации. Звучит несложно. Качаю OpenCV под Python, втыкаю камеру в usb, пишу скрипт. Для минимизации влияния лишних объектов на кадре, выставляю экспозицию и выдержку на камере в самый минимум, а яркость светодиода делаю высокой, чтобы получить яркие пятна на темном фоне. В первой версии алгоритм был следующий:
1) Переводим изображение в градации серого
2) Бинаризуем по порогу (если яркость пикселя больше порога, он становится белым, иначе – черным). При этом размытое пятно от шарика превращается в кластер белых пикселей на черном фоне
3) Находим контуры кластеров и их центры. Это и есть координаты шарика на кадре
4) Определяем усредненный цвет пикселей кластера (на исходном цветном изображении) в окрестности его центра для идентификации

Вроде, работает, но есть нюансы.
Во-первых, на дешевой камере матрица довольно шумная, что приводит к постоянным флуктуациям контуров бинаризованных кластеров и соответственно к дерганью центра. Нельзя, чтобы у игроков дергалась картинка в VR очках, поэтому нужно было эту проблему решать. Попытки применять другие виды адаптивной бинаризации с разными параметрами не давали большого эффекта.
Во-вторых, разрешение камеры всего лишь 640*480, поэтому на некотором расстоянии (не очень большом) шарик виден как пара пикселей на кадре и алгоритм поиска контуров перестает нормально работать.
Пришлось придумывать новый алгоритм. В голову пришла следующая идея:
1) Переводим изображение в градации серого
2) Размываем картинку мощным Gaussian blur –ом так, чтобы изображения светодиодов превратились в размытые пятна с градиентом яркости от центра к периферии
3) Находим самые яркие пиксели на изображении, они должны соответствовать центрам пятен
4) Так же определяем средний цвет кластера в окрестности центра
Так работает гораздо лучше, координаты центра при неподвижном шарике неподвижны, и работает даже при большом расстоянии от камеры.
Чтобы убедиться, что все это будет работать с 8-ю камерами на одном компе, нужно провести нагрузочный тест.
Подключаю 8 камер к своему десктопу, располагаю их так, чтобы каждая видела светящиеся точки и запускаю скрипт, где описанный алгоритм работает в 8-ми независимых процессах (спасибо питонской либе «multiprocessing») и обрабатывает все потоки сразу.
И… сразу натыкаюсь на фейл. Изображения с камер то появляются, то исчезают, framerate скачет от 0 до 100, кошмар. Расследование показало, что часть usb портов на моем компе подключены к одной шине через внутренний хаб, из-за чего скорость шины делится между несколькими портами и ее уже не хватает на битрейт камер. Втыкание камер в разные порты компа в разных комбинациях показало, что у меня всего 4 независимых usb шины. Пришлось найти материнку с 8-ю шинами, что было довольно непростым квестом.
Продолжаю нагрузочный тест. На этот раз все камеры подключились и выдают нормальные потоки, но сразу сталкиваюсь со следующей проблемой – низкий fps. Процессор загружен на 100% и успевает обрабатывать лишь 8-10 кадров в секунду с каждой из восьми вебок.
Похоже, нужно оптимизировать код. Узким местом оказалось Гауссово размытие (оно и не удивительно, ведь нужно на каждый пиксель кадра производить свертку с матрицей 9*9). Уменьшение ядра не спасало ситуацию. Пришлось искать другой метод нахождения центров пятен на кадрах.
Решение удалось найти внезапно во встроенной в OpenCV функции SimpleBlobDetector. Она делает прямо то, что мне нужно и очень быстро. Преимущество достигается благодаря последовательной бинаризации изображения с разными порогами и поиску контуров. Результат – максимальные 30 fps при загрузке процессора меньше 40%. Нагрузочный тест пройден!
Классификация по цвету
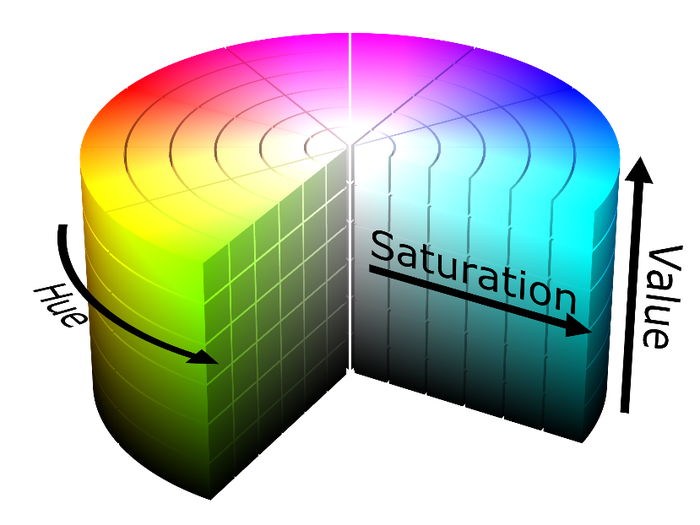
Следующая задача – классификация маркера по его цвету. Усредненное значение цвета по пикселям пятна дает RGB компоненты, которые очень нестабильны и сильно меняются в зависимости от расстояния до камеры и яркости светодиода. Но есть отличное решение: перевод из RGB пространства с HSV (hue, saturation, value). В таком представлении пиксель вместо «красный», «синий», «зеленый», раскладывается на компоненты «тон», «насыщенность», «яркость». В этом случае насыщенность и яркость можно просто исключить и классифицировать только по тону.
И так, на данный момент я научился находить и идентифицировать маркеры на кадрах с большого количества камер. Теперь можно перейти к следующему этапу – трекингу в пространстве.
Я использовал pinhole модель камеры, в которой все лучи падают на матрицу через точку, находящуюся на фокусном расстоянии от матрицы.
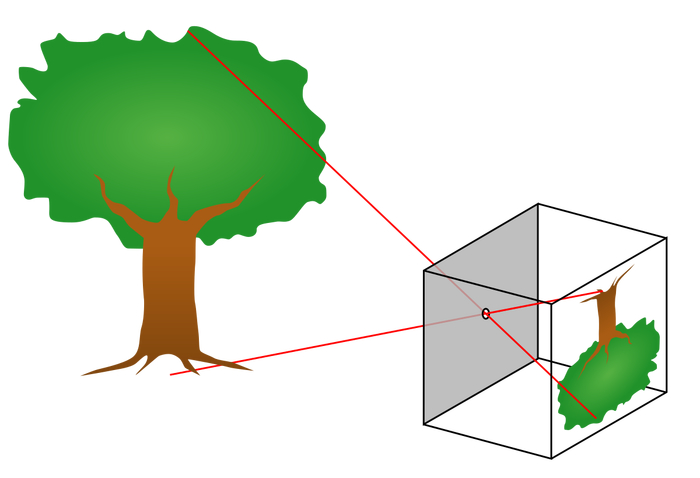
По этой модели будет происходить преобразование двухмерных координат точки на кадре в трехмерные уравнения прямой в пространстве.
Для отслеживания 3D координат маркера нужно получить минимум две скрещивающиеся прямые в пространстве от разных камер и найти точку их пересечения. Увидеть маркер двумя камерами не сложно, но для построения этих прямых нужно, чтобы система знала все о подключенных камерах: где они висят, под какими углами, фокусное расстояние каждого объектива. Проблема в том, что все это неизвестно. Для вычисления параметров требуется некая процедура калибровки.
В первом варианте решил сделать калибровку трекинга максимально примитивной.
1) Вешаю первый блок из восьми камер на потолок, подключаю их к системнику, висящему там же, направляю камеры так, чтобы ими покрывался максимальный игровой объем.
2) С помощью лазерного нивелира и дальномера измеряю XYZ координаты всех камер в единой системе координат
3) Для вычисления ориентаций и фокусных расстояний камер, измеряю координаты специальных стикеров. Стикеры вешаю следующим образом:
В интерфейсе отображения картинки с камеры рисую две точки. Одну в центре кадра, другую в 200 пикселях справа от центра:

Если смотреть на кадр, эти точки падают куда-то на стену, пол или любой другой объект внутри помещения. Вешаю в соответствующие места бумажные наклейки и рисую на них точки маркером.
Измеряю XYZ координаты этих точек с помощью тех же нивелира и дальномера. Итого для блока из восьми камер нужно измерить координаты самих камер и еще по две точки на каждую. Т.е. 24 тройки координат. А таких блоков должно быть около десяти. Получается долгая муторная работа. Но ничего, позже сделаю калибровку автоматизированной.
Запускаю процесс расчета на основе измеренных данных.
Есть две системы координат: одна глобальная, связанная с помещением, другая локальная для каждой камеры. В моем алгоритме результатом для каждой камеры должна получиться матрица 4*4, содержащая ее местоположение и ориентацию, позволяющая преобразовать координаты из локальной в глобальную систему.
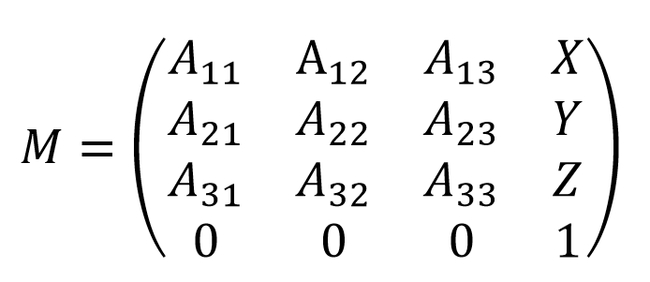
1) Берем исходную матрицу с нулевыми поворотами и смещением.
2) Берем единичный вектор в локальной системе камеры, который смотрит из объектива вперед и преобразуем его в глобальные координаты по исходной матрице.
3) Берем другой вектор в глобальной системе, который из камеры смотрит на центральную точку на стене.
4) С помощью градиентного спуска поворачиваем исходную матрицу так, чтобы после преобразования эти векторы были сонаправлены. Таким образом, мы зафиксировали направление камеры. Осталось зафиксировать вращение вокруг этого направления. Для этого и измерялась вторая точка в 200 пикселях от центра кадра. Поворачиваем матрицу вокруг главной оси, пока два вектора не станут достаточно параллельны.
5) По расстоянию между этими двумя точками вычисляю фокусное расстояния в пикселях (учитывая, что расстояние между проекциями этих точек на кадре составляет 200 пикселей).
Наверняка эту задачу можно было решить аналитически, но для простоты я использовал численное решение на градиентном спуске. Это не страшно, т.к. вычисления будут проводиться один раз после монтажа камер.
Для визуализации результатов калибровки я сделал 2D интерфейс с картой, на которой скрипт рисует метки камер и направления, в которых они видят маркеры. Треугольником обозначаются ориентации камер и углы обзора.
Можно приступать к запуску визуализации, которая покажет правильно ли определились ориентации камер и правильно ли интерпретируются кадры. В идеале, линии, идущие из значков камер должны пересекаться в одной точке.
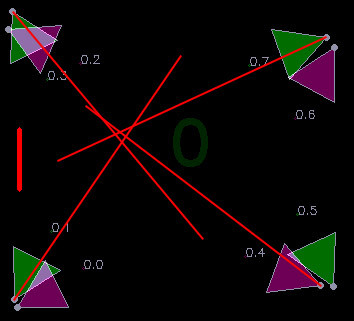
Похоже на правду, но точность явно могла быть выше. Первая причина несовершенства, которая пришла в голову – искажения в объективах камер. Значит, нужно эти искажения как-то компенсировать.
У идеальной камеры важный для меня параметр только один – фокусное расстояние. У реальной кривой камеры нужно учитывать еще дисторсии объектива и смещение центра матрицы.
Для измерения этих параметров есть стандартная процедура калибровки, в процессе которой измеряемой камерой делают набор фотографий шахматной доски, на которых распознаются углы между квадратами с субпиксельной точностью.

Результатом калибровки является матрица, содержащая фокусные расстояния по двум осям и смещение матрицы относительно оптического центра. Все это измеряется в пикселях.
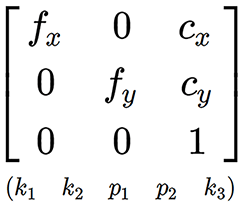
А также вектор коэффициентов дисторсии, который позволяет компенсировать искажения объектива с помощью преобразований координат пикселей.
Применяя преобразования с этими коэффициентами к координатам маркера на кадре, можно привести систему к модели идеальной pinhole камеры.
Провожу новый тест трекинга:
Уже гораздо лучше! Выглядит настолько хорошо, что даже вроде будет работать.
Вычисление координат маркера
И так, я получил кучу прямых, разбросанных по пространству, на пересечениях которых должны находиться маркеры. Только вот прямые в пространстве на самом деле не пересекаются, а скрещиваются, т.е. проходят на некотором расстоянии друг от друга. Моя задача – найти точку, максимально близкую к обеим прямым. Формально говоря, нужно найти середину отрезка, являющегося перпендикуляром к обеим прямым.
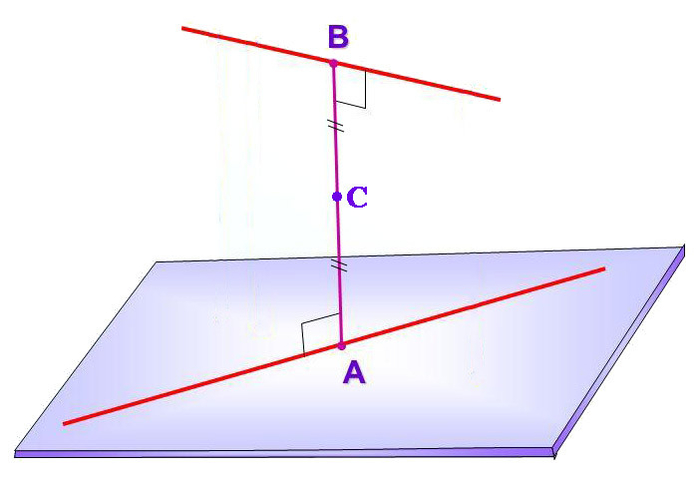
Длина отрезка AB тоже пригодится, т.к. она отражает «качество» полученного результата. Чем он короче, тем ближе друг к другу прямые, тем лучше результат.
Затем я написал алгоритм трекинга, который попарно вычисляет пересечения прямых (внутри одного цвета, от камер, находящихся на достаточном расстоянии друг от друга), ищет лучшее и использует его как координаты маркера. На следующих кадрах старается использовать ту же пару камер, чтобы избежать скачка координат при переходе на трекинг другими камерами.
Параллельно, при разработке костюма с датчиками, я обнаружил странное явление. Все датчики показывали разные значения угла рысканья (направления в горизонтальной плоскости), как будто у каждого был свой север. В первую очередь полез проверять не ошибся ли я в алгоритмах фильтрации данных или в разводке платы, но ничего не нашел. Потом решил посмотреть на сырые данные магнитометра и увидел проблему.
Магнитное поле в нашем помещении было направлено ВЕРТИКАЛЬНО ВНИЗ! Видимо, это связано с железом в конструкции здания.
Но ведь в VR очках тоже используется магнитометр. Почему у них такого эффекта нет? Иду проверять. Оказалось, что в очках он тоже есть… Если сидеть неподвижно, можно заметить, как виртуальный мир медленно, но верно вращается вокруг тебя в рандомную сторону. За минут 10 он уезжает почти на 180 градусов. В нашей игре это неминуемо приведет к рассинхрону виртуальной и реальной реальностей и сломанным об стены очкам.
Похоже, что помимо координат очков, придется определять и их направление в горизонтальной плоскости. Решение напрашивается само – ставить на очки не один, а два одинаковых маркера. Оно позволит определять направление с точностью до разворота на 180 градусов, но с учетом наличия встроенных инерциальных датчиков, этого вполне достаточно.

Система в целом работала, хоть и с небольшими косяками. Но было принято решение запустить квест, который как раз был близок к завершению нашим gamedev разработчиком, присоединившимся к нашей миникоманде. Была затречена вся игровая площадь, установлены двери с датчиками и магнитными замками, изготовлено два интерактивных предмета:

Игроки надевали очки, костюмы и рюкзаки-компьютеры и заходили в игровую зону. Координаты трекинга отсылались им по wi-fi и применялись для позиционирования виртуального персонажа. Все работало достаточно неплохо, посетители довольны. Приятнее всего было наблюдать ужас и крики особо впечатлительных посетителей в моменты, когда на них из темноты нападали виртуальные призраки =)

Внезапно нам прилетел заказ на большой VR шутер на 8 игроков с автоматами в руках. А это 16 объектов, которые нужно тречить. Повезло, что сценарий предполагал возможность разделения трекинга на две зоны по 4 игрока, поэтому я решил, что проблем не будет, можно принимать заказ и ни о чем не волноваться. Протестировать систему в домашних условиях было невозможно, т.к. требовалась большая площадь и много оборудования, которое будет куплено заказчиком, поэтому до монтажа я решил потратить время на автоматизацию калибровки трекинга.
Первым делом нужно было централизовать всю систему. Вместо разделения игровой зоны на блоки по 8 камер, я сделал единый сервер, на который приходили координаты точек на кадрах всех камер сразу.
1) вешаю камеры и на глаз направляю их в игровую область
2) запускаю режим записи на сервере, в котором все приходящие с камер 2D точки сохраняются в файл
3) хожу по темной игровой локации с маркером в руках
4) останавливаю запись и запускаю расчет калибровочных данных, при котором вычисляются расположения, ориентации и фокусные расстояния всех камер.
5) в результате предыдущего пункта получается единое пространство, наполненное камерами. Т.к. это пространство не привязано к реальным координатам, оно имеет случайное смещение и поворот, которое я вычитаю вручную.
Пришлось перелопатить огромное количество материала по линейной алгебре и написать многие сотни строк питонского кода. Настолько много, что я уже почти не помню как оно работает.

Вот так выглядит напечатанная на принтере специальная палка-калибровалка.
Тестирование большого проекта
Проблемы начались во время тестирования на объекте за пару недель до запуска проекта. Идентификация 8-ми разных цветов маркеров работала ужасно, тестовые игроки постоянно телепортировались друг в друга, некоторые цвета вообще не отличались от внешних засветок в помещении торгового комплекса. Тщетные попытки что-то исправить с каждой бессонной ночью все сильнее вгоняли меня в отчаяние. Все это осложнялось нехваткой производительности сервера при расчете десятков тысяч прямых в секунду.
Когда уровень кортизола в крови превысил теоретический максимум, я решил посмотреть на проблему с другой стороны. Как можно сократить количество разноцветных точек, не сокращая количество маркеров? Сделать трекинг активным. Пускай у каждого игрока, например, левый рог всегда корит красным. А второй иногда загорается зеленым по приходу команды с сервера так, что в один момент времени он горит только у одного игрока. Получается, что зеленая лампочка будет как-будто перепрыгивать с одного игрока на другого, обновляя привязку трекинга к красной лампочке и обнуляя ошибку ориентации магнитометра.
Для этого пришлось бежать в ближайший чипидип, покупать светодиоды, провода, транзисторы, паяльник, изоленту и на соплях навешивать функционал управления светодиодами на плату костюма, которая на это рассчитана не была. Хорошо, что при разводке платы я на всякий случай повесил пару свободных ног stm-ки на контактные площадки.

Алгоритмы трекинга пришлось заметно усложнить, но в итоге все заработало! Телепортации игроков друг в друга исчезли, нагрузка на процессор упала, засветки перестали мешать.
Проект был успешно запущен, первым делом я сделал новые платы костюмов с поддержкой активного трекинга, и мы произвели обновление оборудования.
Чем все закончилось?
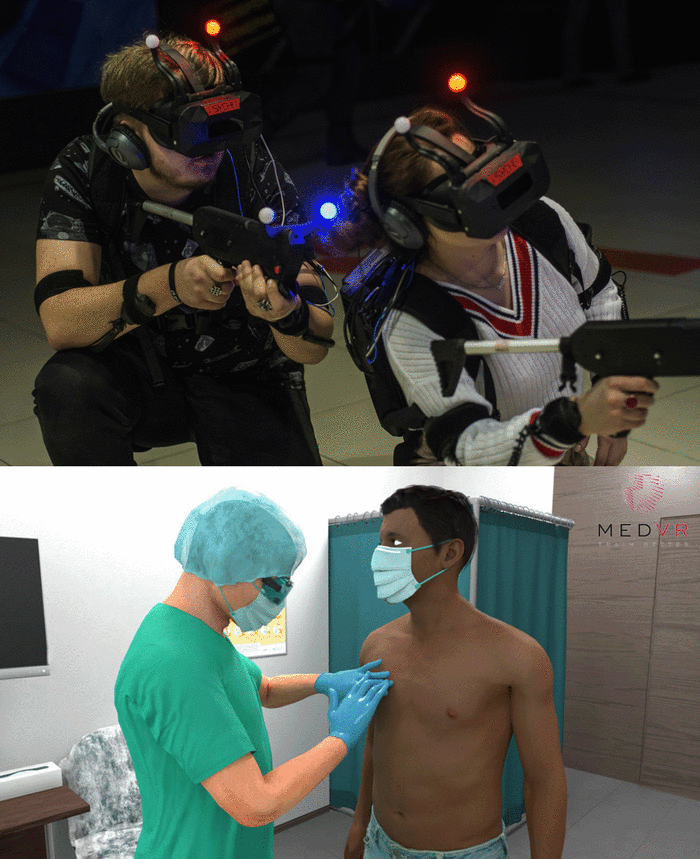
За 3 года мы открыли множество развлекательных точек по всему миру, но коронавирус внес свои коррективы, что дало нам возможность сменить направление работы в более общественно-полезную сторону. Теперь мы довольно успешно занимаемся разработкой медицинских симуляторов в VR. Команда у нас все еще маленькая и мы активно стремимся расширять штат. Если среди читателей есть опытные разработчики под UE4, ищущие работу, пожалуйста, напишите мне.
Традиционный забавный момент в конце статьи:
Периодически при тестах с большим количеством игроков возникал глюк, при котором игрока внезапно на короткое время телепортировало на высоту несколько метров, что вызывало соответствующую реакцию. Дело оказалось в том, что моя модель камеры предполагала пересечение матрицы с бесконечной прямой, идущей от маркера. Но она не учитывала, что у камеры есть перед и зад, так что система искала пересечение бесконечных прямых, даже если точка находится за камерой. Поэтому возникали ситуации, когда две разные камеры видели два разных маркера, но система думала, что это один маркер на высоте в несколько метров.
Система в прямом смысле работала через задницу =)

Вот уже на протяжении нескольких лет Тимофей, преподаватель кафедры информатики МФТИ, выкладывает свои лекции по программированию на своём Youtube канале с открытым доступом.


Разработка системы заметок с нуля. Часть 2: REST API для RESTful API Service + JWT + Swagger
Продолжаем серию материалов про создание системы заметок. В этой части мы спроектируем и разработаем RESTful API Service на Go cо Swagger и авторизацией. Будет много кода, ещё больше рефакторинга и даже немного интеграционных тестов.
В первой части мы спроектировали систему и посмотрели, какие сервисы требуются для построения микросервисной архитектуры.
Подробности в видео и текстовой расшифровке под ним.
Начнём с макетов интерфейса. Нам нужно понять, какие ручки будут у нашего API и какой состав данных он должен отдавать. Макеты мы будем делать, чтобы понять, какие сущности, поля и эндпоинты нам нужны. Используем для этого онлайн-сервис NinjaMock. Он подходит, если макет надо сделать быстро и без лишних действий.
Страницу регистрации сделаем простую, с четырьмя полями: Name, Email, Password и Repeat Password. Лейблы делать не будем, обойдемся плейсходерами. Авторизацию сделаем по юзернейму и паролю.
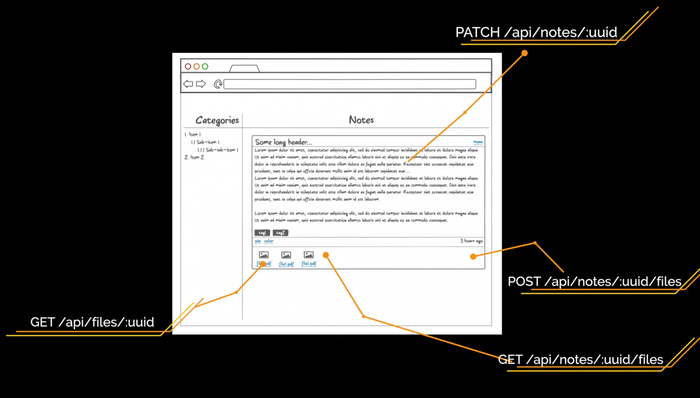
После входа в приложение пользователь увидит список заметок, который будет выглядеть примерно так:
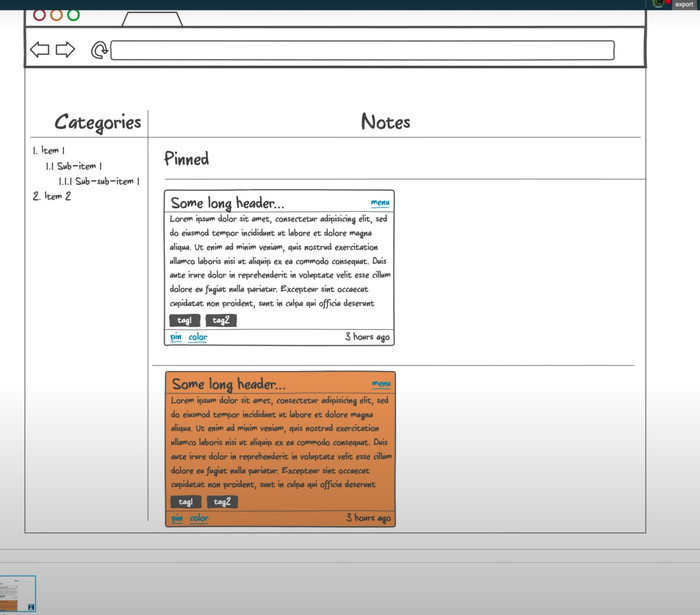
Интерфейс, который будет у нашего веб-приложения:
— Слева — список категорий любой вложенности.
— Справа — список заметок в виде карточек, который делится на два списка: прикреплённые и обычные карточки.
— Каждая карточка состоит из заголовка, который урезается, если он очень длинный.
— Справа указано, сколько секунд/минут/часов/дней назад была создана заметка.
— Тело заголовка — отрендеренный Markdown.
— Панель инструментов. Через неё можно изменить цвет, прикрепить или удалить заметку.
Тут важно отметить, что файлы заметки мы не отображаем и не будем запрашивать у API для списка заметок.
Полная карточка открывается по клику на заметку. Тут можно сразу отобразить полностью длинный заголовок. Высота заметки зависит от количества текста. Для файлов появляется отдельная секция. Мы их будем получать отдельным асинхронным запросом, который не помешает пользователю редактировать заметку. Файлы можно скачать по ссылке, также есть отдельная кнопка на добавление файлов.
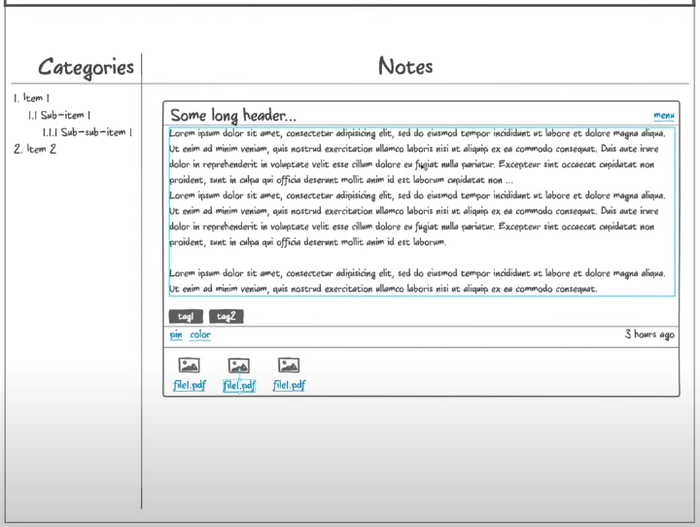
Так будет выглядеть открытая заметка
В ходе прототипирования стало понятно, что в первой части мы забыли добавить еще один микросервис — TagsService. Он будет управлять тегами.
Для страниц авторизации и регистрации нам нужны эндпоинты аутентификации и регистрации соответственно. В качестве аутентификации и сессий пользователя мы будем использовать JWT. Что это такое и как работает, разберём чуть позднее. Пока просто запомните эти 3 буквы.
Для страницы списка заметок нам нужны эндпоинты /api/categories для получения древовидного списка категорий и /api/notes?category_id=? для получения списка заметок текущей категории. Перемещаясь по другим категориям, мы будем отдельно запрашивать заметки для выбранной категории, а на фронтенде сделаем кэш на клиенте. В ходе работы с заметками нам нужно уметь создавать новую категорию. Это будет метод POST на URL /api/categories. Также мы будем создавать новый тег при помощи метода POST на URL /api/tags.

Чтобы обновить заметку, используем метод PATCH на URL /api/notes/:uuid с измененными полями. Делаем PATCH, а не PUT, потому что PUT требует отправки всех полей сущности по спецификации HTTP, а PATCH как раз нужен для частичного обновления. Для отображения заметки нам ещё нужен эндпоинт /api/notes/:uuid/files с методами POST и GET. Также нам нужно скачивать файл, поэтому сделаем метод GET на URL /api/files/:uuid.
Структура репозитория системы
Ещё немного общей информации. Структура репозитория всей системы будет выглядеть следующим образом:
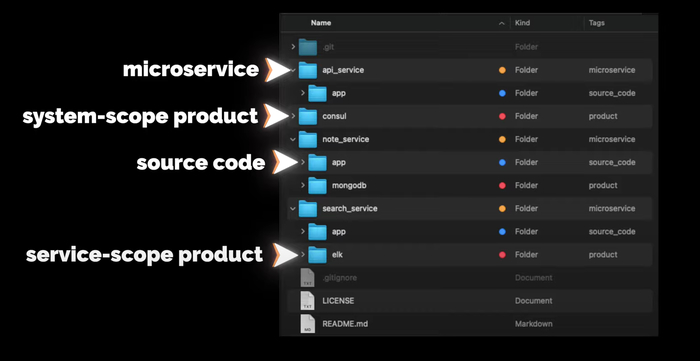
В директории app будет исходный код сервиса (если он будет). На уровне с app будут другие директории других продуктов, которые используются с этим сервисом, например, MongoDB или ELK. Продукты, которые будут использоваться на уровне всей системы, например, Consul, будут в отдельных директориях на уровне с сервисами.
Писать будем на Go
— Идём на официальный сайт.
— Копируем ссылку до архива, скачиваем, проверяем хеш-сумму.
— Распаковываем и добавляем в переменную PATH путь до бинарников Go
— Пишем небольшой тест проверки работоспособности, собираем бинарник и запускаем.
Установка завершена, всё работает
Теперь создаём проект. Структура стандартная:
— cmd — точка входа в приложение,
— internal — внутренняя бизнес-логика приложения,
— pkg — для кода, который можно переиспользовать из проекта в проект.
Я очень люблю логировать ход работы приложения, поэтому перенесу свою обёртку над логером logrus из другого проекта. Основная функция здесь Init, которая создает логер, папку logs и в ней файл all.log со всеми логами. Кроме файла логи будут выводиться в STDOUT. Также в пакете реализована поддержка логирования в разные файлы с разным уровнем логирования, но в текущем проекте мы это использовать не будем.
APIService будет работать на сокете. Создаём роутер, затем файл с сокетом и начинаем его слушать. Также мы хотим перехватывать от системы сигналы завершения работы. Например, если кто-то пошлёт приложению сигнал SIGHUP, приложение должно корректно завершиться, закрыв все текущие соединения и сессии. Хотел перехватывать все сигналы, но линтер предупреждает, что os.Kill и SIGSTOP перехватить не получится, поэтому их удаляем из этого списка.
Теперь давайте добавим сразу стандартный handler для метрик. Я его копирую в директорию pkg, далее добавляю в роутер. Все последующие роутеры будем добавлять так же.
Далее создаём точку входа в приложение. В директории cmd создаём директорию main, а в ней — файл app.go. В нём мы создаём функцию main, в которой инициализируем и создаём логер. Роутер создаём через ключевое слово defer, чтобы метод Init у роутера вызвался только тогда, когда завершится функция main. Таким образом можно выполнять очистку ресурсов, закрытие контекстов и отложенный запуск методов. Запускаем, проверяем логи и сокет, всё работает.
Но для разработки нам нужно запускать приложение на порту, а не на сокете. Поэтому давайте добавим запуск приложения на порту в наш роутер. Определять, как запускать приложение, мы будем с помощью конфига.
Создадим для приложения контекст. Сделаем его синглтоном при помощи механизма sync.Once. Пока что в нём будет только конфиг. Контекст в виде синглтона создаю исключительно в учебных целях, впоследствии он будет выпилен. В большинстве случаев синглтоны — необходимое зло, в нашем проекте они не нужны. Далее создаём конфиг. Это будет YAML-файл, который мы будем парсить в структуру.
В роутере мы вытаскиваем из контекста конфиг и на основании listen.type либо создаем сокет, либо вешаем приложение на порт. Код graceful shutdown выделяем в отдельный пакет и передаём на вход список сигналов и список интерфейсов io.Close, которые надо закрывать. Запускаем приложение и проверяем наш эндпоинт heartbeat. Всё работает. Давайте и конфиг сделаем синглтоном через механизм sync.Once, чтобы потом безболезненно удалить контекст, который создавался в учебных целях.
Теперь переходим к API. Создаём эндпоинты, полученные при анализе прототипов интерфейса. Тут важно отметить, что у нас все данные привязаны к пользователю. На первый взгляд, все ручки должны начинаться с пользователя и его идентификатора /api/users/:uuid. Но у нас будет авторизация, иначе любой пользователь сможет программно запросить заметки любого другого пользователя. Авторизацию можно сделать следующим образом: Basic Auth, Digest Auth, JSON Web Token, сессии и OAuth2. У всех способов есть свои плюсы и минусы. Для этого проекта мы возьмём JSON Web Token.
Работа с JSON Web Token
JSON Web Token (JWT) — это JSON-объект, который определён в открытом стандарте RFC 7519. Он считается одним из безопасных способов передачи информации между двумя участниками. Для его создания необходимо определить заголовок (header) с общей информацией по токену, полезные данные (payload), такие как id пользователя, его роль и т.д., а также подписи (signature).
JWT использует преимущества подхода цифровой подписи JWS (Signature) и кодирования JWE (Encrypting). Подпись не даёт кому-то подделать токен без информации о секретном ключе, а кодирование защищает от прочтения данных третьими лицами. Давайте разберёмся, как они могут нам помочь для аутентификации и авторизации пользователя.
Аутентификация — процедура проверки подлинности. Мы проверяем, есть ли пользователь с полученной связкой логин-пароль в нашей системе.
Авторизация — предоставление пользователю прав на выполнение определённых действий, а также процесс проверки (подтверждения) данных прав при попытке выполнения этих действий.
Другими словами, аутентификация проверяет легальность пользователя. Пользователь становится авторизированным, если может выполнять разрешённые действия.
Важно понимать, что использование JWT не скрывает и не маскирует данные автоматически. Причина использования JWT — проверка, что отправленные данные были действительно отправлены авторизованным источником. Данные внутри JWT закодированы и подписаны, но не зашифрованы. Цель кодирования данных — преобразование структуры. Подписанные данные позволяют получателю данных проверить аутентификацию источника данных.
Реализация JWT в нашем APIService:
— Создаём директории middleware и jwt, а также файл jwt.go.
— Описываем кастомные UserClaims и сам middlware.
— Получаем заголовок Authorization, оттуда берём токен.
— Берём секрет из конфига.
— Создаём верификатор HMAC.
— Парсим и проверяем токен.
— Анмаршалим полученные данные в модель UserClaims.
— Проверяем, что токен валидный на текущий момент.
При любой ошибке отдаём ответ с кодом 401 Unauthorized. Если ошибок не было, в контекст сохраняем ID пользователя в параметр user_id, чтобы во всех хендлерах его можно было получить. Теперь надо этот токен сгенерировать. Это будет делать хендлер авторизации с методом POST и эндпоинтом /api/auth. Он получает входные данные в виде полей username и password, которые мы описываем отдельной структурой user. Здесь также будет взаимодействие с UserService, нам надо там искать пользователя по полученным данным. Если такой пользователь есть, то создаём для него UserClaims, в которых указываем все нужные для нас данные. Определяем время жизни токена при помощи переменной ExpiresAt — берём текущее время и добавляем 15 секунд. Билдим токен и отдаём в виде JSON в параметре token. Клиента к UserService у нас пока нет, поэтому делаем заглушку.
Добавим в хендлер с heartbeat еще один тестовый хендлер, чтобы проверить работу аутентификации. Пишем небольшой тест. Для этого используем инструмент sketch, встроенный в IDE. Делаем POST-запрос на /api/auth, получаем токен и подставляем его в следующий запрос. Получаем ответ от эндпоинта /api/heartbeat, по истечении 5 секунд мы начнём получать ошибку с кодом 401 Unauthorized.
Наш токен действителен очень ограниченное время. Сейчас это 15 секунд, а будет минут 30. Но этого всё равно мало. Когда токен протухнет, пользователю необходимо будет заново авторизовываться в системе. Это сделано для того, чтобы защитить пользовательские данные. Если злоумышленник украдет токен авторизации, который будет действовать очень большой промежуток времени или вообще бессрочно, то это будет провал.
Чтобы этого избежать, прикрутим refresh-токен. Он позволит пересоздать основной токен доступа без запроса данных авторизации пользователя. Такие токены живут очень долго или вообще бессрочно. После того как только старый JWT истекает мы больше не можем обратиться к API. Тогда отправляем refresh-токен. Нам приходит новая пара токена доступа и refresh-токена.
Хранить refresh-токены на сервере мы будем в кэше. В качестве реализации возьмём FreeCache. Я использую свою обёртку над кэшем из другого проекта, которая позволяет заменить реализацию FreeCache на любую другую, так как отдает интерфейс Repository с методами, которые никак не связаны с библиотекой.
Пока рассуждал про кэш, решил зарефакторить существующий код, чтобы было удобней прокидывать объекты без dependency injection и синглтонов. Обернул хендлеры и роутер в структуры. В хендлерах сделал интерфейс с методом Register, которые регистрируют его в роутере. Все объекты теперь инициализируются в main, весь роутер переехал в мейн. Старт приложения выделили в отдельную функцию также в main-файле. Теперь, если хендлеру нужен какой-то объект, я его просто буду добавлять в конструктор структуры хендлера, а инициализировать в main. Плюс появилась возможность прокидывать всем хендлерам свой логер. Это будет удобно когда надо будет добавлять поле trace_id от Zipkin в строчку лога.
Вернемся к refresh_token. Теперь при создании токена доступа создадим refresh_token и отдадим его вместе с основным. Сделаем обработку метода PUT для эндпоинта /api/auth, а в теле запроса будем ожидать параметр refresh_token, чтобы сгенерировать новую пару токена доступа и refresh-токена. Refresh-токен мы кладём в кэш в качестве ключа. Значением будет user_id, чтобы по нему можно было запросить данные пользователя у UserService и сгенерировать новый токен доступа. Refresh-токен одноразовый, поэтому сразу после получения токена из кэша удаляем его.
Для описания нашего API будем использовать спецификацию OpenAPI 3.0 и Swagger — YAML-файл, который описывает все схемы данных и все эндпоинты. По нему очень легко ориентироваться, у него приятный интерфейс. Но описывать вручную всё очень муторно, поэтому лучше генерировать его кодом.
— Создаём эндпоинты /api/auth с методами POST и PUT для получения токена по юзернейму и паролю и по Refresh-токену соответственно.
— Добавляем схемы объектов Token и User.
— Создаём эндпоинты /api/users с методом POST для регистрации нового пользователя. Для него создаём схему CreateUser.
Понимаем, что забыли сделать хендлер для регистрации пользователя. Создаём метод Signup у хенлера Auth и структуру newUser со всеми полями для регистрации. Генерацию JWT выделяем в отдельный метод, чтобы можно было его вызывать как в Auth, так и в Signup-хендлерах. У нас всё еще нет UserService, поэтому проставляем TODO. Нам надо будет провалидировать полученные данные от пользователя и потом отправить их в UserService, чтобы он уже создал пользователя и ответил нам об успехе. Далее вызываем функцию создания пары токена доступа и refresh-токена и отдаём с кодом 201.
У нас есть подсказка в виде Swagger-файла. На его основе создаём все нужные хендлеры. Там, где вызов микросервисов, будем проставлять комментарий с TODO.
Создаём хендлер для категорий, определяем URL в константах. Далее создаём структуры. Опираемся на Swagger-файл, который создали ранее. Далее создаём сам хендлер и реализуем метод Register, который регистрирует его в роутере. Затем создаём методы с логикой работы и сразу пишем тест API на этот метод. Проверяем, находим ошибки в сваггере. Таким образом мы создаём все методы по работе с категориями: получение и создание.
Далее создаём таким же образом хендлер для заметок. Понимаем, что забыли методы частичного обновления и удаления как для заметок, так и для категорий. Дописываем их в Swagger и реализуем методы в коде. Также обязательно тестируем Swagger в онлайн-редакторе.
Здесь надо обратить внимание на то, что методы создания сущности возвращают код ответа 201 и заголовок Location, в котором находится URL для получения сущности. Оттуда можно вытащить идентификатор созданной сущности.
В третьей части мы познакомимся с графовой базой данных Neo4j, а также будем работать над микросервисами CategoryService и APIService.