Стандартное отклонение
Стандартное отклонение (англ. Standard Deviation) — простыми словами это мера того, насколько разбросан набор данных.
Вычисляя его, можно узнать, являются ли числа близкими к среднему значению или далеки от него. Если точки данных находятся далеко от среднего значения, то в наборе данных имеется большое отклонение; таким образом, чем больше разброс данных, тем выше стандартное отклонение.
Стандартное отклонение обозначается буквой σ (греческая буква сигма).
Стандартное отклонение также называется:
Использование и интерпретация величины среднеквадратического отклонения
Стандартное отклонение используется:
Рассмотрим два малых предприятия, у нас есть данные о запасе какого-то товара на их складах.
| День 1 | День 2 | День 3 | День 4 | |
|---|---|---|---|---|
| Пред.А | 19 | 21 | 19 | 21 |
| Пред.Б | 15 | 26 | 15 | 24 |
В обеих компаниях среднее количество товара составляет 20 единиц:
Однако, глядя на цифры, можно заметить:
Если рассчитать стандартное отклонение каждой компании, оно покажет, что
Стандартное отклонение показывает эту волатильность данных — то, с каким размахом они меняются; т.е. как сильно этот запас товара на складах компаний колеблется (поднимается и опускается).
Расчет среднеквадратичного (стандартного) отклонения
Формулы вычисления стандартного отклонения
Разница между формулами S и σ («n» и «n–1»)
Состоит в том, что мы анализируем — всю выборку или только её часть:
Как рассчитать стандартное отклонение?
Пример 1 (с σ)
Рассмотрим данные о запасе какого-то товара на складах Предприятия Б.
| День 1 | День 2 | День 3 | День 4 | |
| Пред.Б | 15 | 26 | 15 | 24 |
Если значений выборки немного (небольшое n, здесь он равен 4) и анализируются все значения, то применяется эта формула:

Применяем эти шаги:
1. Найти среднее арифметическое выборки:
μ = (15 + 26 + 15+ 24) / 4 = 20
2. От каждого значения выборки отнять среднее арифметическое:
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
5. Поделить на размер выборки (т.е. на n):
6. Найти квадратный корень:
Пример 2 (с S)
Задача усложняется, когда существуют сотни, тысячи или даже миллионы данных. В этом случае берётся только часть этих данных и анализируется методом выборки.
У Андрея 20 яблонь, но он посчитал яблоки только на 6 из них.
Популяция — это все 20 яблонь, а выборка — 6 яблонь, это деревья, которые Андрей посчитал.
| Яблоня 1 | Яблоня 2 | Яблоня 3 | Яблоня 4 | Яблоня 5 | Яблоня 6 |
| 9 | 2 | 5 | 4 | 12 | 7 |
Так как мы используем только выборку в качестве оценки всей популяции, то нужно применить эту формулу:

Математически она отличается от предыдущей формулы только тем, что от n нужно будет вычесть 1. Формально нужно будет также вместо μ (среднее арифметическое) написать X ср.
Применяем практически те же шаги:
1. Найти среднее арифметическое выборки:
Xср = (9 + 2 + 5 + 4 + 12 + 7) / 6 = 39 / 6 = 6,5
2. От каждого значения выборки отнять среднее арифметическое:
X1 – Xср = 9 – 6,5 = 2,5
X2 – Xср = 2 – 6,5 = –4,5
X3 – Xср = 5 – 6,5 = –1,5
X4 – Xср = 4 – 6,5 = –2,5
X5 – Xср = 12 – 6,5 = 5,5
X6 – Xср = 7 – 6,5 = 0,5
3. Каждую полученную разницу возвести в квадрат:
4. Сделать сумму полученных значений:
Σ (Xi – Xср)² = 6,25 + 20,25+ 2,25+ 6,25 + 30,25 + 0,25 = 65,5
5. Поделить на размер выборки, вычитав перед этим 1 (т.е. на n–1):
(Σ (Xi – Xср)²)/(n-1) = 65,5 / (6 – 1) = 13,1
6. Найти квадратный корень:
S = √((Σ (Xi – Xср)²)/(n–1)) = √ 13,1 ≈ 3,6193
Дисперсия и стандартное отклонение
Стандартное отклонение равно квадратному корню из дисперсии (S = √D). То есть, если у вас уже есть стандартное отклонение и нужно рассчитать дисперсию, нужно лишь возвести стандартное отклонение в квадрат (S² = D).
Дисперсия — в статистике это «среднее квадратов отклонений от среднего». Чтобы её вычислить нужно:
Ещё расчёт дисперсии можно сделать по этой формуле:
Правило трёх сигм
Это правило гласит: вероятность того, что случайная величина отклонится от своего математического ожидания более чем на три стандартных отклонения (на три сигмы), почти равна нулю.

Глядя на рисунок нормального распределения случайной величины, можно понять, что в пределах:
Это означает, что за пределами остаются лишь 0,28% — это вероятность того, что случайная величина примет значение, которое отклоняется от среднего более чем на 3 сигмы.
Стандартное отклонение в excel
Вычисление стандартного отклонения с «n – 1» в знаменателе (случай выборки из генеральной совокупности):
1. Занесите все данные в документ Excel.

2. Выберите поле, в котором вы хотите отобразить результат.
3. Введите в этом поле «=СТАНДОТКЛОНА(«
4. Выделите поля, где находятся данные, потом закройте скобки.

5. Нажмите Ввод (Enter).

В случае если данные представляют всю генеральную совокупность (n в знаменателе), то нужно использовать функцию СТАНДОТКЛОНПА.


Коэффициент вариации
Коэффициент вариации — отношение стандартного отклонения к среднему значению, т.е. Cv = (S/μ) × 100% или V = (σ/X̅) × 100%.
Стандартное отклонение делится на среднее и умножается на 100%.
Можно классифицировать вариабельность выборки по коэффициенту вариации:
Дисперсия, среднеквадратичное (стандартное) отклонение, коэффициент вариации в Excel
Из предыдущей статьи мы узнали о таких показателях, как размах вариации, межквартильный размах и среднее линейное отклонение. В этой статье изучим дисперсию, среднеквадратичное отклонение и коэффициент вариации.
Дисперсия
Дисперсия случайной величины – это один из основных показателей в статистике. Он отражает меру разброса данных вокруг средней арифметической.
Сейчас небольшой экскурс в теорию вероятностей, которая лежит в основе математической статистики. Как и матожидание, дисперсия является важной характеристикой случайной величины. Если матожидание отражает центр случайной величины, то дисперсия дает характеристику разброса данных вокруг центра.
Формула дисперсии в теории вероятностей имеет вид:

То есть дисперсия — это математическое ожидание отклонений от математического ожидания.
На практике при анализе выборок математическое ожидание, как правило, не известно. Поэтому вместо него используют оценку – среднее арифметическое. Расчет дисперсии производят по формуле:

s 2 – выборочная дисперсия, рассчитанная по данным наблюдений,
X – отдельные значения,
X̅– среднее арифметическое по выборке.
Стоит отметить, что у такого расчета дисперсии есть недостаток – она получается смещенной, т.е. ее математическое ожидание не равно истинному значению дисперсии. Подробней об этом здесь. Однако при увеличении объема выборки она все-таки приближается к своему теоретическому аналогу, т.е. является асимптотически не смещенной.
Простыми словами дисперсия – это средний квадрат отклонений. То есть вначале рассчитывается среднее значение, затем берется разница между каждым исходным и средним значением, возводится в квадрат, складывается и затем делится на количество значений в данной совокупности. Разница между отдельным значением и средней отражает меру отклонения. В квадрат возводится для того, чтобы все отклонения стали исключительно положительными числами и чтобы избежать взаимоуничтожения положительных и отрицательных отклонений при их суммировании. Затем, имея квадраты отклонений, просто рассчитываем среднюю арифметическую. Средний – квадрат – отклонений. Отклонения возводятся в квадрат, и считается средняя. Теперь вы знаете, как найти дисперсию.
Расчет дисперсии в Excel
Генеральную и выборочную дисперсии легко рассчитать в Excel. Есть специальные функции: ДИСП.Г и ДИСП.В соответственно.

В чистом виде дисперсия не используется. Это вспомогательный показатель, который нужен в других расчетах. Например, в проверке статистических гипотез или расчете коэффициентов корреляции. Отсюда неплохо бы знать математические свойства дисперсии.
Свойства дисперсии
Свойство 1. Дисперсия постоянной величины A равна 0 (нулю).
Свойство 2. Если случайную величину умножить на постоянную А, то дисперсия этой случайной величины увеличится в А 2 раз. Другими словами, постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
Свойство 3. Если к случайной величине добавить (или отнять) постоянную А, то дисперсия останется неизменной.
Свойство 4. Если случайные величины X и Y независимы, то дисперсия их суммы равна сумме их дисперсий.
Свойство 5. Если случайные величины X и Y независимы, то дисперсия их разницы также равна сумме дисперсий.
Среднеквадратичное (стандартное) отклонение
Если из дисперсии извлечь квадратный корень, получится среднеквадратичное (стандартное) отклонение (сокращенно СКО). Встречается название среднее квадратичное отклонение и сигма (от названия греческой буквы). Общая формула стандартного отклонения в математике следующая:

На практике формула стандартного отклонения следующая:

Как и с дисперсией, есть и немного другой вариант расчета. Но с ростом выборки разница исчезает.
Расчет cреднеквадратичного (стандартного) отклонения в Excel
Для расчета стандартного отклонения достаточно из дисперсии извлечь квадратный корень. Но в Excel есть и готовые функции: СТАНДОТКЛОН.Г и СТАНДОТКЛОН.В (по генеральной и выборочной совокупности соответственно).

Среднеквадратичное отклонение имеет те же единицы измерения, что и анализируемый показатель, поэтому является сопоставимым с исходными данными.
Коэффициент вариации
Значение стандартного отклонения зависит от масштаба самих данных, что не позволяет сравнивать вариабельность разных выборках. Чтобы устранить влияние масштаба, необходимо рассчитать коэффициент вариации по формуле:

По нему можно сравнивать однородность явлений даже с разным масштабом данных. В статистике принято, что, если значение коэффициента вариации менее 33%, то совокупность считается однородной, если больше 33%, то – неоднородной. В реальности, если коэффициент вариации превышает 33%, то специально ничего делать по этому поводу не нужно. Это информация для общего представления. В общем коэффициент вариации используют для оценки относительного разброса данных в выборке.
Расчет коэффициента вариации в Excel
Расчет коэффициента вариации в Excel также производится делением стандартного отклонения на среднее арифметическое:
Коэффициент вариации обычно выражается в процентах, поэтому ячейке с формулой можно присвоить процентный формат:

Коэффициент осцилляции
Еще один показатель разброса данных на сегодня – коэффициент осцилляции. Это соотношение размаха вариации (разницы между максимальным и минимальным значением) к средней. Готовой формулы Excel нет, поэтому придется скомпоновать три функции: МАКС, МИН, СРЗНАЧ.

Коэффициент осцилляции показывает степень размаха вариации относительно средней, что также можно использовать для сравнения различных наборов данных.
Таким образом, в статистическом анализе существует система показателей, отражающих разброс или однородность данных.
Ниже видео о том, как посчитать коэффициент вариации, дисперсию, стандартное (среднеквадратичное) отклонение и другие показатели вариации в Excel.
6. Формула для вычисления дисперсии.
Среднее квадратическое отклонение. Коэффициент вариации
В первой части урока мы рассмотрели размах вариации, среднее линейное отклонение и дисперсию, и продолжение темы в заголовке. Многие из этих показателей фигурируют в теории вероятностей, и если вы зашли с поисковика именно за ними, то сразу ссылка на нужную статью: Дисперсия дискретной случайной величины – там же всё остальное.
Ну а здесь на повестке дня Математическая статистика (организационный урок для «чайников»), и мы продолжаем изучать показатели вариации:
Всё с формулами, примерами решений и техникой рациональных вычислений.
И снова о дисперсии.
На предыдущем занятии мы рассчитывали дисперсию по определению:
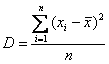 – для несгруппированных данных и
– для несгруппированных данных и
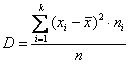 – для дискретного либо интервального вариационного ряда.
– для дискретного либо интервального вариационного ряда.
Если известно, генеральная ли нам дана совокупность или выборочная, то хорошим тоном считается поставить подстрочные индексы: 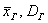 либо
либо 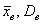 .
.
Расчёт дисперсии по определению прост и реально используется на практике, но существует ещё более простой и удобный способ вычисления – по формуле, которую несложно вывести из определения:
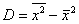 – дисперсия равна разности средней арифметической квадратов всех вариант статистической совокупности и квадрата средней самих этих вариант.
– дисперсия равна разности средней арифметической квадратов всех вариант статистической совокупности и квадрата средней самих этих вариант.
ОСМЫСЛЕННО повторяем ВСЛУХ и вникаем! … Карл украл у Клары кораллы, а Клара украла у Карла кларнет 🙂
Если что-то не очень понятно, то сейчас всё станет на свои места:
Для несгруппированных вариант 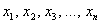 выборочной совокупности формула детализируется следующим образом:
выборочной совокупности формула детализируется следующим образом: 
и для готового вариационного ряда – так: 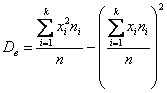 , где
, где 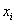 – кратные (одинаковые) варианты дискретного ряда либо середины интервалов интервального ряда, а
– кратные (одинаковые) варианты дискретного ряда либо середины интервалов интервального ряда, а 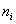 – соответствующие частоты.
– соответствующие частоты.
Для генеральной дисперсии 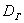 формулы те же, только с буквами
формулы те же, только с буквами 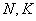 вместо
вместо 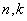 . Во многих случаях удобно использовать просто значок суммирования
. Во многих случаях удобно использовать просто значок суммирования 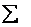 – без переменной-«счётчика», поскольку в контексте той или иной задачи и так понятно, что суммируется.
– без переменной-«счётчика», поскольку в контексте той или иной задачи и так понятно, что суммируется.
И начнём мы со знакомой подопытной задачи:
В результате 10 независимых измерений получены опытные данные, которые представлены в таблице: 
Это данные из Примера 13, и на этот раз нам требуется вычислить дисперсию с помощью формулы. Напоминаю, что там мы её рассчитали по определению и получили результат 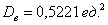 , таким образом, ответ известен заранее, и это всегда круто. Всегда, когда он правильный.
, таким образом, ответ известен заранее, и это всегда круто. Всегда, когда он правильный.
Решение: используем формулу  .
.
Для этого нужно найти выборочную среднюю, повторим действие: 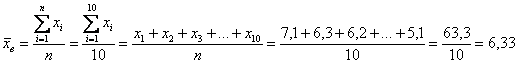 ,
,
вычислить квадраты всех вариант: 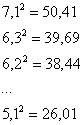
и их сумму: 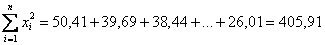
Результаты вычислений удобно заносить в таблицу: 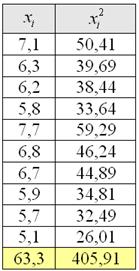
Осталось применить формулу: 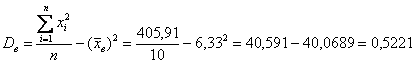 , что и требовалось увидеть.
, что и требовалось увидеть.
Ответ: 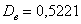
Теперь случай сформированного вариационного ряда. В Примере 14 мы потренировались на дискретном ряде, и сейчас очередь интервального:
С целью изучения вкладов в Сбербанке города проведено выборочное исследование, в результате которого получены следующие данные: 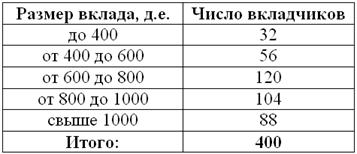
Вычислить выборочную дисперсию и среднее квадратическое отклонение, оценить соответствующие показатели генеральной совокупности.
Автор задачи заботливо подсчитал объем выборки 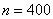 , но не «закрыл» крайние интервалы. Такая вещь уже встречалась, и решение мы начинаем с этого закрытия. Поскольку длины внутренних интервалов составляют
, но не «закрыл» крайние интервалы. Такая вещь уже встречалась, и решение мы начинаем с этого закрытия. Поскольку длины внутренних интервалов составляют 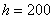 д.е., то логично рассмотреть такую же длину и по краям, то бишь, интервалы от 200 до 400 и от 1000 до 1200 денежных единиц.
д.е., то логично рассмотреть такую же длину и по краям, то бишь, интервалы от 200 до 400 и от 1000 до 1200 денежных единиц.
…Возможно, у вас возник вопрос, а как быть, если даны интервалы разной длины? В этом случае принимаем за «эталон» среднюю длину известных интервалов.
Для расчёта числовых характеристик перейдём к дискретному вариационному ряду, выбрав в качестве вариант  середины интервалов, которые здесь видны устно:
середины интервалов, которые здесь видны устно: 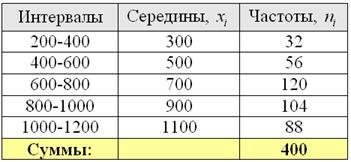
В тяжёлых случаях суммируем концы интервалов и делим их пополам, например: 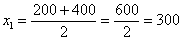 .
.
Кроме того, варианты целесообразно уменьшить в 1000 раз, поскольку в ходе дальнейших вычислений будут получаться гигантские числа. С современными вычислительными мощностями, это, конечно, не проблема, но смотреться будет некрасиво.
Сначала вычислим выборочную среднюю. Этот алгоритм уже обкатан: находим произведения 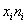 , их сумму:
, их сумму: 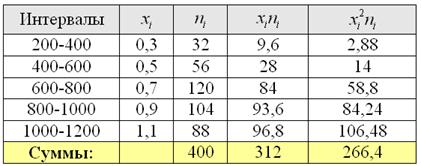
и по соответствующей формуле:
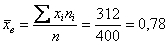 тыс. д.е. или 780 д.е. – средний размер вклада.
тыс. д.е. или 780 д.е. – средний размер вклада.
Примечание: далее для компактной записи я буду использовать просто значок 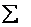 – без переменной-«счётчика».
– без переменной-«счётчика».
Теперь дисперсия. Её никто не запрещает рассчитать по определению 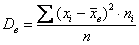 , но заметьте, насколько легче формула
, но заметьте, насколько легче формула  – для её применения всего-то лишь нужно рассчитать произведения
– для её применения всего-то лишь нужно рассчитать произведения 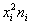 и их сумму
и их сумму 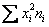 (правый столбец таблицы). Несмотря на то, что многие читатели уже освоили технику вычислений в Экселе, я продолжу записывать ролики – мало ли, кто что запамятовал:
(правый столбец таблицы). Несмотря на то, что многие читатели уже освоили технику вычислений в Экселе, я продолжу записывать ролики – мало ли, кто что запамятовал:
Итак, по формуле вычисления дисперсии, получаем:
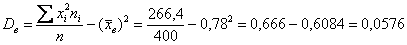 тыс. д.е. в квадрате (т.к. по определению, дисперсия – есть величина квадратичная).
тыс. д.е. в квадрате (т.к. по определению, дисперсия – есть величина квадратичная).
И, чтобы вернуться в размерность задачи, из дисперсии следует извлечь квадратный корень:
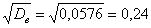 тыс. д.е. или 240 денежных единиц. Полученный показатель называется
тыс. д.е. или 240 денежных единиц. Полученный показатель называется
среднее квадратическое отклонение
Или стандартное отклонение. Оно обозначается греческой буквой «сигма», и коль скоро у нас выборочная совокупность, то добавляем соответствующий подстрочный индекс:
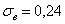 – выборочное среднее квадратическое отклонение.
– выборочное среднее квадратическое отклонение.
Чем меньше стандартное отклонение (и дисперсия), тем меньше вариация – тем бОльшее количество вариант находится вблизи выборочной средней. Но у нас, как нетрудно «прикинуть на глазок», разброс довольно-таки велик – значительное количество вкладов расположено далековато от 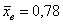 , и поэтому значение
, и поэтому значение 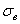 получилось немалым.
получилось немалым.
Следующая часть задачи состоит в том, чтобы корректно оценить генеральную дисперсию 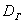 и генеральное среднее квадратическое отклонение
и генеральное среднее квадратическое отклонение 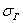 .
.
В 1-й части урока я рассказал о том, что выборочная дисперсия представляет собой смещённую оценку генеральной дисперсии. Это означает, что если мы будем проводить неоднократные выборки из той же генеральной совокупности, то полученные значения 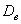 будут систематически занижено оценивать
будут систематически занижено оценивать 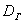 . Обращаю ваше внимание, что это не значит, что
. Обращаю ваше внимание, что это не значит, что 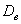 будет всегда меньше, чем
будет всегда меньше, чем 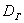 .
.
И поэтому выборочную дисперсию, как намекает условие, нужно поправить:
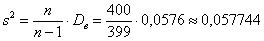 – исправленная выборочная дисперсия
– исправленная выборочная дисперсия
и, соответственно:
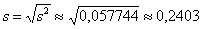 или 240,30 д.е. – исправленное среднее квадратическое отклонение.
или 240,30 д.е. – исправленное среднее квадратическое отклонение.
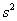 и
и 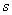 – это уже несмещённые оценки генеральной дисперсии
– это уже несмещённые оценки генеральной дисперсии 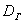 и генерального стандартного отклонения
и генерального стандартного отклонения 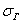 соответственно.
соответственно.
Ввиду большого объёма выборки (более 100 вариант) этой поправкой можно пренебречь, но всё же мы не будем «разбрасываться» 30 «копейками».
Ответ: 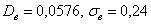 ; в качестве оценки соответствующих генеральных показателей принимаем
; в качестве оценки соответствующих генеральных показателей принимаем 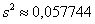 и
и 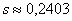 .
.
Рассмотренные выше показатели (размах вариации, среднее линейное отклонение, дисперсия, стандартное отклонение) входят в группу абсолютных показателей вариации, которые обладают рядом неудобств. Так, если в прорешанной задаче не уменьшать варианты в 1000 раз, то дисперсия получится в миллион раз больше! Да-да, не 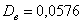 , а
, а 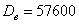 . И возникает естественное желание привести результаты к некому единому стандарту.
. И возникает естественное желание привести результаты к некому единому стандарту.
Для этого существуют показатели относительные, и самым известным из них является
коэффициент вариации
– это отношение стандартного отклонения к средней, выраженное в процентах: 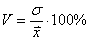
И вот теперь совершенно без разницы, в д.е. мы считали: 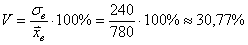
или в тысячах д.е.: 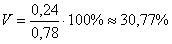
Примечание: на практике часто считают именно через 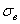 , но для оценки коэффициента вариации всей генеральной совокупности, конечно же, корректнее использовать исправленное стандартное отклонение
, но для оценки коэффициента вариации всей генеральной совокупности, конечно же, корректнее использовать исправленное стандартное отклонение 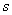 .
.
В статистике существует следующий эмпирический ориентир:
– если показатель вариации составляет примерно 30% и меньше, то статистическая совокупность считается однородной. Это означает, что большинство вариант находится недалеко от средней, и найденное значение 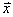 хорошо характеризует центральную тенденцию совокупности.
хорошо характеризует центральную тенденцию совокупности.
– если показатель вариации составляет существенно больше 30%, то совокупность неоднородна, то есть, значительное количество вариант находятся далеко от 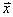 , и выборочная средняя плохо характеризует типичную варианту. В таких случаях целесообразно рассмотреть квартили, децили, а иногда и перцентили, которые делят вариационный ряд на части, и для каждого участка рассчитать свои показатели. Но это уже немного дебри статистики.
, и выборочная средняя плохо характеризует типичную варианту. В таких случаях целесообразно рассмотреть квартили, децили, а иногда и перцентили, которые делят вариационный ряд на части, и для каждого участка рассчитать свои показатели. Но это уже немного дебри статистики.
Другое преимущество относительных показателей – это возможность сравнивать разнородные статистические совокупности. Например, множество слонов и множество хомячков. Совершенно понятно, что дисперсия веса слонов по отношению к дисперсии веса хомяков будет просто конской, и их сопоставление не имеет смысла. Но вот анализ коэффициентов вариации веса вполне осмыслен, и может статься, что у слонов он составляет 10%, а у хомячков 40% (пример, конечно, условный). Это говорит о сбалансированном питании и размеренной жизни слонов. А вот хомяки там, то носятся с голодухи по полям, то отъедаются и спят в норах, и поэтому среди них есть много худощавых и много упитанных особей 🙂
Кроме коэффициента вариации, существуют и другие относительные показатели, но в реальных студенческих работах они почти не встречаются, и поэтому я не буду их рассматривать в рамках данного курса.
И сейчас, конечно же, задачки для самостоятельного решения:
Пример 17, на отработку терминов и формул:
а) Стандартное отклонение выборочной совокупности равно 5, а средний квадрат её вариант – 250. Найти выборочную среднюю.
б) Определите среднее квадратическое отклонение, если известно, что средняя равна 260, а коэффициент вариации составляет 30%.
и Пример 18, творческий:
Производство стальных труб на предприятии (тонн) в 1-м полугодии составило: 
Определить:
– среднемесячный объем производства;
– среднее квадратическое отклонение;
– коэффициент вариации.
Сделать краткие содержательные выводы. – Да, это тоже типичный пункт статистической задачи!
Обратите внимание, что здесь не понятно, выборочной ли считать эту совокупность или генеральной. И в таких случаях лучше не заниматься домыслами, просто используем обозначения без подстрочных индексов.
Вообще, задачи на экономическую и промышленную тематику – самые популярные в статистике, и в моей коллекции их сотни. Но все они до ужаса однотипны, и поэтому я предлагаю их в терапевтической дозировке 🙂
Выполнить расчёты в Экселе – числа уже там, ну а инструкцию я на этот раз не привёл, поскольку люди вы уже опытные.
Краткое решение и ответ в конце урока, который подошёл к концу.
Следующее занятие не за горами, а уже за кочкой:
Пример 17. Решение:
а) Используем формулу 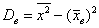 . По условию,
. По условию, 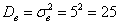 ,
, 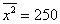 . Таким образом:
. Таким образом: 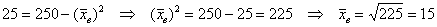
б) Используем формулу 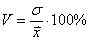 . По условию,
. По условию, 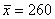 ,
, 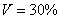 . Таким образом:
. Таким образом: 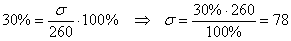
Ответ: а) 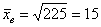 , б)
, б) 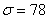
Пример 18. Решение: вычислим сумму вариант и сумму их квадратов: 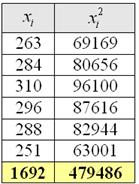
Найдём среднюю:
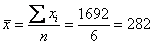 тонны – среднемесячный объем производства за полугодие.
тонны – среднемесячный объем производства за полугодие.
Дисперсию вычислим по формуле: 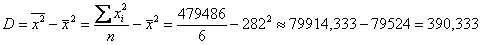
Среднее квадратическое отклонение:
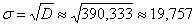 тонн.
тонн.
Коэффициент вариации: 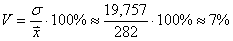
Ответ: 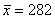 тонны,
тонны, 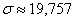 тонн,
тонн, 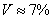
Краткие выводы: за первое полугодие среднемесячный объём производства труб составил 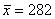 тонны. Низкие показатели вариации говорят о стабильной ситуации на производстве.
тонны. Низкие показатели вариации говорят о стабильной ситуации на производстве.
Автор: Емелин Александр
(Переход на главную страницу)
 Zaochnik.com – профессиональная помощь студентам
Zaochnik.com – профессиональная помощь студентам
cкидкa 15% на первый зaкaз, прoмoкoд: 5530-hihi5
Tutoronline.ru – онлайн репетиторы по математике и другим предметам