Aimbot – помощник Aim на основе машинного обучения
Aimbot – помощник Aim на основе машинного обучения
По сути, я создал помощника aim для игры, используя машинное обучение, которое позже я назову Aimbot. Исключительно с помощью визуального ввода скриншота NAIMbot способен обнаружить врага на экране и рассчитать расстояние от центра экрана до врага и точно прицелиться в цель.
▬ ▬ ▬ ▬ Начало ▬ ▬ ▬ ▬ Моим первым препятствием было то, как перемещать игрока и мышь извне. После долгих исследований выяснилось, что приложения DirectX нуждаются в специальном вводе, и было важно правильно выполнить этот шаг, поскольку все построено на этом. Следующим шагом была попытка сделать вычисляемый ввод похожим на человеческий. Для этого мне нужно было создать функцию для восстановления парабол, чтобы начало движения мыши было медленнее, чем середина, так как человеку нужно ускорить физическую мышь.
▬ ▬ ▬ ▬ Сбор данных ▬ ▬ ▬ ▬//Хотя обычно данные должны быть помечены вручную, я нашел много способов автоматизировать сбор данных. Я, к сожалению, не могу раскрыть слишком много деталей, так как это мое конкурентное преимущество, но в случае этого проекта я использовал смесь внутриигровых данных и данных внешней памяти для сбора данных. Конечно, эти данные нуждались в обработке, которая была выполнена с использованием cv2 и знаний нейронных сетей.
▬ ▬ ▬ ▬ Машинное обучение ▬ ▬ ▬ ▬/| Часть машинного обучения сводится к части классификации и части локализации. Для локализации я использовал сверточную нейронную сеть региона. Поскольку я не был доволен точностью и скоростью, я переключился на обнаружение объектов Google, поскольку за ним стоят целые исследовательские группы. Скорость и точность были, наконец, разумными. Но чтобы улучшить его еще больше, я настроил гиперпараметры и изменил размер входного изображения. Трудной частью было сбалансировать скорость и точность, так как это очень зависит от используемого оборудования.
Есть еще несколько аспектов этого проекта, поскольку мой первоначальный план состоял в том, чтобы сделать NAIMbot коммерчески доступным, например, подключение базы данных к веб-сайту и запись на него при каждой покупке (чтобы избежать проблем с использованием лицензий на программное обеспечение) или создание графического пользовательского интерфейса. Эти вещи были более простыми, так что нет необходимости погружаться глубже, но если вы хотите узнать больше о чем-либо, не стесняйтесь спрашивать!
В заключение: Это означает, что я создал ненавязчивый помощник по прицеливанию, чего никогда раньше не было. Это открывает много дверей для конкурентной сцены, где помощь aim очень популярна. Вот почему я остановил проект. Я не хочу нести ответственность за то, что расстроил всю соревновательную сцену, которая мне нравится. Вместо этого я хотел бы использовать этот проект в качестве опыта. Тот факт, что я получил неизмеримое количество знаний от этого проекта, будет использован для того, чтобы помочь другим с их проблемами и идеями.
Как написать aimbot на python
Pine is an aimbot powered by real-time object detection with neural networks.
This software can be tweaked to work smoothly in CS:GO, Fortnite, and Overwatch. Pine also has built-in support for Nvidia’s CUDA toolkit and is optimized to achieve extremely high object-detection FPS. It is GPU accelerated and blazingly fast.
What games does it work with?
This release is currently optimized for CS:GO, but I plan adding more game configs in the future
Why Neural Networks?
Well, neural network aimbots are great for a lot of reasons. Probably most importantly, they never access the memory of the game, so they are practically invisible to «Anti-Cheat» sofware. Additionally, they can abstract their capabilities to many different games without code modifications. The only issue:
Neural Network Aimbots have always had one big problem: their target detection is okay, but their inference time is terrible. Even HAAR Cascades are a bad fit, since they have decent speed but horrible accuracy. MobileNetSSD and Faster R-CNN were sorta ok if you had a Nvidia Titan X with CUDA drivers. But let’s be honest, who the hell can afford a Titan?
Enter YOLOv3, tiny edition. Detection scores are decent, and inference times are. WHAT? 220 FPS WITH A 33% mAP?! For reference of how absolutely insane this is, SSD513 gets about 8 FPS with 50% mAP.

Finally, a real-time object-detection network that will run on my dinky AMD M370X from 2015! This network is what inspired me to build Pine.
YOLOv3: The Internal Object-Detection Engine
At its core, Pine’s internal object detection system relies on a modified version of the YOLOv3 neural network architecture. The detection network is trained on a combination of video game images and the COCO dataset. It is optimized to recognize human-like objects as quickly as possible. The detection engine can be abstracted to many FPS games, including CS:GO, TF2, and more.

OpenCV: GPU-Enabled Image Processing
OpenCV is at the heart of Pine’s image processing capabilities. Not only does it provide an abstraction layer for working with the screen capture data, but it it also allows us to harness the power of GPU hardware by interfacing CUDA and OpenCL. After Pine takes a capture of the user’s screen, it uses OpenCV to process that image into a form that is recognizable to the object-detection engine.

Thanks to everyone who made this project possible. I’d like to give special shoutouts to the following people:
About
? Aimbot powered by real-time object detection with neural networks, GPU accelerated with Nvidia. Optimized for use with CS:GO.
Создание простого разговорного чатбота в python
Как вы думаете, сложно ли написать на Python собственного чатбота, способного поддержать беседу? Оказалось, очень легко, если найти хороший набор данных. Причём это можно сделать даже без нейросетей, хотя немного математической магии всё-таки понадобится.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.

Поиск ответа в диалоговом датасете
Год назад меня попросили показать ребятам, которые прежде не занимались анализом данных, какое-нибудь вдохновляющее приложение машинного обучения, которое можно собрать самостоятельно. Я попробовал собрать вместе с ними бота-болталку, и у нас это действительно получилось за один вечер. Процесс и результат нам понравились, и написал об этом в своем блоге. А теперь подумал, что и Хабру будет интересно.
Итак, начинаем. Наша задача — сделать алгоритм, который на любую фразу будет давать уместный ответ. Например, на «как дела?» отвечать «отлично, а у тебя?». Самый простой способ добиться этого — найти готовую базу вопросов и ответов. Например, взять субтитры из большого количества кинофильмов.
Я, впрочем, поступлю ещё более по-читерски, и возьму данные из соревнования Яндекс.Алгоритм 2018 — это те же диалоги из фильмов, для которых работники Толоки разметили хорошие и неплохие продолжения. Яндекс собирал эти данные, чтобы обучать Алису (статьи о её кишках 1, 2, 3). Собственно, Алисой я и был вдохновлен, когда придумывал этого бота. В таблице от Яндекса даны три последних фразы и ответ на них (reply), но мы будем пользоваться только самой последней из них (context_0).

Векторизация текстов
Теперь говорим о том, как превратить тексты в числовые векторы, чтобы осуществлять по ним приближённый поиск.
Мы уже познакомились с библиотекой pandas в Python — она позволяет загружать таблицы, осуществлять поиск в них, и т.п. Теперь затронем библиотеку scikit-learn (sklearn), которая позволяет более хитрые манипуляции с данными — то, что называется машинным обучением. Это значит, что любому алгоритму сперва нужно показать данные (fit), чтобы он узнал о них что-то важное. В результате алгоритм «научится» делать с этими данными что-то полезное — преобразовывать их (transform), или даже предсказывать неизвестные величины (predict).
В данном случае мы хотим преобразовать тексты («вопросы») в числовые векторы. Это нужно, чтобы можно было находить «близкие» друг к другу тексты, пользуясь математическим понятием расстояние. Расстояние между двумя точками можно рассчитать по теореме Пифагора — как корень из суммы квадратов разностей их координат. В математике это называется Евклидовой метрикой. Если мы сможем превращать тексты в объекты, у которых есть координаты, то мы сможем вычислять Евклидову метрику и, например, находить в базе вопрос, наиболее всего похожий на «о чём ты думаешь?».
Самый простой способ задать координаты текста — это пронумеровать все слова в языке, и сказать, что i-тая координата текста равна числу вхождений в него i-того слова. Например, для текста «я не могу не плакать» координата слова «не» равна 2, координаты слов «я», «могу» и «плакать» равны 1, а координаты всех остальных слов (коих десятки тысяч) равны 0. Такое представление теряет информацию о порядке слов, но всё равно работает неплохо.
Проблема в том, что у слов, которые встречаются часто (например, частиц «и» и «а») координаты будут несоразмерно большие, хотя информации они несут мало. Чтобы смягчить эту проблему, координату каждого слова можно поделить на логарифм числа текстов, где такое слово встречается — это называется tf-idf и тоже работает неплохо.

Проблема только одна: в нашей базе 60 тысяч текстовых «вопросов», в которых содержится 14 тысяч различных слов. Если превратить все вопросы в векторы, получится матрица 60к*14к. Работать с такой не очень классно, поэтому дальше мы поговорим о сокращении размерности.
Сокращение размерности
Мы уже поставили задачу создания болталочного чатбота, скачали и векторизовали данные для его обучения. Теперь у нас есть числовая матрица, представляющая реплики пользователей. Она состоит из 60 тысяч строк (столько было реплик в базе диалогов) и 14 тысяч столбцов (столько в них было различных слов). Сейчас наша задача — сделать её поменьше. Например, представить каждый текст не 14123-мерным, а всего лишь 300-мерным вектором.
Достичь этого можно, умножив нашу матрицу размера 60049х14123 на специально подобранную матрицу проекции размера 14123х300, в итоге получим результат 60049х300. Алгоритм PCA (метод главных компонент) подбирает матрицу проекции так, чтобы исходную матрицу можно было потом восстановить с наименьшей среднеквадратической ошибкой. В нашем случае получилось сохранить около 44% об исходной матрице, хотя размерность сократилась почти в 50 раз.

За счёт чего возможно такое эффективное сжатие? Напомним, что исходная матрица содержит счётчики упоминания отдельных слов в текстах. Но слова, как правило, употреблятся не независимо друг от друга, а в контексте. Например, чем больше раз в тексте новости встречается слово «блокировка», тем больше раз, скорее всего в этом тексте встретится также слово «телеграм». А вот корреляция слова «блокировка», например, со словом «кафтан» отрицательная — они встречаются в разных контекстах.
Так вот, получается, что метод главных компонент запоминает не все 14 тысяч слов, а 300 типовых контекстов, по которым эти слова потом можно пытаться восстановить. Столбцы матрицы проекции, соответствующие синонимичным словам, обычно похожи друг на друга, потому что эти слова часто встречаются в одном контексте. А значит, можно сократить избыточные измерения, не потеряв при этом в информативности.
Во многих современных приложениях матрицу проекции слов вычисляют нейросети (например, word2vec). Но на самом деле простой линейной алгебры для практически полезного результата уже достаточно. Метод главных компонент вычислительно сводится к SVD, а оно — к расчёту собственных векторов и собственных чисел матрицы. Впрочем, программировать это можно, даже не зная деталей.
Поиск ближайших соседей
В предыдущих разделах мы закачали в python корпус диалогов, векторизовали его, и сократили размерность, а теперь хотим наконец научиться искать в нашем 300-мерном пространстве ближайших соседей и наконец-то осмысленно отвечать на вопросы.
Поскольку научились отображать вопросы в Евклидово пространство не очень высокой размерности, поиск соседей в нём можно осуществлять довольно быстро. Мы воспользуемся уже готовым алгоритмом поиска соседей BallTree. Но мы напишем свою модель-обёртку, которая выбирала бы одного из k ближайших соседей, причём чем ближе сосед, тем выше вероятность его выбора. Ибо брать всегда одного самого близкого соседа — скучно, но не завязываться на сходство совсем — опасно.
Поэтому мы хотим превратить найденные расстояния от запроса до текстов-эталонов в вероятности выбора этих текстов. Для этого можно использовать функцию softmax, которая ещё часто стоит на выходе из нейросетей. Она превращает свои аргументы в набор неотрицательных чисел, сумма которых равна 1 — как раз то, что нам нужно. Дальше полученные «вероятности» мы можем использовать для случайного выбора ответа.

Фразы, которые будет вводить пользователь, надо пропускать через все три алгоритма — векторизатор, метод главных компонент, и алгоритм выбора ответа. Чтобы писать меньше кода, можно связать их в единую цепочку (pipeline), применяющую алгоритмы последовательно.
В результате мы получили алгоритм, который по вопросу пользователя способен найти похожий на него вопрос и выдать ответ на него. И иногда это ответы даже звучат почти осмысленно.

Публикация бота в Telegram
Мы уже разобрались, как сделать чатбота-болталку, который бы выдавал примерно уместные ответы на запросы пользователя. Теперь показываю, как выпустить такого чатбота в Телеграм.
Проще всего использовать для этого готовую обёртку Telegram API для питона — например, pytelegrambotapi. Итак, пошаговая инструкция:
Полный код к статье я намеренно не выкладываю — вы получите гораздо больше удовольствия и полезного опыта, когда напечатаете его сами, и получите работающего бота в результате собственных усилий. Ну или если вам очень лень это делать, можете поболтать с моей версией ботика.
Telegram-бот на Python за полчаса с aiogram
Напишем простой диалоговый Telegram-бот на Python, который в дальнейшем можно дополнить различными функциями, и задеплоим его.
Примечание Вы читаете улучшенную версию некогда выпущенной нами статьи.
Настройка
Откройте Telegram, найдите @BotFather и начните беседу. Отправьте команду /newbot и следуйте инструкциям. Вы получите:
Обязательно сохраните токен, так как это ключ для взаимодействия с ботом.
Установка Python
Для написания Telegram-бота на Python, нужно установить сам язык. Если вы пользуетесь Windows, скачать Python можно с официального сайта. Версия важна. Нам подойдет Python не ниже версии 3.7. Если же у вас Linux или macOS, то, скорее всего, у вас стоит Python 3.6. Как обновиться, можете почитать здесь.
Тем, кто только начал изучение этого языка, будет также полезна дорожная карта Python-разработчика.
Установка pip
Установка aiogram
Установить данный фреймворк для Telegram Bot API с помощью pip:
Hello, bot!
Давайте напишем простенькую программу приветствия. Для начала следует импортировать библиотеки и создать экземпляры Телеграм бота и диспетчера:
Теперь напишем обработчик текстовых сообщений, который будет обрабатывать входящие команды /start и /help :
Добавим ещё один обработчик для получения текстовых сообщений. Если бот получит «Привет», он также поздоровается. Все остальные сообщения будут определены, как нераспознанные:
Запускаем Telegram бота, написанного на Python, следующим образом:
Примечание Так мы задаём боту непрерывное отслеживание новых сообщений. Если бот упадёт, а сообщения продолжат поступать, они будут накапливаться в течение 24 часов на серверах Telegram, и в случае восстановления бота прилетят ему все сразу.
Ну вот и всё, простенький бот в Телеграмме на языке Python готов.
Docker
Сейчас мало кто не слышал про Docker, но если вдруг не слышали — вот хорошая статья. Для нашего проекта потребуется самый простой Dockerfile:
Каталог проекта должны при этом содержать следующие файлы:
Для локальных тестов достаточно установить Docker (linux, mac, windows), после чего в папке проекта собрать и запустить контейнер с помощью команд:
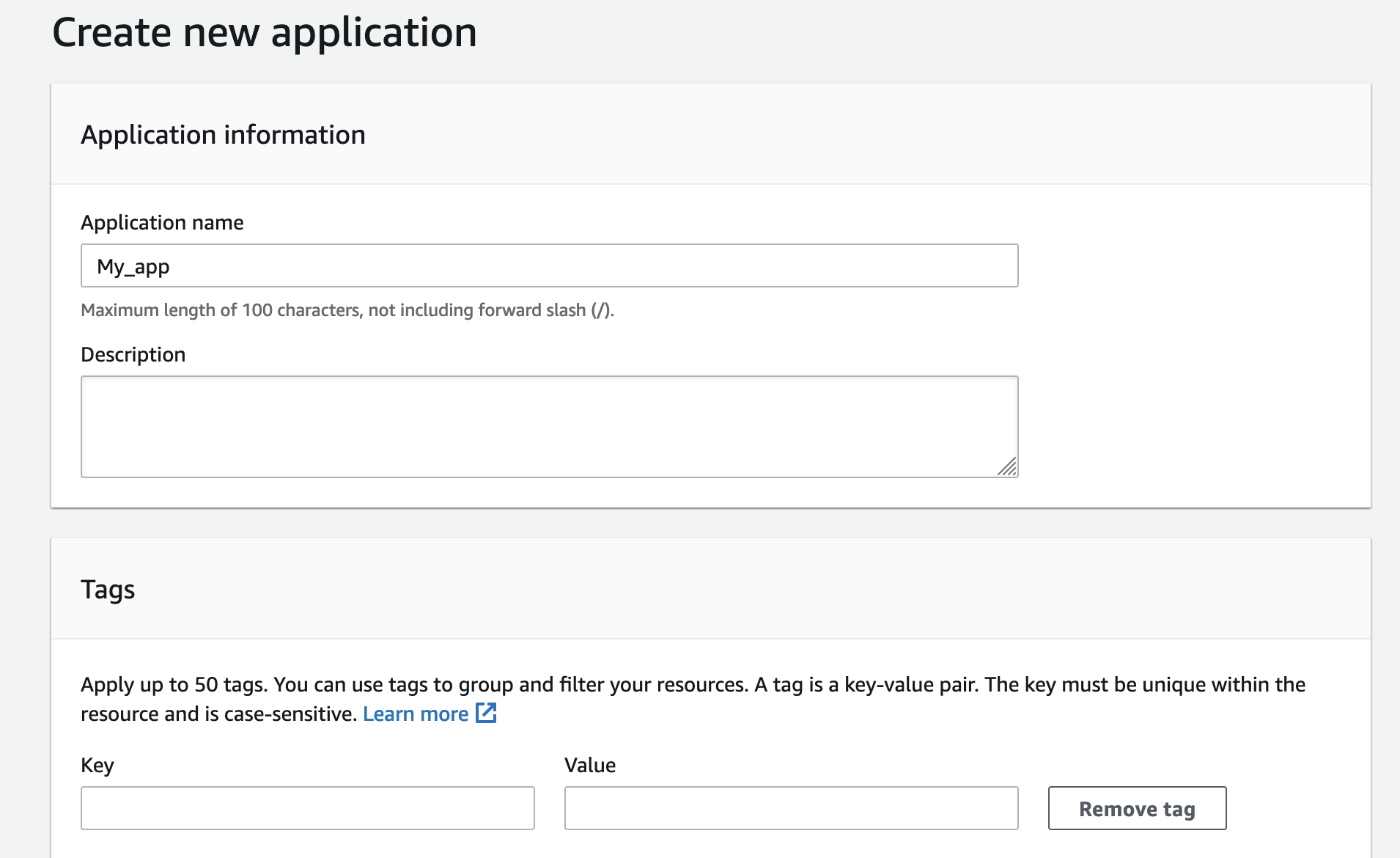
my_app — это просто название нашего контейнера, вместо которого можно использовать другое имя.
-d — специальный флаг, который запускает контейнер в фоне и позволяет дальше работать в терминале. Это называется detached mode.
Деплой на AWS
Прежде всего нам понадобится аккаунт на Docker Hub. Это аналог GitHub, только не с исходниками кода, а с уже созданными контейнерами. Работа с Docker Hub выглядит достаточно просто:
Загружаем его на докерхаб:
Для проверки успешности загрузки можете запустить контейнер из Docker Hub с помощью команды:
Далее загрузим наш контейнер в AWS Elastic Beanstalk. Для этого потребуется аккаунт на AWS. Если его нет, необходимо зарегистрироваться. Вас попросят ввести данные карты для верификации, но переживать не стоит, ведь мы воспользуемся бесплатным годовым триалом. Чтобы поиграться, этого более чем достаточно, а вот если вы захотите вывести проект в продакшен, следует перейти на VPS — это даст больше контроля и гибкости.




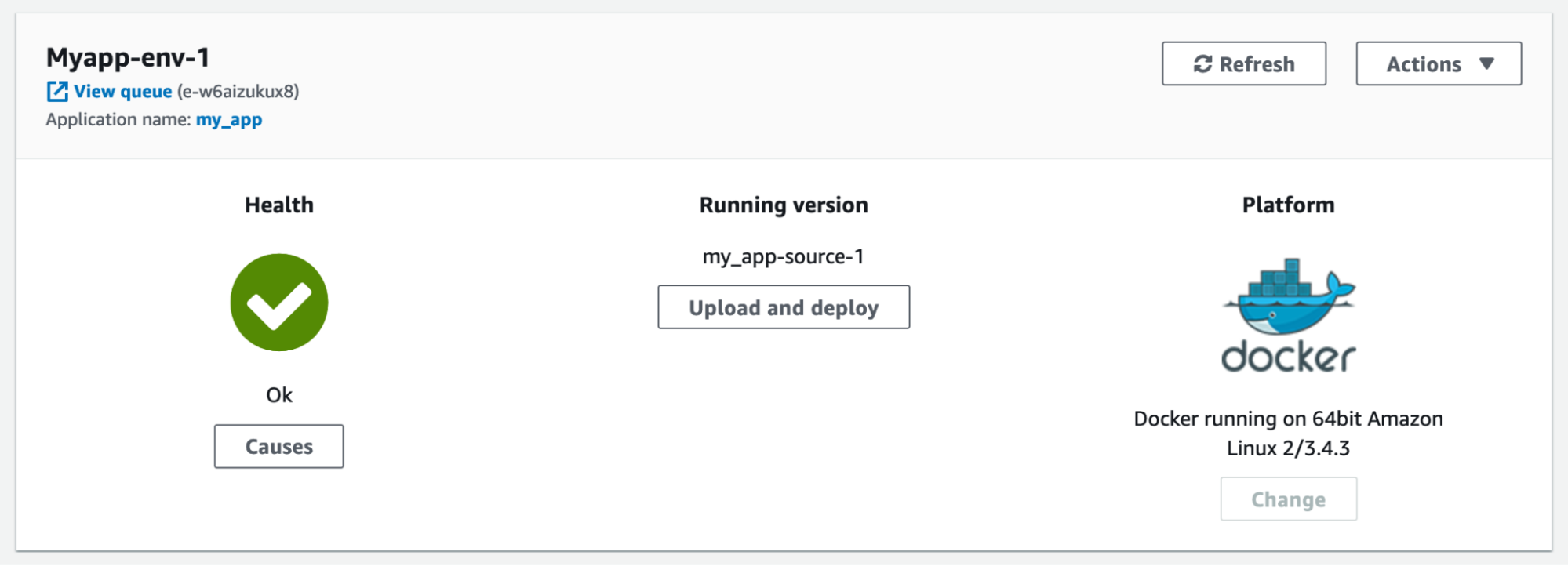
Проверяем работу нашего Telegram bot:
Заключение
Поздравляем! Теперь вы знаете, как писать роботов для Telegram на Python.
Бота можно дополнять другими функциями, например, добавить отправку файлов, опрос или клавиатуру.
Кстати, в телеграмме есть аж целых два типа клавиатур:
Но и это полностью рабочий Телеграм-бот на Python: дополните словарём, и получите полноценную беседу. Также можете опробовать функциональность нашего Telegram-бота.
В «настоящих проектах» не обойтись без базы данных. Тут на помощь приходит docker-compose, который позволяет объединить несколько контейнеров в один сервис. Таким образом, например, можно создать приложение и положить его в контейнер, а базу данных, как отдельный сервис, поместить в другой контейнер, и с помощью docker-compose наладить между ними связь.
Также для более серьёзной разработки лучше использовать выделенный виртуальный сервер (VPS): он даёт гораздо больше гибкости и свободы, чем тот же AWS. А самое главное, он более приближён к «боевой» разработке. Схема работы тут будет даже проще, чем с AWS: вам просто нужно установить Docker, спуллить образ с Docker Hub и запустить его.
Питоном по телеграму! Пишем пять простых Telegram-ботов на Python

Содержание статьи
Python для новичков
Если ты совсем не ориентируешься в Python, то отличным началом будет прочтение трех вводных статей, которые я публиковал в «Хакере» этим летом, либо посещение курса «Python для новичков», который я начну вести для читателей «Хакера» уже совсем скоро — 30 ноября.
Чтобы создать бота, нам нужно дать ему название, адрес и получить токен — строку, которая будет однозначно идентифицировать нашего бота для серверов Telegram. Зайдем в Telegram под своим аккаунтом и откроем «отца всех ботов», BotFather.
Жмем кнопку «Запустить» (или отправим / start ), в ответ BotFather пришлет нам список доступных команд:
Когда мы наконец найдем свободный и красивый адрес для нашего бота, в ответ получим сообщение, в котором после фразы Use this token to access the HTTP API будет написана строка из букв и цифр — это и есть необходимый нам токен. Сохраним ее где‑нибудь на своем компьютере, чтобы потом использовать в скрипте бота.
Для взаимодействия с Telegram API есть несколько готовых модулей. Самый простой из них — Telebot. Чтобы установить его, набери
Эхо-бот
Для начала реализуем так называемого эхо‑бота. Он будет получать от пользователя текстовое сообщение и возвращать его.