Создание простой нейронной сети на Python

Feb 26 · 8 min read
![]()
В течение последних десятилетий машинное обучение оказало огромное влияние на весь мир, и его популярность только набирает обороты. Все больше людей увлекается подотраслями этой науки, например нейронными сетями, которые разрабатываются по принципам функционирования человеческого мозга. В этой статье мы разберем код Python для простой нейронной сети, классифицирующей векторы 1х3, где первым элементом является 10.
Шаг 1: импорт NumPy, Scikit-learn и Matplotlib
Для этого проекта мы используем три пакета. NumPy будет служить для создания векторов и матриц, а также математических операций. Scikit-learn возьмет на себя обязанность по масштабированию данных, а Matpotlib предоставит график изменения показателей ошибки в процессе обучения сети.
Шаг 2: создание обучающей и контрольной выборок
Нейронны е сети отлично справляются с изучением тенденций как в больших, так и в малых датасетах. Тем не менее специалисты по данным должны иметь в виду опасность возможного переобучения, которое чаще встречается в проектах с небольшими наборами данных. Переобучение происходит, когда алгоритм слишком долго обучается на датасете, в результате чего модель просто запоминает представленные данные, давая хорошие результаты конкретно на используемой обучающей выборке. При этом она существенно хуже обобщается на новые данные, а ведь именно это нам от нее и нужно.
Чтобы гарантировать оценку модели с позиции ее возможности прогнозировать именно новые точки данных, принято разделять датасеты на обучающую и контрольную выборки (а иногда еще и на тестовую).
Шаг 3: масштабирование данных
Многие модели МО не способны понимать различия между, например единицами измерения, и будут, естественно, придавать большие веса признакам с большими величинами. Это может нарушить способность алгоритма правильно прогнозировать новые точки данных. Более того, обучение моделей МО на признаках с высокими величинами будет медленнее, чем нужно, по крайней мере при использовании градиентного спуска. Причина в том, что градиентный спуск сходится к искомой точке быстрее, когда значения находятся приблизительно в одном диапазоне.
Шаг 4: Создание класса нейронной сети
Один из простейших способов познакомиться со всеми элементами нейронной сети — создать соответствующий класс. Он должен включать все переменные и функции, которые потребуются для должной работы нейронной сети.
Шаг 4.1: создание функции инициализации
Функция _init_ вызывается при создании класса, что позволяет правильно инициализировать его переменные.
Разрабатываем и развёртываем собственную платформу ИИ с Python и Django
Взлёт искусственного интеллекта привёл к популярности платформ машинного обучения MLaaS. Если ваша компания не собирается строить фреймворк и развёртывать свои собственные модели, есть шанс, что она использует некоторые платформы MLaaS, например H2O или KNIME. Многие исследователи данных, которые хотят сэкономить время, пользуются этими инструментами, чтобы быстро прототипировать и тестировать модели, а позже решают, будут ли их модели работать дальше.
Но не бойтесь всей этой инфраструктуры; чтобы понять эту статью, достаточно минимума знаний языка Python и фреймворка Django. Специально к старту нового потока курса по машинному обучению в этом посте покажем, как быстро создать собственную платформу ML, способную запускать самые популярные алгоритмы на лету.

Портрет Орнеллы Мути Джозефа Айерле (фрагмент), рассчитанный с помощью технологии искусственного интеллекта.
Прежде всего взгляните, пожалуйста, на сайт, который я разработал для этого проекта, и позвольте мне показать вам краткое введение в то, что можно сделать с этой платформой, в этом видео.
Как видите, вы выбираете самые популярные модели с контролируемым и неконтролируемым обучением и запускаете их всего одним щелчком мыши. Если хочется попробовать те же наборы данных, что и в видео, вы можете скачать их здесь.
Круто, давайте посмотрим, как это сделать! Возможно, вы работаете на ноутбуке или на облачном сервере, я использовал сервер Digital Ocean, приложение работает на Nginx и Gunicorn, и я подробно расскажу о том, как развёртывать его: это может быть полезно, когда нужно развёртывать приложения на Linux-сервере каждый день.
Давайте начнём настраивать наше окружение с некоторых установок:
После этого всё, что Вам нужно сделать, — это настроить Вашу конфигурацию для сервиса Gunicorn:
Теперь всё готово, и вы можете просто клонировать код из моего GitHub-репозитория (текущая ветка — releasee-1.2) и установить все нужные пакеты, просто выполнив команду:
Проверьте технические характеристики вашей системы, чтобы убедиться, что она соответствует требованиям (стоят нужные версии Python, Django и т. д.). После этого вы увидите типичные папки структуры проекта Django, а именно:
Прежде всего мы импортируем все библиотеки, которые нам понадобятся для наших моделей машинного обучения и построения красивых графиков онлайн (Pandas, NumPy, sci-kit-learn, TensorFlow, Keras, Seaborn, Plotly и т. д.).
Заключение
В этом проекте мы увидели, как сравнительно легко внедрить приложение для компьютерного обучения на сервере Linux с помощью Django, мы могли бы также использовать Flask (еще одно популярное приложение на Python) или многие другие технологии. Дело в том, что, если вы просто хотите, чтобы ваша модель работала на фронтенде сайта, чтобы пользователи могли ею пользоваться, вам нужно лишь встроить свои модели в функции, которые принимают входные данные, настроенные пользователями.
Обратите внимание, что мы делали всё на лету, не нуждаясь в базе данных. Это очень маленький навык, если вы являетесь инженером-машиностроителем и вам необходимо быстро построить и развернуть модель. Проблема с реальными платформами машинного обучения заключается в том, что им необходимо принимать огромные объёмы данных от тысяч пользователей и хранить пользовательскую информацию, то есть проблема этих платформ заключается не в сложности выполняемых ими моделей, а в сложности облачных операций, которые они выполняют, чтобы иметь возможность справляться с их рабочей нагрузкой. Что ж, на сегодня всё, надеюсь, вам понравился этот проект и понравилось программировать его!
Машинное обучение для начинающих: создание нейронных сетей

Далее будет представлено максимально простое объяснение того, как работают нейронные сети, а также показаны способы их реализации в Python. Приятная новость для новичков – нейронные сети не такие уж и сложные. Термин нейронные сети зачастую используют в разговоре, ссылаясь на какой-то чрезвычайно запутанный концепт. На деле же все намного проще.
Данная статья предназначена для людей, которые ранее не работали с нейронными сетями вообще или же имеют довольно поверхностное понимание того, что это такое. Принцип работы нейронных сетей будет показан на примере их реализации через Python.
Содержание статьи
Создание нейронных блоков
Для начала необходимо определиться с тем, что из себя представляют базовые компоненты нейронной сети – нейроны. Нейрон принимает вводные данные, выполняет с ними определенные математические операции, а затем выводит результат. Нейрон с двумя входными данными выглядит следующим образом:
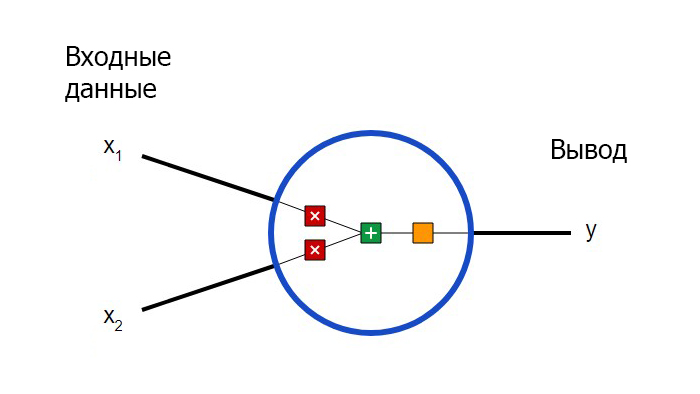
Здесь происходят три вещи. Во-первых, каждый вход умножается на вес (на схеме обозначен красным ):
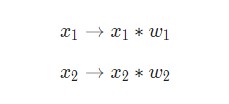
Затем все взвешенные входы складываются вместе со смещением b (на схеме обозначен зеленым ):
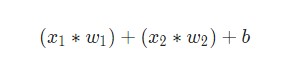
Наконец, сумма передается через функцию активации (на схеме обозначена желтым ):
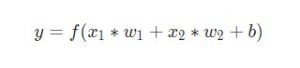
Функция активации используется для подключения несвязанных входных данных с выводом, у которого простая и предсказуемая форма. Как правило, в качестве используемой функцией активации берется функция сигмоида:
Простой пример работы с нейронами в Python
Предположим, у нас есть нейрон с двумя входами, который использует функцию активации сигмоида и имеет следующие параметры:
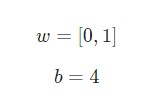
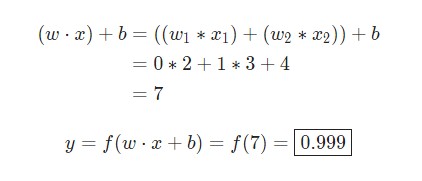
Создание нейрона с нуля в Python
Есть вопросы по Python?
На нашем форуме вы можете задать любой вопрос и получить ответ от всего нашего сообщества!
Telegram Чат & Канал
Вступите в наш дружный чат по Python и начните общение с единомышленниками! Станьте частью большого сообщества!
Паблик VK
Одно из самых больших сообществ по Python в социальной сети ВК. Видео уроки и книги для вас!
Приступим к имплементации нейрона. Для этого потребуется использовать NumPy. Это мощная вычислительная библиотека Python, которая задействует математические операции:
Пример сбор нейронов в нейросеть
Нейронная сеть по сути представляет собой группу связанных между собой нейронов. Простая нейронная сеть выглядит следующим образом:
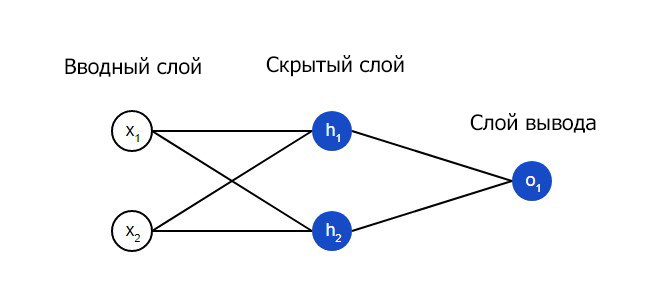
Скрытым слоем называется любой слой между вводным слоем и слоем вывода, что являются первым и последним слоями соответственно. Скрытых слоев может быть несколько.
Пример прямого распространения FeedForward
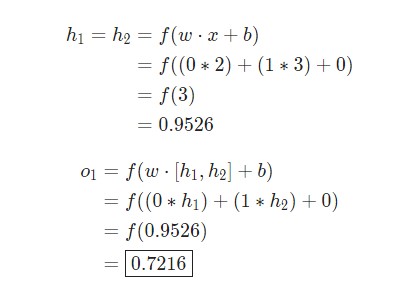
Нейронная сеть может иметь любое количество слоев с любым количеством нейронов в этих слоях.
Суть остается той же: нужно направить входные данные через нейроны в сеть для получения в итоге выходных данных. Для простоты далее в данной статье будет создан код сети, упомянутая выше.
Создание нейронной сети прямое распространение FeedForward
Далее будет показано, как реализовать прямое распространение feedforward в отношении нейронной сети. В качестве опорной точки будет использована следующая схема нейронной сети:
Пример тренировки нейронной сети — минимизация потерь, Часть 1
Предположим, у нас есть следующие параметры:
| Имя/Name | Вес/Weight (фунты) | Рост/Height (дюймы) | Пол/Gender |
| Alice | 133 | 65 | F |
| Bob | 160 | 72 | M |
| Charlie | 152 | 70 | M |
| Diana | 120 | 60 | F |
Давайте натренируем нейронную сеть таким образом, чтобы она предсказывала пол заданного человека в зависимости от его веса и роста.
| Имя/Name | Вес/Weight (минус 135) | Рост/Height (минус 66) | Пол/Gender |
| Alice | -2 | -1 | 1 |
| Bob | 25 | 6 | 0 |
| Charlie | 17 | 4 | 0 |
| Diana | -15 | -6 | 1 |
Потери
В данном случае будет использоваться среднеквадратическая ошибка (MSE) потери:
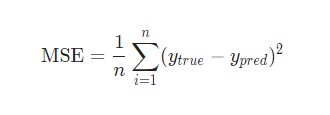
Лучшие предсказания = Меньшие потери.
Тренировка нейронной сети = стремление к минимизации ее потерь.
Пример подсчета потерь в тренировки нейронной сети
Нейросеть в 11 строчек на Python
О чём статья
Лично я лучше всего обучаюсь при помощи небольшого работающего кода, с которым могу поиграться. В этом пособии мы научимся алгоритму обратного распространения ошибок на примере небольшой нейронной сети, реализованной на Python.
Дайте код!
Слишком сжато? Давайте разобьём его на более простые части.
Часть 1: Небольшая игрушечная нейросеть
Нейросеть, тренируемая через обратное распространение (backpropagation), пытается использовать входные данные для предсказания выходных.
Предположим, нам нужно предсказать, как будет выглядеть колонка «выход» на основе входных данных. Эту задачу можно было бы решить, подсчитав статистическое соответствие между ними. И мы бы увидели, что с выходными данными на 100% коррелирует левый столбец.
Обратное распространение, в самом простом случае, рассчитывает подобную статистику для создания модели. Давайте попробуем.
Нейросеть в два слоя
Переменные и их описания.
X — матрица входного набор данных; строки – тренировочные примеры
y – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
«*» — поэлементное умножение – два вектора одного размера умножают соответствующие значения, и на выходе получается вектор такого же размера
«-» – поэлементное вычитание векторов
x.dot(y) – если x и y – это вектора, то на выходе получится скалярное произведение. Если это матрицы, то получится перемножение матриц. Если матрица только одна из них – это перемножение вектора и матрицы.
Разберём код по строчкам
Импортирует numpy, библиотеку линейной алгебры. Единственная наша зависимость.
Наша нелинейность. Конкретно эта функция создаёт «сигмоиду». Она ставит в соответствие любое число значению от 0 до 1 и преобразовывает числа в вероятности, а также имеет несколько других полезных для тренировки нейросетей свойств.

Эта функция также умеет выдавать производную сигмоиды (deriv=True). Это одно из её полезных свойств. Если выход функции – это переменная out, тогда производная будет out * (1-out). Эффективно.
Инициализация массива входных данных в виде numpy-матрицы. Каждая строка – тренировочный пример. Столбцы – это входные узлы. У нас получается 3 входных узла в сети и 4 тренировочных примера.
Инициализирует выходные данные. «.T» – функция переноса. После переноса у матрицы y есть 4 строки с одним столбцом. Как и в случае входных данных, каждая строка – это тренировочный пример, и каждый столбец (в нашем случае один) – выходной узел. У сети, получается, 3 входа и 1 выход.
Благодаря этому случайное распределение будет каждый раз одним и тем же. Это позволит нам проще отслеживать работу сети после внесения изменений в код.
Матрица весов сети. syn0 означает «synapse zero». Так как у нас всего два слоя, вход и выход, нам нужна одна матрица весов, которая их свяжет. Её размерность (3, 1), поскольку у нас есть 3 входа и 1 выход. Иными словами, l0 имеет размер 3, а l1 – 1. Поскольку мы связываем все узлы в l0 со всеми узлами l1, нам требуется матрица размерности (3, 1).
Заметьте, что она инициализируется случайным образом, и среднее значение равно нулю. За этим стоит достаточно сложная теория. Пока просто примем это как рекомендацию. Также заметим, что наша нейросеть – это и есть эта самая матрица. У нас есть «слои» l0 и l1, но они представляют собой временные значения, основанные на наборе данных. Мы их не храним. Всё обучение хранится в syn0.
Тут начинается основной код тренировки сети. Цикл с кодом повторяется многократно и оптимизирует сеть для набора данных.
Первый слой, l0, это просто данные. В X содержится 4 тренировочных примера. Мы обработаем их все и сразу – это называется групповой тренировкой [full batch]. Итого мы имеем 4 разных строки l0, но их можно представить себе как один тренировочный пример – на этом этапе это не имеет значения (можно было загрузить их 1000 или 10000 без всяких изменений в коде).
Это шаг предсказания. Мы позволяем сети попробовать предсказать вывод на основе ввода. Затем мы посмотрим, как это у неё получается, чтобы можно было подправить её в сторону улучшения.
В строке содержится два шага. Первый делает матричное перемножение l0 и syn0. Второй передаёт вывод через сигмоиду. Размерности у них следующие:
Матричные умножения требуют, чтобы в середине уравнения размерности совпадали. Итоговая матрица имеет количество строк, как у первой, а столбцов – как у второй.
Мы загрузили 4 тренировочных примера, и получили 4 догадки (матрица 4х1). Каждый вывод соответствует догадке сети для данного ввода.
Поскольку в l1 содержатся догадки, мы можем сравнить их разницу с реальностью, вычитая её l1 из правильного ответа y. l1_error – вектор из положительных и отрицательных чисел, характеризующий «промах» сети.
А вот и секретный ингредиент. Эту строку нужно разбирать по частям.
Первая часть: производная
l1 представляет три этих точки, а код выдаёт наклон линий, показанных ниже. Заметьте, что при больших значениях вроде x=2.0 (зелёная точка) и очень малые, вроде x=-1.0 (фиолетовая) линии имеют небольшой уклон. Самый большой угол у точки х=0 (голубая). Это имеет большое значение. Также отметьте, что все производные лежат в пределах от 0 до 1.
Полное выражение: производная, взвешенная по ошибкам
Математически существуют более точные способы, но в нашем случае подходит и этот. l1_error – это матрица (4,1). nonlin(l1,True) возвращает матрицу (4,1). Здесь мы поэлементно их перемножаем, и на выходе тоже получаем матрицу (4,1), l1_delta.
Умножая производные на ошибки, мы уменьшаем ошибки предсказаний, сделанных с высокой уверенностью. Если наклон линии был небольшим, то в сети содержится либо очень большое, либо очень малое значение. Если догадка в сети близка к нулю (х=0, у=0,5), то она не особенно уверенная. Мы обновляем эти неуверенные предсказания и оставляем в покое предсказания с высокой уверенностью, умножая их на величины, близкие к нулю.
Мы готовы к обновлению сети. Рассмотрим один тренировочный пример. В нём мы будем обновлять веса. Обновим крайний левый вес (9.5)
Для крайнего левого веса это будет 1.0 * l1_delta. Предположительно, это лишь незначительно увеличит 9.5. Почему? Поскольку предсказание было уже достаточно уверенным, и предсказания были практически правильными. Небольшая ошибка и небольшой наклон линии означает очень небольшое обновление.
Но поскольку мы делаем групповую тренировку, указанный выше шаг мы повторяем для всех четырёх тренировочных примеров. Так что это выглядит очень похоже на изображение вверху. Так что же делает наша строчка? Она подсчитывает обновления весов для каждого веса, для каждого тренировочного примера, суммирует их и обновляет все веса – и всё одной строкой.
Понаблюдав за обновлением сети, вернёмся к нашим тренировочным данным. Когда и вход, и выход равны 1, мы увеличиваем вес между ними. Когда вход 1, а выход – 0, мы уменьшаем вес.
Таким образом, в наших четырёх тренировочных примерах ниже, вес первого входа по отношению к выходу будет постоянно увеличиваться или оставаться постоянным, а два других веса будут увеличиваться и уменьшаться в зависимости от примеров. Этот эффект и способствует обучению сети на основе корреляций входных и выходных данных.
Часть 2: задачка посложнее
Попробуем предсказать выходные данные на основе трёх входных столбцов данных. Ни один из входных столбцов не коррелирует на 100% с выходным. Третий столбец вообще ни с чем не связан, поскольку в нём всю дорогу содержатся единицы. Однако и тут можно увидеть схему – если в одном из двух первых столбцов (но не в обоих сразу) содержится 1, то результат также будет равен 1.
Это нелинейная схема, поскольку прямого соответствия столбцов один к одному не существует. Соответствие строится на комбинации входных данных, столбцов 1 и 2.
Интересно, что распознавание образов является очень похожей задачей. Если у вас есть 100 картинок одинакового размера, на которых изображены велосипеды и курительные трубки, присутствие на них определённых пикселей в определённых местах не коррелирует напрямую с наличием на изображении велосипеда или трубки. Статистически их цвет может казаться случайным. Но некоторые комбинации пикселей не случайны – те, что формируют изображение велосипеда (или трубки).

Стратегия
Чтобы скомбинировать пиксели в нечто, у чего может появиться однозначное соответствие с выходными данными, нужно добавить ещё один слой. Первый слой комбинирует вход, второй назначает соответствие выходу, используя в качестве входных данных выходные данные первого слоя. Обратите внимание на таблицу.
Случайным образом назначив веса, мы получим скрытые значения для слоя №1. Интересно, что у второго столбца скрытых весов уже есть небольшая корреляция с выходом. Не идеальная, но есть. И это тоже является важной частью процесса тренировки сети. Тренировка будет только усиливать эту корреляцию. Она будет обновлять syn1, чтобы назначить её соответствие выходным данным, и syn0, чтобы лучше получать данные со входа.
Нейросеть в три слоя
Переменные и их описания
X — матрица входного набор данных; строки – тренировочные примеры
y – матрица выходного набора данных; строки – тренировочные примеры
l0 – первый слой сети, определённый входными данными
l1 – второй слой сети, или скрытый слой
l2 – финальный слой, это наша гипотеза. По мере тренировки должен приближаться к правильному ответу
syn0 – первый слой весов, Synapse 0, объединяет l0 с l1.
syn1 – второй слой весов, Synapse 1, объединяет l1 с l2.
l2_error – промах сети в количественном выражении
l2_delta – ошибка сети, в зависимости от уверенности предсказания. Почти совпадает с ошибкой, за исключением уверенных предсказаний
l1_error – взвешивая l2_delta весами из syn1, мы подсчитываем ошибку в среднем/скрытом слое
l1_delta – ошибки сети из l1, масштабируемые по увеернности предсказаний. Почти совпадает с l1_error, за исключением уверенных предсказаний
Код должен быть достаточно понятным – это просто предыдущая реализация сети, сложенная в два слоя один над другим. Выход первого слоя l1 – это вход второго слоя. Что-то новое есть лишь в следующей строке.
Использует ошибки, взвешенные по уверенности предсказаний из l2, чтобы подсчитать ошибку для l1. Получаем, можно сказать, ошибку, взвешенную по вкладам – мы подсчитываем, какой вклад в ошибки в l2 вносят значения в узлах l1. Этот шаг и называется обратным распространением ошибок. Затем мы обновляем syn0, используя тот же алгоритм, что и в варианте с нейросетью из двух слоёв.