Создание простого чат-бота в VK на Python 3
Создание основы для работы бота будет состоять из следующих этапов:
Для кого эта статья?
Статья рассчитана для начинающих программистов. Метод работы программы очень прост и любой, кто умеет разбираться в синтаксисе Питона и немного знающий ООП сможет его реализовать для своих нужд. Но в принципе даже не зная никаких принципов ООП, думаю можно научиться добавлять простые функции или хотя бы в крайнем случае использовать готовые исходники из GitHub.
Что есть в этой статье?
Создание основы бота. После этого его можно будет запрограммировать как-угодно. Автоматизировать какую-то рутину или использовать как собеседник.
Улучшенная (слегка усложненная версия бота). Я решил сначала представить простой процедурный код бота, а затем слегка усложнить его, добавив функции, значительно улучшающие работу бота.
Добавление функции передачи погоды. Научим бота говорить нам погоду.
Создание бота в ВК
Начнем мы с создания бота, а именно группу в ВК.
Для это нужно зайти в «группы» → «создать сообщество».
Выберите любой тип сообщества и введите название, тематику группы.
На открывшейся странице настроек, выберите «Работа с API»
Далее, необходимо создать API-ключ.
Затем выберите нужные вам параметры с доступом для вашего API-ключа.
Скорее всего, вам придётся подтверждать действие в ВК с помощью мобильного телефона. Затем скопируйте полученный API-ключ где-нибудь в файл. Он нам еще понадобится.
Затем нужно разрешить сообщения. Для этого переходим в «сообщения» и включаем их.
Приступим к программной части бота
Мы не будем реализовывать его через запросы к ВК, а если быть точнее, просто используем библиотеку VkLongPool, которая сделает это за нас.
Для этого необходима библиотека vk_api. Установим его через pip:
Но лично я работаю с виртуальным окружением Anaconda. С этим зачастую возникают проблемы при первой работе. Обычно проблема в том, что система не распознают команду «python». А решается эта проблема путем добавления его в PATH.
Приступим к самому коду:
Импортируем нужные модули:
Авторизовавшись как сообщество и настроив longpool:
В нем мы циклически будем проверять на наличие event-ов. А получить тип event-а сможем с помощью event.type.
После этого получив сообщение от пользователя сможем отправить ему соответствующее письмо с помощью уже созданной функции write_msg.
Итак, мы создали очень простого бота в ВК с такой же простой реализацией. А логику бота можно программировать как душе угодно.
Теперь приступим к более реальному программированию
Создадим класс VkBot в файле vk_bot.py, который будет служить нам ботом.
И добавим туда метод с помощью которого можно получить имя пользователя через vk id.
Это делается с помощью beatifulsoup4.
Устанавливаем если его нет:
На него есть достаточное количество статей, которые стоит изучить. С помощью него же создадим еще несколько методов:
Измените параметр _get_weather на нужный город, в последствии этот метод можно будет вызывать с указанием города, а по умолчанию будет ваше указанное значение.
С помощью этих методов мы сможем получить время и погоду. Эти методы вырезаны из моего основного проекта бота. Следует организовать их в отдельных пакетах и классах, применяя наследование. Но ради примера работы, я решил вместить все это в один класс бота, что конечно плохо.
Создадим основной метод new_message, который будет обрабатывать сообщение пользователя и возвращать ответ:
Теперь вернемся к запускаемому файлу:
Импортируем класс нашего бота:
Изменим основной наш цикл:
То есть теперь мы будем передавать полученное сообщение объекту бота, который вернет нам нужный ответ.
Это усложнение программы просто необходимо, если вы хотите дальше улучшить функционал бота:
Создайте отдельные пакеты и классы для каждой функции _get_time и _get_weather. Организуйте наследование с общего класса. И каждую новую функцию определяйте в отдельных классах, лучше всего, конечно, еще и разделить на пакеты.
Добавьте словарь с ключом идентификатора пользователя и значением объекта бота. Таким образом, не придется каждый раз в цикле создавать объект бота. К тому же, это обеспечит пользование несколькими пользователями сразу в сложных конструкциях.
Таким образом, выбрав хорошую архитектуру кода, вы сможете создать многофункционального бота.
К примеру, я научил своего бота проигрывать музыку на компьютере, открывать сайты сидя с телефона. Присылать рецепты блюд на завтрак, обед, ужин.
Вы же можете редактировать бота под себя.
Буду рад вашим идеям. По любым вопросам пишите.
Пишем чат бота для ВКонтакте на python с помощью longpoll
Сейчас боты стали обыденностью и находятся на каждом шагу, но если тебе нужен свой бот в социальной сети вконтакте, то это легко реализовать.
Ну прям совсем для новичков
Как оно работает?
Long Polling — это технология, которая позволяет получать данные о новых событиях с помощью «длинных запросов». Сервер получает запрос, но отправляет ответ на него не сразу, а лишь тогда, когда произойдёт какое-либо событие (например, придёт новое сообщение), либо истечёт заданное время ожидания.
Говоря русским языком, мы отправляем на сервер запрос, а он в свою очередь тыкает вконтакте если там произойдёт что либо, например, нам придёт сообщение он бежит и говорит об этом нам. От этого и будем плясать.
Техническая реализация
Для начала нам нужно доказать вконтакту что мы — это мы, а не кто-либо ещё. Делается это очень просто.
Замечание, ребята из ВК рекомендуют использовать в качестве логина номер телефона т.к. иначе можно нарваться на проверку антиробот, ту самую где тебя просят ввести недостающие цифры из номера телефона.
Если бот будет сидеть в группе то авторизация выглядит по другому.
— Что такое токен?
— Такая штука из циферок и буковок которую нужно получить в настройках группы. Для этого достаточно открыть раздел «Управление сообществом» («Управление страницей», если у Вас публичная страница), выбрать вкладку «Работа с API» и нажать «Создать ключ доступа».
Теперь вызовем longpool.
В сообщениях может быть не только заданный вами текст. Например:
А ещё можно прикреплять картинки.
Можно придумать ещё много всего интересного, но тут подумайте сами, а я лишь скажу что: ссылки можно делить на части. Например:
и никто не запретил нам получать ответ от пользователя на примере Википедии:
Ссылки на примеры и документацию
На этом я с вами попрощаюсь. Хорошего кодинга.
Как создать чат-бота для Telegram с помощью Python
Это пошаговое руководство по созданию бота для Telegram. Бот будет показывать курсы валют, разницу между курсом раньше и сейчас, а также использовать современные встроенные клавиатуры.
Время переходить к делу и узнать наконец, как создавать ботов в Telegram.
Шаг №0: немного теории об API Telegram-ботов
Начать руководство стоит с простого вопроса: как создавать чат-ботов в Telegram?
Ответ очень простой: для чтения сообщений отправленных пользователями и для отправки сообщений назад используется API HTML. Это требует использования URL:
Токен выглядит приблизительно так:
Если значение ‘ok’ — true, значит запрос был успешным и результат отобразится в поле ‘field’. Если false — в поле ‘description’ будет сообщение об ошибке.
Следующий вопрос: как получать пользовательские сообщения?
Второй вариант — использовать webhooks. Метод setWebhook нужно будет применить только один раз. После этого Telegram будет отправлять все обновления на конкретный URL-адрес, как только они появятся. Единственное ограничение — необходим HTTPS, но можно использовать и сертификаты, заверенные самостоятельно.
Как выбрать оптимальный метод? Метод getUpdates лучше всего подходит, если:
Метод с Webhook лучше подойдет в таких случаях:
Еще один вопрос: как создать зарегистрировать бота?
@BotFather используется для создания ботов в Telegram. Он также отвечает за базовую настройку (описание, фото профиля, встроенная поддержка и так далее).
Существует масса библиотек, которые облегчают процесс работы с API Telegram-бота. Вот некоторые из них:
По своей сути, все эти библиотеки — оболочки HTML-запросов. Большая часть из них написана с помощью принципов ООП. Типы данных Telegram Bot API представлены в виде классов.
В этом руководстве будет использоваться библиотека pyTelegramBotApi.
Шаг №1: реализовать запросы курсов валют
Весь код был проверен на версии Python==3.7 c использование библиотек:
pyTelegramBotAPI==3.6.6
pytz==2019.1
requests==2.7.0
Начать стоит с написания Python-скрипта, который будет реализовывать логику конкретных запросов курсов валют. Использовать будем PrivatBank API. URL: https://api.privatbank.ua/p24api/pubinfo?json&exchange&coursid=5.
Создадим файл pb.py со следующим кодом:
Были реализованы три метода:
Шаг №2: создать Telegram-бота с помощью @BotFather
Необходимо подключиться к боту @BotFather, чтобы получить список чат-команд в Telegram. Далее нужно набрать команду /newbot для инструкций выбора название и имени бота. После успешного создания бота вы получите следующее сообщение:
Теперь, когда настройка закончена, можно переходить к написанию кода. Прежде чем двигаться дальше, рекомендуется почитать об API и ознакомиться с документацией библиотеки, чтобы лучше понимать то, о чем пойдет речь дальше.
Шаг №3: настроить и запустить бота
Начнем с создания файла config.py для настройки:
В этом файле указаны: токен бота и часовой пояс, в котором тот будет работать (это понадобится в будущем для определения времени обновления сообщений. API Telegram не позволяет видеть временную зону пользователя, поэтому время обновления должно отображаться с подсказкой о часовом поясе).
Создадим бота с помощью библиотеки pyTelegramBotAPI. Для этого конструктору нужно передать токен:
Шаг №4: написать обработчик команды /start
Из переменной бота возможно вызывать любые методы API Telegram-бота.
Начнем с написания обработчика команды /start и добавим его перед строкой bot.polling(none_stop=True) :
Как можно видеть, pyTelegramBotApi использует декораторы Python для запуска обработчиков разных команд Telegram. Также можно перехватывать сообщения с помощью регулярных выражений, узнавать тип содержимого в них и лямбда-функции.
Это было просто, не так ли?
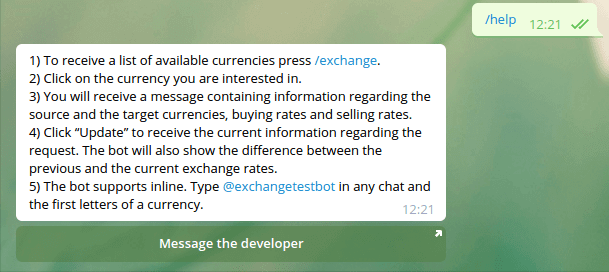
Шаг №5: создать обработчик команды /help
Давайте оживим обработчик команды /help с помощью встроенной кнопки со ссылкой на ваш аккаунт в Telegram. Кнопку можно озаглавить “Message the developer”.
Код выше выглядит вот так:
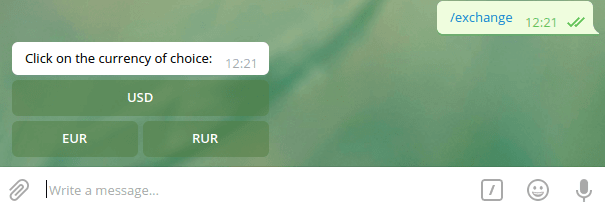
Шаг №6: добавить обработчик команды /exchange
Обработчик команды /exchange отображает меню выбора валюты и встроенную клавиатуру с 3 кнопками: USD, EUR и RUR (это валюты, поддерживаемые API банка).
Вот как работает ответ /exchange:
Шаг №7: написать обработчик для кнопок встроенной клавиатуры
Давайте реализуем метод get_ex_callback :
Все довольно просто.
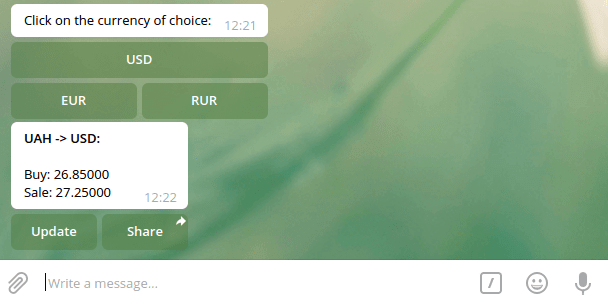
Запишем в get_update_keyboard текущий курс валют в callback_data в форме JSON. JSON сжимается, потому что максимальный разрешенный размер файла равен 64 байтам.
Кнопка t значит тип, а e — обмен. Остальное выполнено по тому же принципу.
Вот как будет выглядеть бот после нажатия кнопки USD:
Шаг №8: реализовать обработчик кнопки обновления
Как это работает? Очень просто:
Метод get_ex_from_iq_data разбирает JSON из callback_data :
get_edited_signature генерирует текст “Updated…”:
Вот как выглядит сообщение после обновления, если курсы валют не изменились:
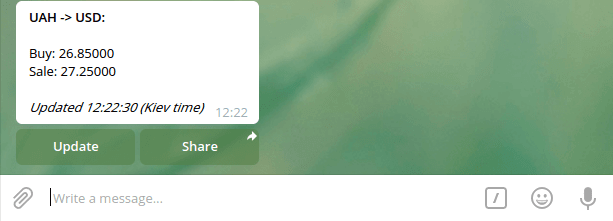
И вот так — если изменились:
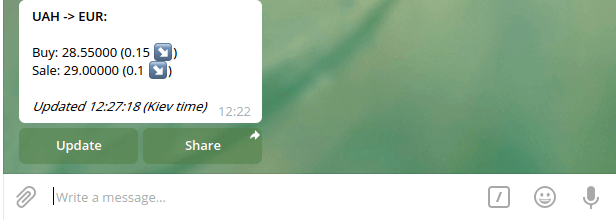
Шаг №9: реализовать встроенный режим
Реализация встроенного режима значит, что если пользователь введет @ + имя бота в любом чате, это активирует поиск введенного текста и выведет результаты. После нажатия на один из них бот отправит результат от вашего имени (с пометкой “via bot”).
Обработчик встроенных запросов реализован.
Теперь при вводе “@exchangetestbost + пробел” вы увидите следующее:

Попробуем набрать usd, и результат мгновенно отфильтруется:
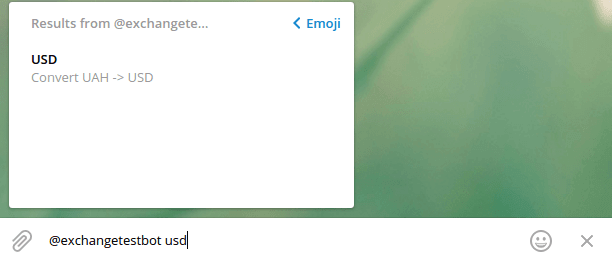
Проверим предложенный результат:

Кнопка “Update” тоже работает:
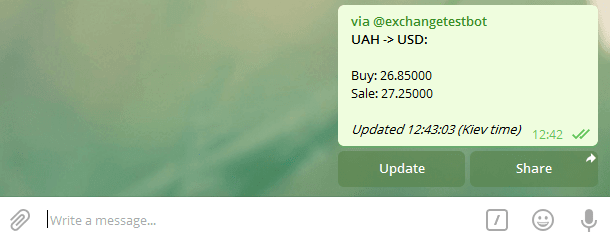
Отличная работа! Вы реализовали встроенный режим!
Выводы
Поздравляем! Теперь вы знаете, как сделать бота для Telegram, добавить встроенную клавиатуру, обновление сообщений и встроенный режим. Можете похлопать себя по спине и поднять тост за нового бота.
Обучаемый Telegram чат-бот с ИИ в 30 строчек кода на Python

Сегодня мне в голову пришла мысль: «А почему бы не написать Telegram чат-бота с ИИ, которого потом можно будет обучать?»
Сейчас сделать это совсем легко, поэтому, недолго думая, я принялся к написанию кода.
Языком я выбрал Python, т.к. на нём легче всего работать с подобного рода приложениями.
Итак, для создания Telegram чат-бота с ИИ нам потребуется:
1. API Telegram. В качестве обёртки я взял проверенную библиотеку python-telegram-bot
2. API ИИ. Выбрал я продукт от Google, а именно Dialogflow. Он предоставляет довольно-таки неплохое бесплатное API. Обёртка Dialogflow для Python
Шаг 1. Создаём бота в Telegram
Придумываем имя нашему боту и пишем @botfather. После создания бота нам придёт API токен, который желательно бы где-то сохранить, т.к. в дальнейшем он нам понадобится.

Шаг 2. Пишем основу бота
Создаём папку Bot, в которой потом создаём файл bot.py. Здесь будет код нашего бота.
Открываем консоль и переходим в директорию с файлом, устанавливаем python-telegram-bot.
После установки мы уже можем написать «основу», которая пока что будет просто отвечать однотипными сообщениями. Импортируем необходимые модули и прописываем наш токен API:
Далее напишем 2 обработчика команд. Это callback-функции, которые будут вызываться тогда, когда будет получено обновление. Напишем две таких функции для команды /start и для обычного любого текстового сообщения. В качестве аргументов туда передаются два параметра: bot и update. Bot содержит необходимые методы для взаимодействия с API, а update содержит данные о пришедшем сообщении.
Теперь осталось лишь присвоить уведомлениям эти обработчики и начать поиск обновлений.
Делается это очень просто:
Итого, полная основа скрипта выглядит вот так:
Теперь мы можем проверить работоспособность нашего нового бота. Вставляем на 2 строке наш API токен, сохраняем изменения, переносимся в консоль и запускаем бота:
После запуска пишем ему. Если всё настроено правильно, то Вы увидите вот это:
Основа бота написана, приступаем к следующему шагу!
P.s. не забывайте выключить бота, для этого вернитесь в консоль и нажмите Ctrl + C, подождите пару секунд и бот успешно завершит работу.
Шаг 3. Настройка ИИ
В первую очередь, идём и регистрируемся на Dialogflow (просто входим с помощью своего Google аккаунта). Сразу после авторизации мы попадаем в панель управления.
Жмём на кнопку Create agent и заполняем поля по усмотрению (это никакой роли не сыграет, это нужно лишь для следующего действия).
Жмём на Create и видим следующую картину:
Расскажу, почему созданный нами ранее «Агент» никакой роли не играет. Во вкладке Intents есть «команды», по которым работает бот. Сейчас он умеет лишь отвечать на фразы типа «Привет», и если не понимает, то отвечает «Я вас не понял». Не сильно впечатляет.
После создания нашего пустого агента, у нас появилась куча других вкладок. Нам нужно нажать на Prebuilt Agents (это уже специально обученные агенты, которые имеют множество команд) и из всего представленного списка выбрать Small Talk.
Наводим на него и жмём Import. Далее ничего не меняя, жмём Ok. Агент импортировался и теперь мы можем его настроить. Для этого в левом верхнем углу жмём на шестерёнку возле Small-Talk и попадаем на страницу настроек. Теперь мы можем изменить имя агента, как захотим (я оставляю как было). Меняем часовой пояс и во вкладке Languages проверяем, чтобы был установлен русский язык (если не установлен, то ставим).
Возвращаемся на вкладку General, спускаемся немного вниз и копируем Client access token
Теперь наш ИИ полностью настроен, можно возвращаться к боту.
Шаг 4. Собираем всё вместе
ИИ готов, основа бота готова, что дальше? Дальше нам нужно скачать обёртку API от Dialogflow для питона.
Установили? Возвращаемся к нашему боту. Добавляем в нашу секцию «Настройки» импорт модулей apiai и json (нужно, чтобы в будущем разбирать json ответы от dialogflow). Теперь это выглядит вот так:
Переходим к функции textMessage (которая отвечает за получение любого текстового сообщения) и посылаем полученные сообщения на сервера Dialogflow:
Этот код будет посылать запрос к Dialogflow, но нам нужно также извлечь ответ. Дописываем парочку строк, итого textMessage выглядит вот так:
Немного пояснений. С помощью
получается ответ от сервера, закодированный в байтах. Чтобы декодировать его, просто применяем метод
и после этого «заворачиваем» всё в
чтобы распарсить json ответ.
Если ответа нет (точнее, json приходит всегда, но не всегда есть сам массив с ответом ИИ), то это означает, что Small-Talk не понял пользователя (обучением можно будет заняться позже). Поэтому если «ответа» нет, то пишем пользователю «Я Вас не совсем понял!».
Итого, полный код бота с ИИ будет выглядеть вот так:
Сохраняем изменения, запускаем бота и идём проверять:
Вот и всё! Бот в 30 строк с ИИ написан!
Шаг 5. Заключительная часть
Думаю, Вы убедились, что написать бота с ИИ – дело 10 минут. Осталось лишь теперь его учить и учить. Делать это, кстати, можно во вкладке Training. Там можно посмотреть все сообщения, которые писались и что на них ответил бот (или не ответил). Там же его можно и обучать, говоря боту где он ответил правильно, а где нет.
Надеюсь, статья была Вам полезна, удачи в обучении!
Как создать чат-бота с нуля на Python: подробная инструкция

Аналитики Gartner утверждают, что к 2020 году 85% взаимодействий клиентов с сервисами сведется к общению с чат-ботами. В 2018 году они уже обрабатывают около 30% операций. В этой статье мы расскажем, как создать своего чат-бота на Python.
Возможно, вы слышали о Duolingo: популярном приложении для изучения иностранных языков, в котором обучение проходит в форме игры. Duolingo популярен благодаря инновационному стилю обучения. Концепция проста: от пяти до десяти минут интерактивного обучения в день достаточно, чтобы выучить язык.
Н есмотря на то что Duolingo позволяет изучить новый язык, у пользователей сервиса возникла проблема. Они почувствовали, что не развивают разговорные навыки, так как обучаются самостоятельно. Пользователи неохотно обучались в парах из-за смущения. Эта проблема не осталась незамеченной для разработчиков.
Команда сервиса решила проблему, создав чат-бота в приложении, чтобы помочь пользователям получать разговорные навыки и применять их на практике.
Поскольку боты разрабатывались так, чтобы быть разговорчивыми и дружелюбными, пользователи Duolingo практикуются в общении в удобное им время, выбирая «собеседника» из набора, пока не поборят смущение в достаточной степени, чтобы перейти к общению с другими пользователями. Это решило проблему пользователей и ускорило обучение через приложение.
Итак, что такое чат-бот?
Чат-бот — это программа, которая выясняет потребности пользователей, а затем помогает удовлетворить их (денежная транзакция, бронирование отелей, составление документов). Сегодня почти каждая компания имеет чат-бота для взаимодействия с пользователями. Некоторые способы использования чат-ботов:
История чат-ботов восходит к 1966 году, когда Джозеф Вейценбаум разработал компьютерную программу ELIZA. Программа подражает манере речи психотерапевта и состоит лишь из 200 строк кода. Пообщаться с Элизой можно до сих пор на сайте.
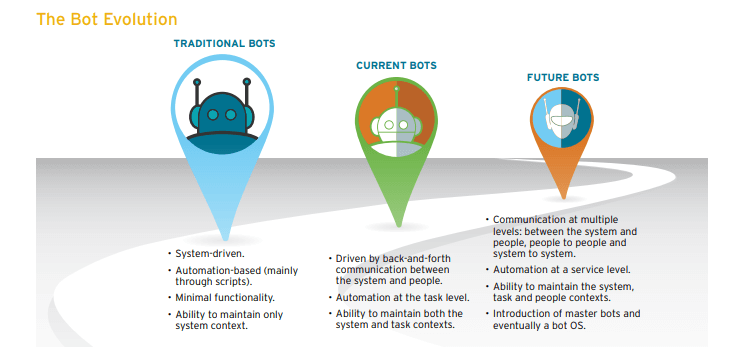
Как работает чат-бот?
Существует два типа ботов: работающие по правилам и самообучающиеся.
В поисковых ботах используются эвристические методы для выбора ответа из библиотеки предопределенных реплик. Такие чат-боты используют текст сообщения и контекст диалога для выбора ответа из предопределенного списка. Контекст включает в себя текущее положение в древе диалога, все предыдущие сообщения и сохраненные ранее переменные (например, имя пользователя). Эвристика для выбора ответа может быть спроектирована по-разному : от условной логики «или-или» до машинных классификаторов.
Генеративные боты могут самостоятельно создавать ответы и не всегда отвечают одним из предопределенных вариантов. Это делает их интеллектуальными, так как такие боты изучают каждое слово в запросе и генерируют ответ.
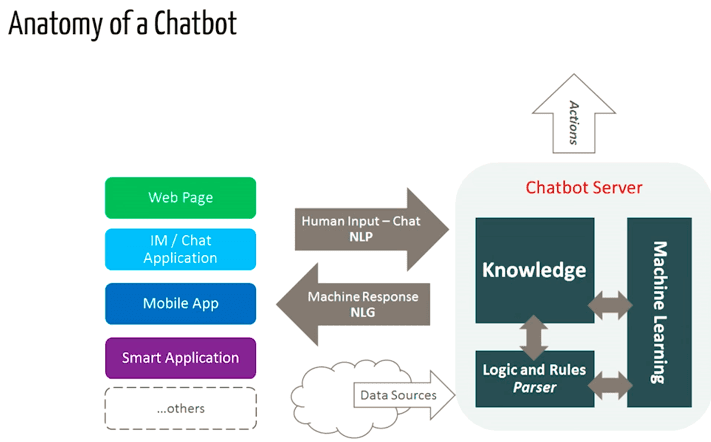
В этой статье мы научимся писать код простых поисковых чат-ботов на основе библиотеки NLTK.
Создание бота на Python
Предполагается, что вы умеете пользоваться библиотеками scikit и NLTK. Однако, если вы новичок в обработке естественного языка (NLP), вы все равно можете прочитать статью, а затем изучить соответствующую литературу.
Обработка естественного языка (NLP)
Обработка естественного языка — это область исследований, в которой изучается взаимодействие между человеческим языком и компьютером. NLP основана на синтезе компьютерных наук, искусственного интеллекта и вычислительной лингвистики. NLP — это способ для компьютеров анализировать, понимать и извлекать смысл из человеческого языка разумным и полезным образом.
Краткое введение в NLKT
NLTK (Natural Language Toolkit) — платформа для создания программ на Python для работы с естественной речью. NLKT предоставляет простые в использовании интерфейсы для более чем 50 корпораций и лингвистических ресурсов, таких как WordNet, а также набор библиотек для обработки текста в целях классификации, токенизации, генерации, тегирования, синтаксического анализа и понимания семантики, создания оболочки библиотек NLP для коммерческого применения.
Книга Natural Language Processing with Python — практическое введение в программирование для обработки языка. Рекомендуем ее прочитать, если вы владеете английским языком.
Загрузка и установка NLTK
Инструкции для конкретных платформ смотрите здесь.
Установка пакетов NLTK
Импортируйте NLTK и запустите nltk.download(). Это откроет загрузчик NLTK, где вы сможете выбрать версию кода и модели для загрузки. Вы также можете загрузить все пакеты сразу.
Предварительная обработка текста с помощью NLTK
Основная проблема с данными заключается в том, что они представлены в текстовом формате. Для решения задач алгоритмами машинного обучения требуется некий вектор свойств. Поэтому прежде чем начать создавать проект по NLP, нужно предварительно обработать его. Предварительная обработка текста включает в себя:
Пакет NLTK включает в себя предварительно обученный токенизатор Punkt для английского языка.
Набор слов
После первого этапа предварительной обработки нужно преобразовать текст в вектор (или массив) чисел. «Набор слов» — это представление текста, описывающего наличие слов в тексте. «Набор слов» состоит из:
Почему используется слово «набор»? Это связано с тем, что информация о порядке или структуре слов в тексте отбрасывается, и модель учитывает только то, как часто определенные слова встречаются в тексте, но не то, где именно они находятся.
Идея «набора слов» состоит в том, что тексты похожи по содержанию, если включают в себя похожие слова. Кроме того, кое-что узнать о содержании текста можно лишь по набору слов.
Например, если словарь содержит слова
Метод TF-IDF
Проблема «набора слов» заключается в том, что в тексте могут доминировать часто встречающиеся слова, которые не содержат ценную для нас информацию. Также «набор слов» присваивает большую важность длинным текстам по сравнению с короткими.
Один из подходов к решению этих проблем состоит в том, чтобы вычислять частоту появления слова не в одном тексте, а во всех сразу. За счет этого вклад, например, артиклей «a» и «the» будет нивелирован. Такой подход называется TF-IDF (Term Frequency-Inverse Document Frequency) и состоит из двух этапов:
Коэффициент TF-IDF — это вес, часто используемый для обработки информации и интеллектуального анализа текста. Он является статистической мерой, используемой для оценки важности слова для текста в некотором наборе текстов.
Пример
Рассмотрим текст, содержащий 100 слов, в котором слово «телефон» появляется 5 раз. Параметр TF для слова «телефон» равен (5/100) = 0,05.
Теперь предположим, что у нас 10 миллионов документов, и слово телефон появляется в тысяче из них. Коэффициент вычисляется как 1+log(10 000 000/1000) = 4. Таким образом, TD-IDF равен 0,05 * 4 = 0,20.
TF-IDF может быть реализован в scikit так:
Коэффициент Отиаи
TF-IDF — это преобразование, применяемое к текстам для получения двух вещественных векторов в векторном пространстве. Тогда мы можем получить коэффициент Отиаи любой пары векторов, вычислив их поэлементное произведение и разделив его на произведение их норм. Таким образом, получается косинус угла между векторами. Коэффициент Отиаи является мерой сходства между двумя ненулевыми векторами. Используя эту формулу, можно вычислить схожесть между любыми двумя текстами d1 и d2.
Здесь d1, d2 — два ненулевых вектора.
Подробное объяснение и практический пример TF-IDF и коэффициента Отиаи приведены в посте по ссылке.
Пришло время перейти к решению нашей задачи, то есть созданию чат-бота. Назовем его «ROBO».
Обучение чат-бота
В нашем примере мы будем использовать страницу Википедии в качестве текста. Скопируйте содержимое страницы и поместите его в текстовый файл под названием «chatbot.txt». Можете сразу использовать другой текст.
Импорт необходимых библиотек
Чтение данных
Выполним чтение файла corpus.txt и преобразуем весь текст в список предложений и список слов для дальнейшей предварительной обработки.
Давайте рассмотрим пример файлов sent_tokens и word_tokens
Предварительная обработка исходного текста
Теперь определим функцию LemTokens, которая примет в качестве входных параметров токены и выдаст нормированные токены.
Подбор ключевых слов
Определим реплику-приветствие бота. Если пользователь приветствует бота, бот поздоровается в ответ. В ELIZA используется простое сопоставление ключевых слов для приветствий. Будем использовать ту же идею.
Генерация ответа
Чтобы сгенерировать ответ нашего бота для ввода вопросов, будет использоваться концепция схожести текстов. Поэтому мы начинаем с импорта необходимых модулей.
Этот модуль будет использоваться для поиска в запросе пользователя ключевых слов. Это самый простой способ создать чат-бота.
Определим функцию отклика, которая возвращает один из нескольких возможных ответов. Если запрос не соответствует ни одному ключевому слову, бот выдает ответ «Извините! Я вас не понимаю».
Наконец, мы задаем реплики бота в начале и конце переписки, в зависимости от реплик пользователя.
Вот и все. Мы написали код нашего первого бота в NLTK. Здесь вы можете найти весь код вместе с текстом. Теперь давайте посмотрим, как он взаимодействует с людьми:

Получилось не так уж плохо. Даже если чат-бот не смог дать удовлетворительного ответа на некоторые вопросы, он хорошо справился с другими.
Заключение
Хотя наш примитивный бот едва ли обладает когнитивными навыками, это был неплохой способ разобраться с NLP и узнать о работе чат-ботов. «ROBO», по крайней мере, отвечает на запросы пользователя. Он, конечно, не обманет ваших друзей, и для коммерческой системы вы захотите рассмотреть одну из существующих бот-платформ или фреймворки, но этот пример поможет вам продумать архитектуру бота.