Web Scraping с помощью python
Введение
Недавно заглянув на КиноПоиск, я обнаружила, что за долгие годы успела оставить более 1000 оценок и подумала, что было бы интересно поисследовать эти данные подробнее: менялись ли мои вкусы в кино с течением времени? есть ли годовая/недельная сезонность в активности? коррелируют ли мои оценки с рейтингом КиноПоиска, IMDb или кинокритиков?
Но прежде чем анализировать и строить красивые графики, нужно получить данные. К сожалению, многие сервисы (и КиноПоиск не исключение) не имеют публичного API, так что, приходится засучить рукава и парсить html-страницы. Именно о том, как скачать и распарсить web-cайт, я и хочу рассказать в этой статье.
В первую очередь статья предназначена для тех, кто всегда хотел разобраться с Web Scrapping, но не доходили руки или не знал с чего начать.
Off-topic: к слову, Новый Кинопоиск под капотом использует запросы, которые возвращают данные об оценках в виде JSON, так что, задача могла быть решена и другим путем.
Задача
Инструменты
Загрузка данных
Первая попытка
Приступим к выгрузке данных. Для начала, попробуем просто получить страницу по url и сохранить в локальный файл.
Открываем полученный файл и видим, что все не так просто: сайт распознал в нас робота и не спешит показывать данные. 
Разберемся, как работает браузер
Однако, у браузера отлично получается получать информацию с сайта. Посмотрим, как именно он отправляет запрос. Для этого воспользуемся панелью «Сеть» в «Инструментах разработчика» в браузере (я использую для этого Firebug), обычно нужный нам запрос — самый продолжительный.
Как мы видим, браузер также передает в headers UserAgent, cookie и еще ряд параметров. Для начала попробуем просто передать в header корректный UserAgent.
На этот раз все получилось, теперь нам отдаются нужные данные. Стоит отметить, что иногда сайт также проверяет корректность cookie, в таком случае помогут sessions в библиотеке Requests.
Скачаем все оценки
Парсинг
Немного про XPath
XPath — это язык запросов к xml и xhtml документов. Мы будем использовать XPath селекторы при работе с библиотекой lxml (документация). Рассмотрим небольшой пример работы с XPath
Подробнее про синтаксис XPath также можно почитать на W3Schools.
Вернемся к нашей задаче
Каждый фильм представлен как
. Рассмотрим, как вытащить русское название фильма и ссылку на страницу фильма (также узнаем, как получить текст и значение атрибута).
Еще небольшой хинт для debug’a: для того, чтобы посмотреть, что внутри выбранной ноды в BeautifulSoup можно просто распечатать ее, а в lxml воспользоваться функцией tostring() модуля etree.
Резюме
В результате, мы научились парсить web-сайты, познакомились с библиотеками Requests, BeautifulSoup и lxml, а также получили пригодные для дальнейшего анализа данные о просмотренных фильмах на КиноПоиске.
Полный код проекта можно найти на github’e.
Пишем изящный парсер на Питоне
довольно общеупотребительны. Код выше лёгким движением руки программиста (и тяжёлым движением руки комитета по стандартизации) превращается в:
Стало чуть-чуть лучше, хотя всё ещё не выглядит идеально. В Python нет и такого, но если вы ненавидите if в Python-коде так же сильно, как я, и хотите научиться быстро писать простые парсеры, то добро пожаловать под кат. В этой статье мы попытаемся написать короткий и изящный парсер для JSON на Python 2 (без каких-либо дополнительных модулей, конечно же).
Что такое парсинг и с чем его едят
Парсинг (по-русски «синтаксический анализ») — это бессмертная задача разобрать и преобразовать в осмысленные единицы нечто, написанное на некотором фиксированном языке, будь то язык программирования, язык разметки, язык структурированных запросов или главный язык жизни, Вселенной и всего такого. Типичная последовательность этапов решения задачи выглядит примерно так:
Модельная задача
Написание парсера проиллюстрируем на простом, но не до конца тривиальном примере — парсинге JSON. Грамматика выглядит примерно так:
Здесь нет правил для string и number — они, вместе со всеми строками в кавычках, будут нашими токенами.
Парсим JSON
Полноценный токенайзер мы писать не станем (это скучно и не совсем тема статьи) — будем работать с целой строкой и бить её на токены по мере необходимости. Напишем две первые функции:
(Я обещал без if’ов, но это последние, чесслово!)
Для всего остального напишем одну функцию, генерящую простенькие функции-парсеры:
Итого, по какому принципу мы строим наши функции:
Парсим правило с ветвлением
Ну уж нет, эти if достали меня!
Но на второй взгляд мы увидим, что каждая опция может занимать всего одну строчку!
При этом эффективность остаётся на прежнем уровне — каждая функция начнёт выполняться (а стало быть, делать работу, проверяя регулярные выражения) только тогда, когда предыдущая не даст результата. return гарантирует, что лишняя работа не будет выполнена, если где-то в середине списка парсинг удался.
Парсим последовательности конструкций
С этим мощным (пусть и страшноватым) инструментом наша функция перепишется в виде:
Ну а дописать функцию parse_comma_separated_values — раз плюнуть:
Приведёт ли такое решение к бесконечной рекурсии? Нет! Однажды функция parse_comma не найдёт очередной запятой, и до последующей parse_comma_separated_values выполнение уже не дойдёт.
Идём дальше! Объект:
Ну, что там дальше?
Собственно, всё! Остаётся добавить простую интерфейсную функцию:
130 строк. Попробуем запустить:
Заключение
Конечно, я рассмотрел далеко не все ситуации, которые могут возникнуть при написании парсеров. Иногда программисту может потребоваться ручное управление выполнением, а не запуск последовательности chain ов и sequence ов. К счастью, это не так неудобно в рассмотренном подходе, как может показаться. Так, если нужно попытаться распарсить необязательную конструкцию и сделать действие в зависимости от её наличия, можно написать:
Несмотря на неполноту и неакадемичность изложения, я надеюсь, что эта статья будет полезна начинающим программистам, а может, даже удивит новизной подхода программистов продвинутых. При этом я прекрасно отдаю себе отчёт, что это просто новая форма для старого доброго рекурсивного спуска; но если программирование — это искусство, разве не важна в нём форма если не наравне, то хотя бы в степени, близкой к содержанию.
Как обычно, не откладывая пишите в личку обо всех обнаруженных неточностях, орфографических, грамматических и фактических ошибках — иначе я сгорю от стыда!
Учимся парсить веб-сайты на Python + BeautifulSoup
Интернет, пожалуй, самый большой источник информации (и дезинформации) на планете. Самостоятельно обработать множество ресурсов крайне сложно и затратно по времени, но есть способы автоматизации этого процесса. Речь идут о процессе скрейпинга страницы и последующего анализа данных. При помощи этих инструментов можно автоматизировать сбор огромного количества данных. А сообщество Python создало несколько мощных инструментов для этого. Интересно? Тогда погнали!
И да. Хотя многие сайты ничего против парсеров не имеют, но есть и те, кто не одобряет сбор данных с их сайта подобным образом. Стоит это учитывать, особенно если вы планируете какой-то крупный проект на базе собираемых данных.
С сегодня я предлагаю попробовать себя в этой интересной сфере при помощи классного инструмента под названием Beautiful Soup (Красивый суп?). Название начинает иметь смысл если вы хоть раз видели HTML кашу загруженной странички.
В этом примере мы попробуем стянуть данные сначала из специального сайта для обучения парсингу. А в следующий раз я покажу как я собираю некоторые блоки данных с сайта Minecraft Wiki, где структура сайта куда менее дружелюбная.
Этот гайд я написал под вдохновением и впечатлением от подобного на сайте realpython.com, так что многие моменты и примеры совпадают, но содержимое и определённые части были изменены или написаны иначе, т.к. это не перевод. Оригинал: Beautiful Soup: Build a Web Scraper With Python.
Цель: Fake Python Job Site
Этот сайт прост и понятен. Там есть список данных, которые нам и нужно будет вытащить из загруженной странички.

Понятное дело, что обработать так можно любой сайт. Буквально все из тех, которые вы можете открыть в своём браузере. Но для разных сайтов нужен будет свой скрипт, сложность которого будет напрямую зависеть от сложности самого сайта.
Главным инструментом в браузере для вас станет Инспектор страниц. В браузерах на базе хромиума его можно запустить вот так:
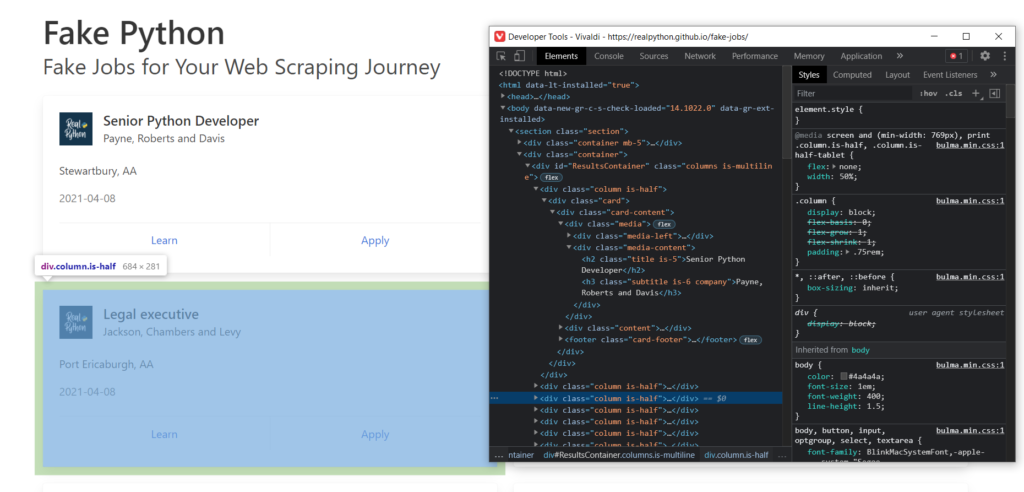
Он отображает полный код загруженной странички. Из него же мы будем извлекать интересующие нас данные. Если вы выделите блоки html кода, то при помощи подсветки легко сможете понять, что за что отвечает.
Ладно, на сайт посмотрели. Теперь перейдём в редактор.
Пишем код парсера для Fake Python
Для работы нам нужно будет несколько библиотек: requests и beautifulsoup4. Их устанавливаем через терминал при помощи команд:
Осваиваем парсинг сайта: короткий туториал на Python
Постоянно в Интернете, ничего не успеваете? Парсинг сайта спешит на помощь! Разбираемся, как автоматизировать получение нужной информации.

Чтобы быть в курсе, кто получит кубок мира в 2019 году, или как будет выглядеть будущее страны в ближайшие 5 лет, приходится постоянно зависать в Интернете. Но если вы не хотите тратить много времени на Интернет и жаждете оставаться в курсе всех событий, то эта статья для вас. Итак, не теряя времени, начнём!
Доступ к новейшей информации получаем двумя способами. Первый – с помощью API, который предоставляют медиа-сайты, а второй – с помощью парсинга сайтов (Web Scraping).
Использование API предельно просто, и, вероятно, лучший способ получения обновлённой информации – вызвать соответствующий программный интерфейс. Но, к сожалению, не все сайты предоставляют общедоступные API. Таким образом, остаётся другой путь – парсинг сайтов.
Парсинг сайта
Это метод извлечения информации с веб-сайтов. Эта методика преимущественно фокусируется на преобразовании неструктурированных данных – в формате HTML – в Интернете в структурированные данные: базы данных или электронные таблицы. Парсинг сайта включает в себя доступ к Интернету напрямую через HTTP или через веб-браузер. В этой статье будем использовать Python, чтобы создать бот для получения контента.
Последовательность действий
Эта последовательность помогает пройти по URL-адресу нужной страницы, получить HTML-содержимое и проанализировать необходимые данные. Но иногда требуется сперва войти на сайт, а затем перейти по конкретному адресу, чтобы получить данные. В этом случае добавляется ещё один шаг для входа на сайт.
Пакеты
Для анализа HTML-содержимого и получения необходимых данных используется библиотека Beautiful Soup. Это удивительный пакет Python для парсинга документов формата HTML и XML.
Для входа на веб-сайт, перехода к нужному URL-адресу в рамках одного сеанса и загрузки HTML-содержимого будем использовать библиотеку Selenium. Selenium Python помогает при нажатии на кнопки, вводе контента и других манипуляциях.
Погружение в код
Сначала импортируем библиотеки, которые будем использовать:
Затем укажем драйверу браузера путь к Selenium, чтобы запустить наш веб-браузер (Google Chrome). И если не хотим, чтобы наш бот отображал графический интерфейс браузера, добавим опцию headless в Selenium.
Браузеры без графического интерфейса (headless) предоставляют автоматизированное управление веб-страницей в среде, аналогичной популярным веб-браузерам, но выполняются через интерфейс командной строки или с использованием сетевых коммуникаций.
После настройки среды путём определения браузера и установки библиотек приступаем к HTML. Перейдём на страницу входа и найдём идентификатор, класс или имя полей для ввода адреса электронной почты, пароля и кнопки отправки, чтобы ввести данные в структуру страницы.
Затем отправим учётные данные в эти HTML-теги, нажав кнопку «Отправить», чтобы ввести информацию в структуру страницы.
После успешного входа в систему перейдём на нужную страницу и получим HTML-содержимое страницы.
Когда получили HTML-содержимое, единственное, что остаётся, – парсинг. Распарсим содержимое с помощью библиотек Beautiful Soup и html5lib.
Один раз находим родительский тег, а затем рекурсивно проходим по дочерним элементам и печатаем значения.
Чтобы выполнить указанную программу, установите библиотеки Selenium, Beautiful Soup и html5lib с помощью pip. После установки библиотек команда #python
выведет значения в консоль.
Так парсятся данные с любого сайта.
Если же парсим веб-сайт, который часто обновляет контент, например, результаты спортивных соревнований или текущие результаты выборов, целесообразно создать задание cron для запуска этой программы через конкретные интервалы времени.
Используете парсинг сайта?
Для вывода результатов необязательно ограничиваться консолью, правда?
Создание парсеров с помощью Scrapy и Python
Научимся писать парсеры с помощью Scrapy, мощного фреймворка для извлечения, обработки и хранения данных.
В этом руководстве вы узнаете, как использовать фреймворк Python, Scrapy, с помощью которого можно обрабатывать большие объемы данных. Обучение будет основано на процессе построения скрапера для интернет-магазина Aliexpress.com.
Базовые знания HTML и CSS помогут лучше и быстрее освоить материал.
Обзор Scrapy

Веб-скрапинг (парсинг) стал эффективным путем извлечения информации из сети для последующего принятия решений и анализа. Он является неотъемлемым инструментом в руках специалиста в области data science. Дата сайентисты должны знать, как собирать данные с веб-страниц и хранить их в разных форматах для дальнейшего анализа.
Любую страницу в интернете можно исследовать в поисках информации, а все, что есть на странице — можно извлечь. У каждой страницы есть собственная структура и веб-элементы, из-за чего необходимо писать собственных сканеров для каждой страницы.
Scrapy предоставляет мощный фреймворк для извлечения, обработки и хранения данных.
Scrapy использует Spiders — автономных сканеров с определенным набором инструкций. С помощью фреймворка легко разработать даже крупные проекты для скрапинга, так чтобы и другие разработчики могли использовать этот код.
Scrapy vs. Beautiful Soup
В этом разделе будет дан обзор одного из самых популярных инструментов для парсинга, BeautifulSoup, и проведено его сравнение со Scrapy.
Scrapy — это Python-фреймворк, предлагающий полноценный набор инструментов и позволяющий разработчикам не думать о настройке кода.
BeautifulSoup также широко используется для веб-скрапинга. Это пакет Python для парсинга документов в форматах HTML и XML и извлечения данных из них. Он доступен для Python 2.6+ и Python 3.
Вот основные отличия между ними:
Синхронность означает, что необходимо ждать, пока процесс завершит работу, прежде чем начинать новый, а асинхронный позволяет переходить к следующему процессу, пока предыдущий еще не завершен.
Установка Scrapy
Чтобы установить Anaconda, посмотрите эти руководства PythonRu для Mac и Windows.
Также можно использовать установщик пакетов pyhton pip. Это работает в Linux, Mac и Windows:
Scrapy Shell
Scrapy предоставляет оболочку веб-сканера Scrapy Shell, которую разработчики могут использовать для проверки своих предположений относительно поведения сайта. Возьмем в качестве примера страницу с планшетами на сайте Aliexpress. С помощью Scrapy можно узнать, из каких элементов она состоит и понять, как это использовать в конкретных целях.
Откройте командную строку и напишите следующую команду:
Необходимо запустить парсер на странице с помощью команды fetch в оболочке. Он пройдет по странице, загружая текст и метаданные.
fetch(“https://www.aliexpress.com/category/200216607/tablets.html”)
Примечание: всегда заключайте ссылку в кавычки, одинарные или двойные
Вывод будет следующий:
Отобразится скрипт, который генерирует страницу. Это то же самое, что вы видите по нажатию правой кнопкой мыши в пустом месте и выборе «Просмотр кода страница» или «Просмотреть код». Но поскольку нужна конкретная информация, а не целый скрипт, с помощью инструментов разработчика в браузере необходимо определить требуемый элемент. Возьмем следующие элементы:
Нажмите правой кнопкой по элементу и кликните на «Просмотреть код».
Использование CSS-селекторов для извлечения
Извлечь эту информацию можно с помощью атрибутов элементов или CSS-селекторов в виде классов. Напишите следующее в оболочке Scrapy, чтобы получить имя продукта:
extract_first() извлекает первый элемент, соответствующий селектору css. Для извлечения всех названий нужно использовать extract() :
Следующий код извлечет ценовой диапазон этих продуктов:
То же можно повторить для количества заказов и имени магазина.
Использование XPath для извлечения
XPath — это язык запросов для выбора узлов в документах типа XML. Ориентироваться по документу можно с помощью XPath. Scrapy использует этот же язык для работы с объектами документа HTML. Использованные выше CSS-селекторы также конвертируются в XPath, но в большинстве случаев CSS очень легко использовать. И тем не менее важно значить, как язык работает в Scrapy.
Откройте оболочку и введите fetch(«https://www.aliexpress.com/category/200216607/tablets.html/») как и раньше. Попробуйте написать следующий код:
Если необходимо получить все теги
Можно и дальше фильтровать начальные узлы, чтобы получить нужные узлы с помощью атрибутов и их значений. Это синтаксис использования классов и их значений.
Используйте text() для извлечения всего текста в узлах
Создание проекта Scrapy и собственного робота (Spider)
Парсинг хорошо подходит для создания агрегатора, который будет использоваться для сравнения данных. Например, нужно купить планшет, предварительно сравнив несколько продуктов и их цены. Для этого можно исследовать все страницы и сохранить данные в файл Excel. В этом примере продолжим парсить aliexpress.com на предмет информации о планшетах.
Создадим робота (Spider) для страницы. В первую очередь необходимо создать проект Scrapy, где будут храниться код и результаты. Напишите следующее в терминале или anaconda.

| Файл/папка | Назначение |
|---|---|
| scrapy.cfg | Файл настройки развертывания |
| aliexpress/ | Модуль Python проекта, отсюда импортируется код |
| __init.py__ | Файл инициализации |
| items.py | Python файл с элементами проекта |
| pipelines.py | Файл, который содержит пайплайн проекта |
| settings.py | Файл настроек проекта |
| spiders/ | Папка, в которой будут храниться роботы |
| __init.py__ | Файл инициализации |
После создания проекта нужно перейти в новую папку и написать следующую команду:
можно использовать функцию parse() из BeautifulSoup в Scrapy для парсинга HTML-документа.
zip() берет n элементов итерации и возвращает список кортежей. Элемент с индексом i в кортеже создается с помощью элемента с индексом i каждого элемента итерации.
Теперь можно запустить робота и посмотреть результат:
Экспорт данных
Данные должны быть представлены в форматах CSV или JSON, чтобы их можно было анализировать. Этот раздел руководства посвящен тому, как получить такой файл из имеющихся данных.
Для сохранения файла CSV откройте settings.py в папке проекта и добавьте следующие строки:
Примечание: при каждом запуске паука он будет добавлять файл.
Feed Export также может добавить временную метку в имя файла. Или его можно использовать для выбора папки, куда необходимо сохранить данные.
response.url вернет URL страницы, с которой был сгенерирован ответ. После запуска парсера с помощью scrapy crawl aliexpress_tables можно просмотреть json-файл в каталоге проекта.
Следующие страницы, пагинация
Если у страницы есть последующие, в ее конце всегда будут навигационные элементы, которые позволяют перемещаться вперед и назад.
Запомните! У каждой веб-страницы собственная структура. Нужно будет изучить ее, чтобы получить желаемый элемент. Всегда экспериментируйте с response.css(SELECTOR) в Scrapy Shell, прежде чем переходить к коду.
Измените aliexpress_tabelts.py следующим образом:
Теперь можно просто расслабиться и смотреть, как робот парсит страницы. Этот извлечет все из последующих страниц. Процесс займет много времени, а размер файла будет 1,1 МБ.
Scrapy сделает для вас все!
Из этого руководства вы узнали о Scrapy, о его отличиях от BeautifulSoup, о Scrapy Shell и о создании собственных проектов. Scrapy перебирает на себя весь процесс написания кода: от создания файлов проекта и папок до обработки дублирующихся URL. Весь процесс парсинга занимает минуты, а Scrapy предоставляет поддержку всех распространенных форматов данных, которые могут быть использованы в других программах.
Теперь вы должны лучше понимать, как работает Scrapy, и как использовать его в собственных целях. Чтобы овладеть Scrapy на высоком уровне, нужно разобраться со всеми его функциями, но вы уже как минимум знаете, как эффективно парсить группы веб-страниц.