Как написать свой web-framework на Python
FullStack CTO
FullStack CTO
Пишем свой Flask
И так, это продолжение темы про то, как изучить Python за выходные (новогодние выходные, если что).

В отличие от PHP, в Python сервер нужно реализовывать самому. Но, фреймворки все это делают за вас, а для продакшена используются готовые решения, такие как gunicorn.
Gunicorn это вариация WSGI HTTP сервера. Что такое WSGI — оставлю на самостоятельное обучение. Чтобы добиться совместимости с WSGI, нам нужен вызываемый объект (функция или класс), который принимает два параметра (environ и start_response), и возвращает совместимый с WSGI ответ.
Предполагается что вы уже знаете про виртуальное окружение, у вас стоит последняя версия питона и вы умеете пользоваться пакетным менеджером pip. Я не учу питону, я делюсь своим опытом как написать что-то похожее на фреймворк Flask.
И так, чтобы сделать простейший вебсервер на Python достаточно создать простейший файл main.py со следующим кодом:
И далее самый простой способ запустить это приложение:
В данном случае мы запускаем сервер с 1м воркером и указываем файл и вызываемую функцию. Все.
Но для отладки лучше использовать вебсервер из пакета wsgiref:
и для старта такого сервера не нужен gunicorn, достаточно просто вызвать наш main.py
Ну что же, с сервером вроде бы разобрались. Давайте создадим myflask.py и начнем разработку. Вообще схема моего проекта будет выглядеть так:
Это самый простой файл, пока у нас нет реализаций других файлов.
В данном файле мы говорим что импортируем некоторый app из файла app.py. Если этот файл вызван напрямую, а не импортирован, то мы вызываем наше приложение app.run()
Config.py
Создаем app.py
Я буду краток на слова и сразу показывать код. Вроде бы все так просто, что нет смысла комментировать:
Здесь мы создаем объект app и описываем маршрутизацию, использую классную фичу языка — декораторы.
Создаем MyFlask
Ну и теперь создаем наш фреймворк:
Я не знаю надо ли расписывать весь этот код. Чего в этом коде не хватает — это реализации MyFlaskConfig, который описывается так:
Кстати, код функции from_object подсмотрел в исходниках Flask.
И так, это минимум, который позволяет реализовать простейший фреймворк похожий по API на Flask.
Чтобы не возвращать просто текст, давайте создадим простое подобие шаблонизатора:
Теперь создадим простой html шаблон templates/index.html:
Теперь наш app.py можно переписать так:
Тут показан пример как сделать наипростейший шаблонизатор. И вот когда что-то такое я написал для себя, мне стало как-то проще. Еще я до кучи почитал исходники Flask и теперь готов написать что-то в продакшн. Как вариант, для начала начну с административной панели GeekJob.ru — тем более архитектура SOA, так что могу смело добавлять сервисы в текущий проект без боли.
Запуск в production
Если хочется запустить это в продакшен, то создаем файл конфигурации для gunicorn:
Создаем скрипт запуска bin/start_gunicorn.sh:
Ну и теперь запускаем наш проект через:
Ну вот примерно как-то так работает Flask. Конечно его возможности сильно богаче, я только показал утрированный пример. В качестве шаблонизатора надо бы прикрутить Jinja2. Реализовать логику блюпринтов… Ну и много чего еще сделать, на самом деле. Но у меня нет сил и желания все разжевывать досконально. Для обучения в самый раз. Если было полезно — ставьте лайк.
Итого

В этом руководстве мы построим наиболее важные части фреймворка. В конце у нас появятся обработчики запросов (к примеру, Django views), и маршрутизации: простая (как /books/ ) и параметризованная (как /greet/
Перед тем, как приступить к чему-нибудь новому, я хочу обдумать итоговый результат. В данном случае, в конце дня, мы хотим иметь возможность использовать данный фреймворк в работе, а это значит, мы хотим, чтобы наш фреймворк поддерживался быстрым, легким и эффективным сервером. В своих проектах я использую gunicorn на протяжении нескольких лет, и очень доволен результатами. В связи с этим, я решил использовать gunicorn и для данного проекта.
Gunicorn это WSGI HTTP сервер, так что для него нужна особенная точка входа в наше приложение.
Ознакомились с WSGI? Отлично! Давайте продолжим.
Чтобы добиться WSGI совместимости, нам нужен вызываемый объект (функция или класс), который принимает два параметра (environ и start_response), и возвращает совместимый с WSGI ответ. Не волнуйтесь о том, что написанное кажется непонятным. Суть может стать яснее, когда мы перейдем к коду.
VPS для практики
Если вы начинающий программист, то рано или поздно вам придется познакомиться с Linux и запуском своего приложения сразу на рабочий VPS для клиента или для собственного проекта. Мы рекомендуем VPS от Fornex, т.к. данный хостинг отлично подходит для тех кто хочет быстро получить рабочий и надежный VPS.
Какой VPS выбрать?
Это самый сложный вопрос который может появится у новичка над которым вываливают весь спектр услуг.
Первым делом нужно завести аккаунт на Fornex.com
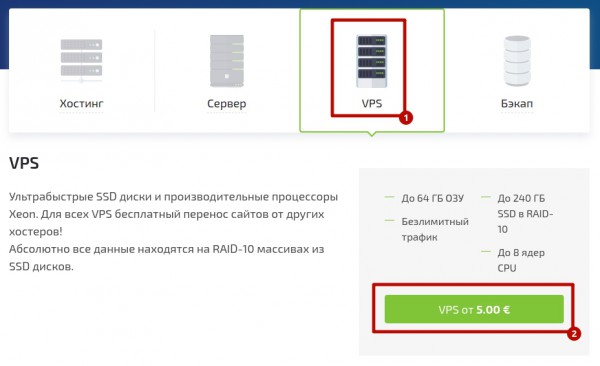
На данном этапе нашего проекта подойдет и обычный VPS.
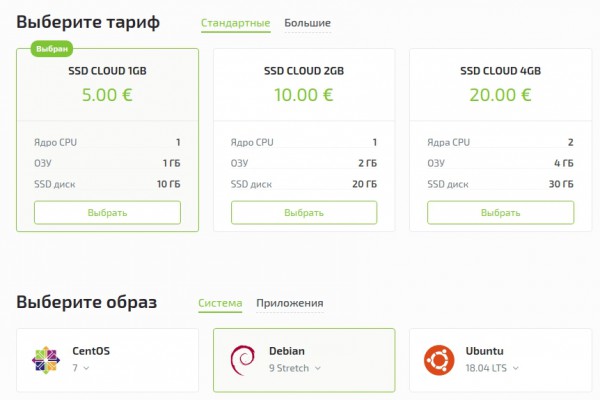
Выбираем SSD CLOUD 1GB и операционную систему Debian 9. Всегда нужно выбирать последнюю самую новую версию. Это избавит вас от проблем со старыми библиотеками.
Подключение по SSH
После заказа нашего VPS, мы получим данные от сервера. Нам понадобиться логин и пароль от SSH. Для того чтобы войти по SSH мы воспользуемся Putty (для Windows) либо в обычный терминал на Linux пишем:
Для корректной работы, нужно установить необходимые библиотеки:
Ниже мы будем использовать менеджер пакетов pip, устанавливаем его:
Создание веб-фреймворка
Придумайте название вашего фреймворка и создайте одноименную папку. Свой я назвал bumbo :
Переходим к этой папке, создаем виртуальное окружение и активируем её:
Внутри нашего файла app.py мы впишем простую функцию, чтобы узнать, будет ли она работать с gunicorn :
Теперь, давайте сделаем эту функцию классом, так как нам понадобятся несколько вспомогательных методов, и их намного проще прописать внутри класса.
Создадим файл api.py :
Теперь, удалите все внутри app.py и впишите следующее:
Теперь, когда мы создали наш класс, я хочу сделать код более элегантным, так как наши байты ( b»Hello World» ) и start_response могут запутать нас.
К счастью, есть замечательный пакет под названием WebOb, который предоставляет объекты для HTTP запросов и ответов, заворачивая среду запросов WSGI и статус, заголовки и тело ответов. Используя данный пакет, мы можем передать environ и start_response классам, которые предоставляются этим пакетом, без необходимости разбираться с этим самостоятельно.
Перед тем как продолжить, я предлагаю вам ознакомиться с документацией WebOb, чтобы понять о чем я толкую, а также обратить внимание на API нашего WebOb.
Здесь мы приступим к рефакторингу данного кода. Для начала, установим WebOb:
Импортируйте классы Request и Response в начало файла api.py:
Теперь мы можем использовать их внутри метода __call__ :
Выглядит намного лучше! Перезапустите gunicorn и увидите тот же результат, что и раньше. Лучшая часть в том, что мне не нужно объяснять, что здесь происходит! Всё говорит само за себя. Мы создаем запрос, и возвращаем этот ответ.
Отлично! Хочу обратить внимание на то, что request здесь еще не используется, так как мы ничего для этого не сделали. Итак, давайте используем эту возможность и также используем объект request. Кстати, давайте проведем рефакторинг создания ответа, превратив его в собственный метод. Почем так лучше? Мы узнаем позже:
Перезапустите gunicorn и увидите новое сообщение в браузере, а мы будем двигаться дальше.
Что скажете? Выглядит неплохо. Давайте это реализуем.
Как вы видите, метод route является декоратором, принимает путь и оборачивает методы. Это будет несложно реализовать:
Сейчас у нас есть все необходимые детали. У нас есть обработчики и связанные с ними пути. Теперь, при получении запроса, нам нужно проверить его путь, подобрать подходящий обработчик, вызвать его и вернуть соответствующий ответ. Давайте сделаем это:
Не так уж и сложно, не так ли? Мы просто провели итерацию над self.routes, сравнили пути с путем запроса, и при совпадении, вызвали обработчик, связанный с этим путем.
Следующим нашим действием будет найти ответ на вопрос “Что случится, если путь не будет найден?”. Давайте создадим метод, который возвращает простой HTTP ответ “не найдено” со статусом кода 404:
Теперь, используем это в нашем методе handle_request :
Перезапустите gunicorn и попробуйте посетить несуществующие пути. Вы должны увидеть страницу “Not found”. Теперь, выполним рефакторинг таким образом, чтобы найти обработчик для его собственного метода ради читаемости:
На мой взгляд, все выглядит намного лучше и понятнее. Перезапустите gunicorn, чтобы убедиться в там, что все работает так же, как и раньше.
Теперь у нас есть пути и обработчики. Это замечательно, но наши пути достаточно простые. Они не поддерживают сложные параметры ключевых слов в пути URL. Что если нам нужен путь наподобие @app.route(«/hello/
Как вы видите, он проанализировал строку Hello, Matthew и определил, что Matthew соответствует предоставленному
Давайте используем его в нашем методе find_handler, чтобы не только найти метод, который соответствует пути, но и параметрам, которые мы предоставляем:
Мы все еще итерируем над self.routes, и теперь вместо сравнения пути с путем запроса, мы попытаемся проанализировать его, и если будет результат, мы вернем обработчик и параметры ключевых слов как словарь. Теперь, мы можем использовать наш handle_request для отсылки этих параметров в обработчик вот так:
Давайте напишем обработчик с таким типом пути и испробуем его:
Вывод
Это был длинный путь, но я думаю он был просто замечательным. Я лично узнал много нового, пока писал это. Если вам понравилось данное руководство, дайте мне знать в комментариях, какие другие функции должны быть реализованы в нашем фреймворке. Лично я подумываю об основанных на классах обработчиках, поддержку шаблонов и статичных файлах.
Русские Блоги
Как написать веб-фреймворк на Python?

Разве это не изобретение велосипеда? Существует так много отличных веб-фреймворков, зачем писать их самому?
Написание веб-фреймворка не обязательно означает разработку. Для разных целей процесс будет сильно различаться. Для изучающих программирование:Написание веб-фреймворка самостоятельно имеет следующие преимущества:
Лучше знать и понимать веб-фреймворк
Обзор и закрепление знаний о веб-разработке
Внедряйте дизайн-мышление и тренируйте дизайн-мышление
Сравните отличные фреймворки и поймите, что такое хороший фреймворк
Если вы занимаетесь веб-разработкой, лучше всего попытаться написать фреймворк самостоятельно или, по крайней мере, обычно посмотрите исходный код некоторых отличных фреймворков; я рекомендую здесь написать легкий веб-фреймворк самостоятельно; написание фреймворка не one Его можно набрать в два клика, а иногда это занимает несколько дней, поэтому нужно быть готовым.

Основные моменты, необходимые для написания веб-фреймворка: Модуль базы данных, модуль сеанса, модуль обработки исключений, модуль WSGI, модуль механизма шаблонов, модуль маршрутизации, модуль просмотра, вспомогательный модуль и т. Д.Вот учебное пособие для тренировочного лагеря экспериментального здания (подходит для студентов, которые имеют определенный фундамент Python и имеют контакт с веб-разработкой). С помощью этого учебного пособия вы можете изучить следующие моменты:
Процесс связи на основе HTTP, обработка для разных методов запроса
Процесс планирования между веб-сервером, WSGI и фреймворком Python
От дизайна к реализации проектной модели MVC
Интерактивный дизайн базы данных MySQL
Разработка веб-фреймворка до реализации
Процесс разработки приложения, от анализа требований, проектирования архитектуры, проектирования модели базы данных до реализации приложения.

Все эти 4 курса будут открыты неделя за неделей в сентябре, и каждый сможет получить их бесплатно (первый курс был закрыт для приема).Вы также можете войти на компьютер shiyanlou.com, чтобы просмотреть подробную информацию о курсе.

Дело в том, что метод получения этих 4 курсов бесплатно выглядит следующим образом

Напомнить мне еще раз: Курс бесплатный в течение ограниченного времени только в сентябре, поэтому, пожалуйста, поторопитесь и получите его в первую очередь.

Для студентов, которые только что обратили внимание и разобрались в нашем лабораторном корпусе, вот подарочный пакет для вас:
Чтобы увидеть больше интересных уроков, нажмите на картинку ниже:
Написание framework на asyncio, aiohttp и мысли про Python3 часть первая
Введение
Грубо говоря, все, что надо было реализовать, это чтобы система отдавала данные в виде bytes :
Немного, с переименованием библиотек помучаться:
Надо еще добавить что в aiohttp вполне можно писать и синхронно, выполнять блокирующие операции, хотя это и не совсем правильно.
Естественно от версии 0.1 ожидать каких то батареек не приходится, но думаю, что в следующей версии, уже можно будет увидеть много положительных сдвигов.
Краткий обзор других фреймворков на базе asyncio и aiohttp
introduction — еще один базирующийся на aiohttp framework
1. Структура
Итак, у нас должна быть сама библиотека, которую мы хотим устанавливать с помощью pip install и в которой должны быть модули или батарейки, идущие в составе — например, админка или веб-магазин. И должен быть проект, который мы создаем в каком-то месте, в котором разработчик должен иметь возможность добавлять свои модули с разным функционалом.
В каждом компоненте как проекта, так и самой библиотеки должна быть папка со статикой и папка с шаблонами, файлик со списком роутов и файлик или файлики с запросами к базе и выводом всего этого в шаблоны.
Если нужно python 3.5 устанавливается так:
Библиотека — устанавливается через pip3 install :
Пример проекта — их может быть сколько угодно штук, в идеале для каждого сайта свой:
Содержание файликов со списком роутов мы хотим видеть примерно таким:
А view где эти роуты обрабатываются такого типа:
2. aiohttp, jinja2 и отладчик
Но нам надо вызывать шаблоны с разных мест и желательно максимально просто, например:
И для самого шаблона нужно как-то сокращенно указывать путь. Мест, где могут хранится шаблоны, может быть несколько штук:
где app компонента а template шаблона.
Поэтому, в месте, где мы инициализируем пути, подключения шаблонов мы вызываем функцию которая будет собирать все пути, к директориям где лежат шаблоны:
2) Зная пути и имя шаблона, читаем его с диска (замечу что asyncio не поддерживает асинхронные операции чтения с диска):
Тут хотелось бы заметить один момент, часто в примерах к подключению jinja2 в том числе в aiohttp_jinja2 рекомендуется для инициализации применять FileSystemLoader просто передавая ему путь, или список путей, например:
aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader(‘/templ/’))
А в нашем случае мы использовали FunctionLoader :
aiohttp_jinja2.setup(app, loader=jinja2.FunctionLoader ( load_templ ) )
Это связано с тем что мы хотим хранить шаблоны в разных директориях, для разных модулей, и не беспокоиться об одинаковых названиях. А в случае с FunctionLoader мы идём только по необходимым путям. В результате у нас модули имеют независимые пространства имён.
aiohttp_debugtoolbar
aiohttp_debugtoolbar — подключается довольно легко, там где мы инициализируем наш app :
Сам aiohttp_debugtoolbar у меня вызвал приятное впечатление, и все необходимое в нем присутствует, немного скриншотов:

3. aiohttp и роуты
В aiohttp роуты выглядят достаточно просто, пример из документации с получением динамического параметра из адреса:
Тут придется воспользоватся глобальной переменной, хоть это не очень кошерно. Функция route имеет простой вид:
В глобальную переменную, представляющую из себя список, заносим кортежами значения каждого роута. А потом во время инициализации просто в форе проходим по всем кортежам и подставляем в аутентичный вызов роута:
4. Отдача статики
Начинать реализовывать мы как и всегда, с инициализации. Тут мы просто одним роутом обслуживаем все основные встречающиеся виды статических адресов.
Дальше в функции union_stat мы просто разбираем параметры роута
И формируем соотвествующие пути.
После этого, в другой вспомогательной функции, мы создаем нужные нам заголовки для файлов, например:
И читаем сам файл с диска.
В конце мы возвращаем заголовки и сам файл:
Редирект по адресу заданyому в роуте ‘test’ c 302 ответом
5. aiohttp и Websocket
Сама обработка вебсокетов выглядит довольно просто, и скажем написания небольшого чата по количеству кода довольно лаконично.
6. asyncio и mongodb, aiohttp, session, middleware
У таких фреймворков как flask или bootle есть возможность вызвать какую либо функцию перед загрузкой всего остального или после, например, в bootle :
Для этого мы создадим middleware и инициализируем его в самом начале, это делается довольно просто, пример с уже инициализированным дебагером, сессиями и базой.
А в конце закрываем соединение:
7. aiohttp, supervisor, nginx, gunicorn
Запустить aiohttp можно несколькими способами:
Aiohttp и supervisor
В /etc/supervisor/conf.d/ создаем файл aio.conf и в нем:
После этого обновляем конфиги всех приложений, без перезапуска
Перезапуск приложений для которых обновился конфиг:
Смотрим статус приложений:
В случае с нашим небольшим фреймворком, в стартовом файле мы добавляем в sys.path нужные нам пути:
Aiohttp gunicorn и supervisor
Простой вариант для запуска с помощью gunicorn выглядит таким образом, тут нужно обратить внимание что мы не пишем над функцией index карутину, для вызова.
Ну а в файле который будет уже запускать gunicorn мы просто вызываем
Теперь можно просто запустить сам gunicorn из папки с файлом
Для запуска gunicorn через supervisor у нас будет следующая конфигурация, в папке с проектом создаем файл gunicorn.conf.py в нем:
8. После установки, о примерах.
Теперь мы можем установить нашу библиотечку
Сам utils.py устроен довольно просто.
Создание проекта или модуля выглядит так.
С помощью модуля argparse получаем опции из командной строки:
9. Road map
Версия 0.2 — 0.5
P.S. Все постарался описать максимально кратко. Естественно, в этой версии даже для заявленных возможностей скорее всего есть масса ошибок, очевидных и не очень, поэтому прошу сообщать. А также всех кого заинтересовала эта библиотека и вообще развитие темы Asyncio в данном формате. Пишите свои замечания и пожелания для функционала и я постараюсь по возможности исправить и реализовать.
Исправления грамматических неточностей и ошибок приветствуются в личке.
Всех приветствую, дорогие друзья) Начну с не большого предисловия. Я конечно очень люблю критику, так как с ее помощью можно стать еще сильнее. Но все таки, цель данного цикла, показать, что особо сложного ничего нет и основываясь на простом мы можем создать что-либо интересное. Т.е. зная всего основы такого языка, как Python, уже можно написать много чего интересного. И я придерживаюсь этой цели цикла, стараясь не затрагивать сложности (хотя они интереснее).
Сегодня мы напишем весьма не большой, так сказать фреймворк) Думаю, такая работа может и растянуться на несколько статей. Все попытаюсь объяснять простым языком. И, как я упомянул ранее, к сложностям прибегать не будем (а если и прибегнем, то попытаюсь разжевать).
3. Поговорим о функционале.
Во-первых, наш мини фреймворк будет в основном упрощать многие действия. Думаю, что напишем мы несколько модулей. Некоторые из них, как например сканирование портов, к ним можно пристроить nmap, а например, при поиске интересных файлов, субдоменов, написать уже самим. Разнообразие еще никому не вредило. Для начала, давайте, разберемся, какие модули будем писать. Исходя из теории, мы должны будем узнать
Со временем, возможно и дополним данный список. А теперь, конечно, приступаем к работе.
4. Приступаем к работе.
Наш фреймворк будет написан на python3 и чуть выше Для начала, создайте 2-е папки. Одна из которых будет modules, а другая wordlists.
Также создаем главный файл в котором будем, в скором использовать все наши модули. Должно получиться примерно так

Для начала, составим не сложный алгоритм для main.py
Первым модулем, который на вход будет получать доменное имя ресурса, будет модуль по определению IP адреса. Конечно, стоит узнать и сервер.
Создаем файл siteName.py в папке modules с следующим содержимым
Теперь, давайте напишем не большое, основное меню. Но перед этим я, также написал вывод уже существующих модулей
Думаю, что на этом можно и закончить, а завтра займемся поиском CMS, whois lookup и сканированием портов. Рекомендую повторить вам тему, про регулярки т.к. завтра они вам понадобятся. (Из-за нехватки времени, статья не получилась более обширней). Всем пока!)