Парсинг на Python с Beautiful Soup
Парсинг — это распространенный способ получения данных из интернета для разного типа приложений. Практически бесконечное количество информации в сети объясняет факт существования разнообразных инструментов для ее сбора. В процессе скрапинга компьютер отправляет запрос, в ответ на который получает HTML-документ. После этого начинается этап парсинга. Здесь уже можно сосредоточиться только на тех данных, которые нужны. В этом материале используем такие библиотеки, как Beautiful Soup, Ixml и Requests. Разберем их.
Установка библиотек для парсинга
Чтобы двигаться дальше, сначала выполните эти команды в терминале. Также рекомендуется использовать виртуальную среду, чтобы система «оставалась чистой».
Поиск сайта для скрапинга
Для знакомства с процессом скрапинга можно воспользоваться сайтом https://quotes.toscrape.com/, который, похоже, был создан для этих целей.
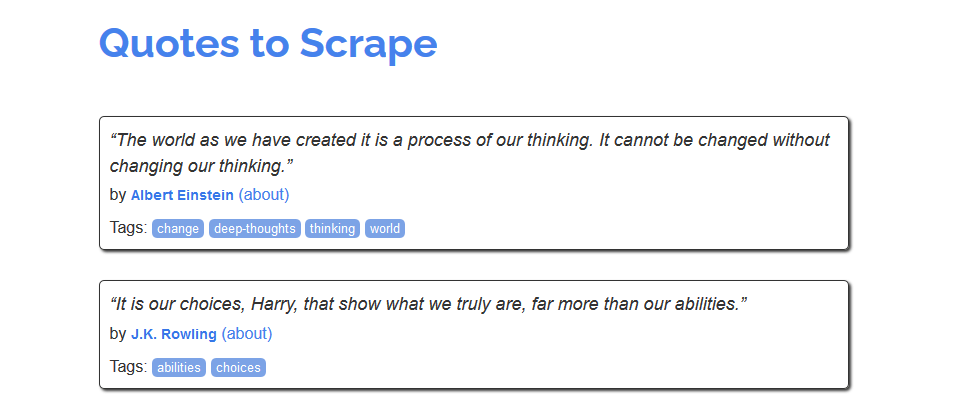
Из него можно было бы создать, например, хранилище имен авторов, тегов или самих цитат. Но как это сделать? Сперва нужно изучить исходный код страницы. Это те данные, которые возвращаются в ответ на запрос. В современных браузерах этот код можно посмотреть, кликнув правой кнопкой на странице и нажав «Просмотр кода страницы».

На экране будет выведена сырая HTML-разметка страница. Например, такая:
На этом примере можно увидеть, что разметка включает массу на первый взгляд перемешенных данных. Задача веб-скрапинга — получение доступа к тем частям страницы, которые нужны. Многие разработчики используют регулярные выражения для этого, но библиотека Beautiful Soup в Python — более дружелюбный способ извлечения необходимой информации.
Создание скрипта скрапинга
В PyCharm (или другой IDE) добавим новый файл для кода, который будет отвечать за парсинг.
Вот что происходит: ПО заходит на сайт, считывает данные, получает исходный код — все по аналогии с ручным подходом. Единственное отличие в том, что в этот раз достаточно лишь одного клика.
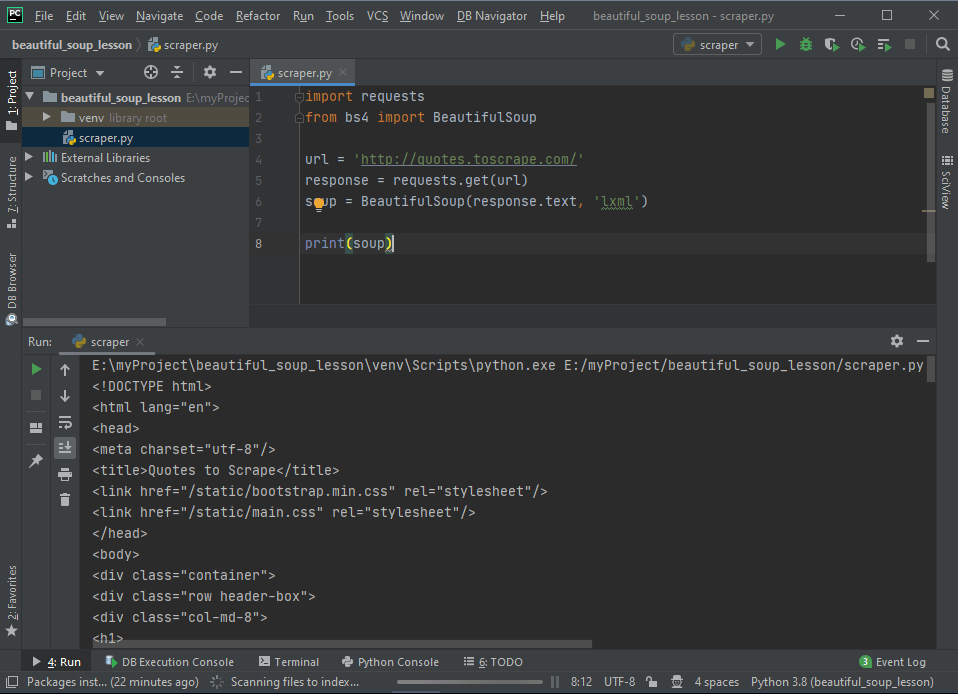
Прохождение по структуре HTML
Написанный скрипт уже получает данные о разметке из указанного адреса. Дальше нужно сосредоточиться на конкретных интересующих данных.

Таким образом и происходит дешифровка данных, которые требуется получить. Сперва нужно найти некий шаблон на странице, а после этого — создать код, который бы работал для него. Можете поводить мышью и увидеть, что это работает для всех элементов. Можно увидеть соотношение любой цитаты на странице с соответствующим тегом в коде.
Скрапинг же позволяет извлекать все похожие разделы HTML-документа. И это все, что нужно знать об HTML для скрапинга.
Парсинг HTML-разметки
Веб-парсинг на Python
Веб-парсинг на Python – это гораздо больше, чем просто извлечение контента с помощью селекторов CSS. Благодаря приемам и идеям из этой статьи вы сможете более надежно, быстро и эффективно собирать данные.
Начинаем
Сперва установите все необходимые библиотеки, запустив pip install.
Чтобы не запрашивать HTML каждый раз, мы можем сохранить его в HTML-файле и уже оттуда загружать BeautifulSoup. Чисто для демонстрации давайте сделаем это вручную. Самый простой способ – это просмотреть исходный код страницы, скопировать и вставить его в файл. Важно посетить страницу без входа в систему, как это сделал бы поисковый робот.
Получение HTML-кода может показаться простой задачей, но это далеко не так. Вообще эта тема тянет на отдельную полноценную статью, так что здесь мы затронем ее лишь вскользь. Мы советуем использовать статический подход из примера ниже, поскольку многие сайты после нескольких запросов начнут перенаправлять вас на страницу входа. Некоторые покажут капчу, и в худшем случае ваш IP будет забанен.
После статической загрузки из файла мы сможем делать сколько угодно попыток запросов, не имея проблем проблем с сетью и не опасаясь блокировки.
Изучите сайт перед тем, как начать писать код
Прежде чем начать писать программу, нужно понять содержание и структуру страницы. Это можно сделать довольно просто при помощи браузера. Мы будем использовать DevTools Chrome, но в других браузерах есть аналогичные инструменты.
Например, мы можем открыть любую страницу продукта на Amazon. Беглый просмотр покажет нам название продукта, цену, доступность и многие другие поля. Перед копированием всех этих селекторов мы рекомендуем потратить пару минут на поиск скрытых входных данных, метаданных и сетевых запросов.
Пользуясь Chrome DevTools или аналогичными инструментами, проявляйте осторожность. Контент, который вы увидите, возможно, был изменен в результате работы JavaScript и сетевых запросов. Да, это утомительно, но иногда нужно исследовать исходный HTML, чтобы избежать запуска JavaScript.
Дисклеймер: мы не будем включать URL-запрос в фрагменты кода для каждого примера. Все они похожи на первый. И помните: сохраняйте HTML-файл локально, если собираетесь протестировать его несколько раз.
Скрытые инпуты
Скрытые инпуты позволяют разработчикам включать поля ввода, которые конечные пользователи не могут видеть или изменять. Многие формы используют их для включения внутренних идентификаторов или токенов безопасности.
В продуктах Amazon мы видим, что их довольно много. Некоторые из них будут доступны в других местах или форматах, но иногда они уникальны. В любом случае имена скрытых инпутов обычно более стабильны, чем имена классов.

Метаданные
Хотя некоторый контент отображается через пользовательский интерфейс, его может быть проще извлечь с помощью метаданных. Например, можно получить количество просмотров в числовом формате и дату публикации в формате ГГГГ-ММ-ДД для видео на YouTube. Да, эти данные можно увидеть на сайте, но их можно получить и с помощью всего пары строк кода. Несколько минут на написание кода точно окупятся.
XHR-запросы
Некоторые сайты загружают пустой шаблон и вставляют в него все данные через XHR-запросы. В таких случаях проверки исходного HTML будет недостаточно. Нам нужно исследовать сеть, в частности XHR-запросы.
Возьмем, к примеру, Auction. Заполните форму с любым городом и выполните поиск. Вы будете перенаправлены на страницу результатов, которая, пока выполняются запросы для введенного вами города, представляет собой страницу-каркас.
Это вынуждает нас использовать headless-браузер, который может выполнять JavaScript и перехватывать сетевые запросы. Иногда вы можете вызвать конечную точку XHR напрямую, но обычно для этого требуются файлы cookie или другие методы аутентификации. Или вас могут немедленно забанить, поскольку это не обычный путь пользователя. Будьте осторожны.
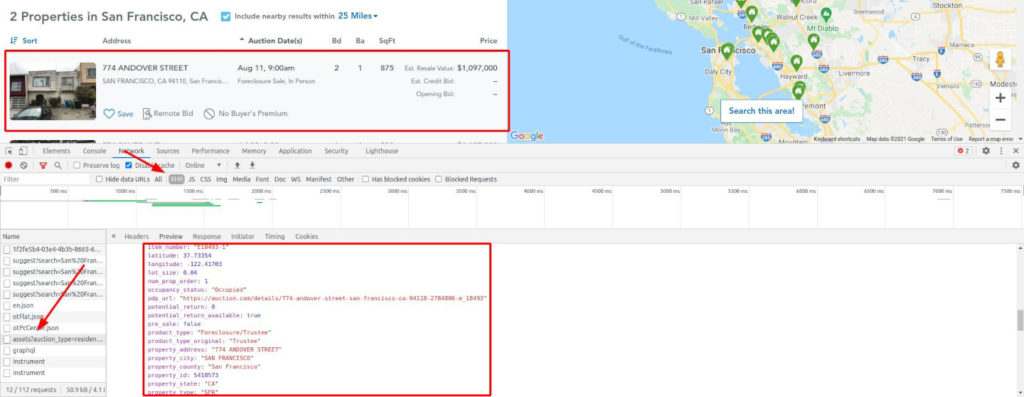
Мы наткнулись на золотую жилу! Взгляните еще раз на изображение.
Все возможные данные, уже очищенные и отформатированные, готовы к извлечению. А также геолокация, внутренние идентификаторы, цена в числовом виде без форматирования, год постройки и т. д.
Рецепты и хитрости для извлечения надежного контента
Уймите свой пыл ненадолго. Получить все с помощью селекторов CSS – это вариант, но есть еще множество других опций. Давайте рассмотрим больше инструментов и идей. Тогда вы сможете самостоятельно принимать решения, зная обо всех альтернативах.
Получение внутренних ссылок
Теперь мы начнем использовать BeautifulSoup для получения значимого контента. Эта библиотека позволяет нам получать контент по идентификаторам, классам, псевдоселекторам и т.д. Мы рассмотрим лишь небольшую часть ее возможностей.
В этом примере со страницы будут извлечены все внутренние ссылки. Упростим себе задачу и будем считать внутренними только ссылки, начинающиеся с косой черты. В более полном варианте следует проверить домен и поддомены.
Получив все эти ссылки, мы можем убрать дубликаты и поставить их в очередь для последующего парсинга. Поступая таким образом, мы могли бы создать поискового робота для всего сайта, а не только для одной страницы. Однако это уже совсем другая тема, ведь количество страниц для сканирования может увеличиваться, как снежный ком.
Марк Лутц «Изучаем Python»
Скачивайте книгу у нас в телеграм
Будьте осторожны, выполняя это автоматически. Вы можете получить сотни ссылок за несколько секунд, что приведет к слишком большому количеству запросов к одному и тому же сайту. При неосторожном обращении можно нарваться на капчу или бан.
Извлечение ссылок на социальные сети и электронную почту
Другой распространенной задачей парсинга является извлечение ссылок на соцсети и email-адресов. Точного определения для «ссылок на соцсети» нет, поэтому мы будем получать их, основываясь на домене. Что касается email-адресов, то здесь есть два варианта: ссылки «mailto» и проверка всего текста.
Для примера мы будем использовать тестовый сайт.
Для начала получим все ссылки, как в предыдущем примере. Затем переберем их, проверяя, есть ли среди них домены соцсетей или «mailto». Если да, добавим такие URL-адреса в список и выведем конечный список на экран.
Эту задачу можно решить и с помощью регулярных выражений. Конечно, если вы не дружите с regexp, это немного сложнее. Основная идея в том, что мы ищем совпадение текста с заданным паттерном.
В нашем случае паттерн — некоторое количество символов (в основном, букв и цифр), за которым идет знак @, а затем опять символы (домен), точка и еще от двух до четырех символов (домен верхнего уровня. Этому паттерну будет соответствовать, например, test@example.com.
Обратите внимание, что этот паттерн несовершенен: он не учитывает составные домены верхнего уровня, такие как co.uk.
Наше регулярное выражение можно запустить для всего контента (HTML) или только для текста. Мы используем HTML, хотя при этом полученные email-адреса будут дублироваться (они есть и в тексте, и в href).
Автоматический парсинг таблиц
HTML-таблицы все еще широко применяются на сайтах. Мы можем воспользоваться этим, поскольку они обычно структурированы и хорошо отформатированы.
Используя в качестве примера список самых продаваемых альбомов из Википедии, мы извлечем все значения в датафрейм pandas. Это простой пример, но со всеми данными нужно обращаться так, как если бы они были получены из набора данных.
Другой способ – использовать pandas и напрямую импортировать HTML, как показано ниже. При таком подходе все будет сделано за нас: первая строка будет соответствовать заголовкам, а остальные будут вставлены как контент с правильным типом. read_html() возвращает массив, поэтому мы берем первый элемент, а затем удаляем столбец, у которого нет содержимого.
Попав в датафрейм, мы можем выполнить любую операцию. Например — упорядочить по продажам, поскольку pandas преобразовала некоторые столбцы в числа. Или вывести сумму продаж. Здесь это не очень полезно, но идея понятна.
Извлечение информации не из HTML, а из метаданных
Как было замечено ранее, есть способы получить важные данные, не полагаясь на визуальный контент. Давайте рассмотрим пример с «Ведьмаком» от Netflix. Мы попробуем получить список актеров. Легко, правда?
Что, если бы мы сказали вам, что актеров и актрис четырнадцать? Вы попытаетесь получить все имена? Не прокручивайте дальше, если хотите попробовать самостоятельно.
Помните: актеров больше, чем кажется на первый взгляд. Вы знаете троих – поищите их в исходном HTML. Честно говоря, внизу есть еще одно место, где показан весь состав, но постарайтесь его избегать.
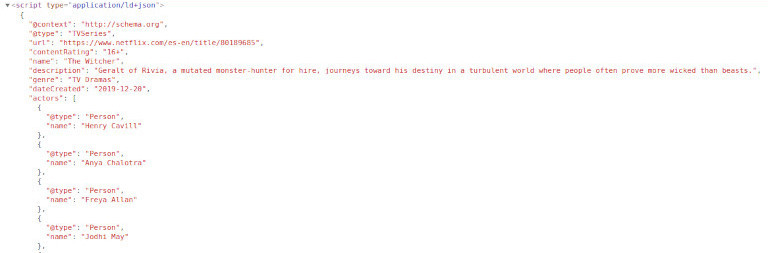
Netflix включает фрагмент Schema.org со списком актеров и актрис и многими другими данными. Как и в примере с YouTube, иногда удобнее использовать этот подход. Например, даты обычно отображаются в «машинном» формате, который более удобен при парсинге.
Разберем следующий пример, используя Instagram-профиль Билли Айлиш. После посещения нескольких страниц вы будете перенаправлены на страницу входа. Будьте осторожны при парсинге Instagram и используйте для тестирования локальный HTML-код.
Взгляните на исходный HTML. Заголовок и описание включают подписчиков, подписки и количество постов. Это может быть проблемой, поскольку они имеют строковый формат, но мы можем с этим справиться. Если мы хотим только эти данные, нам не понадобится headless-браузер. Отлично!
Скрытая информация о продукте в онлайн-магазине
Комбинируя некоторые из уже рассмотренных методов, мы хотим извлечь невидимую информацию о продукте. Наш первый пример — это eCommerce-магазин Shopify – Spigen.
Мы сможем извлечь требуемые данные наверняка: не из имени продукта и не из «хлебных крошек», поскольку мы не можем быть уверены в их надежности.

Другой пример со Shopify: nomz. Мы хотим извлечь количество оценок и среднее значение, доступные в HTML. Однако средняя оценка скрыта от просмотра с помощью CSS.
Здесь есть тег, поставленный исключительно для скринридеров, рядом с которым расположены средняя оценка и счетчик. Последние включают текст, что не является проблемой. Но мы можем добиться большего.
Это несложно, если вы изучите исходный код. Схема продукта будет первым, что вы увидите. Применяя то, чему вы научились на примере с Netflix, получите первый блок «ld + json», проанализируйте JSON, и весь контент будет доступен!
И последнее. Мы воспользуемся атрибутами данных, которые также распространены в eCommerce. Просматривая страницу с бейсбольными битами онлайн-магазина Marucci Sports, мы видим, что у каждого продукта есть несколько полезных точек данных. Цена в числовом формате, идентификатор, название продукта и категория. У нас есть все данные, которые нам могут понадобиться.
Отлично! Мы получили все данные с этой страницы. Теперь нужно проделать это со второй, а затем с третьей. Действуя постепенно, мы с большей вероятностью не нарвемся на бан.
Не забудьте преобразовать эти данные и сохранить их в CSV-файлах или в базе данных. Вложенные поля непросто экспортировать ни в один из этих форматов.
Итоги
Сегодня мы поговорили о веб-парсинге на Python. Нам бы хотелось, чтобы вы усвоили три урока:
Подробно про веб парсинг в Python с примерами
Что такое веб-парсинг в Python?
Парсинг в Python – это метод извлечения большого количества данных с нескольких веб-сайтов. Термин «парсинг» относится к получению информации из другого источника (веб-страницы) и сохранению ее в локальном файле.
Например: предположим, что вы работаете над проектом под названием «Веб-сайт сравнения телефонов», где вам требуются цены на мобильные телефоны, рейтинги и названия моделей для сравнения различных мобильных телефонов. Если вы собираете эти данные вручную, проверяя различные сайты, это займет много времени. В этом случае важную роль играет парсинг веб-страниц, когда, написав несколько строк кода, вы можете получить желаемые результаты.

Web Scrapping извлекает данные с веб-сайтов в неструктурированном формате. Это помогает собрать эти неструктурированные данные и преобразовать их в структурированную форму.
Законен ли веб-скрапинг?
Здесь возникает вопрос, является ли веб-скрапинг законным или нет. Ответ в том, что некоторые сайты разрешают это при легальном использовании. Веб-парсинг – это просто инструмент, который вы можете использовать правильно или неправильно.
Непубличные данные доступны не всем; если вы попытаетесь извлечь такие данные, это будет нарушением закона.
Есть несколько инструментов для парсинга данных с веб-сайтов, например:
Почему и зачем использовать веб-парсинг?

Необработанные данные можно использовать в различных областях. Давайте посмотрим на использование веб-скрапинга:
Широко используется для сбора данных с нескольких интернет-магазинов, сравнения цен на товары и принятия выгодных ценовых решений. Мониторинг цен с использованием данных, переданных через Интернет, дает компаниям возможность узнать о состоянии рынка и способствует динамическому ценообразованию. Это гарантирует компаниям, что они всегда превосходят других.
Web Scrapping идеально подходит для анализа рыночных тенденций. Это понимание конкретного рынка. Крупной организации требуется большой объем данных, и сбор данных обеспечивает данные с гарантированным уровнем надежности и точности.
Многие компании используют личные данные электронной почты для электронного маркетинга. Они могут ориентироваться на конкретную аудиторию для своего маркетинга.
Один новостной цикл может создать выдающийся эффект или создать реальную угрозу для вашего бизнеса. Если ваша компания зависит от анализа новостей организации, он часто появляется в новостях. Таким образом, парсинг веб-страниц обеспечивает оптимальное решение для мониторинга и анализа наиболее важных историй. Новостные статьи и платформа социальных сетей могут напрямую влиять на фондовый рынок.
Web Scrapping играет важную роль в извлечении данных с веб-сайтов социальных сетей, таких как Twitter, Facebook и Instagram, для поиска актуальных тем.
Большой набор данных, таких как общая информация, статистика и температура, удаляется с веб-сайтов, который анализируется и используется для проведения опросов или исследований и разработок.
Зачем использовать именно Python?
Есть и другие популярные языки программирования, но почему мы предпочитаем Python другим языкам программирования для парсинга веб-страниц? Ниже мы описываем список функций Python, которые делают его наиболее полезным языком программирования для сбора данных с веб-страниц.
В Python нам не нужно определять типы данных для переменных; мы можем напрямую использовать переменную там, где это требуется. Это экономит время и ускоряет выполнение задачи. Python определяет свои классы для определения типа данных переменной.
Python поставляется с обширным набором библиотек, таких как NumPy, Matplotlib, Pandas, Scipy и т. д., которые обеспечивают гибкость для работы с различными целями. Он подходит почти для каждой развивающейся области, а также для извлечения данных и выполнения манипуляций.
Целью парсинга веб-страниц является экономия времени. Но что, если вы потратите больше времени на написание кода? Вот почему мы используем Python, поскольку он может выполнять задачу в нескольких строках кода.
Python имеет открытый исходный код, что означает, что он доступен всем бесплатно. У него одно из крупнейших сообществ в мире, где вы можете обратиться за помощью, если застряли где-нибудь в коде Python.
Основы веб-парсинга
Веб-скраппинг состоит из двух частей: веб-сканера и веб-скребка. Проще говоря, веб-сканер – это лошадь, а скребок – колесница. Сканер ведет парсера и извлекает запрошенные данные. Давайте разберемся с этими двумя компонентами веб-парсинга:
 Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
Поискового робота обычно называют «пауком». Это технология искусственного интеллекта, которая просматривает Интернет, индексирует и ищет контент по заданным ссылкам. Он ищет соответствующую информацию, запрошенную программистом.
 Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Веб-скрапер – это специальный инструмент, предназначенный для быстрого и эффективного извлечения данных с нескольких веб-сайтов. Веб-скраперы сильно различаются по дизайну и сложности в зависимости от проекта.
Как работает Web Scrapping?
Давайте разберем по шагам, как работает парсинг веб-страниц.
Шаг 1. Найдите URL, который вам нужен.
Во-первых, вы должны понимать требования к данным в соответствии с вашим проектом. Веб-страница или веб-сайт содержит большой объем информации. Вот почему отбрасывайте только актуальную информацию. Проще говоря, разработчик должен быть знаком с требованиями к данным.
Шаг – 2: Проверка страницы
Данные извлекаются в необработанном формате HTML, который необходимо тщательно анализировать и отсеивать мешающие необработанные данные. В некоторых случаях данные могут быть простыми, такими как имя и адрес, или такими же сложными, как многомерные данные о погоде и данные фондового рынка.
Шаг – 3: Напишите код
Напишите код для извлечения информации, предоставления соответствующей информации и запуска кода.
Шаг – 4: Сохраните данные в файле
Сохраните эту информацию в необходимом формате файла csv, xml, JSON.
Начало работы с Web Scrapping
Давайте разберемся с необходимой библиотекой для Python. Библиотека, используемая для разметки веб-страниц.
Примечание. Рекомендуется использовать IDE PyCharm.

BeautifulSoup – это библиотека Python, которая используется для извлечения данных из файлов HTML и XML. Она в основном предназначена для парсинга веб-страниц. Работает с анализатором, обеспечивая естественный способ навигации, поиска и изменения дерева синтаксического анализа. Последняя версия BeautifulSoup – 4.8.1.
Давайте подробно разберемся с библиотекой BeautifulSoup.
Установка BeautifulSoup
Вы можете установить BeautifulSoup, введя следующую команду:
BeautifulSoup поддерживает парсер HTML и несколько сторонних парсеров Python. Вы можете установить любой из них в зависимости от ваших предпочтений. Список парсеров BeautifulSoup:
| Парсер | Типичное использование |
|---|---|
| Python’s html.parser | BeautifulSoup (разметка, “html.parser”) |
| lxml’s HTML parser | BeautifulSoup (разметка, «lxml») |
| lxml’s XML parser | BeautifulSoup (разметка, «lxml-xml») |
| Html5lib | BeautifulSoup (разметка, “html5lib”) |
Мы рекомендуем вам установить парсер html5lib, потому что он больше подходит для более новой версии Python, либо вы можете установить парсер lxml.
Введите в терминале следующую команду:

BeautifulSoup используется для преобразования сложного HTML-документа в сложное дерево объектов Python. Но есть несколько основных типов объектов, которые чаще всего используются:
Объект Tag соответствует исходному документу XML или HTML.
Тег содержит множество атрибутов и методов, но наиболее важными особенностями тега являются имя и атрибут.
Тег может иметь любое количество атрибутов. Тег имеет атрибут “id”, значение которого – “boldest”. Мы можем получить доступ к атрибутам тега, рассматривая тег как словарь.
Мы можем добавлять, удалять и изменять атрибуты тега. Это можно сделать, используя тег как словарь.
В HTML5 есть некоторые атрибуты, которые могут иметь несколько значений. Класс (состоит более чем из одного css) – это наиболее распространенный многозначный атрибут. Другие атрибуты: rel, rev, accept-charset, headers и accesskey.
Строка в BeautifulSoup ссылается на текст внутри тега. BeautifulSoup использует класс NavigableString для хранения этих фрагментов текста.
Неизменяемая строка означает, что ее нельзя редактировать. Но ее можно заменить другой строкой с помощью replace_with().
В некоторых случаях, если вы хотите использовать NavigableString вне BeautifulSoup, unicode() помогает ему превратиться в обычную строку Python Unicode.
Объект BeautifulSoup представляет весь проанализированный документ в целом. Во многих случаях мы можем использовать его как объект Tag. Это означает, что он поддерживает большинство методов, описанных для навигации по дереву и поиска в дереве.
Пример парсера
Давайте разберем пример, чтобы понять, что такое парсер на практике, извлекая данные с веб-страницы и проверяя всю страницу.
Для начала откройте свою любимую страницу в Википедии и проверьте всю страницу, перед извлечением данных с веб-страницы вы должны убедиться в своих требованиях. Рассмотрим следующий код:
В следующих строках кода мы извлекаем все заголовки веб-страницы по имени класса. Здесь знания внешнего интерфейса играют важную роль при проверке веб-страницы.
В приведенном выше коде мы импортировали bs4 и запросили библиотеку. В третьей строке мы создали объект res для отправки запроса на веб-страницу. Как видите, мы извлекли весь заголовок с веб-страницы.

Веб-страница Wikipedia Learning
Давайте разберемся с другим примером: мы сделаем GET-запрос к URL-адресу и создадим объект дерева синтаксического анализа (soup) с использованием BeautifulSoup и встроенного в Python парсера “html5lib”.
Здесь мы удалим веб-страницу по указанной ссылке (https://www.javatpoint.com/). Рассмотрим следующий код:
Приведенный выше код отобразит весь html-код домашней страницы javatpoint.
Используя объект BeautifulSoup, то есть soup, мы можем собрать необходимую таблицу данных. Напечатаем интересующую нас информацию с помощью объекта soup:
Выход даст следующий результат:
Выход: это даст следующий результат:
Вывод: он напечатает все ссылки вместе со своими атрибутами. Здесь мы отображаем некоторые из них:
Программа: извлечение данных с веб-сайта Flipkart
В этом примере мы удалим цены, рейтинги и название модели мобильных телефонов из Flipkart, одного из популярных веб-сайтов электронной коммерции. Ниже приведены предварительные условия для выполнения этой задачи:
Шаг – 1: найдите нужный URL.
Первым шагом является поиск URL-адреса, который вы хотите удалить. Здесь мы извлекаем детали мобильного телефона из Flipkart. URL-адрес этой страницы: https://www.flipkart.com/search?q=iphones&otracker=search&otracker1=search&marketplace=FLIPKART&as-show=on&as=off.
Шаг 2: проверка страницы.
Необходимо внимательно изучить страницу, поскольку данные обычно содержатся в тегах. Итак, нам нужно провести осмотр, чтобы выбрать нужный тег. Чтобы проверить страницу, щелкните элемент правой кнопкой мыши и выберите «Проверить».
Шаг – 3: найдите данные для извлечения.
Извлеките цену, имя и рейтинг, которые содержатся в теге «div» соответственно.
Шаг – 4: напишите код.

Мы удалили детали iPhone и сохранили их в файле CSV, как вы можете видеть на выходе. В приведенном выше коде мы добавили комментарий к нескольким строкам кода для тестирования. Вы можете удалить эти комментарии и посмотреть результат.