Руководство по созданию интерпретатора языка Pascal на Python
Предлагаем вашему вниманию серию статей, опубликованную в блоге Руслана Спивака. В ней автор подробно описывает процесс разработки базового интерпретатора. Серия пополняется, и в этой подборке вы найдете первые части руководства.
Примеры кода приведены на Python, однако подробные пояснения позволят читателю использовать для реализации любой другой удобный язык. В качестве интерпретируемого языка выбран Pascal, однако и здесь вы не будете ограничены — можно обратиться к любому другому языку, с семантикой которого вы хорошо знакомы.
Если вы не знаете, как работает компилятор, то вы не знаете, как работает компьютер. И если вы не уверены на 100%, что знаете, как работает компилятор, то вы не знаете, как он работает. — Стив Йиг
Небольшой ликбез перед прочтением. Компилятор — программа, которая переводит (транслирует) исходный код на языке программирования (высокого уровня) на язык, «более понятный компьютеру» (низкоуровневый). При этом программа сначала полностью транслируется, а затем выполняется. Интерпретатор — такой же транслятор, но выполняющий инструкции «на лету» (пооператорно, построчно), то есть без предварительной компиляции всего кода.
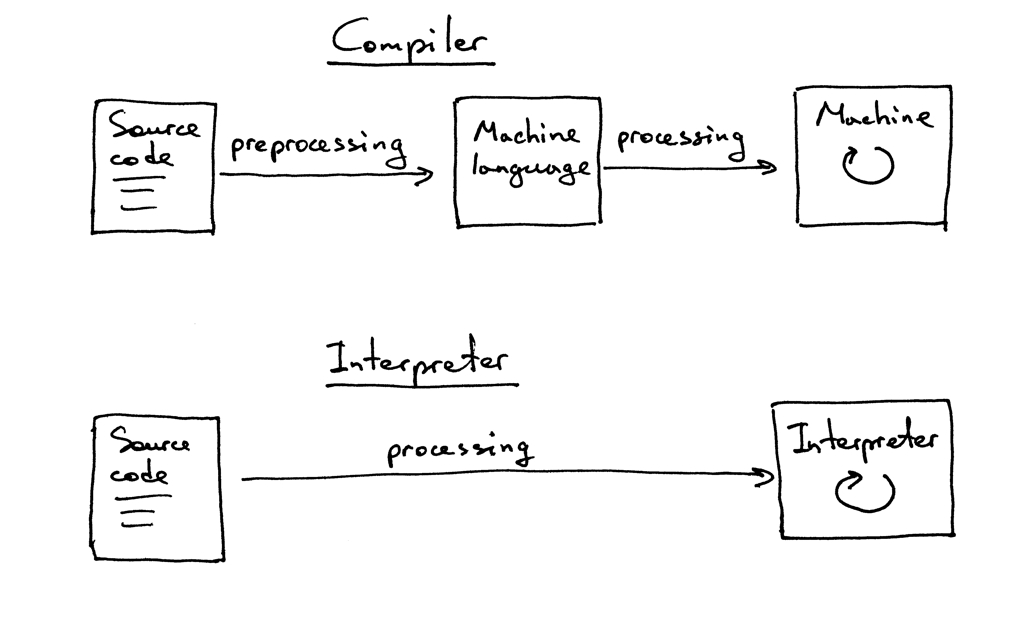
Различие между компилятором и интерпретатором
Почему вам нужно создать свой интерпретатор:
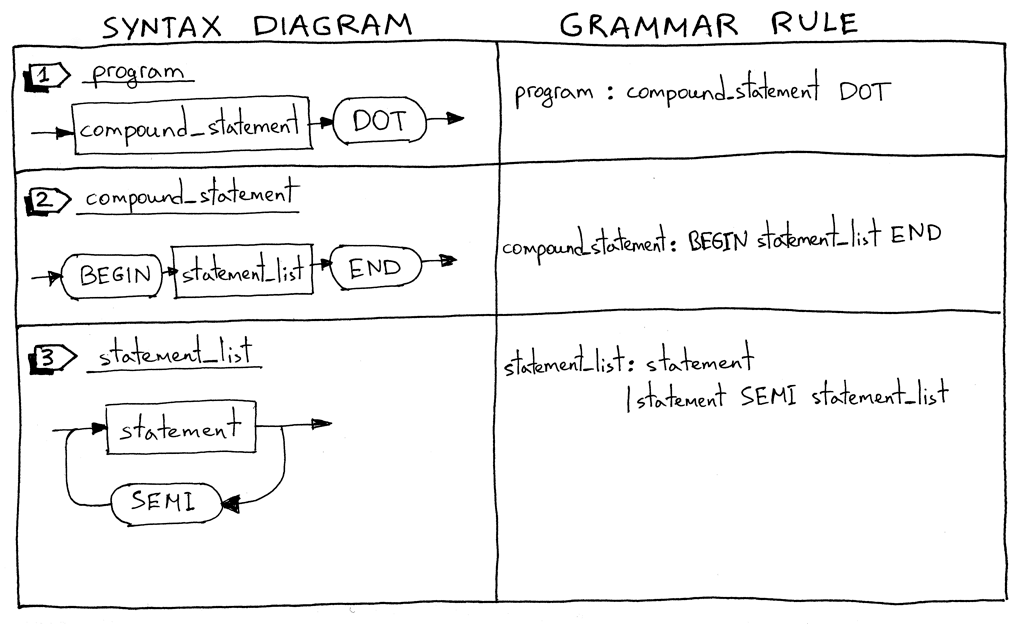
Что приятно, статьи подробно иллюстрируются. Создается впечатление, что автор перед вами ведет настоящую лекцию. Вот, например, одна из синтаксических диаграмм:
В конце каждой части руководства дается несколько задач для самостоятельной реализации и список полезных книг для более полного изучения вопроса. Итак, теперь приступайте к чтению:
Часть 1. Основные понятия, разбиение на токены и сложение однозначных чисел.
Часть 2. Обработка пробельных символов, многозначные числа.
Часть 3. Синтаксические диаграммы, одиночные умножение и деление.
Часть 4. Множественные умножения и деления, форма Бэкуса-Наура.
Часть 5. Калькулятор с произвольным числом операций, ассоциативность и порядок выполнения операторов.
Часть 6. Заканчиваем калькулятор: произвольный уровень вложенности.
Часть 7. Базовые используемые структуры данных. Также рекомендуем эту серию статей.
Часть 9. Объявление программы, составные операторы, присваивание, таблицы символов и обработка переменных.
Часть 10. Продолжение предыдущей части руководства. Обработка комментариев.
Серия продолжит пополняться, а пока можете обратиться к одному из пособий, которые рекомендует автор в конце каждой части.
Как мне написать интерпретатор с C++ на паскаль?
Я зделал модуль по Паскаль, где мне его выложить для общего пользования и как защитить авторство?
Кто с таким сталкивался, подскажите что делать, на каком сайте выложить и как можно сказать.
Мне нужно написать коды к этим задачам.( Все пишут в Паскале). Но если можете мне в Бейсике. Пожалуйста
Мне нужно написать коды к этим задачам.( Все пишут в Паскале). Но если можете в Бейсике.
Написать интерпретатор
здравствуйте,ребята помогите написать интерпретатор на языке С++. у кого небудь есть готовый.
yegorje, если именно так, как Вы написали, то запросто. Работа муторная и долгая. Составляешь соответствия С++ и Паскалевских инструкций, и вперёд, работать со строками. Например, самое простое: < заменяешь на begin, >заменяешь на end; и так далее, и тому подобное.
Если же «Как мне написать интерпретатор C++ на паскале?», то тоже. Почти ничего страшного. Нужно только по ходу интерпретации создавать нужные переменные, и одновременно парсить С++ строки и выполнять их по одной с помощью кучи мелких подпрограмм и горы условий.
как мне написать батник
Здравствуйте, начал изучать c++, но сама структура IDE мне не нравиться, поэтому я хочу спросить.
Написать интерпретатор Lisp’a
подскажите пожалуйста Добавлено через 54 минуты есть код Лиспа на Лиспе, надо перевести на F#.
Написать свой интерпретатор
Привет, мир! Помогите, направьте меня на правильное русло (интерпретатор с нуля, написать свой.
Можно ли на C# написать интерпретатор
Моно ли на C# написать интерпретатор? Например для питона интерпретатор написан на C ибо C быстрый.
Как же мне, тупому, написать формулу
Да простят меня модераторы, знаю что виновен:umnik: Что то видать я совсем отупел. Не могу.
Как в с++ мне написать условный оператор?
Если d>=0, то если (x1/10, остаток = 0) и (x2/10 остаток = 0), то f увеличиваем на 1. Мой.
ВВЕДЕНИЕ
В трех первых частях этой серии мы рассмотрели синтаксический анализ и компиляцию математических выражений, постепенно и методично пройдя от очень простых одно-символьных «выражений», состоящих из одного терма, через выражения в более общей форме и закончив достаточно полным синтаксическим анализатором, способным анализировать и транслировать операции присваивания с много символьными токенами, вложенными пробелами и вызовами функций. Сейчас я собираюсь провести вас сквозь этот процесс еще раз, но уже с целью интерпретации а не компиляции объектного кода.
Если эта серия о компиляторах, то почему мы должны беспокоиться об интерпретаторах? Просто я хочу чтобы вы увидели как изменяется характер синтаксического анализатора при изменении целей. Я также хочу объединить понятия этих двух типов трансляторов, чтобы вы могли видеть не только различия но и сходства.
Рассмотрим следующее присваивание:
В компиляторе мы хотим заставить центральный процессор выполнить это присваивание во время выполнения. Сам транслятор не выполняет никаких арифметических операций… он только выдает объектный код, который заставит процессор сделать это когда код выполнится. В примере выше компилятор выдал бы код для вычисления значения выражения и сохранения результата в переменной x.
Для интерпретатора, напротив, никакого объектного кода не генерируется. Вместо этого арифметические операции выполняются немедленно как только происходит синтаксический анализ. К примеру, когда синтаксический анализ присваивания завершен, x будет содержать новое значение.
Метод, который мы применяем во всей этой серии, называется «синтаксически-управляемым переводом». Как вы знаете к настоящему времен, структура синтаксического анализатора очень близко привязана к синтаксису анализируемых нами конструкций. Мы создали процедуры на Pascal, которые распознают каждую конструкцию языка. Каждая из этих конструкций (и процедур) связана с соответствующим «действием», которое выполняет все необходимое как только конструкция распознана. В нашем компиляторе каждое действие включает выдачу объектного кода для выполнения позднее во время исполнения. В интерпретаторе каждое действие включает что-то для немедленного выполнения.
Что я хотел бы, чтобы вы увидели, это то, что план… структура… синтаксического анализатора не меняется. Изменяются только действия. Так что, если вы можете написать интерпретатор для данного языка, то вы можете также написать и компилятор, и наоборот. Однако, как вы увидите, имеются и отличия, и значительные. Поскольку действия различны, процедуры, завершающие распознавание, пишутся по-разному. Характерно, что в интерпретаторе завершающие подпрограммы распознавания написаны как функции, возвращающие числовое значение вызвавшей их программе. Ни одна из подпрограмм анализа нашего компилятора не делает этого.
Наш компилятор, фактически, это то, что мы могли бы назвать «чистым» компилятором. Как только конструкция распознана, объектный код выдается немедленно. (Это одна из причин, по которым код не очень эффективный.) Интерпретатор, который мы собираемся построить, является чистым интерпретаторов в том смысле, что здесь нет никакой трансляции типа «токенизации», выполняемой над исходным текстом. Это две крайности трансляции. В реальном мире трансляторы не являются такими чистыми, но стремятся использовать часть каждой методики.
Я могу привести несколько примеров. Я уже упомянул один: большинство интерпретаторов, типа Microsoft BASIC, к примеру, транслируют исходный текст (токенизируют его) в промежуточную форму, чтобы было легче выполнять синтаксический анализ в реальном режиме времени.
Другой пример – ассемблер. Целью ассемблера, конечно, является получение объектного кода и он обычно выполняет это по однозначному принципу: одна инструкция на строку исходного кода. Но почти все ассемблеры также разрешают использовать выражения как параметры. В этом случае выражения всегда являются константами, и ассемблер не предназначен выдавать для них объектный код. Скорее он «интерпретирует» выражение и вычисляет соответствующее значение, которое фактически и выдается с объектным кодом.
Фактически, мы могли бы использовать часть этого сами. Транслятор, который мы создали в предыдущей главе, будет покорно выплевывать объектный код для сложных выражений, даже если каждый терм в выражении будет константой. В этом случае было бы гораздо лучше, если бы транслятор вел себя немного как интерпретатор и просто вычислял соответствующее значение константы.
В теории компиляции существует понятие, называемое «ленивой» трансляцией. Идея состоит в том, что вы не просто выдаете код при каждом действии. Фактически, в крайнем случае вы не выдаете что-либо вообще до тех пор, пока это не будет абсолютно необходимо. Для выполнения этого, действия, связанные с подпрограммами анализа, обычно не просто выдают код. Иногда они это делают, но часто они просто возвращают информацию обратно вызвавшей программе. Вооружившись этой информацией, вызывающая программа может затем сделать лучший выбор того, что делать.
К примеру, для данного выражения
наш компилятор будет покорно выплевывать поток из 18 инструкций для загрузки каждого параметра в регистры, выполнения арифметических действий и сохранения результата. Ленивая оценка распознала бы, что выражение, содержащее константы, может быть рассчитано во время компиляции и уменьшила бы выражение до
Даже ленивая оценка была бы затем достаточно умной, чтобы понять, что это эквивалентно
что совсем не требует никаких действий. Мы смогли уменьшить 18 инструкций до нуля!
Обратите внимание, что нет никакой возможности оптимизировать таким способом наш компилятор, потому что каждое действие выполняется в нем немедленно.
Ленивая оценка выражений может произвести значительно лучший объектный код чем тот который мы могли произвести. Я, тем не менее, предупреждаю вас: это значительно усложняет код синтаксического анализатора, потому что каждая подпрограмма теперь должна принять решение относительно того, выдать объектный код или нет. Ленивая оценка конечно же названа так не потому, что она проще для создателей компиляторов!
Так как мы действуем в основном по принципу KISS, я не буду более углубляться в эту тему. Я только хочу, чтобы вы знали, что вы можете получить некоторую оптимизацию кода, объединяя методы компиляции и интерпретации. В частности Вы должны знать, что подпрограммы синтаксического анализа в более интеллектуальном трансляторе обычно что-то возвращают вызвавшей их программе и иногда сами ожидают этого. Эта главная причина обсуждения интерпретаторов в этой главе.
ИНТЕРПРЕТАТОР
Итак, теперь, когда вы знаете почему мы принялись за все это, давайте начнем. Просто для того, чтобы дать вам практику, мы начнем с пустого Cradle и создадим транслятор заново. На этот раз, конечно, мы сможем двигаться немного быстрее.
Так как сейчас мы собираемся выполнять арифметические действия, то первое, что мы должны сделать – изменить функцию GetNum, которая до настоящего момента всегда возвращала символ (или строку). Лучше если сейчас она будет возвращать целое число. Сделайте копию Cradle (на всякий случай не изменяйте сам Cradle!!) и модифицируйте GetNum следующим образом:
Затем напишите следующую версию Expression:
И, наконец, вставьте
в конец основной программы. Теперь откомпилируйте и протестируйте.
Теперь давайте расширим ее, включив поддержку операций сложения. Измените Expression так:
Структура Expression, конечно, схожа с тем, что мы делали ранее, так что мы не будем иметь слишком много проблем при ее отладке. Тем не менее это была серьезная разработка, не так ли? Процедуры Add и Subtract исчезли! Причина в том, что для выполнения необходимых действий нужны оба аргумента операции. Я мог бы сохранить эти процедуры и передавать в них значение выражения на данный момент, содержащееся в Value. Но мне показалось более правильным оставить Value как строго локальную переменную, что означает, что код для Add и Subtract должен быть помещен вместе. Этот результат наводит на мысль, что хотя разработанная нами структура была хорошей и проверенной для нашей бесхитростной схемы трансляции, она возможно не могла бы использоваться с ленивой оценкой. Эту небольшую интересную новость нам возможно необходимо иметь в виду в будущем.
Итак, транслятор работает? Тогда давайте сделаем следующий шаг. Несложно понять, что процедура Term должна выглядеть также. Замените каждый вызов GetNum в функции Expression на вызов Term и затем наберите следующую версию Term:
< Parse and Translate a Math Term >
function Term: integer;
var Value: integer;
begin
Value := GetNum;
while Look in [‘*’, ‘/’] do begin
case Look of
‘*’: begin
Match(‘*’);
Value := Value * GetNum;
end;
‘/’: begin
Match(‘/’);
Value := Value div GetNum;
end;
end;
end;
Term := Value;
end;
Теперь испробуйте. Не забудьте двух вещей: во-первых мы имеем дело с целочисленным делением, поэтому, например, 1/3 выдаст ноль. Во-вторых, даже если мы можем получать на выходе многозначные числа, входные числа все еще ограничены одиночной цифрой.
Сейчас это выглядит как глупое ограничение, так как мы уже видели как легко может быть расширена функция GetNum. Так что давайте исправим ее прямо сейчас. Вот новая версия:
Если вы откомпилировали и протестировали эту версию интерпретатора, следующим шагом должна быть установка функции Factor, поддерживающей выражения в скобках. Мы задержимся немного дольше на именах переменных. Сначала измените ссылку на GetNum в функции Term, чтобы вместо нее вызывалась функция Factor. Теперь наберите следующую версию Factor:
< Parse and Translate a Math Factor >
function Expression: integer; Forward;
function Factor: integer;
begin
if Look = ‘(‘ then begin
Match(‘(‘);
Factor := Expression;
Match(‘)’);
end
else
Factor := GetNum;
end;
Это было довольно легко, а? Мы быстро пришли к полезному интерпретатору.
НЕМНОГО ФИЛОСОФИИ
Прежде чем двинуться дальше, я бы хотел обратить ваше внимание на кое-что. Я говорю о концепции, которую мы использовали на всех этих уроках, но которую я явно не упомянул до сих пор. Я думаю, что пришло время сделать это, так как эта концепция настолько полезная и настолько мощная, что она стирает все различия между тривиально простым синтаксическим анализатором и тем, который слишком сложен для того, чтобы иметь с ним дело.
В ранние дни технологии компиляции люди тратили ужасно много времени на выяснение того, как работать с такими вещами как приоритет операторов… способа, который определяет приоритет операторов умножения и деления над сложением и вычитанием и т.п. Я помню одного своего коллегу лет тридцать назад и как возбужденно он выяснял как это делается. Используемый им метод предусматривал создание двух стеков, в которые вы помещали оператор или операнд. С каждым оператором был связан уровень приоритета и правила требовали, чтобы вы фактически выполняли операцию («уменьшающую» стек) если уровень приоритета на вершине стека был корректным. Чтобы сделать жизнь более интересной оператор типа «)» имел различные приоритеты в зависимости от того, был он уже в стеке или нет. Вы должны были дать ему одно значение перед тем как поместите в стек и другое, когда решите извлечь из стека. Просто для эксперимента я самостоятельно поработал со всем этим несколько лет назад и могу сказать вам, что это очень сложно.
Мы не делали что-либо подобное. Фактически, к настоящему времени синтаксический анализ арифметических выражений должен походить на детскую игру. Как мы оказались настолько удачными? И куда делся стек приоритетов?
Подобная вещь происходит в нашем интерпретаторе выше. Вы просто знаете, что для того, чтобы выполнить вычисления арифметических выражений (в противоположность их анализу), должны иметься числа, помещенные в стек. Но где стек?
Наконец, в учебниках по компиляторам имеются разделы, где обсуждены стеки и другие структуры. В другом передовом методе синтаксического анализа (LR) используется явный стек. Фактически этот метод очень похож на старый способ вычисления арифметических выражений. Другая концепция – это синтаксическое дерево. Авторы любят рисовать диаграммы из токенов в выражении объединенные в дерево с операторами во внутренних узлах. И снова, где в нашем методе деревья и стеки? Мы не видели ничего такого. Во всех случаях ответ в том, что эти структуры не явные а неявные. В любом машинном языке имеется стек, используемый каждый раз, когда вы вызываете подпрограмму. Каждый раз, когда вызывается подпрограмма, адрес возврата помещается в стек ЦПУ. В конце подпрограммы адрес выталкивается из стека и управление передается на этот адрес. В рекурсивном языке, таком как Pascal, могут также иметься локальные данные, помещенные в стек, и они также возвращаются когда это необходимо.
Например функция Expression содержит локальный параметр, названный Value, которому присваивается значение при вызове Term. Предположим, при следующем вызове Term для второго аргумента, что Term вызывает Factor, который рекурсивно вызывает Expression снова. Этот «экземпляр» Expression получает другое значение для его копии Value. Что случится с первым значением Value? Ответ: он все еще в стеке и будет здесь снова, когда мы возвратимся из нашей последовательности вызовов.
Другими словами, причина, по которой это выглядит так просто в том, что мы максимально использовали ресурсы языка. Уровни иерархии и синтаксические деревья присутствуют здесь, все правильно, но они скрыты внутри структуры синтаксического анализатора и о них заботится порядок в котором вызываются различные процедуры. Теперь, когда вы увидели, как мы делаем это, возможно трудно будет придумать как сделать это каким-либо другим способом. Но я могу сказать вам, что это заняло много лет для создателей компиляторов. Первые компиляторы были слишком сложными. Забавно, как работа становится легче с небольшой практикой.
Вывод из всего того, что я привел здесь, служит и уроком и предупреждением. Урок: дела могут быть простыми если вы приметесь за них с правильной стороны. Предупреждение: смотрите, что делаете. Если вы делаете что-либо самостоятельно и начинаете испытывать потребность в отдельном стеке или дереве, возможно это время спросить себя, правильно ли вы смотрите на вещи. Возможно вы просто не используете возможностей языка так как могли бы.
Следующий шаг – добавление имен переменных. Сейчас, однако, мы имеем небольшую проблему. В случае с компилятором мы не имели проблем при работе с именами переменных… мы просто выдавали эти имена ассемблеру и позволяли остальной части программы заботиться о распределении для них памяти. Здесь же, напротив, у нас должна быть возможность извлекать значения переменных и возвращать их как значение функции Factor. Нам необходим механизм хранения этих переменных.
В ранние дни персональных компьютеров существовал Tiny Basic. Он имел в общей сложности 26 возможных переменных: одна на каждую букву алфавита. Это хорошо соответствует нашей концепции одно-символьных токенов, так что мы испробуем этот же прием. В начале интерпретатора, сразу после объявления переменной Look, вставьте строку:
Table: Array[‘A’..’Z’] of integer;
Мы также должны инициализировать массив, поэтому добавьте следующую процедуру:
< Initialize the Variable Area >
procedure InitTable;
var i: char;
begin
for i := ‘A’ to ‘Z’ do
Table[i] := 0;
end;
Вы также должны вставить вызов InitTable в процедуру Init. Не забудьте сделать это, иначе результат может удивить вас!
Теперь, когда у нас есть массив переменных, мы можем модифицировать Factor так, чтобы он их использовал. Так как мы не имеем (пока) способа для установки значения переменной, Factor будет всегда возвращать для них нулевые значения, но давайте двинемся дальше и расширим его. Вот новая версия:
< Parse and Translate a Math Factor >
function Expression: integer; Forward;
function Factor: integer;
begin
if Look = ‘(‘ then begin
Match(‘(‘);
Factor := Expression;
Match(‘)’);
end
else if IsAlpha(Look) then
Factor := Table[GetName]
else
Factor := GetNum;
end
Как всегда откомпилируйте и протестируйте эту версию программы. Даже притом, что все переменные сейчас равны нулю, по крайней мере мы можем правильно анализировать законченные выражения, так же как и отлавливать любые неправильно оформленные.
Я предполагаю вы уже знаете следующий шаг: мы должны добавить операции присваивания, чтобы мы могли помещать что-нибудь в переменные. Сейчас давайте будем «однострочниками», хотя скоро мы сможем обрабатывать множество операторов.
Операция присваивания похожа на то, что мы делали раньше:
Чтобы протестировать ее, я добавил временный оператор write в основную программу для вывода значения A. Затем я протестировал ее с различными присваиваниями.
Конечно, интерпретируемый язык, который может воспринимать только одну строку программы не имеет большой ценности. Поэтому нам нужно обрабатывать множество утверждений. Это просто означает что необходимо поместить цикл вокруг вызова Assignment. Давайте сделаем это сейчас. Но что должно быть критерием выхода из цикла? Рад, что вы спросили, потому что это поднимает вопрос, который мы были способны игнорировать до сих пор.
Одной из наиболее сложных вещей в любом трансляторе является определение момента когда необходимо выйти из данной конструкции и продолжить выполнение. Пока это не было для нас проблемой, потому что мы допускали только одну конструкцию… или выражение или операцию присваивания. Когда мы начинаем добавлять циклы и различные виды операторов, вы найдете, что мы должны быть очень осторожны, чтобы они завершались правильно. Если мы помещаем наш интерпретатор в цикл, то нам нужен способ для выхода из него. В прерывании по концу строки нет ничего хорошего, поскольку с его помощью мы переходим к следующей строке. Мы всегда могли позволить нераспознаваемым символам прерывать выполнение, но это приводило бы к завершению каждой программы сообщением об ошибке, что конечно выглядит несерьезно.
Нам нужен завершающий символ. Я выступаю за завершающую точку в Pascal («.»). Небольшое осложнение состоит в том, что Turbo Pascal завершает каждую нормальную строку двумя символами: возврат каретки (CR) и перевод строки (LF). В конце каждой строки мы должны «съедать» эти символы перед обработкой следующей. Естественным способом было бы сделать это в процедуре Match за исключением того, что сообщение об ошибке Match выводит ожидаемые символы, что для CR и LF не будет выглядеть так хорошо. Для этого нам нужна специальная процедура, которую мы, без сомнения, будем использовать много раз. Вот она:
< Recognize and Skip Over a Newline >
procedure NewLine;
begin
if Look = CR then begin
GetChar;
if Look = LF then
GetChar;
end;
end;
Вставьте эту процедуру в любом удобном месте… я поместил ее сразу после Match. Теперь перепишите основную программу, чтобы она выглядела следующим образом:
Обратите внимание, что проверка на CR теперь исчезла и что также нет проверки на ошибку непосредственно внутри NewLine. Это нормально… все оставшиеся фиктивные символы будут отловлены в начале следующей операции присваивания.
Хорошо, сейчас мы имеем функционирующий интерпретатор. Однако, это не дает нам много хорошего, так как у нас нет никакого способа для ввода или вывода данных. Уверен что нам помогут несколько подпрограмм ввода/вывода!
Тогда давайте завершим этот урок добавив подпрограммы ввода/вывода. Так как мы придерживаемся одно-символьных токенов, я буду использовать знак «?» для замены операции чтения, знак «!» для операции записи и символ, немедленно следующий после них, который будет использоваться как одно-символьный «список параметров». Вот эти подпрограммы:
Я полагаю они не очень причудливы… например нет никакого символа приглашения при вводе… но они делают свою работу.
Соответствующие изменения в основной программе показаны ниже. Обратите внимание, что мы используем обычный прием – оператор выбора по текущему предсказывающему символу, чтобы решить что делать.
< Main Program >
begin
Init;
repeat
case Look of
‘?’: Input;
‘!’: Output;
else Assignment;
end;
NewLine;
until Look = ‘.’;
end.
Я надеюсь, к настоящему времени вы убедились, что ограничение имен одним символом и обработка пробелов это вещи о которых легко позаботиться, как мы сделали это на последнем уроке. На этот раз, если вам захотелось поиграть с этими расширениями, будьте моим гостем… они «оставлены как упражнение для студента». Увидимся в следующий раз.
Комментарии и вопросы
Материалы статей собраны из открытых источников, владелец сайта не претендует на авторство. Там где авторство установить не удалось, материал подаётся без имени автора. В случае если Вы считаете, что Ваши права нарушены, пожалуйста, свяжитесь с владельцем сайта.