Простой Telegram-бот на Python за 30 минут
На Хабре, да и не только, про ботов рассказано уже так много, что даже слишком. Но заинтересовавшись пару недель назад данной темой, найти нормальный материал у меня так и не вышло: все статьи были либо для совсем чайников и ограничивались отправкой сообщения в ответ на сообщение пользователя, либо были неактуальны. Это и подтолкнуло меня на написание статьи, которая бы объяснила такому же новичку, как я, как написать и запустить более-менее осмысленного бота (с возможностью расширения функциональности).
Часть 1: Регистрация бота
Самая простая и описанная часть. Очень коротко: нужно найти бота @BotFather, написать ему /start, или /newbot, заполнить поля, которые он спросит (название бота и его короткое имя), и получить сообщение с токеном бота и ссылкой на документацию. Токен нужно сохранить, желательно надёжно, так как это единственный ключ для авторизации бота и взаимодействия с ним.
Часть 2: Подготовка к написанию кода
Как уже было сказано в заголовке, писать бота мы будем на Python’е. В данной статье будет описана работа с библиотекой PyTelegramBotAPI (Telebot). Если у вас не установлен Python, то сперва нужно сделать это: в терминале Linux нужно ввести
После, в терминале Linux, или командной строке Windows вводим
Теперь все готово для написания кода.
Часть 3: Получаем сообщения и говорим «Привет»
Небольшое отступление. Телеграмм умеет сообщать боту о действиях пользователя двумя способами: через ответ на запрос сервера (Long Poll), и через Webhook, когда сервер Телеграмма сам присылает сообщение о том, что кто-то написал боту. Второй способ явно выглядит лучше, но требует выделенного IP-адреса, и установленного SSL на сервере. В этой статье я хочу рассказать о написании бота, а не настройке сервера, поэтому пользоваться мы будем Long Poll’ом.
Открывайте ваш любимый текстовый редактор, и давайте писать код бота!
Первое, что нужно сделать это импортировать нашу библиотеку и подключить токен бота:
Теперь объявим метод для получения текстовых сообщений:
В этом участке кода мы объявили слушателя для текстовых сообщений и метод их обработки. Поле content_types может принимать разные значения, и не только одно, например
Будет реагировать на текстовые сообщения, документы и аудио. Более подробно можно почитать в официальной документации
Теперь добавим в наш метод немного функционала: если пользователь напишет нам «Привет», то скажем ему «Привет, чем я могу помочь?», а если нам напишут команду «/help», то скажем пользователю написать «Привет»:
Данный участок кода не требует комментариев, как мне кажется. Теперь нужно добавить в наш код только одну строчку (вне всех методов).
Теперь наш бот будет постоянно спрашивать у сервера Телеграмма «Мне кто-нибудь написал?», и если мы напишем нашему боту, то Телеграмм передаст ему наше сообщение. Сохраняем весь файл, и пишем в консоли
Где bot.py – имя нашего файла.
Теперь можно написать боту и посмотреть на результат:
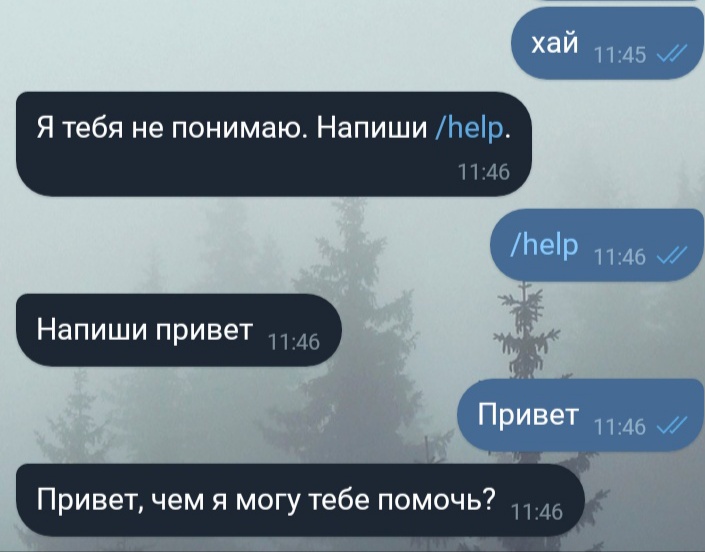
Часть 4: Кнопки и ветки сообщений
Отправлять сообщения это несомненно весело, но ещё веселее вести с пользователем диалог: задавать ему вопросы и получать на них ответы. Допустим, теперь наш бот будет спрашивать у пользователя по очереди его имя, фамилию и возраст. Для этого мы будем использовать метод register_next_step_handler бота:
И так, данные пользователя мы записали. В этом примере показан очень упрощённый пример, по хорошему, хранить промежуточные данные и состояния пользователя нужно в БД, но мы сегодня работаем с ботом, а не с базами данных. Последний штрих – запросим у пользователей подтверждение того, что все введено верно, да не просто так, а с кнопками! Для этого немного отредактируем код метода get_age
И теперь наш бот отправляет клавиатуру, но если на нее нажать, то ничего не произойдёт. Потому что мы не написали метод-обработчик. Давайте напишем:
Остаётся только дописать в начало файла одну строку:
Вот и всё, сохраняем и запускаем нашего бота:
Создание простого разговорного чатбота в python
Как вы думаете, сложно ли написать на Python собственного чатбота, способного поддержать беседу? Оказалось, очень легко, если найти хороший набор данных. Причём это можно сделать даже без нейросетей, хотя немного математической магии всё-таки понадобится.
Идти будем маленькими шагами: сначала вспомним, как загружать данные в Python, затем научимся считать слова, постепенно подключим линейную алгебру и теорвер, и под конец сделаем из получившегося болтательного алгоритма бота для Телеграм.
Этот туториал подойдёт тем, кто уже немножко трогал пальцем Python, но не особо знаком с машинным обучением. Я намеренно не пользовался никакими nlp-шными библиотеками, чтобы показать, что нечто работающее можно собрать и на голом sklearn.

Поиск ответа в диалоговом датасете
Год назад меня попросили показать ребятам, которые прежде не занимались анализом данных, какое-нибудь вдохновляющее приложение машинного обучения, которое можно собрать самостоятельно. Я попробовал собрать вместе с ними бота-болталку, и у нас это действительно получилось за один вечер. Процесс и результат нам понравились, и написал об этом в своем блоге. А теперь подумал, что и Хабру будет интересно.
Итак, начинаем. Наша задача — сделать алгоритм, который на любую фразу будет давать уместный ответ. Например, на «как дела?» отвечать «отлично, а у тебя?». Самый простой способ добиться этого — найти готовую базу вопросов и ответов. Например, взять субтитры из большого количества кинофильмов.
Я, впрочем, поступлю ещё более по-читерски, и возьму данные из соревнования Яндекс.Алгоритм 2018 — это те же диалоги из фильмов, для которых работники Толоки разметили хорошие и неплохие продолжения. Яндекс собирал эти данные, чтобы обучать Алису (статьи о её кишках 1, 2, 3). Собственно, Алисой я и был вдохновлен, когда придумывал этого бота. В таблице от Яндекса даны три последних фразы и ответ на них (reply), но мы будем пользоваться только самой последней из них (context_0).

Векторизация текстов
Теперь говорим о том, как превратить тексты в числовые векторы, чтобы осуществлять по ним приближённый поиск.
Мы уже познакомились с библиотекой pandas в Python — она позволяет загружать таблицы, осуществлять поиск в них, и т.п. Теперь затронем библиотеку scikit-learn (sklearn), которая позволяет более хитрые манипуляции с данными — то, что называется машинным обучением. Это значит, что любому алгоритму сперва нужно показать данные (fit), чтобы он узнал о них что-то важное. В результате алгоритм «научится» делать с этими данными что-то полезное — преобразовывать их (transform), или даже предсказывать неизвестные величины (predict).
В данном случае мы хотим преобразовать тексты («вопросы») в числовые векторы. Это нужно, чтобы можно было находить «близкие» друг к другу тексты, пользуясь математическим понятием расстояние. Расстояние между двумя точками можно рассчитать по теореме Пифагора — как корень из суммы квадратов разностей их координат. В математике это называется Евклидовой метрикой. Если мы сможем превращать тексты в объекты, у которых есть координаты, то мы сможем вычислять Евклидову метрику и, например, находить в базе вопрос, наиболее всего похожий на «о чём ты думаешь?».
Самый простой способ задать координаты текста — это пронумеровать все слова в языке, и сказать, что i-тая координата текста равна числу вхождений в него i-того слова. Например, для текста «я не могу не плакать» координата слова «не» равна 2, координаты слов «я», «могу» и «плакать» равны 1, а координаты всех остальных слов (коих десятки тысяч) равны 0. Такое представление теряет информацию о порядке слов, но всё равно работает неплохо.
Проблема в том, что у слов, которые встречаются часто (например, частиц «и» и «а») координаты будут несоразмерно большие, хотя информации они несут мало. Чтобы смягчить эту проблему, координату каждого слова можно поделить на логарифм числа текстов, где такое слово встречается — это называется tf-idf и тоже работает неплохо.

Проблема только одна: в нашей базе 60 тысяч текстовых «вопросов», в которых содержится 14 тысяч различных слов. Если превратить все вопросы в векторы, получится матрица 60к*14к. Работать с такой не очень классно, поэтому дальше мы поговорим о сокращении размерности.
Сокращение размерности
Мы уже поставили задачу создания болталочного чатбота, скачали и векторизовали данные для его обучения. Теперь у нас есть числовая матрица, представляющая реплики пользователей. Она состоит из 60 тысяч строк (столько было реплик в базе диалогов) и 14 тысяч столбцов (столько в них было различных слов). Сейчас наша задача — сделать её поменьше. Например, представить каждый текст не 14123-мерным, а всего лишь 300-мерным вектором.
Достичь этого можно, умножив нашу матрицу размера 60049х14123 на специально подобранную матрицу проекции размера 14123х300, в итоге получим результат 60049х300. Алгоритм PCA (метод главных компонент) подбирает матрицу проекции так, чтобы исходную матрицу можно было потом восстановить с наименьшей среднеквадратической ошибкой. В нашем случае получилось сохранить около 44% об исходной матрице, хотя размерность сократилась почти в 50 раз.

За счёт чего возможно такое эффективное сжатие? Напомним, что исходная матрица содержит счётчики упоминания отдельных слов в текстах. Но слова, как правило, употреблятся не независимо друг от друга, а в контексте. Например, чем больше раз в тексте новости встречается слово «блокировка», тем больше раз, скорее всего в этом тексте встретится также слово «телеграм». А вот корреляция слова «блокировка», например, со словом «кафтан» отрицательная — они встречаются в разных контекстах.
Так вот, получается, что метод главных компонент запоминает не все 14 тысяч слов, а 300 типовых контекстов, по которым эти слова потом можно пытаться восстановить. Столбцы матрицы проекции, соответствующие синонимичным словам, обычно похожи друг на друга, потому что эти слова часто встречаются в одном контексте. А значит, можно сократить избыточные измерения, не потеряв при этом в информативности.
Во многих современных приложениях матрицу проекции слов вычисляют нейросети (например, word2vec). Но на самом деле простой линейной алгебры для практически полезного результата уже достаточно. Метод главных компонент вычислительно сводится к SVD, а оно — к расчёту собственных векторов и собственных чисел матрицы. Впрочем, программировать это можно, даже не зная деталей.
Поиск ближайших соседей
В предыдущих разделах мы закачали в python корпус диалогов, векторизовали его, и сократили размерность, а теперь хотим наконец научиться искать в нашем 300-мерном пространстве ближайших соседей и наконец-то осмысленно отвечать на вопросы.
Поскольку научились отображать вопросы в Евклидово пространство не очень высокой размерности, поиск соседей в нём можно осуществлять довольно быстро. Мы воспользуемся уже готовым алгоритмом поиска соседей BallTree. Но мы напишем свою модель-обёртку, которая выбирала бы одного из k ближайших соседей, причём чем ближе сосед, тем выше вероятность его выбора. Ибо брать всегда одного самого близкого соседа — скучно, но не завязываться на сходство совсем — опасно.
Поэтому мы хотим превратить найденные расстояния от запроса до текстов-эталонов в вероятности выбора этих текстов. Для этого можно использовать функцию softmax, которая ещё часто стоит на выходе из нейросетей. Она превращает свои аргументы в набор неотрицательных чисел, сумма которых равна 1 — как раз то, что нам нужно. Дальше полученные «вероятности» мы можем использовать для случайного выбора ответа.

Фразы, которые будет вводить пользователь, надо пропускать через все три алгоритма — векторизатор, метод главных компонент, и алгоритм выбора ответа. Чтобы писать меньше кода, можно связать их в единую цепочку (pipeline), применяющую алгоритмы последовательно.
В результате мы получили алгоритм, который по вопросу пользователя способен найти похожий на него вопрос и выдать ответ на него. И иногда это ответы даже звучат почти осмысленно.

Публикация бота в Telegram
Мы уже разобрались, как сделать чатбота-болталку, который бы выдавал примерно уместные ответы на запросы пользователя. Теперь показываю, как выпустить такого чатбота в Телеграм.
Проще всего использовать для этого готовую обёртку Telegram API для питона — например, pytelegrambotapi. Итак, пошаговая инструкция:
Полный код к статье я намеренно не выкладываю — вы получите гораздо больше удовольствия и полезного опыта, когда напечатаете его сами, и получите работающего бота в результате собственных усилий. Ну или если вам очень лень это делать, можете поболтать с моей версией ботика.
Пишем чат-бот на Python + PostgreSQL и Telegram
Пошаговое руководство написания чат-бота на языке Python.
Установим Python и библиотеки;
Получим вопросы и ответы из БД PostgreSQL;
Подключим чат-бот к каналу Telegram.
Colaboratory от Google
Изучение Python можно начать используя сервис Colaboratory от Google, или просто Colab. Сервис позволяет писать и выполнять код Python в браузере, не требуя собственного сервера.
Пример кода. Вопросы и ответы для чат-бота подгрузим с https://drive.google.com из текстового файла
Запуск в Production
Наигравшись с кодом в Colaboratory и освоив Python развернем систему на боевом сервере Debian
Установим Python и PIP (установщик пакетов).
Так как Debian не самый новый, устанавливается версия 3.5
Установим необходимые пакеты Python
Пишем код в файле Chat_bot.py
Структура таблицы ответов chats_answer, формат SQL
Да, я готов об этом поговорить
Структура таблицы вопросов chats_question, формат SQL. Каждый вопрос связан с кодом ответа.
Лет то тебе сколько
Поговорим о возрасте
Трейлер фильма Матрица
Продолжаем код в файле Chat_bot.py
Векторизация и трансформация
Функция поиска ответа
Проверка из консоли
Запустим и проверим
Подключим Telegram
Откроем Telegram и обратимся к боту @BOTFATHER https://t.me/botfather
Все просто, зарегистрируем нового бота и получим token.
В целом все готово. Вопросы в базу данных добавляются автоматически от службы тех. поддержки. Остаётся маркетологу в админ панели на YII назначать ответы вопросам. Раз в сутки cron перезапускает скрипт чат-бота, новые фразы поступают в работу.
Весь код чат бота
В теле программы есть переменные k=5 и temperature=10.0. Их можно менять, что будет влиять на поиск, делая его более мягким или более жестким.
Питоном по телеграму! Пишем пять простых Telegram-ботов на Python

Содержание статьи
Python для новичков
Если ты совсем не ориентируешься в Python, то отличным началом будет прочтение трех вводных статей, которые я публиковал в «Хакере» этим летом, либо посещение курса «Python для новичков», который я начну вести для читателей «Хакера» уже совсем скоро — 30 ноября.
Чтобы создать бота, нам нужно дать ему название, адрес и получить токен — строку, которая будет однозначно идентифицировать нашего бота для серверов Telegram. Зайдем в Telegram под своим аккаунтом и откроем «отца всех ботов», BotFather.
Жмем кнопку «Запустить» (или отправим / start ), в ответ BotFather пришлет нам список доступных команд:
Когда мы наконец найдем свободный и красивый адрес для нашего бота, в ответ получим сообщение, в котором после фразы Use this token to access the HTTP API будет написана строка из букв и цифр — это и есть необходимый нам токен. Сохраним ее где‑нибудь на своем компьютере, чтобы потом использовать в скрипте бота.
Для взаимодействия с Telegram API есть несколько готовых модулей. Самый простой из них — Telebot. Чтобы установить его, набери
Эхо-бот
Для начала реализуем так называемого эхо‑бота. Он будет получать от пользователя текстовое сообщение и возвращать его.
Как создать чат-бота с нуля на Python: подробная инструкция

Аналитики Gartner утверждают, что к 2020 году 85% взаимодействий клиентов с сервисами сведется к общению с чат-ботами. В 2018 году они уже обрабатывают около 30% операций. В этой статье мы расскажем, как создать своего чат-бота на Python.
Возможно, вы слышали о Duolingo: популярном приложении для изучения иностранных языков, в котором обучение проходит в форме игры. Duolingo популярен благодаря инновационному стилю обучения. Концепция проста: от пяти до десяти минут интерактивного обучения в день достаточно, чтобы выучить язык.
Н есмотря на то что Duolingo позволяет изучить новый язык, у пользователей сервиса возникла проблема. Они почувствовали, что не развивают разговорные навыки, так как обучаются самостоятельно. Пользователи неохотно обучались в парах из-за смущения. Эта проблема не осталась незамеченной для разработчиков.
Команда сервиса решила проблему, создав чат-бота в приложении, чтобы помочь пользователям получать разговорные навыки и применять их на практике.
Поскольку боты разрабатывались так, чтобы быть разговорчивыми и дружелюбными, пользователи Duolingo практикуются в общении в удобное им время, выбирая «собеседника» из набора, пока не поборят смущение в достаточной степени, чтобы перейти к общению с другими пользователями. Это решило проблему пользователей и ускорило обучение через приложение.
Итак, что такое чат-бот?
Чат-бот — это программа, которая выясняет потребности пользователей, а затем помогает удовлетворить их (денежная транзакция, бронирование отелей, составление документов). Сегодня почти каждая компания имеет чат-бота для взаимодействия с пользователями. Некоторые способы использования чат-ботов:
История чат-ботов восходит к 1966 году, когда Джозеф Вейценбаум разработал компьютерную программу ELIZA. Программа подражает манере речи психотерапевта и состоит лишь из 200 строк кода. Пообщаться с Элизой можно до сих пор на сайте.
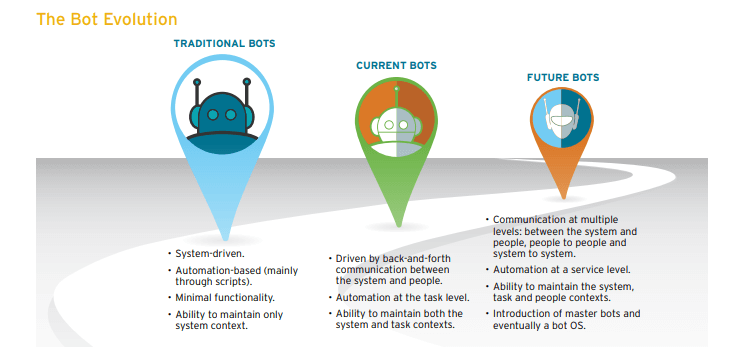
Как работает чат-бот?
Существует два типа ботов: работающие по правилам и самообучающиеся.
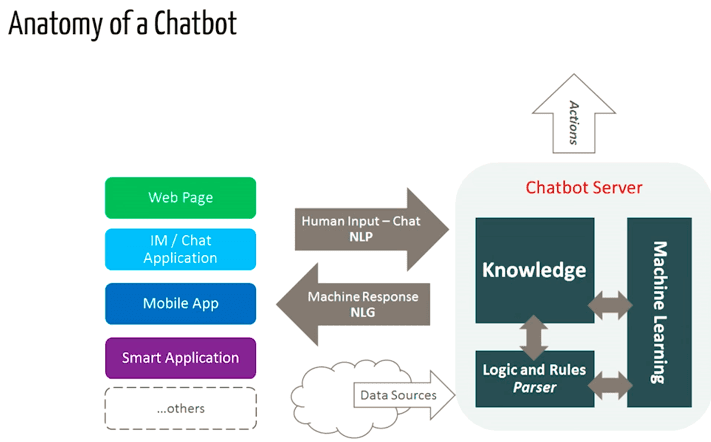
В поисковых ботах используются эвристические методы для выбора ответа из библиотеки предопределенных реплик. Такие чат-боты используют текст сообщения и контекст диалога для выбора ответа из предопределенного списка. Контекст включает в себя текущее положение в древе диалога, все предыдущие сообщения и сохраненные ранее переменные (например, имя пользователя). Эвристика для выбора ответа может быть спроектирована по-разному : от условной логики «или-или» до машинных классификаторов.
Генеративные боты могут самостоятельно создавать ответы и не всегда отвечают одним из предопределенных вариантов. Это делает их интеллектуальными, так как такие боты изучают каждое слово в запросе и генерируют ответ.
В этой статье мы научимся писать код простых поисковых чат-ботов на основе библиотеки NLTK.
Создание бота на Python
Предполагается, что вы умеете пользоваться библиотеками scikit и NLTK. Однако, если вы новичок в обработке естественного языка (NLP), вы все равно можете прочитать статью, а затем изучить соответствующую литературу.
Обработка естественного языка (NLP)
Обработка естественного языка — это область исследований, в которой изучается взаимодействие между человеческим языком и компьютером. NLP основана на синтезе компьютерных наук, искусственного интеллекта и вычислительной лингвистики. NLP — это способ для компьютеров анализировать, понимать и извлекать смысл из человеческого языка разумным и полезным образом.
Краткое введение в NLKT
NLTK (Natural Language Toolkit) — платформа для создания программ на Python для работы с естественной речью. NLKT предоставляет простые в использовании интерфейсы для более чем 50 корпораций и лингвистических ресурсов, таких как WordNet, а также набор библиотек для обработки текста в целях классификации, токенизации, генерации, тегирования, синтаксического анализа и понимания семантики, создания оболочки библиотек NLP для коммерческого применения.
Книга Natural Language Processing with Python — практическое введение в программирование для обработки языка. Рекомендуем ее прочитать, если вы владеете английским языком.
Загрузка и установка NLTK
Инструкции для конкретных платформ смотрите здесь.
Установка пакетов NLTK
Импортируйте NLTK и запустите nltk.download(). Это откроет загрузчик NLTK, где вы сможете выбрать версию кода и модели для загрузки. Вы также можете загрузить все пакеты сразу.
Предварительная обработка текста с помощью NLTK
Основная проблема с данными заключается в том, что они представлены в текстовом формате. Для решения задач алгоритмами машинного обучения требуется некий вектор свойств. Поэтому прежде чем начать создавать проект по NLP, нужно предварительно обработать его. Предварительная обработка текста включает в себя:
Пакет NLTK включает в себя предварительно обученный токенизатор Punkt для английского языка.
Набор слов
После первого этапа предварительной обработки нужно преобразовать текст в вектор (или массив) чисел. «Набор слов» — это представление текста, описывающего наличие слов в тексте. «Набор слов» состоит из:
Почему используется слово «набор»? Это связано с тем, что информация о порядке или структуре слов в тексте отбрасывается, и модель учитывает только то, как часто определенные слова встречаются в тексте, но не то, где именно они находятся.
Идея «набора слов» состоит в том, что тексты похожи по содержанию, если включают в себя похожие слова. Кроме того, кое-что узнать о содержании текста можно лишь по набору слов.
Например, если словарь содержит слова
Метод TF-IDF
Проблема «набора слов» заключается в том, что в тексте могут доминировать часто встречающиеся слова, которые не содержат ценную для нас информацию. Также «набор слов» присваивает большую важность длинным текстам по сравнению с короткими.
Один из подходов к решению этих проблем состоит в том, чтобы вычислять частоту появления слова не в одном тексте, а во всех сразу. За счет этого вклад, например, артиклей «a» и «the» будет нивелирован. Такой подход называется TF-IDF (Term Frequency-Inverse Document Frequency) и состоит из двух этапов:
Коэффициент TF-IDF — это вес, часто используемый для обработки информации и интеллектуального анализа текста. Он является статистической мерой, используемой для оценки важности слова для текста в некотором наборе текстов.
Пример
Рассмотрим текст, содержащий 100 слов, в котором слово «телефон» появляется 5 раз. Параметр TF для слова «телефон» равен (5/100) = 0,05.
Теперь предположим, что у нас 10 миллионов документов, и слово телефон появляется в тысяче из них. Коэффициент вычисляется как 1+log(10 000 000/1000) = 4. Таким образом, TD-IDF равен 0,05 * 4 = 0,20.
TF-IDF может быть реализован в scikit так:
Коэффициент Отиаи
TF-IDF — это преобразование, применяемое к текстам для получения двух вещественных векторов в векторном пространстве. Тогда мы можем получить коэффициент Отиаи любой пары векторов, вычислив их поэлементное произведение и разделив его на произведение их норм. Таким образом, получается косинус угла между векторами. Коэффициент Отиаи является мерой сходства между двумя ненулевыми векторами. Используя эту формулу, можно вычислить схожесть между любыми двумя текстами d1 и d2.
Здесь d1, d2 — два ненулевых вектора.
Подробное объяснение и практический пример TF-IDF и коэффициента Отиаи приведены в посте по ссылке.
Пришло время перейти к решению нашей задачи, то есть созданию чат-бота. Назовем его «ROBO».
Обучение чат-бота
В нашем примере мы будем использовать страницу Википедии в качестве текста. Скопируйте содержимое страницы и поместите его в текстовый файл под названием «chatbot.txt». Можете сразу использовать другой текст.
Импорт необходимых библиотек
Чтение данных
Выполним чтение файла corpus.txt и преобразуем весь текст в список предложений и список слов для дальнейшей предварительной обработки.
Давайте рассмотрим пример файлов sent_tokens и word_tokens
Предварительная обработка исходного текста
Теперь определим функцию LemTokens, которая примет в качестве входных параметров токены и выдаст нормированные токены.
Подбор ключевых слов
Определим реплику-приветствие бота. Если пользователь приветствует бота, бот поздоровается в ответ. В ELIZA используется простое сопоставление ключевых слов для приветствий. Будем использовать ту же идею.
Генерация ответа
Чтобы сгенерировать ответ нашего бота для ввода вопросов, будет использоваться концепция схожести текстов. Поэтому мы начинаем с импорта необходимых модулей.
Этот модуль будет использоваться для поиска в запросе пользователя ключевых слов. Это самый простой способ создать чат-бота.
Определим функцию отклика, которая возвращает один из нескольких возможных ответов. Если запрос не соответствует ни одному ключевому слову, бот выдает ответ «Извините! Я вас не понимаю».
Наконец, мы задаем реплики бота в начале и конце переписки, в зависимости от реплик пользователя.
Вот и все. Мы написали код нашего первого бота в NLTK. Здесь вы можете найти весь код вместе с текстом. Теперь давайте посмотрим, как он взаимодействует с людьми:

Получилось не так уж плохо. Даже если чат-бот не смог дать удовлетворительного ответа на некоторые вопросы, он хорошо справился с другими.
Заключение
Хотя наш примитивный бот едва ли обладает когнитивными навыками, это был неплохой способ разобраться с NLP и узнать о работе чат-ботов. «ROBO», по крайней мере, отвечает на запросы пользователя. Он, конечно, не обманет ваших друзей, и для коммерческой системы вы захотите рассмотреть одну из существующих бот-платформ или фреймворки, но этот пример поможет вам продумать архитектуру бота.