Python 3: Генерация случайных чисел (модуль random)¶
«Генерация случайных чисел слишком важна, чтобы оставлять её на волю случая»
Python порождает случайные числа на основе формулы, так что они не на самом деле случайные, а, как говорят, псевдослучайные [1]. Этот способ удобен для большинства приложений (кроме онлайновых казино) [2].
| [1] | Википедия: Генератор псевдослучайных чисел |
| [2] | Доусон М. Программируем на Python. — СПб.: Питер, 2014. — 416 с.: ил. — 3-е изд |
Модуль random позволяет генерировать случайные числа. Прежде чем использовать модуль, необходимо подключить его с помощью инструкции:
random.random¶
random.random() — возвращает псевдослучайное число от 0.0 до 1.0
random.seed¶
random.seed( ) — настраивает генератор случайных чисел на новую последовательность. По умолчанию используется системное время. Если значение параметра будет одиноким, то генерируется одинокое число:
random.uniform¶
random.randint¶
random.choince¶
random.choince( ) — возвращает случайный элемент из любой последовательности (строки, списка, кортежа):
random.randrange¶
random.shuffle¶
random.shuffle( ) — перемешивает последовательность (изменяется сама последовательность). Поэтому функция не работает для неизменяемых объектов.
Вероятностные распределения¶
random.expovariate(lambd) — экспоненциальное распределение. lambd равен 1/среднее желаемое. Lambd должен быть отличным от нуля. Возвращаемые значения от 0 до плюс бесконечности, если lambd положительно, и от минус бесконечности до 0, если lambd отрицательный.
random.gauss(значение, стандартное отклонение) — распределение Гаусса.
random.normalvariate(mu, sigma) — нормальное распределение. mu — среднее значение, sigma — стандартное отклонение.
random.vonmisesvariate(mu, kappa) — mu — средний угол, выраженный в радианах от 0 до 2π, и kappa — параметр концентрации, который должен быть больше или равен нулю. Если каппа равна нулю, это распределение сводится к случайному углу в диапазоне от 0 до 2π.
random.paretovariate(alpha) — распределение Парето.
random.weibullvariate(alpha, beta) — распределение Вейбулла.
Примеры¶
Генерация произвольного пароля¶
Хороший пароль должен быть произвольным и состоять минимум из 6 символов, в нём должны быть цифры, строчные и прописные буквы. Приготовить такой пароль можно по следующему рецепту:
Этот же скрипт можно записать всего в две строки:
Данная команда является краткой записью цикла for, вместо неё можно было написать так:
Данный цикл повторяется 12 раз и на каждом круге добавляет к строке psw произвольно выбранный элемент из списка.
Random Python
Каждый человек ежедневно сталкивается со случайностью. Википедия нам говорит: случайность — это результат маловероятного или непредсказуемого события. Непредсказуемого. Стоит отметить, что, чем сложнее система, тем ниже возможность прогнозировать (предсказывать) её будущие состояния. Мир сложен и именно по-этому случайность встречается столь часто. Можно сказать, что случайностью мы называем все события, которые не можем предугадать. Таким образом, разговор о случайном – это разговор о нехватке информации. Но эту нехватку человек научился использовать себе на пользу. К примеру, случайные величина широко применяются в криптографии.
В языке Python есть удобные инструменты для работы со случайными значениями. Речь о модуле стандартной библиотеки под названием random (и не только о нём). Давайте знакомиться!
Как использовать модуль random в Python
Для начала модуль надо импортировать.
Python функции модуля random
Случайное целое число — randint() функция random
Самое частое применение данного модуля — генерация случайных чисел. Самая популярная функция для этого — randint().
Она возвращает случайное целое число, лежащее в диапазоне, указанном в параметрах функции. Оба аргумента обязательны и должны быть целыми числами.
Генерация случайного целого числа — randrange()
Функция randrange() используется для генерации случайного целого числа в пределах заданного диапазона. Отличие от randint() заключается в том, что здесь есть третий параметр – шаг, по умолчанию равный единице.
Выбор случайного элемента из списка choice()
Вы играли в детстве в «считалочки»? Эники-беники… Вот этим и занимается random.choice(): функция возвращает один случайный элемент последовательности.
Функция sample()
random.sample() применяется, когда надо выбрать несколько элементов из заданной коллекции. Она возвращает список уникальных элементов, выбранных из исходной последовательности. Количество элементов, которое вернёт функция, задаётся аргументом k.
Случайные элементы из списка — choices()
random.choices делает то же, что и random.sample(), но элементы, которые она возвращает, могут быть не уникальными.
Генератор псевдослучайных чисел — seed()
Метод seed() используется для инициализации генератора псевдослучайных чисел в Python. Вот что это означает: для генерации псевдослучайных чисел необходимо какое-то исходное число и именно это число можно установить данным методом. Если значение seed не установлено, тогда система будет отталкиваться от текущего времени.
Перемешивание данных — shuffle()
Метод random.shuffle() применяется для расстановки элементов последовательности в случайном порядке. Представьте коробку в которой лежат какие-то предметы. Встряхните её ?
Генерации числа с плавающей запятой — uniform()
random.uniform() похожа на randint(), но применяется для генерации числа с плавающей запятой в указанном диапазоне.
Функция triangular()
Функция random.triangular() позволяет управлять вероятностью – она возвращает случайное число с плавающей запятой, которое соответствует заданному диапазону, а также уточняющему значению mode. Этот параметр дает возможность взвешивать возможный результат ближе к одному из двух других значений параметров. По умолчанию он находится посередине диапазона.
Криптографическая зашита генератора случайных данных
Случайные числа, полученные при помощи модуля random в Питоне, не являются криптографически устойчивыми. Это означает, что криптоанализ позволяет предсказать какое число будет сгенерировано следующим. Попробуем исправить ситуацию.
Его зачастую следует использовать вместо генератора псевдослучайных чисел по умолчанию в модуле random, который предназначен для моделирования и симуляции, а не безопасности или криптографии.
Numpy.random — Генератор псевдослучайных чисел
Самый простой способ задать массив со случайными элементами — использовать функцию sample (или random, или random_sample, или ranf — это всё одна и та же функция).
Без аргументов возвращает просто число в промежутке [0, 1), с одним целым числом — одномерный массив, с кортежем — массив с размерами, указанными в кортеже (все числа — из промежутка [0, 1)).
Генерация случайного n-мерного массива вещественных чисел
numpy.random.rand()применяется для генерации массива случайных вещественных чисел в пределах заданного диапазона.
Также можно генерировать числа согласно различным распределениям (Гаусса, Парето и другие). Чаще всего нужно равномерное распределение, которое можно получить с помощь функции uniform.
Для начала необходимо установить Numpy.
Генерация случайного n-мерного массива целых чисел
С помощью функции randint или random_integers можно создать массив из целых чисел. Аргументы: low, high, size: от какого, до какого числа (randint не включает в себя это число, а random_integers включает), и size — размеры массива.
Выбор случайного элемента из массива чисел или последовательности
Функция NumPy random.choice() используется для получения случайных выборок одномерного массива, который возвращается как случайные выборки массива NumPy. Эта функция генерирует случайные выборки, которые обычно используются в статистике данных, анализе данных, полях, связанных с данными, а также может использоваться в машинном обучении, байесовской статистике и т. д.
Генерация случайных универсальных уникальных ID
Универсальные уникальные идентификаторы, также известные как UUID, — это 128-битные числа, используемые для однозначной идентификации информации в компьютерных системах. UUID могут использоваться для обозначения широкого спектра элементов, включая документы, объекты, сеансы, токены, сущности и т. Д. Их также можно использовать в качестве ключей базы данных.
Эта библиотека генерирует уникальные идентификаторы на основе системного времени и сетевого адреса компьютера. Объект UUID неизменяем и содержит некоторые функции для создания различных уникальных идентификаторов.
UUID состоит из пяти компонентов, каждый из которых имеет фиксированную длину. Символ дефиса разделяет каждый компонент. Мы можем представить UUID в формате «8-4-4-4-12», где каждая из цифр представляет длину в шестнадцатеричном формате.
UUID Python, сгенерированный с помощью функции uuid4(), создается с использованием истинно случайного или псевдослучайного генератора. Поэтому вероятность повторения двух гуидов невелика. Когда UUID необходимо сгенерировать на отдельных машинах или мы хотим сгенерировать безопасные UUID, используйте UUID4 (). Он также используется для генерации криптографически безопасных случайных чисел.
Генерация случайных данных в Python (Руководство)


Насколько случайны случайности? Это странный вопрос, но желательно его задать, если речь идет об информационной безопасности. Когда вы генерируете случайные данные, числа или строки в Python, неплохо иметь хотя бы приблизительное представление о том, как именно генерируются эти данные.
Содержание:
Здесь мы рассмотрим несколько различных способов генерации данных в Python и перейдем к их сравнению в таких категориях, как безопасность, универсальность, предназначение и скорость.
Мы обещаем, что данное руководство не будет похоже на урок математики, или криптографии: математики здесь будет ровно столько, сколько необходимо!
Насколько случайны случайности?
Во первых, нужно сделать небольшое заявление. Большая часть случайных данных, сгенерированных в Python — не совсем “случайная” в научном понимании слова. Скорее, это псевдослучайность, сгенерированная генератором псевдослучайных чисел (PRNG), который по сути, является любым алгоритмом для генерации на первый взгляд случайных, но все еще воспроизводимых данных.
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
“Настоящие” случайные числа могут быть сгенерированы при помощи (как вы, скорее всего, можете догадаться), настоящим генератором случайных чисел (true random number generator, TRNG). Пример: регулярно поднимать игральный кубик с пола, подбрасывать его в воздух и дать ему приземлиться.
Представим, что вы совершаете бросок произвольно и понятия не имеете, какое число выпадет на кубике. Бросок кубика — это грубая форма использования аппаратного обеспечения для генерации числа, которое не является детерминированным. TRNG выходит за рамки этой статьи, однако это стоит упомянуть в любом случае, хотя бы для сравнения.
PRNG, выполняемые обычно программным, а не аппаратным обеспечением, немного отличаются. Вот краткое описание:
Они начинают со случайного числа, также известного как зерно и затем используют алгоритм для генерации псевдослучайной последовательности битов, основанных на нём.
В какой-то момент вам могут посоветовать почитать документацию. И эти люди не то, что ошибутся. Вот интересный сниппет из документации модуля random, который вам не стоит упускать:
Внимание: псевдослучайные генераторы этого модуля не должны быть использованы в целях безопасности (источник).
Возможно, вы уже сталкивались с random.seed(999), random.seed(1234), или им подобным. Этот вызов функции проходит через генератор случайных чисел, который используется модулем random Python. Это то, что делает последующие вызовы генератора случайных чисел детерминированными: вход А производит выход Б. Это чудо может стать проклятием, если используется неправильно.
Возможно термины “случайный” и “детерминированный” выглядят так, будто не могут упоминаться в одном контексте. Чтобы прояснить этот момент, вот супер упрощенная версия random(), которая итеративно создает “случайное” число, используя x = (x * 3) % 19.
“Х” изначально определен как значение сид (cлучайное начальное значение), после чего превращается в детерминированную последовательность чисел, основанных на этом семени:
Не стоит воспринимать этот пример слишком буквально, так как он служит чисто для отображения концепции. Если вы используете значение сид 1234, дальнейшая последовательность вызовов random() всегда должна быть идентичной:
Мы рассмотрим более серьезную иллюстрацию данного примера в дальнейшем.
Что значит “криптографически безопасно”?
Если вам казалось, что в статье мало акронимов типа “RNG” — то добавим сюда еще один: CSPRNG — криптографически безопасный PRNG. CSPRNG подходят для генерации конфиденциальных данных, таких как пароли, аутентификаторы и токены. Благодаря заданной случайно строке, условный злодей не сможет определить, какая строка шла за или перед этой строкой в последовательности случайных строк.
Еще один термин, с которым вы можете столкнуться — энтропия. В двух словах, она ссылается на количество случайностей, желаемых или введенных. Например, один модуль Python, который мы рассмотрим в данной статье, определяет DEFAULT_ENTROPY = 32, количество возвращаемых байтов по умолчанию. Разработчики считают это количество байтов “достаточным”.
Обратите внимание: В данной статье я предполагаю, что байт ссылается на 8 битов, как в далеких 60-х, а не к какой-либо другой единице хранения. Можете называть его октетом, если хотите.
Главная суть CSPRNG — это то, что они все еще псевдослучайные. Они сконструированы таким образом, что являются внутренне детерминированными, но добавляют некие другие переменные, или имеют определенную собственность, которая делает их “достаточно случайными”, чтобы запретить поддержку любой функции, которая выполняет детерменизм.
Что вы из этого почерпнете?
Практически, это значит, что вам нужно использовать PRNG для статистического моделирования, симуляции и сделать случайные данные воспроизводимыми. PRNG также значительно быстрее, чем CSPRNG, что вы и увидите в дальнейшем. Используйте CSPRNG для безопасности и в криптографических приложениях, где конфиденциальные данные являются обязательным условием.
В дополнение к расширению использования вышеупомянутых примеров в этой статье, вы познакомитесь с инструментами Python для работы как с PRNG, так и с CSPRNG:
Мы рассмотрим все вышеперечисленное и подытожим детальным сравнением.
PRNG в Python
Модуль random
Возможно самый известный инструмент для генерации случайных данных в Python — это модуль random, который использует алгоритм PRNG под названием Mersenne Twister в качестве корневого генератора.
Ранее, мы затронули random.seed(), и теперь настало подходящее время, чтобы узнать, как он работает. Сначала, давайте создадим случайные данные без сидинга. Функция random.random() возвращает случайное десятичное число с интервалом [0.0, 1.0). В результате всегда будет меньше, чем правая конечная точка (1.0). Это также известно, как полуоткрытый диапазон:
Если вы запустите этот код лично, весьма вероятно, что полученные числа на вашем компьютере будут другими. По умолчанию, когда вы не используете сид генератор, вы используете текущее системное время, или “источник случайности” вашей операционной системы, если это доступно.
С random.seed() вы можете сделать результаты воспроизводимыми, и цепочка вызова, после random.seed(), будет генерировать один и тот же след данных:
Обратите внимание на повторение “случайных” чисел. Последовательность случайных чисел становится детерменированной, или полностью определенной значением сида, 444.
Давайте рассмотрим основы того, как функционирует модуль random. Ранее мы создали случайное десятичное число. Вы можете сгенерировать случайное целое число между двумя отметками в Python при помощи функции random.randint(). Таким образом охватывается целый интервал [x, y] и обе конечные точки могут быть включены:
С random.randrange(), вы можете исключить правую часть интервала, то есть сгенерированное число всегда остается внутри [x, y) и всегда будет меньше правой части:
Если вы хотите сгенерировать случайные десятичные числа, которые находятся в определенном интервале [x, y], вы можете использовать random.uniform(), который вырывается из непрерывного равномерного распределения:
Чтобы взять случайный элемент из последовательности, не являющейся пустой (такой как список или кортеж), вы можете использовать random.choice(). Также есть random.choices() для выборки нескольких элементов из последовательности с заменой (дубликаты возможны):
Вы можете сделать последовательность случайной прямо на месте, при помощи random.shuffle(). Таким образом удастся обновить объект последовательности и сделать порядок элементов случайным:
Если вы не хотите делать это с изначальным списком, сначала вам может понадобиться сделать копию, а потом уже перемешать её. Вы можете создавать копии списков Python при помощи модуля copy, или просто x[:], или x.copy(), где x является списком.
Перед тем, как перейти к генерированию случайных данных в NumPy, давайте рассмотрим еще одно приложение, которое частично включено в процесс: генерация последовательности уникальных случайных строк с одинаковой длиной.
В первую очередь, это может разобраться с устройством функции. Вам нужно выбрать из “пула” символов, таких как буквы, числа, и\или знаки препинания, совмести их в одну строку, и затем проверить, является ли эта строка сгенерированной. Python работает отлично для такого типа тестирования:
«».join() присоединяет буквы из random.choices() в простую строку, где «k» это длинна строки. Это токен добавлен в набор, который не может иметь дубликатов, и цикл while будет проходить, пока набор не будет содержать количество элементов, которое вы определили.
На заметку: Модуль string содержит ряд полезных констант: cii_lowercase, ascii_uppercase, string.punctuation, ascii_whitespace и еще много других.
Давайте проверим эту функцию:
Для хорошо настроенной версии этой функции, этот ответ Stack Overflow использует функции генератора, привязку имени и еще несколько продвинутых хитростей, чтобы создать более быструю, криптографически безопасную версию упомянутой ранее unique_strings().
PRNG для массивов: numpy.random
Одна вещь, которую вы могли заметить, заключается в том, что большинство функций из случайного числа возвращают скалярное значение (один int, float, или другой объект). Если вы хотели сгенерировать последовательность случайных чисел, один из способов достичь этого — охватить список Python:
Есть еще один вариант, который был разработан как раз для этого. Вы можете рассматривать пакет numpy.random от NumPy как стандартный модуль random библиотеки Python, но только для массивов NumPy. (Он также имеет возможность рисовать из гораздо большего количество статистических распределений).
Обратите внимание на то, что numpy.random использует собственные PRNG, которые отделены от обычных случайных чисел. Вы не будете создавать детерминестически случайные массивы NumPy с вызовом random.seed():
Без дальнейших церемоний, вот несколько примеров, удовлетворяющих ваш аппетит:
В синтаксе для randn(d0, d1, …, dn), параметры d0, d1, …, dn являются опциональными и указывают форму итогового объекта. Здесь, np.random.randn(3, 4) создает 2d массив с 3 строками и 4 столбцами. В качестве данных будут i.i.d., что означает, что каждая точка данных создается независимо от других.
Еще одна простая операция — это создание последовательности случайных логических значений: True или False. Один из способов сделать это — использовать np.random.choice([True, False]). Однако, будет практически в 4 раза быстрее выбрать (0, 1), а затем отобразить эти целые числа в соответствующие булевские значения:
КОД # randint является [inclusive, exclusive), в отличие от random.randint()
КОД
Что на счет генерации коррелированных данных? Скажем, вы хотите симулировать два корелированных временных ряда. Один из способов сделать — это использовать функцию multivariate_normal() нашего NumPy, которая учитывает матрицу ковариации. Другими словами, чтобы списать из одной нормальной распределенной случайной переменной, вам нужно определить ее среднее значение и дисперсию (или стандартное отклонение).
Для выборки из многомерного нормального распределения, вы определяете матрицу ковариации и средние значения, в итоге вы получите несколько взаимосвязанных рядов данных, которые разделены приблизительно нормально.
Однако, в отличие от ковариации, корреляция — это более знакомая для большинства мера, к тому же более интуитивная. Это ковариация, нормализованная продуктом стандартных отклонений, так что вы можете определить ковариацию с точки зрения корреляции и стандартного отклонения:
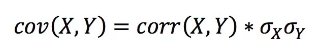
Итак, можете ли вы списать случайные выборки из многомерного нормального распределения, определив матрицу корреляции и стандартные отклонения? Да, но вам нужно будет получить приведенную выше формулу матрицы. Здесь, S — это вектор стандартных отклонений, P — это их корреляционная матрица, и С — это результирующая (квадратная) ковариационная матрица:
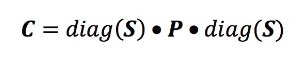
Это может быть выражено в NumPy следующим образом:
Теперь, вы можете сгенерировать два временных ряда, которые коррелируют, но все еще являются случайными:
Вы можете рассматривать данные как 500 пар обратно-коррелированных точек данных. Вот проверка правильности, так что вы можете вернуться к изначальному вводу, который приблизительно соответствует corr, stdev, и mean из примера выше:
Перед тем как мы перейдем к CSPRNG, может быть полезно обобщить некоторые случайные функции и копии numpy.random:
| Модуль random | Аналог NumPy | Использование |
| random() | rand() | Случайное десятичное [0.0, 1.0) |
| randint(a, b) | random_integers() | Случайное целое число [a, b] |
| randrange(a, b[, step]) | randint() | Случайное целое число [a, b) |
| uniform(a, b) | uniform() | Случайное десятичное [a, b] |
| choice(seq) | choice() | Случайный элемент из seq |
| choices(seq, k=1) | choice() | Случайные k элементы из seq с заменой |
| sample(population, k) | choice() с параметром replace=False | Случайные k элементы из seq без замены |
| shuffle(x[, random]) | shuffle() | Перемешка порядка |
| normalvariate(mu, sigma) или gauss(mu, sigma) | normal() | Пример из нормального распределения со средним значением mu и стандартным отклонением sigma |
Обратите внимание: NumPy специализируется на построении и обработке больших, многомерных массивов. Если вам нужно только одно значение, то random будет достаточно, к тому же, еще и быстрее. Для небольших последовательностей, random может быть еще быстрее, так как NumPy имеет ряд дополнительных расходов.
Мы рассмотрели две фундаментальные опции PRNG, так что теперь мы можем перейти к еще более безопасным адаптациям.
CSPRNG в Python
os.urandom(): настолько случайно, на сколько возможно
Функция Python под названием os.urandom() используется как в secrets, так и в uuid (мы к ним скоро придем). Чтобы не вдаваться в лишние подробности, os.urandom() генерирует зависимые от операционной системы случайные байты, которые спокойно можно назвать криптографически надежными: