Selenium для Python. Глава 2. Первые Шаги
Продолжение перевода неофициальной документации Selenium для Python.
Перевод сделан с разрешения автора Baiju Muthukadan.
Оригинал можно найти здесь.
Содержание:
2. Первые шаги
2.1. Простое использование
Если вы установили привязку Selenium к Python, вы можете начать использовать ее с помощью интерпретатора Python.
Код выше может быть сохранен в файл (к примеру, python_org_search.py), и запущен:
Запускаемый вами Python должен содержать установленный модуль selenium.
2.2. Пошаговый разбор примера
Модуль selenium.webdriver предоставляет весь функционал WebDriver’а. На данный момент WebDriver поддерживает реализации Firefox, Chrome, Ie и Remote. Класс Keys обеспечивает взаимодействие с командами клавиатуры, такими как RETURN, F1, ALT и т.д…
Далее создается элемент класса Firefox WebDriver.
Метод driver.get перенаправляет к странице URL в параметре. WebDriver будет ждать пока страница не загрузится полностью (то есть, событие “onload” игнорируется), прежде чем передать контроль вашему тесту или скрипту. Стоит отметить, что если страница использует много AJAX-кода при загрузке, то WebDriver может не распознать, загрузилась ли она полностью:
Следующая строка — это утверждение (англ. assertion), что заголовок содержит слово “Python” [assert позволяет проверять предположения о значениях произвольных данных в произвольном месте программы. По своей сути assert напоминает констатацию факта, расположенную посреди кода программы. В случаях, когда произнесенное утверждение не верно, assert возбуждает исключение. Такое поведение позволяет контролировать выполнение программы в строго определенном русле. Отличие assert от условий заключается в том, что программа с assert не приемлет иного хода событий, считая дальнейшее выполнение программы или функции бессмысленным — Прим. пер.]:
WebDriver предоставляет ряд способов получения элементов с помощью методов find_element_by_*. Для примера, элемент ввода текста input может быть найден по его атрибуту name методом find_element_by_name. Подробное описание методов поиска элементов можно найти в главе Поиск Элементов:
После этого мы посылаем нажатия клавиш (аналогично введению клавиш с клавиатуры). Специальные команды могут быть переданы с помощью класса Keys импортированного из selenium.webdriver.common.keys:
После ответа страницы, вы получите результат, если таковой ожидается. Чтобы удостовериться, что мы получили какой-либо результат, добавим утверждение:
В завершение, окно браузера закрывается. Вы можете также вызывать метод quit вместо close. Метод quit закроет браузер полностью, в то время как close закроет одну вкладку. Однако, в случае, когда открыта только одна вкладка, по умолчанию большинство браузеров закрывается полностью:
2.3. Использование Selenium для написания тестов
Selenium чаще всего используется для написания тестовых ситуаций. Сам пакет selenium не предоставляет никаких тестовых утилит или инструментов разработки. Вы можете писать тесты с помощью модуля Python unittest. Другим вашим выбором в качестве тестовых утилит/инструментов разработки могут стать py.test и nose.
В этой главе, в качестве выбранной утилиты будет использоваться unittest. Ниже приводится видоизмененный пример с использованием этого модуля. Данный скрипт тестирует функциональность поиска на сайте python.org:
Вы можете запустить тест выше из командной строки следующей командой:
Результат сверху показывает, что тест завершился успешно.
2.4. Пошаговый разбор примера
Сначала были импортированы все основные необходимые модули. Модуль unittest встроен в Python и реализован на Java’s JUnit. Этот модуль предоставляет собой утилиту для организации тестов.
Модуль selenium.webdriver предоставляет весь функционал WebDriver’а. На данный момент WebDriver поддерживает реализации Firefox, Chrome, Ie и Remote. Класс Keys обеспечивает взаимодействие с командами клавиатуры, такими как RETURN, F1, ALT и т.д…
Класс теста унаследован от unittest.TestCase. Наследование класса TestCase является способом сообщения модулю unittest, что это тест:
setUp — это часть инициализации, этот метод будет вызываться перед каждым методом теста, который вы собираетесь написать внутри класса теста. Здесь мы создаем элемент класса Firefox WebDriver.
Далее описан метод нашего теста. Метод теста всегда должен начинаться с фразы test. Первая строка метода создает локальную ссылку на объект драйвера, созданный методом setUp.
Метод driver.get перенаправляет к странице URL в параметре. WebDriver будет ждать пока страница не загрузится полностью (то есть, событие “onload” игнорируется), прежде чем передать контроль вашему тесту или скрипту. Стоит отметить, что если страница использует много AJAX-кода при загрузке, то WebDriver может не распознать, загрузилась ли она полностью:
Следующая строка — это утверждение, что заголовок содержит слово “Python”:
WebDriver предоставляет ряд способов получения элементов с помощью методов find_element_by_*. Для примера, элемент ввода текста input может быть найден по его атрибуту name методом find_element_by_name. Подробное описание методов поиска элементов можно найти в главе Поиск Элементов:
После этого мы посылаем нажатия клавиш (аналогично введению клавиш с клавиатуры). Специальные команды могут быть переданы с помощью класса Keys импортированного из selenium.webdriver.common.keys:
После ответа страницы, вы получите результат, если таковой ожидается. Чтобы удостовериться, что мы получили какой-либо результат, добавим утверждение:
Метод tearDown будет вызван после каждого метода теста. Это метод для действий чистки. В текущем методе реализовано закрытие окна браузера. Вы можете также вызывать метод quit вместо close. Метод quit закроет браузер полностью, в то время как close закроет одну вкладку. Однако, в случае, когда открыта только одна вкладка, по умолчанию большинство браузеров закрывается полностью.:
Завершающий код — это стандартная вставка кода для запуска набора тестов [Сравнение __name__ с «__main__» означает, что модуль (файл программы) запущен как отдельная программа («main» (англ.) — «основная», «главная») (а не импортирован из другого модуля). Если вы импортируете модуль, атрибут модуля __name__ будет равен имени файла без каталога и расширения — Прим. пер.]:
2.5. Использование Selenium с remote WebDriver
Строка выше сообщает о том, что вы можете использовать указанный URL для подключения remote WebDriver. Ниже приводится несколько примеров:
Переменная desired_capabilities — это словарь. Вместо того, чтобы использовать словари по умолчанию, вы можете явно прописать значения:
Python для микроконтроллеров. Учимся программировать одноплатные компьютеры на языке высокого уровня

Содержание статьи
С чего все началось?
Все началось с кампании на Kickstarter. Дэмьен Джордж (Damien George), разработчик из Англии, спроектировал микроконтроллерную плату, предназначенную специально для Python. И кампания «выстрелила». Изначально была заявлена сумма в 15 тысяч фунтов стерлингов, но в результате было собрано в шесть с половиной раз больше — 97 803 фунта стерлингов.
А чем эта плата лучше?
Автор проекта приводил целый ряд преимуществ своей платформы в сравнении с Raspberry Pi и Arduino:
Мощность — MP мощнее в сравнении с микроконтроллером Arduino, здесь используются 32-разрядные ARM-процессоры типа STM32F405 (168 МГц Cortex-M4, 1 Мбайт флеш-памяти, 192 Кбайт ОЗУ).
Простота в использовании — язык MicroPython основан на Python, но несколько упрощен, для того чтобы команды по управлению датчиками и моторами можно было писать буквально в несколько строк.
Отсутствие компилятора — чтобы запустить программу на платформе MicroPython, нет необходимости устанавливать на компьютер дополнительное ПО. Плата определяется ПК как обычный USB-накопитель — стоит закинуть на него текстовый файл с кодом и перезагрузить, программа тут же начнет исполняться. Для удобства все-таки можно установить на ПК эмулятор терминала, который дает возможность вписывать элементы кода с компьютера непосредственно на платформу. Если использовать его, тебе даже не придется перезагружать плату для проверки программы, каждая строка будет тут же исполняться микроконтроллером.
Низкая стоимость — в сравнении с Raspberry Pi платформа PyBoard несколько дешевле и, как следствие, доступнее.
И что, только официальная плата?
Нет. При всех своих достоинствах PyBoard (так называется плата от разработчика MicroPython) — довольно дорогое удовольствие. Но благодаря открытой платформе на многих популярных платах уже можно запустить MicroPython, собранный специально для нее. В данный момент существуют версии:
Подготовка к работе
Перед тем как писать программы, нужно настроить плату, установить на нее прошивку, а также установить на компьютер необходимые программы.
Все примеры проверялись и тестировались на следующем оборудовании:
Прошивка контроллера
Для прошивки платы нам понадобится Python. Точнее, даже не он сам, а утилита esptool, распространяемая с помощью pip. Если у тебя установлен Python (неважно, какой версии), открой терминал (командную строку) и набери:
После установки esptool надо сделать две вещи. Первое — скачать с официального сайта версию прошивки для ESP8266. И второе — определить адрес платы при подключении к компьютеру. Самый простой способ — подключиться к компьютеру, открыть Arduino IDE и посмотреть адрес в списке портов.
Открываем терминал (командную строку) и переходим на рабочий стол:
Форматируем флеш-память платы:
Если при форматировании возникли ошибки, значит, нужно включить режим прошивки вручную. Зажимаем на плате кнопки reset и flash. Затем отпускаем reset и, не отпуская flash, пытаемся отформатироваться еще раз.
И загружаем прошивку на плату:
Взаимодействие с платой
Все взаимодействие с платой может происходить несколькими способами:
При подключении через Serial-порт пользователь в своем терминале (в своей командной строке) видит практически обычный интерпретатор Python.
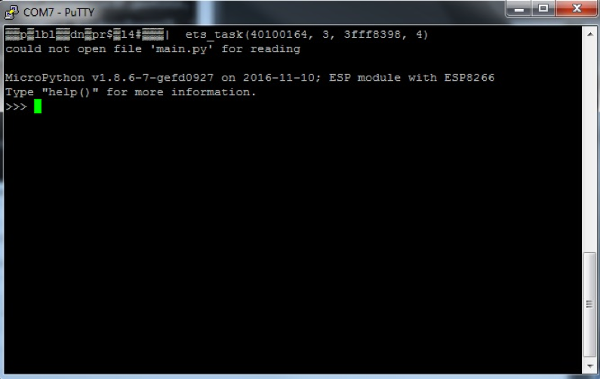 Подключение через SerialPort
Подключение через SerialPort
Для подключения по Serial есть разные программы. Для Windows можно использовать PuTTY или TeraTerm. Для Linux — picocom или minicom. В качестве кросс-платформенного решения можно использовать монитор порта Arduino IDE. Главное — правильно определить порт и указать скорость передачи данных 115200.
Кроме этого, уже создано и выложено на GitHub несколько программ, облегчающих разработку, например EsPy. Кроме Serial-порта, он включает в себя редактор Python-файлов с подсветкой синтаксиса, а также файловый менеджер, позволяющий скачивать и загружать файлы на ESP.
Но все перечисленные способы хороши лишь тогда, когда у нас есть возможность напрямую подключиться к устройству с помощью кабеля. Но плата может быть интегрирована в какое-либо устройство, и разбирать его только для того, чтобы обновить программу, как-то неоптимально. Наверное, именно для таких случаев и был создан WebREPL. Это способ взаимодействия с платой через браузер с любого устройства, находящегося в той же локальной сети, если у платы нет статического IP, и с любого компьютера, если такой IP присутствует. Давай настроим WebREPL. Для этого необходимо, подключившись к плате, набрать
Появится сообщение о статусе автозапуска WebREPL и вопрос, включить или выключить его автозапуск.
После ввода q появляется сообщение о выставлении пароля доступа:
Вводим его, а затем подтверждаем. Теперь после перезагрузки мы сможем подключиться к плате по Wi-Fi.
Так как мы не настроили подключение платы к Wi-Fi-сети, она работает в качестве точки доступа. Имя Wi-Fi-сeти — MicroPython-******, где звездочками я заменил часть MAC-адреса. Подключаемся к ней (пароль — micropythoN ).
Открываем WebREPL и нажимаем на Connect. После ввода пароля мы попадаем в тот же интерфейс, что и при прямом подключении. Кроме этого, в WebREPL есть интерфейс для загрузки файлов на плату и скачивания файлов на компьютер.
Среди файлов, загруженных на плату, есть стандартные:
Начинаем разработку
Hello world
Принято, что первой написанной на новом языке программирования должна быть программа, выводящая Hello world. Не будем отходить от традиции и выведем это сообщение с помощью азбуки Морзе.
Итак, что же происходит? Сначала подключаются библиотеки: стандартная Python-библиотека time и специализированная machine. Эта библиотека отвечает за взаимодействие с GPIO. Стандартный встроенный светодиод располагается на втором пине. Подключаем его и указываем, что он работает на выход. Если бы у нас был подключен какой-нибудь датчик, то мы бы указали режим работы IN.
Следующие две функции отвечают за включение и выключение светодиода на определенный интервал времени. Наверное, интересно, почему я сначала выключаю светодиод, а потом включаю? Мне тоже очень интересно, почему сигнал для данного светодиода инвертирован. Оставим это на совести китайских сборщиков. На самом деле команда pin.off() включает светодиод, а pin.on() — отключает.
Ну а дальше все просто: заносим в переменную Hello_world нашу строчку, записанную кодом Морзе, и, пробегаясь по ней, вызываем ту или иную функцию.
Продолжение доступно только участникам
Вариант 1. Присоединись к сообществу «Xakep.ru», чтобы читать все материалы на сайте
Членство в сообществе в течение указанного срока откроет тебе доступ ко ВСЕМ материалам «Хакера», позволит скачивать выпуски в PDF, отключит рекламу на сайте и увеличит личную накопительную скидку! Подробнее
Могут ли драйверы Windows быть написаны на Python?
могут ли драйверы Windows быть написаны на Python?
7 ответов
помимо драйверов времени загрузки, вы также не можете писать драйверы UMDF, которые:
окончательный ответ не без встраивания интерпретатора в ваш в противном случае драйвер c/assembly. Если у кого-то есть рамки, то ответ нет. Как только у вас есть интерпретатор и привязки на месте, остальная часть логики может быть выполнена в Python.
однако написание драйверов является одной из вещей, для которых C лучше всего подходит. Я предполагаю, что полученный код Python будет выглядеть очень похоже на код C и победит цель интерпретатора накладные расходы.
например, вы должны решить для каждой функции (и действительно для каждой инструкции по сборке), находится ли она в подкачиваемой или не подкачиваемой памяти. Это требует расширения до C, тщательного использования новых функций C++ или в этом случае специального расширения для язык Python и виртуальная машина. Кроме того, ваша совместимая с драйверами виртуальная машина также должна иметь дело с различными IRQLs-существует иерархия «уровней», которые ограничивают то, что вы можете и не можете сделать.
Python работает на виртуальной машине, поэтому нет.
вы можете написать компилятор, который переводит код Python на машинный язык. Как только вы это сделаете, вы сможете это сделать.
Я не знаю ограничений на драйверы в windows (схемы выделения памяти, динамическая загрузка библиотек и все), но вы можете встроить интерпретатор python в свой драйвер, и в этот момент Вы можете делать все, что захотите. Не думаю, что это хорошая идея 🙂
никогда не говори никогда, Но да.. нет!—1—>
вы можете взломать что-то вместе, чтобы запустить пользовательские части драйверов в python. Но материал в режиме ядра может быть выполнен только в C или сборке.
нет они не могут. Драйверы Windows должны быть написаны на языке, который может
опять же, ничто не мешает вам написать компилятор, который переводит python в машинный код;)
Программирование с PyUSB 1.0
От переводчика:
Это перевод руководства Programming with PyUSB 1.0
Данное руководство написано силами разработчиков PyUSB, однако быстро пробежавшись по коммитам я полагаю, что основной автор руководства — walac.
Позвольте мне представиться
PyUSB 1.0 — это библиотека Python обеспечивающая легкий доступ к USB. PyUSB предоставляет различные функции:
Довольно разговоров, давайте писать код!
Кто есть кто
Для начала, давайте дадим описание модулям PyUSB. Все модули PyUSB находятся под пекетом usb, с последующими модулями:
| Модуль | Описание |
|---|---|
| core | Основной модуль USB. |
| util | Вспомогательные функции. |
| control | Стандартные запросы управления. |
| legacy | Слой совместимости с версиями 0.x. |
| backend | Субпакет содержащий встроенные бэкенды. |
К примеру, чтобы импортировать модуль core, введите следующее:
Ну что ж начнём
Далее следует простенькая программа, которая посылает строку ‘test’ в первый найденный источник данных (endpoint OUT):
Первые две строки импортируют модули пакета PyUSB. usb.core — основной модуль, а usb.util содержит вспомогательные функции. Следующая команда ищет наше устройство и возвращает экземпляр объекта, если находит. Если нет, возвращается None. Далее, мы устанавливаем конфигурацию, которую будем использовать. Заметьте: отсутствие аргументов означает, что нужная конфигурация была проставлена по-умолчанию. Как Вы увидите, во многих функциях PyUSB есть настройки по-умолчанию для большинства распространенных устройств. В этом случае, ставится первая найденная конфигурация.
Затем, мы ищем конечную точку в которой заинтересованы. Мы ищем ее внутри первого интерфейса, который у нас есть. После того как нашли эту точку мы посылаем в неё данные.
Если нам заранее известен адрес конечной точки, мы можем просто вызвать функцию write объекта device:
Здесь мы пишем строку ‘test’ в контрольную точку под адресом 1. Все эти функции будут разобраны лучше в последующих разделах.
Что не так?
Каждая функция в PyUSB вызывает исключение в случае ошибки. Помимо стандартных исключений Python, PyUSB определяет usb.core.USBError для ошибок связанных с USB.
Вы также можете использовать функции лога PyUSB. Он использует модуль logging. Для его использования определите переменную окружения PYUSB_DEBUG с одним из следующих уровней логирования: critical, error, warning, info или debug.
По-умолчанию сообщения посылаются в sys.stderr. Если хотите, Вы можете перенаправить сообщения лога в файл определив переменную окружения PYUSB_LOG_FILENAME. Если её значение — корректный путь к файлу, сообщения будут записываться туда, иначе они будут посылаться в sys.stderr.
Где ты?
Функция find() в модуле core используется чтобы найти и пронумеровать устройства присоединенные к системе. К примеру, скажем что у нашего устройства есть vendor ID со значением 0xfffe и product ID равный 0x0001. Если нам нужно найти это устройство мы сделаем так:
Вот и всё, функция возвратит объект usb.core.Device, который представляет наше устройство. Если устройство не найдено оно возвратит None. На самом деле Вы можете использовать любое поле класса Device Descriptor, которое хотите. К примеру, что если мы захотим узнать есть ли USB-принтер подключенный к системе? Это очень легко:
7 — это код для класса принтеров в соответствии со спецификацией USB. О, постойте, что если я хочу пронумеровать все имеющиеся принтеры? Без проблем:
Что случилось? Что ж, время для небольшого объяснения… у find есть параметр, который называется find_all и по-умолчанию имеет значение False. Когда он имеет ложное значение [1], find будет возвращать первое устройство, которое подходит под указанные критерии (скоро об этом поговорим). Если Вы передадите параметру истинное значение, find вместо этого возвратит список из всех устройств подходящих по критериям. Вот и всё! Просто, не правда ли?
Мы закончили? Нет! Я ещё не всё рассказал: многие устройства на самом деле ставят свою информацию о классе в Interface Descriptor вместо Device Descriptor. Так что, чтобы по-настоящему найти все принтеры подключенные к системе, нам нужно будет перебрать все конфигурации, а также все интерфейсы и проверить — выставлено ли у одного из интерфейсов в bInterfaceClass значение 7. Если Вы программист как и я Вы можете задаться вопросом: есть ли путь полегче с помощью которого это можно реализовать. Ответ: да, он есть. Для начала давайте посмотрим на готовый код нахождения всех подключенных принтеров:
Параметр custom_match принимает любой вызываемый объект, который получает объект устройства. Он должен возвращать истинное значение для подходящего устройства и ложное — для неподходящего. Вы также можете скомбинировать custom_match с полями устройства, если захотите:
Здесь нас интересуют принтеры поставщика 0xfffe.
Опиши себя
Ок, мы нашли наше устройство, но перед тем как с ним взаимодействовать, нам хотелось бы узнать больше о нём. Ну Вы знаете, конфигурации, интерфейсы, конечные точки, типы потоков данных…
Если у Вас есть устройство, Вы можете получить доступ к любому полю дескриптора устройства как к свойствам объекта:
Для доступа к имеющимся конфигурациям в устройстве, Вы можете итерировать устройство:
Таким же образом Вы можете итерировать конфигурацию для доступа к интерфейсам, а также итерировать интерфейсы для доступа к их контрольным точкам. У каждого типа объекта есть поля соответствующего дескриптора как атрибуты. Взглянем на пример:
Вы также можете использовать индексы для произвольного доступа к дескрипторам, как здесь:
Как вы можете увидеть индексы отсчитываются с 0. Но постойте! Есть что-то странное в том, как я получаю доступ к интерфейсу… Да, Вы правы, индекс для Configuration принимает ряд из двух значений, из которых первый — это индекс Interface’а, а второй — альтернативная настройка. В общем, чтобы получить доступ к первому интерфейсу, но со второй настройкой, мы напишем cfg[(0,1)].
Теперь время научиться мощному способу поиска дескрипторов — полезной функции find_descriptor. Мы уже видели её в примере поиска принтеров. find_descriptor работает практически также как и find, с двумя исключениями:
Заметьте, что find_descriptor находится в модуле usb.util. Он также принимает описанный ранее параметр custom_match.
Имеем дело с множественными идентичными устройствами
Иногда у Вас может быть два идентичных устройства подсоединенных к компьютеру. Как Вы можете различать их? Объекты Device идут с двумя дополнительными атрибутами, которые не являются частью спецификации USB, но очень полезны: атрибуты bus и address. Прежде всего, стоит сказать, что эти атрибуты идут от бэкенда, а бэкенд может и не поддерживать их — в этом случае они выставлены на None. Тем не менее эти атрибуты представляют номер и адрес шины устройства и, как Вы могли уже догадаться, могут быть использованы для того, чтобы различать два устройства с одинаковыми значениями атрибутов idVendor и idProduct.
Как я должен работать?
Устройства USB после подсоединения должны конфигурироваться с помощью нескольких стандартных запросов. Когда я начал изучать спецификацию USB, я был обескуражен дексрипторами, конфигурациями, интерфейсами, альтернативными настройками, типами передачи и всем этим… И что самое худшее — Вы не можете просто игнорировать их: устройство не работает без установки конфигурации, даже если оно одно! PyUSB пытается сделать Вашу жизнь настолько проще, насколько это возможно. К примеру, после получения Вашего объекта устройства, первым делом, перед тем как взаимодействовать с ним, нужно отправить запрос set_configuration. Параметр конфигурации для этого запроса, который Вас интересует — bConfigurationValue. У большинства устройств есть не более одной конфигурации, а отслеживание значения конфигурации для использования раздражает (хотя большинство кода, который я видел просто жестко кодировали это). Следовательно, в PyUSB, Вы можете просто отправить запрос set_configuration без аргументов. В этом случае он установит первую найденную конфигурацию (если у Вашего устройства она всего одна, Вам вообще не надо беспокоиться о значении конфигурации). К примеру, представим, что у Вас устройство с одним декриптором конфигурации, а его поле bConfigurationValue равно 5 [3], последующие запросы будут работать одинаково:
Вау! Вы можете использовать объект Configuration как параметр для set_configuration! Да, также у него есть метод set для конфигурации самого себя в текущую конфигурацию.
Другая опция, которую Вам нужно или не нужно будет настроить — опция смены интерфейсов. Каждое устройство может иметь только одну активированную конфигурацию в один момент, и у каждой конфигурации может быть больше чем один интерфейс, а Вы можете использовать все интерфейсы в одно и то же время. Вам лучше понять эту концепцию, если Вы думаете о интерфейсе как о логическом устройстве. К примеру, давайте представим многофункциональный принтер, который в одно и то же время и принтер, и сканер. Чтобы не усложнять (или по крайней мере делать настолько просто насколько возможно), давайте будем считать, что у него есть всего одна конфигурация. Т.к. у нас есть принтер и сканер у конфигурации есть 2 интерфейса: один для принтера и один для сканера. Устройство с более чем одним интерфейсом называется композитным устройством. Когда Вы подключаете Ваш многофункциональный принтер к Вашему компьютеру, Операционная Система загрузит два разных драйвера: один для каждого «логического» периферического устройства, которое у Вас есть [4].
Что насчёт альтернытивных настроек интерфейса? Хорошо, что Вы спросили. У интерфейса есть один или более альтернытивных настроек. Интерфейс у которого только одна альтернативная настройка рассматривается как не имеющий альтернативных настроек [5]. Альтернативные настройки для интерфейсов как конфигурации для устройств, то есть на каждый интерфейс у Вас может быть только одна активная альтернативная настройка. К примеру, спецификация USB говорит о том, что у устройства не может быть изохронной контрольной точки в его основной альтернативной настройке [6], так что потоковое устройство должно иметь как минимум две альтернативные настройки, со второй настройкой, имеющей изохронную контрольную точку. Но, в отличии от конфигураций, интерфейсы только с одной альтернативной настройкой не нуждается в настройке [7]. Вы выбираете альтернативную настройку интерфейса с помощью функции set_interface_altsetting:
Спецификация USB говорит, что устройству позволяется возвращать ошибку в случае, если оно получает запрос SET_INTERFACE к интерфейсу у которого нет дополнительных альтернативных настроек. Так что, если Вы не уверены в том, что интерфейс имеет более одной альтернативной настройки или в том, что он принимает запрос SET_INTERFACE, наиболее безопасным методом будет вызвать set_interface_altsetting внутри блока try-except, как здесь:
Вы также можете использовать объект Interface как параметр функции, параметры interface и alternate_setting автоматически наследуются от полей bInterfaceNumber и bAlternateSetting. Пример:
Объект Interface должен принадлежать активному дескриптору конфигурации.
Поговори со мной, милая
А теперь для нас настало время понять как взаимодействовать c USB устройствами. У USB есть четыре типа потоков данных: массовый (bulk transfer), прерывающийся (interrupt transfer), изохронный (isochronous transfer) и управляющий (control transfer). Я не планирую объяснять назначение каждого потока и различия между ними. Поэтому я предполагаю, что у Вас есть по крайней мере базовые знания о потоках данных USB.
Управляющий поток данных — единственный поток, структура которого описана в спецификации, остальные просто отправляют и получают необработанные данные с точки зрения USB. Поэтому у Вас есть различные функции для работы с управляющими потоками, а остальные потоки обрабатываются одними и теми же функциями.
Вы можете обратиться к управляющему потоку данных посредством метода ctrl_transfer. Он используется как для исходящих (OUT) так и для входящих (IN) потоков. Направление потока определяет параметр bmRequestType.
Параметры ctrl_transfer практически совпадают со структурой управляющего запроса. Далее следует пример того, как организовывать управляющий поток данных [8]:
В этом примере предполагается, что наше устройство включает в себя два пользовательских управляющих запроса, которые действуют как loopback pipe. То, что Вы пишете с сообщением CTRL_LOOPBACK_WRITE, Вы можете прочитать с сообщением CTRL_LOOPBACK_READ.
Первые четыре параметра — bmRequestType, bmRequest, wValue и wIndex — поля стандартной структуры управляющего потока. Пятый параметр — это либо пересылаемые данные для исходящего потока данных или кол-во считываемых данных во входящем потоке. Пересылаемые данные могут быть любым типом последовательности, которая может быть подана в качестве параметра на вход метода __init__ для массива. Если нет пересылаемых данных параметр должен иметь значение None (или 0 в случае входящего потока данных). Есть ещё один опциональный параметр указывающий таймаут операции. Если Вы не передаете его, будет использоваться таймаут по-умолчанию (больше об этом дальше). В исходящем потоке данных возвращаемое значение — это количество байтов, реально посылаемое устройству. Во входящем потоке возвращаемое значение — массива со считанными данными.
Для других потоков Вы можете использовать методы write и read, соответственно, чтобы записывать и считывать данные. Вам не нужно беспокоиться о типе потока — он автоматически определяется по адресу контрольной точки. Вот наш пример loopback при условии, что у нас есть loopback pipe в контрольной точке 1:
Первый и третий параметры одинаковы для обоих методов — это адрес контрольной точки и таймаут, соответственно. Второй параметр — пересылаемые данные (write) или количество байтов для считывания (read). Возвращенными данными будут либо экземпляр объекта массива для метода read, либо количество записанных байтов для метода write.
С бета 2 версии вместо количества байтов, Вы можете передать для read или ctrl_transfer объект массива, в который данные будут считываться. В этом случае, количество байтов для считывания будет длиной массива умноженной на значение array.itemsize.
В ctrl_transfer, параметр timeout опционален. Когда timeout опущено, используется свойство Device.default_timeout как операционный таймаут.
Контролируй себя
Кроме функций потоков данных модуль usb.control предоставляет функции, которые включают в себя стандартные управляющие запросы USB, а в модуле usb.util есть удобная функция get_string специально выводящая дескрипторы строк.
Дополнительные темы
За каждой великой абстракцией стоит великая реализация
Раньше был только libusb. Потом пришел libusb 1.0 и у нас были libusb 0.1 и 1.0. После этого мы создали OpenUSB и сейчас мы живем в Вавилонской Башне USB-библиотек [9]. Как PyUSB справляется с этим? Что ж, PyUSB — демократичная библиотека, Вы можете выбрать какую хотите бибилиотеку. На самом деле Вы можете написать вашу собственную библиотеку USB с нуля и сказать PyUSB использовать её.
Функция find имеет ещё один параметр, о котором я Вам не рассказал. Это параметр backend. Если Вы его не передаете — будет использоваться один из встроенных бэкендов. Бэкенд — это объект унаследованный от usb.backend.IBackend, ответственный за введение специфического для операционной системы хлама USB. Как Вы могли догадаться, встроенные libusb 0.1, libusb 1.0 и OpenUSB — бэкенды.
Вы можете написать свой собственный бэкенд и использовать его. Просто наследуйте от IBackend и включите необходимые методы. Вам может понадобиться посмотреть в документацию usb.backend, чтобы понять как это делается.
Не будьте эгоистичны
У Python есть то, что мы называем автоматическое управление памятью. Это значит, что виртуальная машина будет решать когда выгрузить объекты из памяти. Под капотом PyUSB управляет всеми низко-уровневыми ресурсами, с которыми необходимо работать (утверждение интерфейса, регулировки устройства, и т.д.) и большинству пользователей не нужно беспокоиться об этом. Но, из-за непредопределенной природы автоматического уничтожения объектов Python’ом, пользователи не могут предсказать когда выделенные ресурсы будут освобождены. Некоторые приложения нуждаются в том, чтобы выделить и освободить ресурсы детерминировано. Для таких приложений модуль usb.util предоставляет функции для взаимодействия с управлением ресурсами.
Если Вы хотите запрашивать и освобождать интерфейсы вручную, Вы можете использовать функции claim_interface и release_interface. Функция claim_interface будет запрашивать указанный интерфейс, если устройство до сих пор этого не сделало. Если устройство уже запросило интерфейс, она ничего не делает. Так же release_interface будет освобождать указанный интерфейс, если он запрошен. Если интерфейс не запрошен, она ничего не делает. Вы можете использовать ручное запрашивание интерфейсов, чтобы решить описанную в документации libusb проблему выбора конфигурации.
Если Вы хотите освободить все ресурсы выделенные объектом устройства (включая запрошенные интерфейсы), Вы можете использовать функцию dispose_resources. Она освобождает все выделенные ресурсы и переводит объект устройства (но не в аппаратные средства устройства самого по себе) в то состояние, в котором оно было возвращено после использования функции find.
Определение библиотек вручную
В общем, бэкенд — это обертка над общей библиотекой, которая реализует API для доступа к USB. По-умолчанию, бэкенд использует ctypes функцию find_library(). На Linux и других Unix-подобных Операционных Системах, find_library пытается запустить внешние программы (такие как /sbin/ldconfig, gcc и objdump) в целях нахождения файла библиотеки.
В системах в которых эти программы отсутствуют и/или кэш библиотек отключен, эта функция не может использоваться. Чтобы преодолеть ограничения, PyUSB позволяет Вам подавать пользовательскую функцию find_library() на бэкенд.
Примером такого сценария будет:
Заметьте, что find_library — аргумент для функции get_backend(), в котором Вы поставляете функцию, которая ответственная за поиск правильной библиотеки для бэкенда.
Правила старой школы
Если Вы пишите приложение используя старые API PyUSB (0.что-то-там), Вы можете спрашивать себя, нужно ли Вам обновить Ваш код, чтобы использовать новый API. Что ж, Вам стоит это сделать, но это не обязательно. PyUSB 1.0 идет вместе с модулем совместимости usb.legacy. Он включает в себя старое API на основе нового API. «Что ж, должен ли я просто заменить мою строчку import usb на import usb.legacy as usb чтобы заставить моё приложение работать?», спросите Вы. Ответ — да, это будет работать, но это не обязательно. Если Вы запустите свое приложение неизмененным оно будет работать, потому что строчка import usb импортирует все публичные символы из usb.legacy. Если Вы сталкиваетесь с проблемой — скорее всего Вы нашли баг.
Помогите мне, пожалуйста
Если Вас нужна помощь, не пишите мне на e-mail, для этого есть список рассылки. Инструкции по подписке могут быть найдены на сайте PyUSB.
[1] Когда я пишу True или False (с большой буквы), я имею ввиду соответственные значения языка Python. А когда я говорю истинно (true) или ложно (false), я имею ввиду любое выражение Python, которое расценивается как истинное или ложное. (Данное сходство имело место в оригинале и помогает понять понятия истинного и ложного в переводе. — Прим.пер.):
[2] Смотрите конкретную документацию бэкенда.
[3] Спецификация USB не навязывает какое-либо определенное значение для значения конфигурации. То же истинно для номеров интерфейса и альтернативной настройки.
[4] На самом деле всё немного сложнее, но этого просто объяснения для нас хватит.
[5] Я знаю, что это звучит странно.
[6] Это потому, что если нету пропускной способности для изохронных потоков данных во время конфигурации устройства, оно может быть успешно пронумеровано.
[7] Этого не происходит для конфигурации, потому что устройству разрешено быть в несконфигурированном состоянии.
[8] В PyUSB управляющие потоки данных обращаются к контрольной точке 0. Очень очень очень редко устройство имеет альтернативную управляющую контрольную точку (Я никогда не встречал такого устройства).
[9] Это просто шутка, не принимайте это всерьез. Большой выбор лучше, чем без выбора.