Текст в PDF: как редактировать в ABBYY Finereader
Современные компьютерные технологии предлагают массу возможностей для работы с контентом. В частности, существуют различные форматы данных, в том числе и текстовых. Это популярные txt, docx, xlsx и, конечно же, PDF. Последний чаще всего используется для разработки разных документов: от инструкций до договоров. Чтобы работать с этим форматом, нужно использовать специальное ПО, например, купить ABBYY Finereader. Программа позволяет просматривать, сканировать документы. Но можно ли их редактировать, чтобы внести какие-то правки или новые данные?
_09.jpg)
Необходимость в специальной программе для PDF
Документы в данном формате нередко имеют защиту, которая не дает возможности вносить изменения стандартными инструментами. Более того, во многих случаях отсутствует даже возможность полностью скопировать контент, что затрудняет работу. Единственное, что доступно штатными устройствами, будь то браузер или Adobe Reader – это просмотр документа. Именно поэтому нужна специальная программа, представленная выше. Она предназначена для комплексной работы с документами данного формата. Если вы узнаете, как редактировать текст в PDF в ABBYY Finereader, то сможете подготовить файлы под себя или получить из них всю необходимую информацию. Также с ее помощью можно сканировать текст для последующего использования, если речь идет об отсканированных бумажных документах.
Как редактировать текст в PDF?
Чтобы внести правки в документ, вам необходимо сделать следующее:
На этом редактирование PDF в ABBYY Finereader завершено. Убедитесь, что сохранили файл, чтобы все изменения вступили в силу.
Также текстовые данные можно добавлять в документ через специальный инструмент «Текст» (таким способом можно вносить изменения и в отсканированный документ). Для этого сделайте следующее:
Редактирование отсканированных документов
Если PDF-файл не был создан в специальной программе, а представляет собой отсканированный бумажный документ, то вы также можете вносить изменения. Для этого повторите действия, описанные выше. При этом программа будет пытаться оптимизировать текст, если у него искажены буквы или выбрана неправильная ориентация. Учтите, что если документ низкого качества, то изменить текст после сканирования будет проблематично, поскольку будут видны неровности. Поэтому старайтесь использовать качественно отсканированные материалы.
Изменение текста в документе – не единственное, на что способен редактор ABBYY Finereader. Программа также может сканировать печатные материалы и конвертировать их в цифровые, проводить сравнение документов, создавать PDF-файлы с защитой, обрабатывать документы и многое другое. Все это делает данный программный продукт очень полезным и обязательным к приобретению.
Как пользоваться Abbyy Finereader
Перевод текста в цифровой формат — довольно распространенная задача для тех, кто работает с документами. Программа Abbyy Finereader поможет сохранить немало времени, автоматически переводя надписи из растровых картинок или «читалок» в редактируемый текст.
В данной статье рассмотрим, как использовать Abbyy Finereader для распознавания текстов.
Как распознать текст с картинки при помощи Abbyy Finereader
Для того, чтобы распознать текст на растровом изображении, достаточно просто загрузить его в программу, и Abbyy Finereader автоматически распознает текст. Вам остается только редактировать его, выделив нужное и сохранить в требуемом формате или скопировать в текстовый редактор.
Распознать текст можно прямо с подключенного сканера.
Более подробно читайте на нашем сайте.
Как создать документ PDF и FB2 при помощи Abbyy Finereader
Программа Abbyy Finereader позволяет конвертировать изображения в универсальный формат PDF и формат FB2 для чтения на электронных книгах и планшетах.
Процесс создания таких документов схож.
1. В главном меню программы выберите раздел E-Book и нажмите FB2. Выберите тип исходного документа — сканирование, документ или фотография.

2. Найдите и откройте требуемый документ. Он загрузится в программу постранично (это может занять некоторое время).
3. Когда процесс распознавания завершится, программа предложит выбрать формат для сохранения. Выбираем FB2. При необходимости, заходим в «Опции» и вводим дополнительную информацию (автор, название, ключевые слова, описание).
После сохранения можно остаться в режиме редактирования текста и перевести его в формат Word или PDF.
Особенности редактирования текста в Abbyy Finereader
Для текста, который распознал Abbyy Finereader предусмотрено несколько опций.
В исходом документе сохраните картинки и колонтитулы, чтобы они перенеслись в новый документ.
Проведите анализ документа, чтобы знать какие ошибки и проблемы могут возникнуть в процессе преобразования.
Редактируйте изображение страницы. Доступны опции кадрирования, фотокоррекции, изменения разрешения.
Вот мы и рассказали как пользоваться Abbyy Finereader. Он обладает довольно широкими возможностями редактирования и конвертирования текстов. Пусть эта программа поможет в создании любых нужных вам документов.
Помимо этой статьи, на сайте еще 12551 инструкций.
Добавьте сайт Lumpics.ru в закладки (CTRL+D) и мы точно еще пригодимся вам.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Инструкция: как редактировать документы и распознавать тексты с иероглифами в ABBYY FineReader 15
PDF-документы давно стали необходимой составляющей офисной работы. В этом формате хранятся цифровые архивы, юристы согласуют договоры, дизайнеры верстают брошюры, издательства публикуют электронные книги. До недавнего времени главным достоинством и одновременно с этим недостатком PDF-документов было отсутствие возможности редактировать текст в них. Благодаря развитию технологий эту и другие задачи научилась решать программа ABBYY FineReader, которая стала многофункциональным редактором любых документов. «Хайтек» вместе с ABBYY рассказывает, как технологически устроено редактирование PDF-документов в новой версии FineReader 15, каким образом программа сравнивает версии документов и как работает распознавание иероглифов с помощью нейросетей.
Читайте «Хайтек» в
Диджитализация документооборота массово началась еще во второй половине ХХ века. Многие предприятия переходили на электронные документы. В офисах устанавливали первые компьютеры со специальным софтом для обработки и хранения важной информации. Тогда и появились популярные текстовые редакторы. Сотрудники набирали вручную документы, а затем, с появлением в 1993 году PDF, стали экспортировать их в этот формат.
На первый взгляд казалось: если весь документооборот станет электронным, то о шкафах с бумажными каталогами и завалах на рабочих столах можно будет забыть. На практике оказалось, что чем больше организация использует компьютеры для цифрового документооборота, тем больше документов она печатает. 64% крупных компаний уверены, что по крайней мере до 2025 года печать будет значимой частью их бизнеса. С другой стороны, если сегодня в офис по традиционной почте приходит бумажный документ, его немедленно отсканируют и переведут в цифру. Как правило, сканы документов хранят в виде PDF-файлов.
Документом в формате PDF удобнее пользоваться — его можно послать по электронной почте с уверенностью, что информация дойдет до адресата без искажений (если, конечно, кто-то не решит внести изменения собственноручно), и, в отличие от DOC, его трудно изменить. Это особенно важно, если речь идет о контрактах или коммерческих предложениях.
Офисные сотрудники отмечают рост объемов использования PDF: каждый второй респондент ответил, что регулярно работает с документами в этом формате и нуждается в специализированной программе. За последние два года количество таких рабочих файлов в мире выросло в три раза — эти данные приводят эксперты IDC в исследовании «Addressing the document disconnect». В России PDF также пользуется популярностью. Также по результатам исследования ABBYY выяснилось, что в наиболее частые сценарии работы с PDF-документами вошли совершенно не типичные для этого формата ранее задачи: 52% респондентов вносят мелкие правки в текст PDF, исправляют ошибки или опечатки; 62% опрошенных часто ищут информацию в тексте PDF и 60% копируют текст из документа. Поэтому от программ, работающих с PDF, требуются новые возможности для редактирования, сравнения и распознавания текстов. Все они есть в новом FineReader 15.
Почему так сложно редактировать текст в PDF?
Изначально PDF не предназначался для того, что его каким-либо образом изменяли. Что было и его преимуществом — это безопасность, одинаковое отображение на любом устройстве и удобный способ обмена информацией, и недостатком — невозможность внесения правок, поиска по тексту и сравнения документов.
Особенности отображения текста в PDF
Несмотря на то, что PDF — это формат текста, в цифровом виде эти буквы, слова и предложения на самом деле не существуют, они «нарисованы». Содержимое хранится в виде потоков — это могут быть текст, изображения и векторная графика. Типичных для формата DOC слов, строчек, абзацев и таблиц в PDF нет. В формате нет и букв как таковых, а есть коды символов. Такие коды с одинаковыми характеристиками объединяются в группы по виду и размеру шрифта. Этот шрифт определяет, как символ должен отображаться в документе, сопоставляя код символа и глиф — набор команд для отрисовки. Еще одно отличие от обычного текстового документа — объекты в PDF существуют в трех измерениях. По координате Z судят о глубине расположения объекта на странице, ведь текст может находиться поверх изображения или наоборот.
Текст в PDF- документе напоминает «мешочек букв», который нужно правильно отобразить в конкретных местах документа с соответствующим форматированием.
С 2008 года PDF стал открытым форматом, что позволило разработчикам без проблем и дополнительных отчислений создавать программы для чтения файлов PDF, конвертеры и другие полезные вещи. Развитие OCR привело к тому, что у ранее неизменного PDF-документа появилась возможность редактирования — сначала построчного, а затем и в пределах абзацев.
Как ABBYY FineReader помогает редактировать PDF
Чтобы редактировать PDF-документ, его необходимо сначала подготовить к этому. Главная задача этого процесса — понять и проанализировать структуру текста. А ключевая сложность — отсутствие как абзацев, так и вообще форматирования в PDF. Поэтому сразу после того, как программа распознала текст, она начинает воссоздавать абзацы.
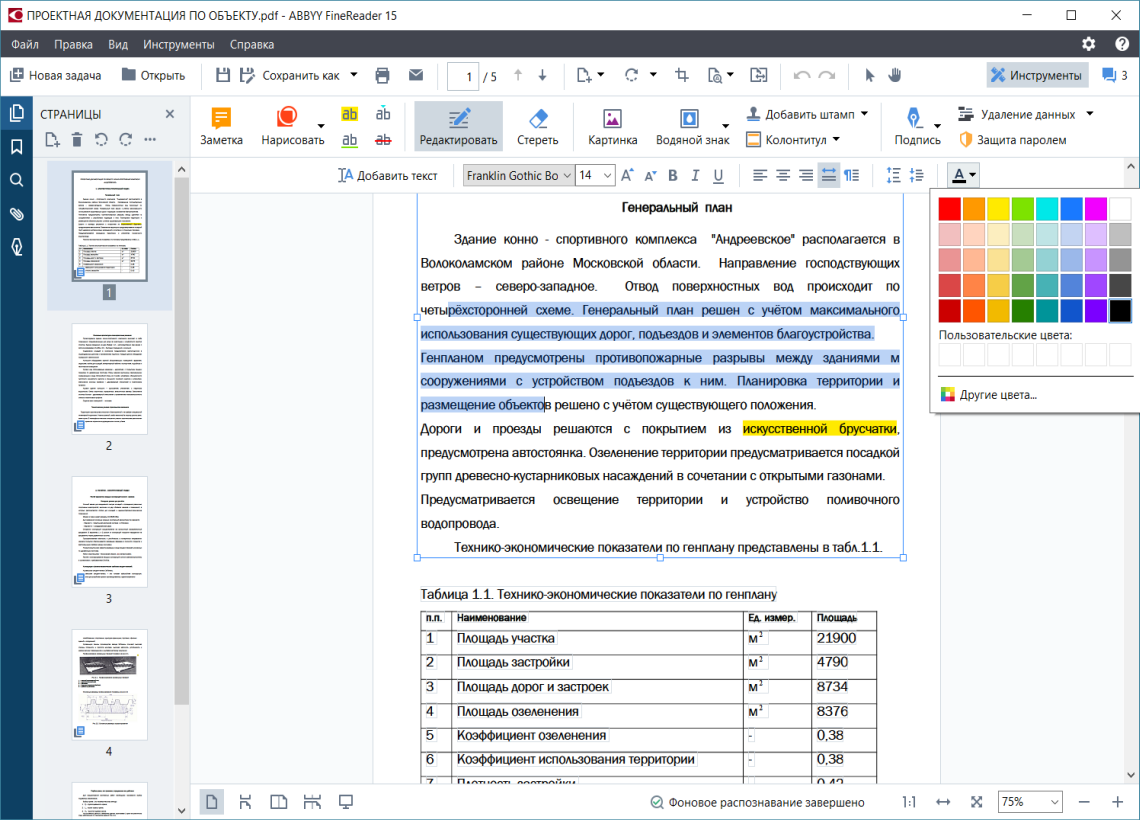
Если речь идет о digital-born-документе (изначально созданный на компьютере, а не отсканированный бумажный документ — «Хайтек»), то в режиме редактирования подключаются фоновые процессы, и программа приступает к анализу структуры документа. Для этого используется технология, которая строит блоки на основе данных, записанных в PDF, а не на основе распознавания. За считанные доли секунды технология должна пройти всю цепочку по определению параметров текста: места, где находятся заголовки, подзаголовки, отдельные абзацы и другие элементы. Потом — распихать «мешочки букв» по этим блокам, сформировать строки.
Следующий этап — синтез. Специальные технологии определяют внешние параметры текста — отступы и межстрочные интервалы. Благодаря этому из хаотичной структуры снова появляется текстовый документ с форматированием. И уже в него можно вносить правки — менять слова и целые абзацы, исправлять форматирование, сохранять изменения и так далее.
Функция построчного редактирования уже была в предыдущей версии FineReader (ABBYY FineReader 14 вышла в январе 2017 года — «Хайтек»). Этого было достаточно, чтобы внести небольшие исправления в текст: заменить несколько букв или цифр. Новый ABBYY FineReader 15 стал универсальным текстовым редактором, в котором вносить изменения можно в целые абзацы.
Как отредактировать текст в отсканированном документе
Отдельная офисная задача — отредактировать скан-копию бумажного документа. Раньше для этого пользователю приходилось конвертировать файл в редактируемый формат или просто искать исходник.
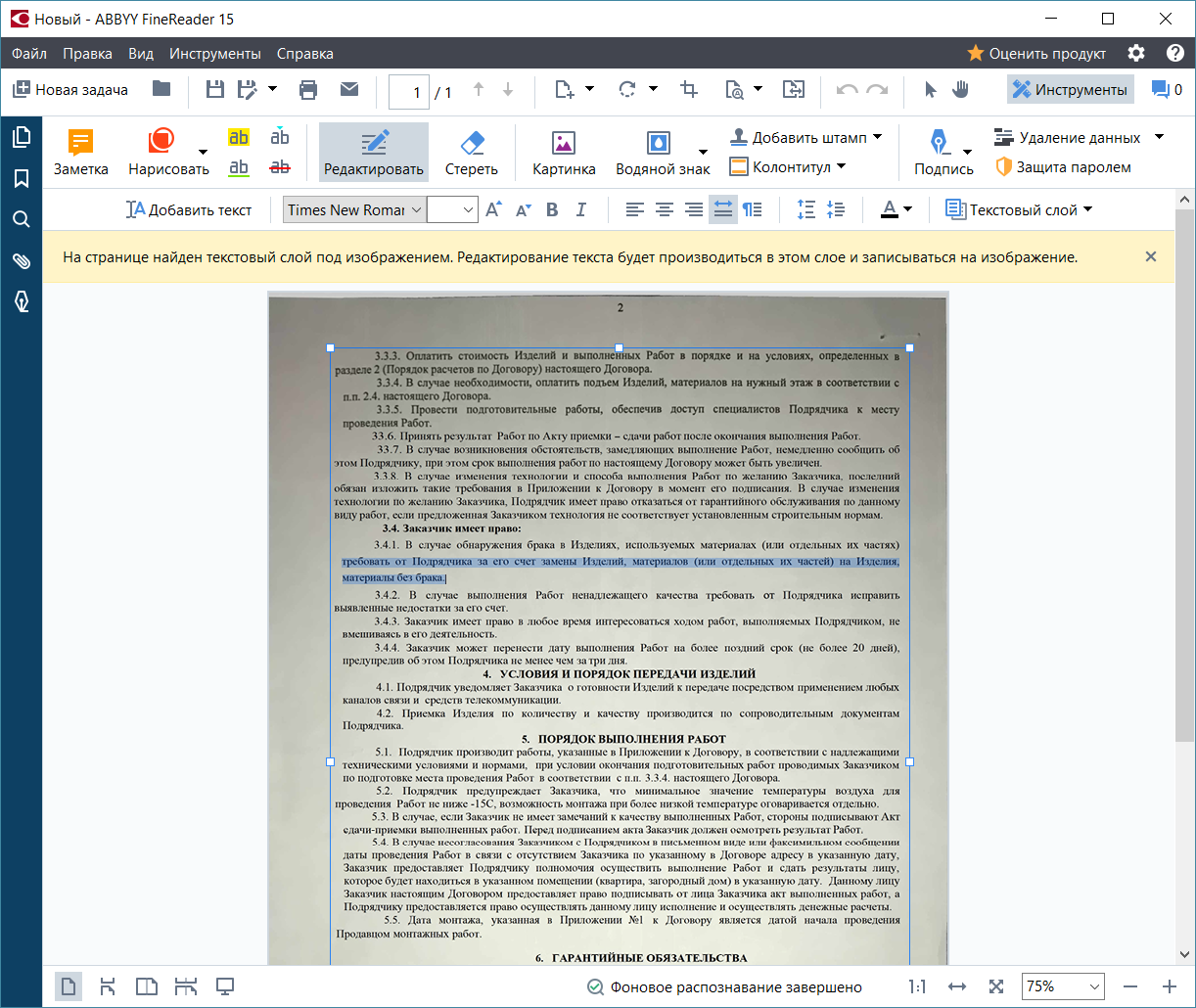
Когда пользователь редактирует скан, ABBYY FineReader 15 в первую очередь распознает документ и создает временный текстовый слой на тех страницах, которые пользователь просматривает. В режиме редактирования создается текстовое представление страницы — именно его редактирует пользователь. Затем эти правки встраиваются в изображение страницы в отсканированном документе.
Как найти в PDF внесенные правки и избежать обмана
Сравнение документов — особо важный для бизнеса сегмент офисных задач. Прежде всего, потому что неожиданные правки могут стоить очень больших денег. Иногда их незаметно пытаются внести в уже подписанный договор и воспользоваться человеческой невнимательностью — такие документы обычно сравнивают юристы, внимательно вычитывая распечатки оригинала, созданного в Word, и ответа контрагента — отсканированный вариант.
Поиск отличий в текстовых документах может быть полезен еще и в том случае, если над ними работают одновременно несколько человек или со временем один и тот же файл периодически изменяют. Это позволяет быстро найти последние правки, которые внесли в файл коллеги. В файлах DOCX для этого есть режим Track Changes, создающий на основе двух версий документа третью — с подсвеченными отличиями в тексте. В новом ABBYY FineReader 15 можно сохранить результаты сравнения любых документов в таком DOCX c Track Changes и в привычном режиме увидеть все различия.
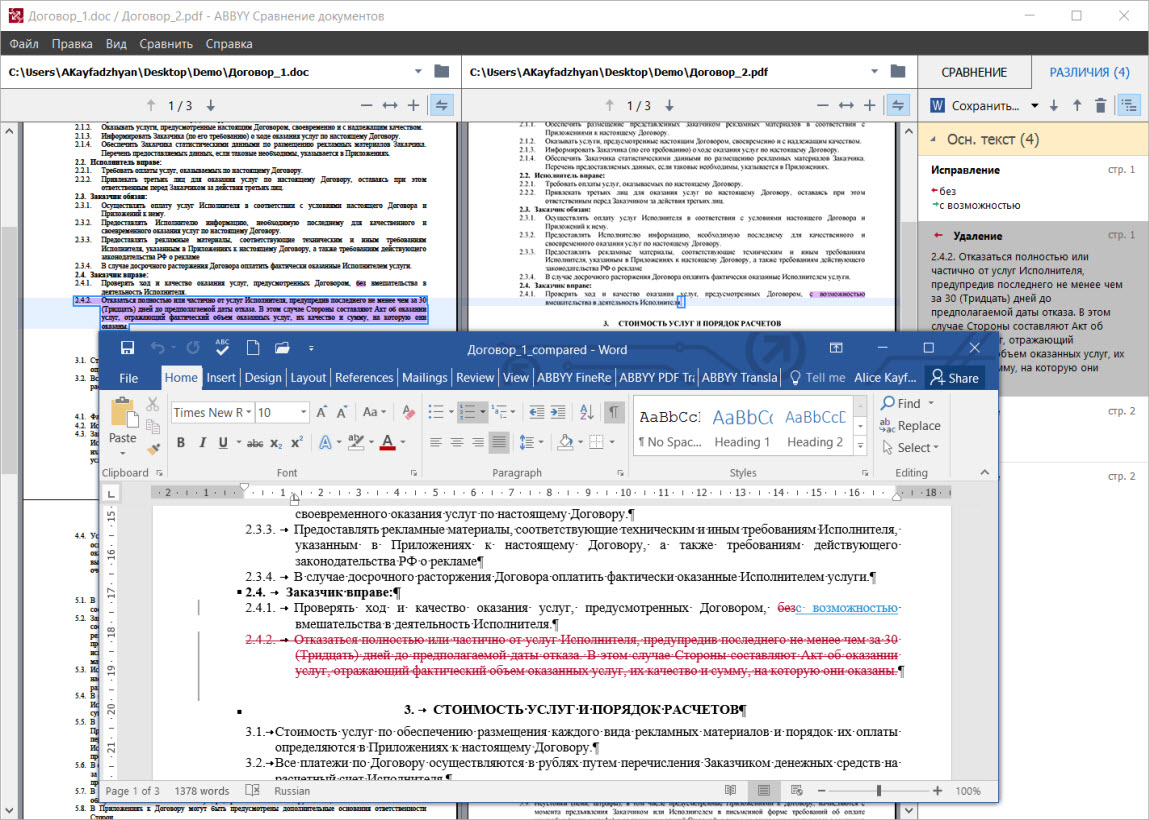
Сравнивать в ABBYY FineReader 15 можно практически что угодно — PDF, сканы или изображения, файлы DOC, DOCX и даже таблицы из Excel. В программу загружаются оба документа, которые при необходимости распознаются с помощью OCR. На основе извлеченного текста в документе определяются дополнительные элементы форматирования — например, колонтитулы, нумерация списков. В программе используется специальный алгоритм, который позволяет быстро выявлять отличия в версиях документов.
Разностный алгоритм принимает два файла на вход. Первый, обычно более ранний — файл А, второй — файл B. Алгоритм определяет количество вставок или удалений, необходимых для превращения одного файла в другой, находя для этого кратчайший путь.
Сравнение проходит в три этапа. Сначала текст, полученный в результате распознавания, разбивается на параграфы. Алгоритм считает, что один параграф — это один объект для сравнения. Все несовпадающие фрагменты обрабатываются во время второго прохода алгоритма — уже по строчкам. Программа определяет, какие строки внутри параграфа совпадают не полностью.
Остается последний проход, уже в рамках несовпадающих строк, который сравнивает отдельные буквы. Этот процесс чуть сложнее: дополнительно используются различные эвристики — варианты распознавания. Если буквы совпадают по вариантам распознавания и процент уверенности распознавания этого элемента превышает 50%, то считается, что они эквивалентны. Не учитываются в качестве различий разные виды кавычек, скобок и маркеры списка.
Для каждого символа существует несколько вариантов распознавания: иногда их число доходит до 20. У каждого из этих вариантов есть процент уверенности, на сколько, по оценке технологии, буква соответствует отсканированному изображению. Затем в ходе анализа документа часть вариантов исключается, так как они не соответствуют эталону или не подходят по морфологии.
На этапе сравнения в программе запускается проверка: совпадает ли эта буква с той, что в документе? Если буква получена в результате распознавания, то проверяется похожесть символов в версиях и рассматриваются варианты распознавания. Возможно, «А» в бумажном документе распозналась ошибочно, и из-за этого при сравнении могут возникнуть разночтения. Тогда в вариантах распознавания ищется другая буква, у которой тоже высокий процент вероятности. Если вероятность больше 50%, в распознанном документе происходит замена. Это помогает избежать ошибок из-за плохого качества сканов.
Но поиск отличий в тексте — лишь один из этапов сравнения документов. Необходимо представить найденные отличия в том виде, в котором пользователю будет комфортно с ними работать. Например, слово «мама» заменили на «папа». По факту изменились только две буквы. Но более наглядно для пользователя будет выглядеть полная замена одного слова на другое, а не замененные на «п» буквы «м». Поэтому программа дорабатывает различия: растягивает и объединяет их до конца слова, строки или параграфа. Программа пытается восстановить логику, по которой действовал человек, вносивший исправления. И сделать так, чтобы различие выглядело более естественно и читалось понятно.
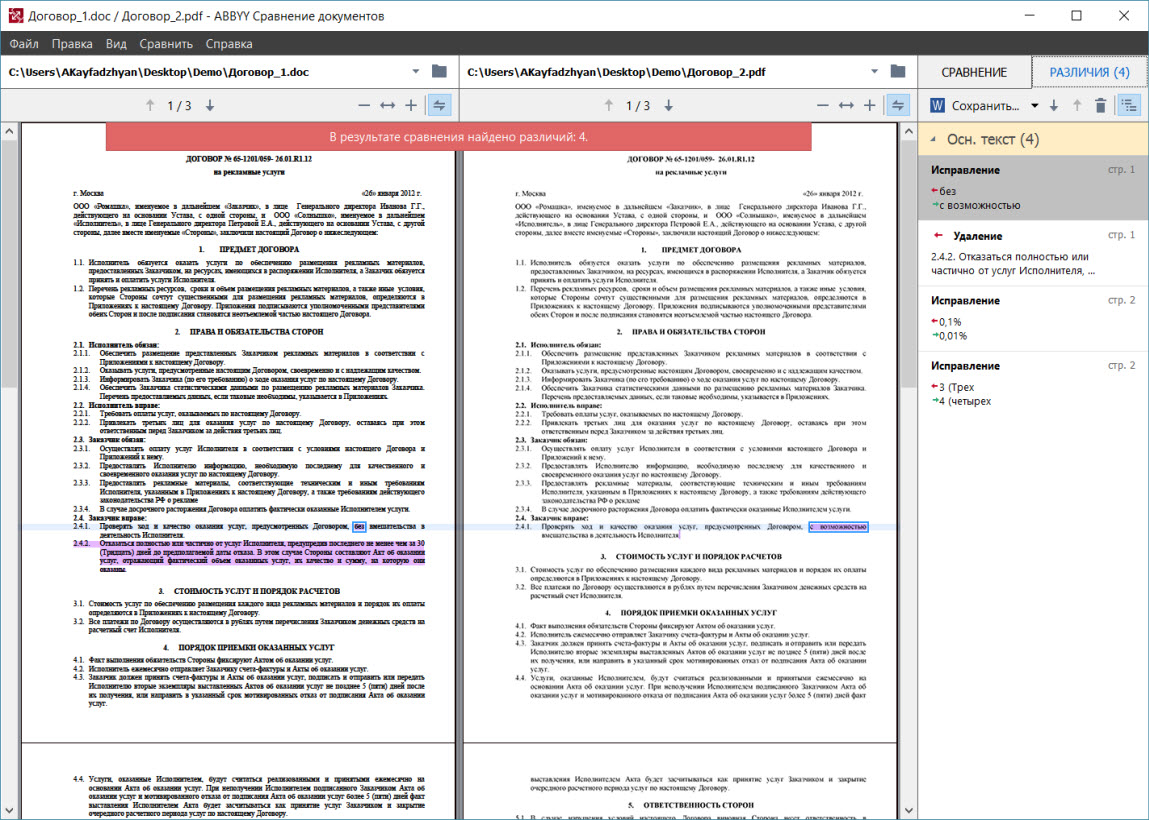
В завершении работы с документами программа объединяет обнаруженные различия в группы. Это необходимо, например, чтобы отделить внесенные исправления в основном тексте от колонтитулов и нумерации списка. В большинстве случаев колонтитулы не интересуют пользователя с точки зрения сравнения, за исключением вставок. Например, если у вас есть список на 100 позиций, в середине которого добавили или изменили один из пунктов. Чтобы работать с документом было удобнее, различия в нумерации попадают в отдельную группу.
В финале пользователь может посмотреть все исправления в документе так, как ему удобно. На выбор есть несколько способов: сохранить новую версию документа в формате DOCX, где все изменения уже подсвечиваются в режиме Track Changes, получить PDF с комментариями в местах изменений или создать таблицу с перечнем правок в Word.
Среди поддерживаемых ABBYY FineReader 15 функций:
Как работают нейросети для распознавания иероглифов и арабской вязи
Распознавание иероглифов осложняется тем, что в отличие от европейских языков, они состоят из большого количества черточек, палочек, наклонов. Но размер иероглифов вполне сопоставим с размером европейских букв. В низком разрешении сканов иероглифы могут и вовсе выглядеть как кляксы. Носитель языка поймет символ, исходя из контекста. Программа же работает поэтапно: сначала анализирует изображение всего документа, определяет абзацы, разбивает распознанные строки на слова, а слова — на отдельные символы. На этом этапе алгоритмы опираются не на контекст, как человек, а на внешний вид иероглифа, и здесь многое зависит от качества изображения. Для распознавания японского, китайского и корейского языков компания ABBYY внедрила нейросети. Они решают две главные задачи при работе с иероглифами — улучшение качества распознавания и «модернизацию» языков.
Качество и скорость в быстром и нормальном режиме
Внедрение нейросетей значительно повысило качество распознавания японского и китайского в быстром режиме, но скорость работы на начальном этапе разработки снизилась. Для клиентов, работающих с большим потоком документов, даже небольшая просадка по скорости может привести к сильному замедлению в обработке данных. Оказалось, что скорость проседает в документах с большим количеством символов с простой структурой — таких, как японская буквенная азбука (в современном японском языке используется три основных системы письма: кандзи — иероглифы китайского происхождения и две слоговые азбуки, созданные в Японии — хирагана и катакана — «Хайтек»).


Эту проблему решили с помощью кэша. Когда программа распознает страницу, одна и та же буква может попадаться на ней несколько раз. Встретив букву «А», написанную одним и тем же шрифтом, ABBYY FineReader анализирует и запоминает ее особенности. Этот принцип оптимизации позволяет не тратить время на распознавание одинаковых символов. Для японского и китайского ранее не использовался кэш, потому что встретить один и тот же иероглиф на странице, написанной естественным языком, можно очень редко. Но для символов с простой структурой это оказалось полезным. Включение кэша позволило ускорить и нормальный, и быстрый режим распознавания.
Почему важно следить за развитием языка
В предыдущих версиях FineReader в японском языке присутствовали иероглифы, которые уже не используются в современных документах. Это заметили сотрудники японского офиса ABBYY: время от времени программа вставляла при распознавании один-два устаревших символа. Для рядового носителя языка это воспринимается как буквы из русского дореволюционного алфавита для нас. Чтобы исправить эту ошибку, потребовалось создать в программе «новый язык» — Japanese Modern. Легко заставить программу не отображать те или иные устаревшие символы. Но необходимо было не просто выбросить ненужное, но и оставить всё необходимое, найти множество иероглифов, которые отображают всё богатство современного японского языка.

Новое множество символов формировалось в несколько этапов. Для тестирования создавали подходящие наборы изображений документов. Если в пакет попадала хотя бы одна страница с устаревшими формами, весь комплект оказывался непригодным. Приходилось вынимать эту страничку и формировать новый комплект материалов. Наконец удалось добиться того, чтобы в результатах распознавания почти не было устаревших символов и при этом правильно отображались все современные иероглифы.
Для китайского в FineReader всегда поддерживали традиционный и упрощенный языки. При этом по составу символов они не отличались. Получить разный результат распознавания всё равно было возможно, потому что в программе было заложено разное распределение вероятностей. В новой версии в результате экспериментов удалось выделить символы, необходимые для распознавания упрощенного китайского. В FineReader заложена возможность создавать пользовательский язык. Используя этот инструмент и внося изменения в состав, специалисты сравнивали результаты распознавания на разных образцах документов, и в результате в упрощенном китайском остался только необходимый набор иероглифов.
Корейская письменность, хангыль — нечто среднее между китайским и европейским письмом. Внешне это квадратные символы, напоминающие иероглифы, и на одной странице текста можно насчитать больше сотни уникальных. С другой стороны, это фонетическая письменность, то есть основанная на записывании звуков. Имеется алфавит, содержащий 24 буквы (плюс можно дополнительно посчитать диграфы и дифтонги). Но, в отличие от латиницы или кириллицы, звуки пишутся не в линию, а объединяются в блоки. Каждый блок может состоять из двух, трех или четырех букв. Первой всегда идет согласная, затем одна или две гласных, и в конце может стоять еще одна согласная. Для корейского обучили отдельную нейросеть, которая, помимо корейских слогов, распознает и некоторые иероглифы. Вместо распознавания символов целиком технология определяет отдельные буквы в них.
Как резать арабскую вязь на фрагменты
Арабский язык отличается от других тем, что найти линии порезки между символами в арабской вязи очень сложно. Даже гистограмма при распознавании арабского отличается: выглядит как бесконечный набор горбиков и ямочек.
Варианты разделения текста на символы создаются всегда, даже для европейских языков. В процессе работы программа выбирает наиболее вероятный путь распознавания. В случае с арабским языком таких вариантов очень много, и это приводило к ошибкам. Поэтому для повышения точности программу научили видеть не отдельную букву, а всё слово целиком. Для этого была разработана сеть end-to-end (e2e). Она полезна не только для арабского, но и для европейских языков — например, в дизайнерских шрифтах, когда на изображениях сложно построить путь для распознавания.

При e2e-подходе на вход в нейросеть поступает набор изображений — фрагментов, состоящих из отдельных слов. На выходе такая нейросеть выдает последовательность графем, которые затем проходят дополнительную обработку: проводится словарный анализ, корректируются пробелы.
Для обучения использовался набор из нескольких сотен тысяч фрагментов — отдельные слова из отсканированных газет, журналов, официальных документов. Они были выбраны в несколько итераций: сначала собирали базу из слов, которые удачно распознали, и обучали нейросеть на этом датасете. Потом еще раз обучали, корректировали, выявляли ошибки. Часть, которую не смогли распознать, отдельно отдавали на доразметку и корректировку фрагментов. В результате всё больше очищали датасет для обучения, улучшая общее качество распознавания.
Кроме того, часть данных для обучения была создана искусственно. Это было необходимо для распознавания шрифтов, для которых было собрано мало образцов. В таких случаях использовался корпус текста, в который добавлялись различные искажения, типичные для этапа сканирования документа: шум, размытие символа. Это делала в автоматическом режиме специальная программа — генератор синтетики, или «портилка».
Сначала в ходе обучения такой подход привел к тому, что потерялась информация об охватывающих прямоугольниках символов, которые необходимо отображать для пользователя на этапе верификации. Отказавшись от посимвольного распознавания, пришлось внедрить альтернативный механизм, который дополнял результаты распознавания информацией об охватывающих прямоугольниках и резал слова на отдельные символы.
Сочетание новых алгоритмов машинного обучения сделало возможным создание многофункционального текстового редактора для работы с PDF, сканами и digital-born-документами. Внесение правок, сравнение файлов и распознавание сложных языков дает пользователю возможность полноценно работать с файлами вне зависимости от их формата. По сути, это позволяет охватить все спектры офисных задач по работе с электронными и даже бумажными документами, максимально упрощая работу сотрудникам и снижая вероятность ошибок из-за человеческого фактора.