Создаем свой язык программирования с блэкджеком и компилятором
В этом пособии с соответствующими примерами кода рассказываем о том, как написать при помощи Python свой язык программирования и компилятор к нему.
Введение
Изучение компиляторов и устройства языков программирования по видеоурокам и руководствам – дело для новичков тяжелое. В этих материалах нередко отсутствуют важные составляющие. Цель публикации – помочь людям, ищущим способ создать свой язык программирования и компилятор. Пример игрушечный, но позволит понять, с чего начать и в каком направлении двигаться.
Системные требования
Если вы незнакомы с нижеприведенными понятиями, не беспокойтесь – мы проясним необходимость этих компонентов далее, по ходу создания компилятора. В качестве лексера и парсера используется PLY. В роли низкоуровневого языка-посредника для генерации оптимизированного кода выступает LLVMlite.
Таким образом, к системе предъявляются следующие требования:
Свой язык программирования: с чего начать?
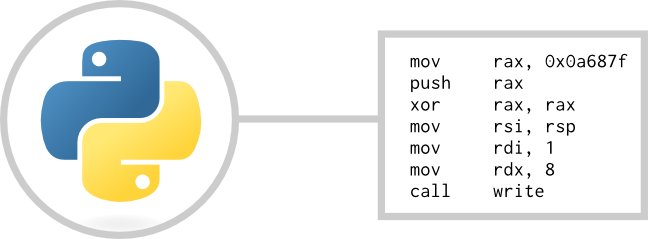
Начнем с того, что назовем свой язык программирования. В качестве примера он будет называться TOY. Пусть пример программы на языке TOY выглядит следующим образом:
Любой язык программирования включает множество составляющих его компонентов. Чтобы не застрять в мелочах, возьмем в качестве микропрограммы вызов одной функции нашего языка:
Как для этой однострочной программы формально описать грамматику языка? Чтобы это сделать, необходимо использовать расширенную Бэкус – Наурову форму (РБНФ) (англ. Extended Backus–Naur Form ( EBNF )). Это формальная система определения синтаксиса языка. Воплощается она при помощи метаязыка, определяющего в одном документе всевозможные грамматические конструкции. Чтобы в деталях разобраться с тем, как работает РБНФ, прочтите эту публикацию.
Создаем РБНФ (EBNF)
Создадим РБНФ, которая опишет минимальный функционал нашей микропрограммы. Начнем с операции суммирования:
Соответствующая РБНФ будет выглядеть следующим образом:
Дополним язык операцией вычитания:
В соответствующем РБНФ изменится первая строка:
Наконец, опишем функцию print:
В этом случае в РБНФ появится новая строка, описывающая работу с выражениями:
В таком ключе развивается описание грамматики языка. Как же научить компьютер транслироваться эту грамматику в бинарный исполняемый код? Для этого нужен компилятор.
Компилятор
Компилятор – это программа, переводящая текст ЯП на машинный или другие языки. Программы на TOY в этом руководстве будут компилироваться в промежуточное представление LLVM IR (IR – сокращение от Intermediate Representation) и затем в машинный язык.
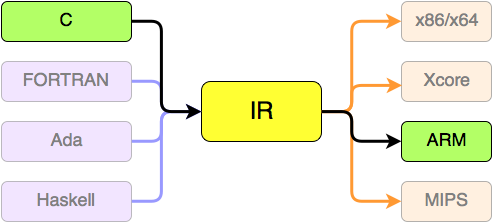
Использование LLVM позволяет оптимизировать процесс компиляции без изучения самого процесса оптимизации. У LLVM действительно хорошая библиотека для работы с компиляторами.
Наш компилятор можно разделить на три составляющие:
Для лексического анализатора и парсера мы будем использовать RPLY, очень близкий к PLY. Это библиотека Python с теми же лексическими и парсинговыми инструментами, но с более качественным API. Для генератора кода будем использовать LLVMLite – библиотеку Python для связывания компонентов LLVM.
1. Лексический анализатор
Итак, первый компонент компилятора – лексический анализатор. Роль этого компонента заключается в том, чтобы разделять текст программы на токены.
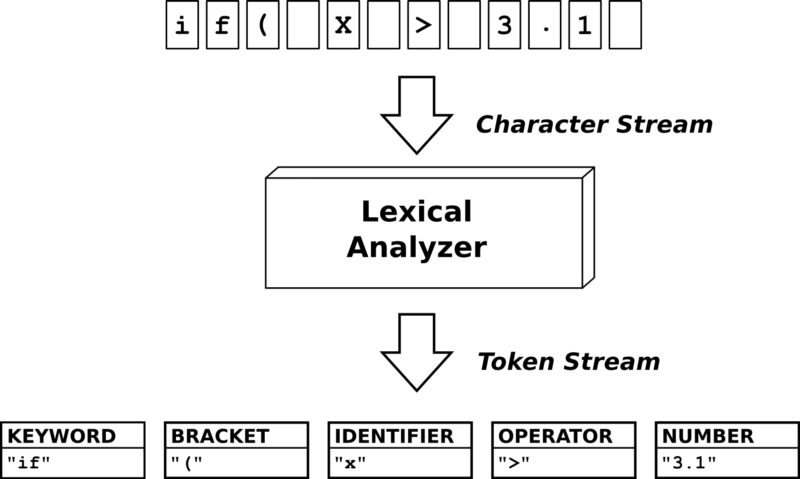
Воспользуемся последней структурой из примера для РБНФ и найдем токены. Рассмотрим команду:
Наш лексический анализатор должен разделить эту строку на следующий список токенов:
Напишем код компилятора. Для начала создадим файл lexer.py, в программном коде которого будут определяться токены. Для создания лексического анализатора воспользуемся классом LexerGenerator библиотеки RPLY.
Создадим основной файл программы main.py. В этом файле мы впоследствии объединим функционал трех компонентов компилятора. Для начала импортируем созданный нами класс Lexer и определим токены для нашей однострочной программы:
При запуске main.py мы увидим на выходе вышеописанные токены. Вы можете изменить названия своих токенов, но для простоты согласования с функциями парсера их лучше оставить как есть.
2. Синтаксический анализатор
Второй компонент компилятора – синтаксический анализатор (он же парсер). Его роль – синтаксический анализ текста программы. Данный компонент принимает список токенов на входе и создает на выходе абстрактное синтаксическое дерево (АСД). Эта концепция более трудна, чем идея списка токенов, поэтому мы настоятельно рекомендуем хотя бы по приведенным выше ссылкам изучить принципы работы парсеров и синтаксических деревьев.
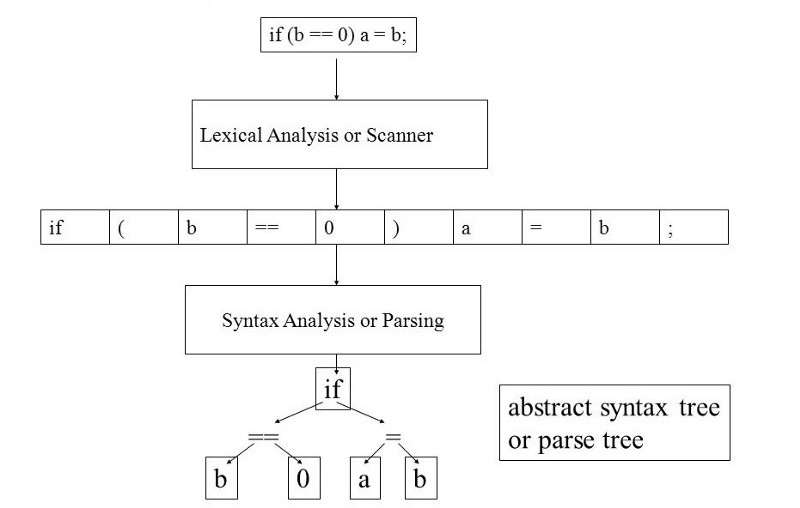
Чтобы воплотить в жизнь синтаксический анализатор, будем использовать структуру, созданную на этапе РБНФ. К счастью, анализатор RPLY использует формат, схожий с РБНФ. Самое сложное – присоединить синтаксический анализатор к АСД, но когда вы поймете идею, это действие станет действительно механическим.
Во-первых, создадим файл ast.py. Он будет содержать все классы, которые могут быть вызваны парсером, и создавать АСД.
Во-вторых, нам необходимо создать сам анализатор. Для этого в новом файле parser.py аналогично лексеру используем класс ParserGenerator из библиотеки RPLY:
Наконец, обновляем файл main.py, чтобы объединить возможности синтаксического и лексического анализаторов:
Теперь при запуске main.py мы получим значение 6. и оно действительно соответствует нашей однострочной программе «print(4 + 4 – 2);».
Таким образом, при помощи двух этих компонентов мы создали работающий компилятор, интерпретирующий язык TOY. Однако компилятор по-прежнему не создает исполняемый машинный код и не оптимизирован. Для этого мы перейдем к самой сложной части руководства – генерации кода с помощью LLVM.
3. Генератор кода
Третья и последняя часть компилятора – это генератор кода. Его роль заключается в том, чтобы преобразовывать АСД в машинный код или промежуточное представление. В нашем случае будет происходить преобразование АСД в промежуточное представление LLVM (LLVM IR).
LLVM может оказаться действительно сложным для понимания инструментом, поэтому обратите внимание на документацию LLVMlite. LLVMlite не имеет реализации для функции печати, поэтому вы должны определить собственную функцию.
Чтобы начать, создадим файл codegen.py, содержащий класс CodeGen. Этот класс отвечает за настройку LLVM и создание/сохранение IR-кода. В нем мы также объявим функцию печати.
Теперь обновим основной файл main.py, чтобы вызывать методы CodeGen:
Как вы можете видеть, для того, чтобы обработка происходила классическим образом, входная программа была вынесена в отдельный файл input.toy. Это уже больше похоже на классический компилятор. Файл input.toy содержит все ту же однострочную программу:
Еще одно изменение – передача парсеру методов module, builder и printf. Это сделано, чтобы мы могли отправить эти объекты АСД. Таким образом, для получения объектов и передачи их АСД необходимо изменить parser.py:
Наконец, самое важное. Мы должны изменить файл ast.py, чтобы получать эти объекты и создавать LLMV АСД, используя методы из библиотеки LLVMlite:
После изменений компилятор готов к преобразованию программы на языке TOY в файл промежуточного представления LLVM output.ll. Далее используем LLC для создания файла объекта output.o и GCC для получения конечного исполняемого файла:
Теперь вы можете запустить исполняем файл, для создания которого вами использовался свой язык программирования:
Следующие шаги
Мы надеемся, что после прохождения этого руководства вы разобрались в общих чертах в концепции РБНФ и трех основных составляющих компилятора. Благодаря этим знаниям вы можете создать свой язык программирования и написать оптимизированный компилятор при помощи Python. Мы призываем вас не останавливаться на достигнутом и добавить в свой язык и компилятор другие важные составляющие:
Итоговый программный код вы также найдете на GitHub.
Другие материалы по теме языков программирования
Пишем свой язык программирования, часть 1: пишем языковую ВМ
Введение
Доброго времени суток всем хабрачитателям!
Итак, пожалуй стоит сказать, что целью моей работы, на основе которой будет написан ряд статеек было пройти весь путь создания полнофункционального ЯП самому с 0 и затем поделиться своими знаниями, наработками и опытом с интересующимися этим людьми.
Я буду описывать создание языка, который описал ранее тут.
Он заинтересовал многих и вызвал бурную дискуссию в комментариях. Следовательно — тема интересна многим.
Думаю, что сразу стоит выложить информацию о проекте:
Сайт (будет заполнен документацией чуть позже).
Репозиторий
Чтобы самому потрогать проект и увидеть все в действии, лучше скачать репозиторий и запускать все из папки bin. В релиз я не спешу выкладывать последние версии языка и среды выполнения, т.к. мне порой бывает просто лень это делать.
Кодить я умею на C/C++ и на Object Pascal. Проект я писал на FPC, т.к. на мой взгляд этот язык гораздо проще и лучше подходит для написание подобного. Вторым определяющим фактором стало то, что FPC поддерживает огромное количество целевых платформ и пересобрать проект под нужную платформу можно с минимумом переделок. Если вы по непонятным мне причинам не любите Object Pascal, то не спешите закрывать пост и бежать кидаться камнями в комментарии. Этот язык весьма красив и нагляден, а кода я буду приводить не так уж и много. Только то, что нужно.
Итак, начну пожалуй я своё повествование.
Ставим цели
Прежде всего, любому проекту нужны поставленные цели и ТЗ, которые придется в будущем реализовывать. Нужно заранее определиться, какого типа язык будет создаваться, чтобы написать первичную ВМ для него.
Ключевые моменты, которые определяли дальнейшую разработку моей ВМ следующие:
Сразу скажу, что ВМ я назвал максимально красноречиво — SVM (Stack-based Virtual Machine).
Начнем, пожалуй, с реализации класса переменной
Перед тем, как начать писать код класса, я решил сразу закинуть директиву <$H+>в заголовок модуля для более гибкой поддержки строк будущим языком.
П.с. для тех, кто может быть не в курсе, в чем разница между H- и H+ режимом FPC.
При сборке кода в режиме H- строки будут представлены в виде массива символов. При H+ — в виде указателя на кусок памяти. В первом случае строки будут изначально фиксированной длины и ограничены по дефолту 256 символами. Во втором случае — строки будут динамически расширяемыми и в них можно будет запихнуть гораздо больше символов. Будут работать немного медленнее, зато более функционально. При H+ можно также объявлять строки как массив символов, например таким вот образом:
Итак, для начала объявим Enum тип, который будем использовать как некий флажок, для определения типа данных по указателю:
Далее опишем основную структуру нашего типа переменной и некоторые методы:
Класс ни от чего не наследуется, поэтому inherited вызовы в конструкторе и деструкторе можно не делать. Уделю внимание директиве inline. В заголовок файла лучше добавить <$inline on>, чтоб наверняка. Её активное использование в ВМ довольно ощутимо повысило производительность (мб где-то аж на 15-20%!). Она говорит компилятору, что тело метода лучше встроить на место его вызова. Выходной код будет немного больше в итоге, но работать будет быстрее. В данном случае, использование inline целесообразно.
Ок, запилили мы на этом этапе основу нашего класса. Теперь нужно описать ряд сеттеров и геттеров (setter & getter) у нашего класса.
Задача в чем — написать пару методов, которые позволят запихнуть и в дальнейшем получить обратно значения из нашего класса.
Для начала разберемся с присвоением значения для нашего класса. Первым можно написать обобщенный сеттер, ну а дальше, для отдельных типов данных:
Теперь можно и для пары геттеров написать код:
Ок, замечательно, теперь, после того, как вы просидели некоторое время пялясь в IDE и с энтузиазмом печатая код сеттеров и геттеров, мы стоим перед задачей реализации поддержки нашим типом математических и логических операций. В качестве примера я приведу реализацию операции сложения:
Все просто. Аналогичным образом можно описать и дальнейшие операции и вот наш класс готов.
Для массивов ещё конечно нужны пара методов, пример получения элемента по индексу:
Супер. Теперь мы можем двигаться дальше.
Реализуем стек
Спустя время я пришел к таким мыслям. Стек должен быть и статичным (для быстродействия) и динамичным (для гибкости) одновременно.
Поэтому стек реализован блочно. Т.е. как это должно работать — изначально массив стека имеет определенный размер (я решил поставить размер блока в 256 элементов, чтобы было красиво и не мало). Соответственно, в комплекте с массивом идет счетчик, указывающий на текущую вершину стека. Перевыделение памяти — это лишняя долгая операция, которую можно выполнять реже. Если в стек будет ложиться больше значений, то его размер можно будет всегда расширить на размер ещё одного блока.
Привожу реализацию стека целиком:
Во внешние методы ВМ будет передавать указатель на стек, чтобы они могли взять оттуда нужные аргументы. Указатель на поток ВМ добавил позже, чтобы можно было реализовывать callback вызовы из внешних методов да и в общем, для передачи большей власти над ВМ методам.
Итак, как с тем, как устроен стек вы ознакомились. Таким же образом устроен callback стек, для простоты и удобства call & return операций и стек сборщика мусора. Единственное — другие размеры блоков.
Поговорим о мусоре
Его, как правило много, очень много. И с ним нужно что-то делать.
Первым делом хочу рассказать о том, как устроены сборщики мусора в других языках, например в Lua, Ruby, Java, Perl, PHP и т.д. Они работают по принципу подсчета указателей на объекты в памяти.
Т.е. вот выделили мы память под что-то, логично — указатель сразу поместили в переменную/массив/куда-то ещё. Сборщик мусора среды выполнения сразу же добавляет этот указатель себе с список возможных мусорных объектов. В фоне, сборщик мусора постоянно мониторит все переменные, массивы и т.д. Если там не оказывается указателя на что-то из списка возможного мусора — значит это мусор и память из под него нужно убрать.
Я решил реализовать свой велосипед. Мне более привычна работа с памятью по принципу Тараса Бульбы. Я тебя породил — я тебя и убью, подразумеваю я, когда вызываю очередной Free у очередного класса. Поэтому сборщик мусора у моей ВМ полуавтоматический. Т.е. его нужно вызывать в ручном режиме и работать с ним соответственно. В его очередь добавляются указатели на объявляемые временные объекты (эта роль ложится на по большей мере на транслятор и немного на разработчика). Для освобождения памяти из под других объектов можно использовать отдельный опкод.
Т.е. у сборщика мусора на момент вызова есть уже готовый список указателей, по которому нужно пробежаться и освободить память.
Итак, теперь разберемся с компиляцией в абстрактный исполняемый файл
Идея изначально заключалась в том, что приложения, написанные на моём языке смогут выполняться без исходников, как это происходит с многими похожими языками. Т.е. его можно будет использовать в коммерческих целях.
Для этого нужно определить формат исполняемых файлов. У меня получилось следующее:
Выполнение кода
После разбора вышеперечисленных секций и инициализации ВМ у нас остается одна секция с кодом. В моей ВМ выполняется не выровненный байткод, т.е. инструкции могут быть произвольной длины.
Набор опкодов — инструкций для виртуальной машины с небольшими комментариями я показываю заранее ниже:
Итак, вы бегло ознакомились с тем, какие операции может выполнять написанная мной ВМ. Теперь хочется сказать о том, как это все работает.
ВМ реализована как object, благодаря чему можно без проблем реализовать поддержку многопоточности.
Имеет указатель на массив с опкодами, IP (Instruction Pointer) — смещение выполняемой инструкции и указатели на прочие структуры ВМ.
Выполнение кода идет большим switch-case.
Просто приведу описание ВМ:
Немного об обработке исключений
Для этого в ВМ есть стек обработчиков исключений и большой try/catch блок, в который завернуто выполнение кода. С стек можно положить структуру, которая имеет смещение точек входа на catch и finally/end блока обработки исключений. Также я предусмотрел опкод trs, который ставится перед catch и перебрасывает код на finally/end, если он выполнился успешно, попутно удаляя блок с информацией об обработчиках исключений с вершины соответствующего стека. Просто? Просто. Удобно? Удобно.
Поговорим о внешних методах и библиотеках
Я уже упоминал о них ранее. Импорты, библиотеки… Без них язык не будет обладать желаемой гибкостью и функционалом.
Первым делом в реализации ВМ объявим тип внешнего метода и протокол его вызова.
Парсер секции импорта заполняет при ицициализации ВМ массив указателей на внешние методы. Следовательно каждый метод имеет статичный адрес, который вычисляется на этапе сборке приложения под ВМ и по которому может быть вызван нужный метод.
Вызов в дальнейшем происходит таким вот образом в процессе выполнения кода:
Напишем простую библиотеку для нашей ВМ
И пусть она будет реализовывать для начала метод Sleep:
Итоги
На этом я пожалуй закончу свою первую статью из задуманного цикла.
Сегодня я довольно подробно описал создание среды выполнения языка. Считаю, что данная статья будет очень полезна людям, которые решат попробовать написать свой ЯП или же разобраться с тем, как работают подобные языки программирования.
Полный код ВМ доступен в репозитории, в ветке /runtime/svm.
Если вам понравилась эта статья, то не ленитесь закинуть плюс в карму и поднять её в топе, я старался и буду стараться для вас.
Если вам что-то непонятно — то добро пожаловать в комментарии или на форум.
Возможно ваши вопросы и ответы на них будут интересны не только вам.
Создание языка программирования. Часть 0
Доброго времени суток Уважаемые Хабра пользователи! Не буду долго рассусоливать, расскажу лишь основное что подтолкнуло меня к написанию данной статьи, и к собственно разработке своего языка программирования.
Все дело в том, что я занимаюсь программированием достаточно давно, и знаю несколько языков программирования. И несмотря на их различия, я в любом языке умудряюсь наворотить сложных конструкций (даже в Python мой код иногда настолько закручен, что я сам не понимаю что я курил когда писал его). В связи с тем что мой код полностью противоречит всем канонам правильного кода, мне стало интересно как же компиляторы и интерпретаторы понимают мой кривой код.
В связи с этим, сразу даю ответ на вопросы «Зачем это надо?! Очередной велосипед написать? Заняться что ли нечем?» — делается это с целью удовлетворения интереса, а так же для того что бы такие же интересующиеся как я имели представление о том как это работает.
Теперь собственно к теории языков программирования. Посмотрим что на этот счет всеми любимая Википедия:
Язык программирования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, определяющих внешний вид программы и действия, которые выполнит исполнитель (обычно — ЭВМ) под её управлением.
С этим все понятно, ничего сложного, все мы знаем что это такое.
О том, что предстоит сделать
1. Лексический анализатор. Модуль который будет проверять правильность лексических конструкций, которые предусмотрены нашим языком программирования.
2. Парсер. Данный модуль будет переводить код понятный человеку в поток токенов, которые в последующем будут исполняться или переводиться в машинный язык.
3. Обычно на этом месте стоит оптимизатор, но так как наша поделка является скорее игрушкой чем крупным проектом, я откажусь от оптимизатора. И теперь наши пути расходятся:
3.1. Транслятор. Данный модуль будет транслировать поток токенов полученных от парсера в машинный код. Данный подход используется в компиляторах
3.2. Исполнитель. Данный модуль выполняет команды записанные в виде потока токенов. Данный подход используется в интерпретаторах.
Я больше склоняюсь к созданию некоего промежуточного звена между интерпретатором и компилятором. То есть к созданию языка программирования, который будет транслироваться в байт-код виртуальной машины, которую так же предстоит написать.
Немного о реализации
1. Для реализации транслятора будет использован язык программирования Python. Почему именно он? Потому что его я знаю лучше всех. К тому же, его типизация, а точнее ее полное отсутствие позволит сократить количество переменных используемых при написании кода.
2. Для реализации виртуальной машины так же будет использован Python.
3. Для сборки проекта будет использован PyInstaller, так как он позволяет упаковывать все в один файл, к тому же на данный момент можно собрать для Linux и Windows без особых заморочек.
Теперь к практике
Предлагаю поставить перед собой минимальную задачу, при выполнении которой мы будем считать задачу условно выполненной и дальше можно не идти. Для этого определимся с минимальным синтаксисом языка:
1. Есть однострочные комментарии, начинаются со знака диеза (#) и продолжаются до конца строки.
2. Есть два типа данных (integer, string).
3. Есть возможность вывода информации на экран.
4. Есть возможность ввода значений с клавиатуры.
Напишем простенькую программу на нашем новом языке, с учетом правил которые мы только что сформулировали:
Вод собственно и все. Простенькая программка, которая демонстрирует возможности только что придуманного языка. На этом я думаю следует закончить.
В следующей части начнем написание своего велосипеда, который сможет выполнить код приведенный выше.
Как написать собственный язык программирования
Перевод статьи «Write you a programming language».
Что это означает — написать язык? Это значит, что вам нужно написать программу, которая будет интерпретировать или компилировать язык программирования (т. е. новый язык). Но для написания этой программы вам придется использовать какой-нибудь из существующих языков (базовый язык). Также можно написать эту программу на чистом машинном коде.
Интерпретатор или компилятор?
Для начала нужно выбрать, что вы хотите написать: интерпретатор или компилятор (или оба). Какую роль они играют?
Любопытно, что вы можете написать для своего языка программирования и интерпретатор, и компилятор. Примеры — Lisp (CommonLisp), Scheme (Chez Scheme).
Также можно написать интерпретатор или компилятор для языка программирования на этом же языке. Для этого вам придется сначала написать первый интерпретатор или компилятор на другом языке, а затем, в новых версиях, вы сможете пользоваться уже новым языком (т. н. раскрутка).
Руководства по теме создания интерпретаторов и компиляторов можно разбить на категории в соответствии с «базовыми» и «новыми» языками, например:
Если язык реализован как компилятор, он переводит исходный язык на язык назначения. Исходный язык — то же самое, что и «новый», но язык назначения — не то же, что «базовый» язык. Руководства можно разбить по категориям в соответствии с исходным языком и языком назначения. Например:
Управление памятью
Следующее, что нужно определить, это как ваш язык программирования будет управлять памятью:
Система типов
Далее надо разобраться, как в вашем языке будет обстоять дело с типами:
Можно выбрать и кое-что позаковыристее. Например, типизацию Мартина-Лёфа (ML), зависимые типы (Idris), линейные типы и т. п.
Парадигмы
Все, указанное выше, касалось всех языков программирования. На следующем этапе вы можете выбрать другие особенности (одну или больше), которые определят парадигму вашего языка.
Например, вы допускаете использование функций первого класса, строгие вычисления (с вызовом по соиспользованию), динамические типы, макросы — и получаете Lisp.
Или вы можете разрешить использование функций первого класса, ленивые вычисления, статические типы — и получить на выходе ML.
Дополнительные особенности
Поверх всего этого вы можете добавить дополнительные особенности, например:
Генераторы парсеров
Одним из факторов успеха MAL является то, что ему не нужен генератор парсера: парсер Lisp относительно легко имплементировать. Это делает его очень портируемым (реализован более чем на 80 языках). То же касается lis.py — у него есть еще более простой токенизатор.
Большинство руководств, не связанных с Lisp, предполагают необходимость какого-то специфичного генератора парсеров, что делает их менее портируемыми.
Список туториалов
Я собрал собственную коллекцию руководств по созданию языков программирования. Они находятся в репозитории на GitHub, так что вы вполне можете стать контрибьютором.